
文本数据增强-EDA笔记
对文本数据进行EDA(同义词替换、随机插入、随机交换、随机删除)简介:实现这些功能需要使用 synonyms 第三方库来实现import synonymsstring_text = "向日葵"print(synonyms.nearby(string_text,5))# 打印5个 向日葵 的近义词# output:(['向日葵', '铃兰', '蒲公英', '雏菊', '头序'], [1.0, 0.
·
对文本数据进行EDA(同义词替换、随机插入、随机交换、随机删除)
简介:实现这些功能需要使用 synonyms 第三方库来实现
import synonyms
string_text = "向日葵"
print(synonyms.nearby(string_text,5)) # 打印5个 向日葵 的近义词
# output:
(['向日葵', '铃兰', '蒲公英', '雏菊', '头序'], [1.0, 0.64993227, 0.6350045, 0.6339984, 0.48143455])
返回的是一个元组:
第一个返回结果是 这个词的近义词,
第二个返回结果是 相似的概率
封装一个获取近义词的函数,便于直接获取近义词
def get_synonyms(word):
synonym_word_list = synonyms.nearby(word,number)[0]
return synonym_word_list
- 同义词替换(对非停用词的词语进行同义词替换)
# 加载停用词列表
with open("../data/stopwords.txt","r",encoding="utf-8") as f:
stop_word_list = [word.strip() for word in f]
# 先进行 jieba 分词
string_eda = "遇到不幸,请先不要一味的抱怨,而是庆幸。"
cut_word_list = jieba.cut(string_eda)
cut_word_list = " ".join(cut_word_list)
cut_word_list = cut_word_list.split() # 得到了 一个切好词的列表
# 将切好词的列表进行复制存储
new_word_list = cut_word_list.copy()
# 去停用词
clean_word_list = [word for word in cut_word_list if word not in stop_word_list]
# 去重
clean_word_list = list(set(clean_word_list))
for word in clean_word_list:
synonym = get_synonyms(word)
if len(synonym) > 1:
# 对于生成的多个近义词,随机选取其中的一个
word_choice = random.choice(synonym)
# 利用原来存好的列表,进行近义词的替换
new_word_list_new = [word_choice if old_word == word else old_word for old_word in new_word_list]
seq = " ".join(new_word_list_new)
print(seq)
效果: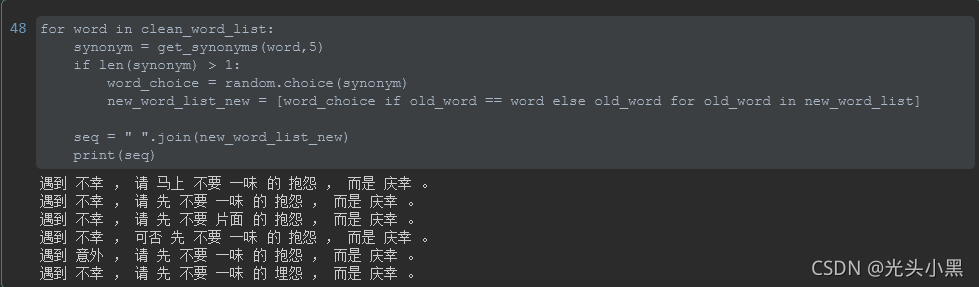
- 随机插入(不去停用词,直接随机选取词语,做近义词,进行插入操作)
# cut_word_list: 遇到 不幸 , 请 先 不要 一味 的 抱怨 , 而是 庆幸 。
# word_list:利用 jieba 切好词的一句话
# number:需要进行几次随机插入
def insert_word(word_list,number):
all_insert_word_list = [] # 存储随机插入的结果的列表
for i in range(number):
synonym = []
while len(synonym) == 0: # 判断这个词有没有相似词,如果没有就再随机选取词
random_word = word_list[random.randint(0,len(word_list) - 1)]
synonym = get_synonyms(random_word)
print(synonym)
random_synonyms_word = random.choice(synonym) # 随机对生成的相似词进行选择
rand_index = random.randint(0,len(word_list)-1)
word_list.insert(rand_index,random_synonyms_word) # 插入列表中
all_insert_word_list.append(" ".join(word_list))
return all_insert_word_list
print(" ".join(cut_word_list))
print(cut_word_list)
all_seq_list = insert_word(cut_word_list,number=5)
for seq in all_seq_list:
print(seq)
效果(看起来插入的位置都是相同的,是因为我在上面固定了随机种子,实际使用的时候可以去掉就 ok):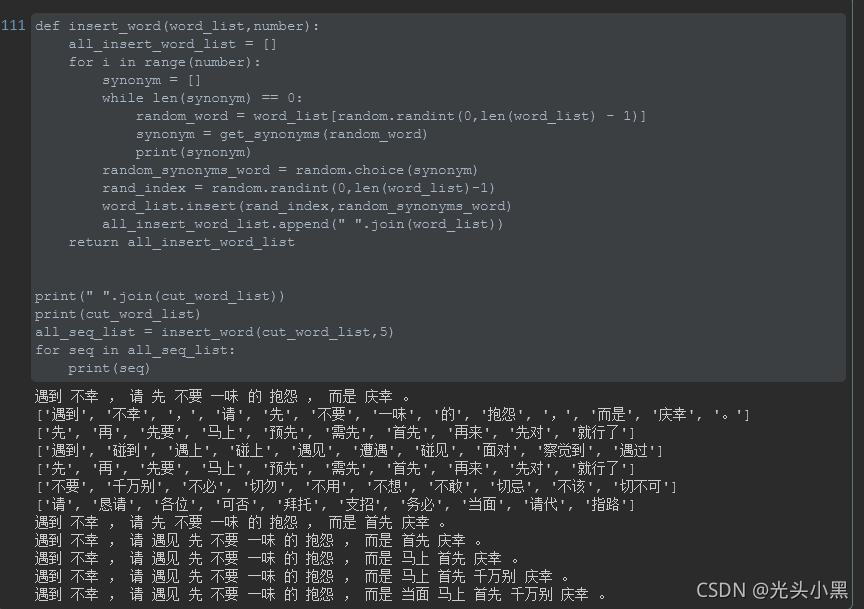
- 随机插入:
def swap_word(word_list,number):
swap_word_list = []
for i in range(number):
rand_index_1 = random.randint(0,len(word_list)-1)
rand_index_2 = random.randint(0,len(word_list)-1)
# 这块是为了防止两个随机的索引重复
while rand_index_1 == rand_index_2:
rand_index_2 = random.randint(0,len(word_list)-1)
word_list[rand_index_1],word_list[rand_index_2] = word_list[rand_index_2],word_list[rand_index_1]
swap_word_list.append(" ".join(word_list))
return swap_word_list
print("原始:",cut_word_list)
swap_list = swap_word(cut_word_list,5)
for seq in swap_list:
print("交换后:",seq)
效果: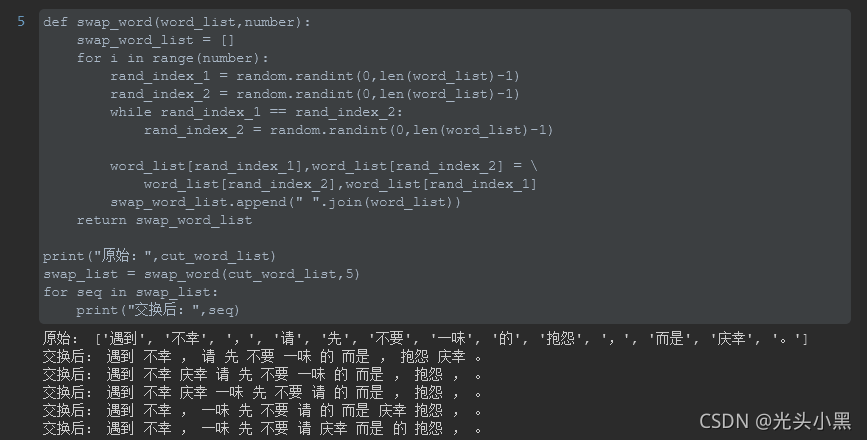
- 随机删除
# 这个函数主要实现了对切词列表的随机删除
# probability:这是删除的概率(可以自定义)
def word_random_del(word_list,probability=0.1):
# 判断切词列表的长度,如果小于等于 1 ,那还删啥啊,都没了,没法删除
if len(word_list) <= 1:
return word_list
# lucky_word:用来存储幸运的,被选出来的词语
lucky_word = []
for word in word_list:
pro = random.uniform(0,1) # 生成随机数(概率)
# 如果大于我们设定的概率,就拿出来,存到 lucky_word 中
if pro > probability:
lucky_word.append(word)
# 如果每个单词的点儿都很差,一个都没选出来,
# 那么就需要随机的在 切词列表 中选取 int(len(word_list)/0.8) 个词语(这个数值可以自定义,根据需要自己修改)
# 同时这个列表也是为了防止选出来的词语有重复的
random_number_list = []
if len(lucky_word) == 0:
for i in range(int(len(word_list)/0.8)):
random_number = random.randint(0, len(word_list)-1)
while random_number not in random_number_list:
random_number_list.append(random_number)
# 这一块用的是 索引直接插入的,也可以直接对列表进行 append ,不知道效果好不好,自己去尝试一下吧
# 不过一个词也没选出来的概率非常小,所以这种情况是为了万一,有可能你写了用不到
lucky_word.insert(random_number,word_list[random_number])
return lucky_word
print("原始:",cut_word_list)
swap_list = word_random_del(cut_word_list,0.1)
print("随机删除:",swap_list)
效果: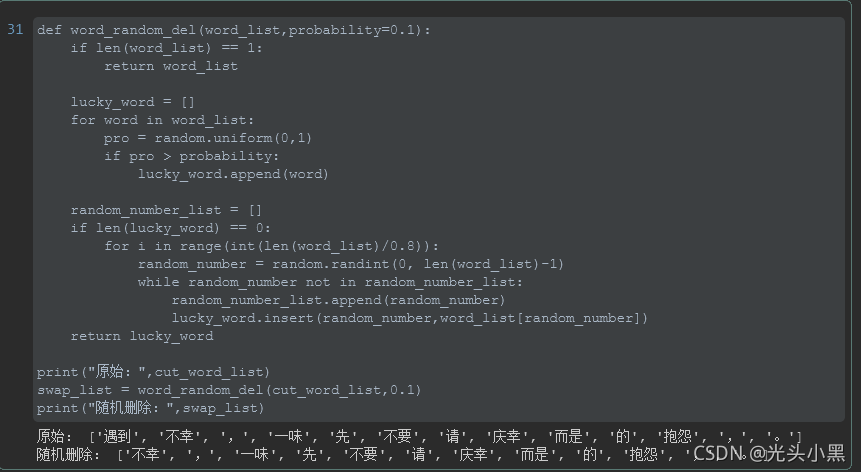

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)