
(动手学习深度学习)第7章 网络中的网络---NiN
NiN网络详解、代码实现
·
NiN
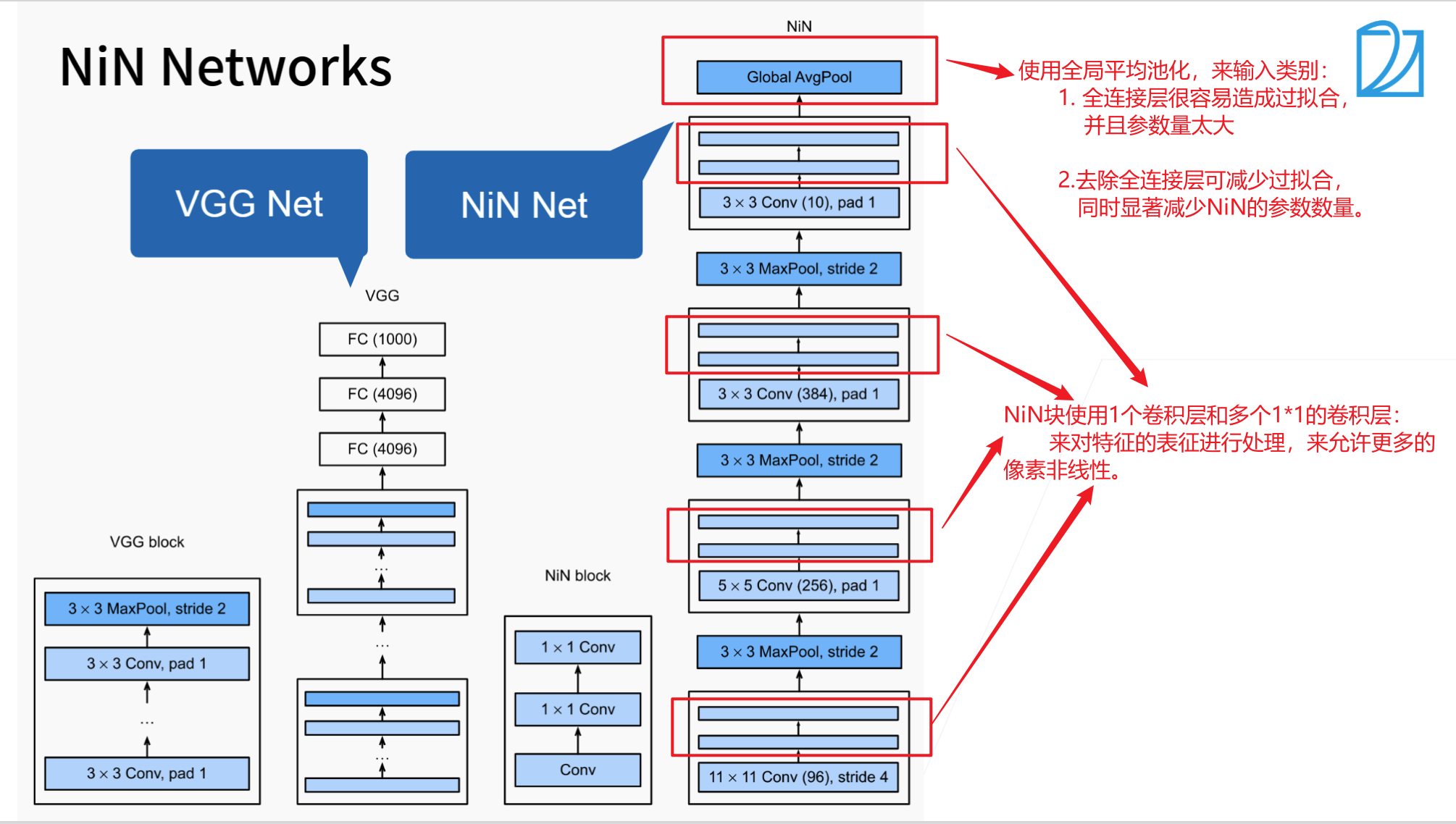
- LeNet、AlexNet、VGG 都有共同的设计模型:
- 通过一系列的卷积层与池化层,来提取网络结构特征;
- 然后通过全连接层,对特征的表征进行处理。
- 如果只使用全连接层,可能会完全放弃表征的空间结构,并且模型计算量很大。
- NiN的改进方案:
- NIN在每个像素的通道上分别使用多层感知机。
- 使用全局平均池化来代替全连接层,大大减少模型计算量。
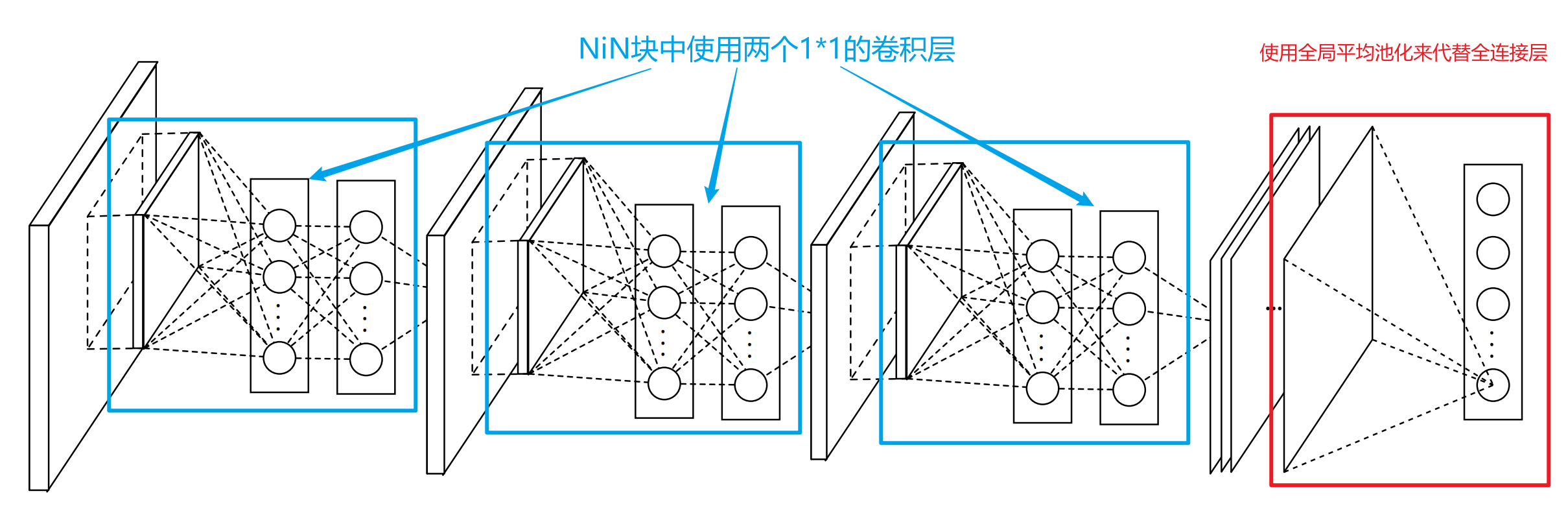


总结
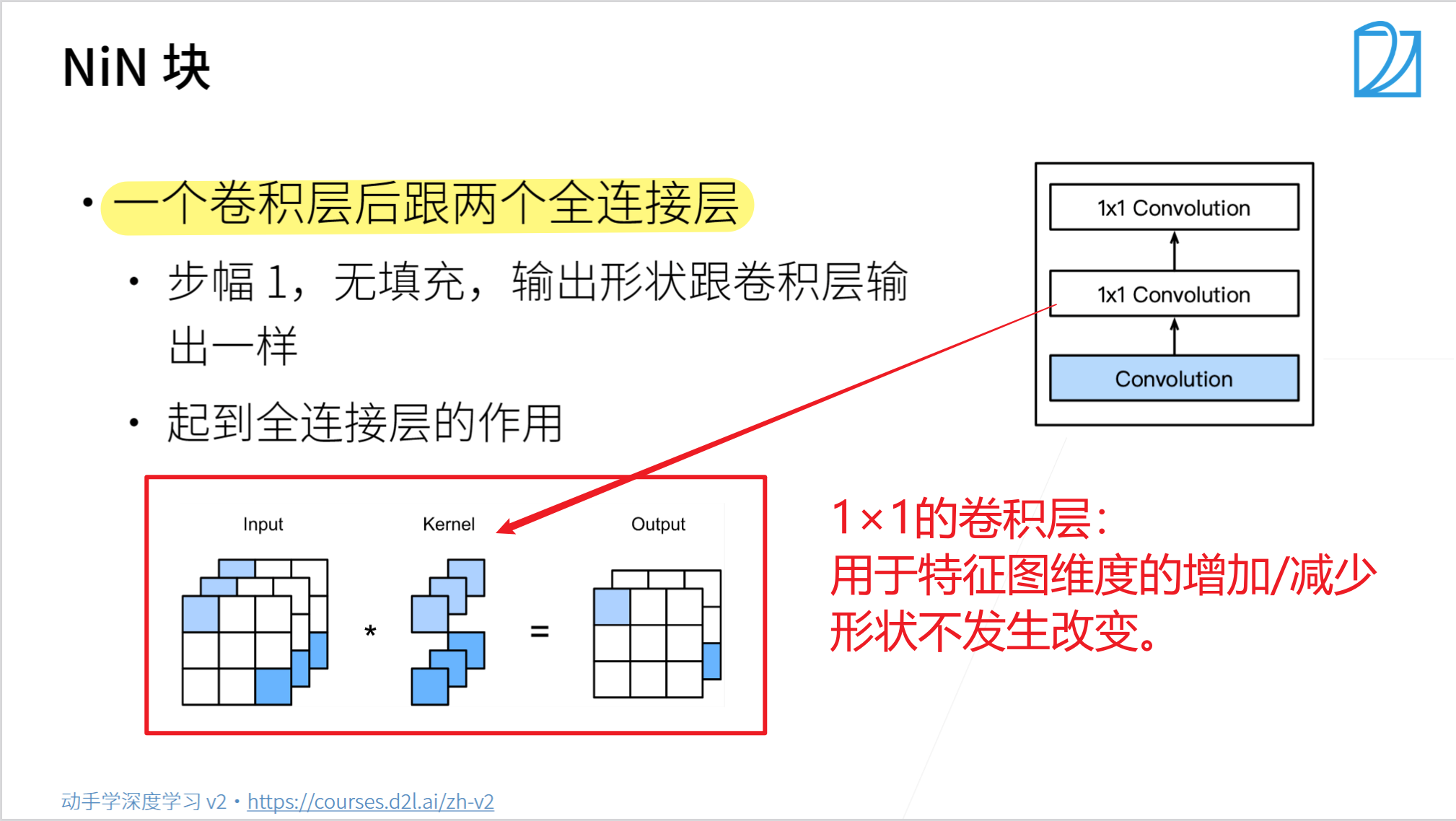
- NiN块使用卷积层加两个1x1卷积层,
- 后者对每个像素增加了非线性
- NiN使用全局平均池化层来替代VGG和AlexNet中的全连接层
- 不容易过拟合,更少的参数个数
NiN代码实现
- 导入相关库
import torch
from torch import nn
from d2l import torch as d2l
- 定义网络模型
# 定义NiN基本块
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU(),
)
# 定义NiN模型
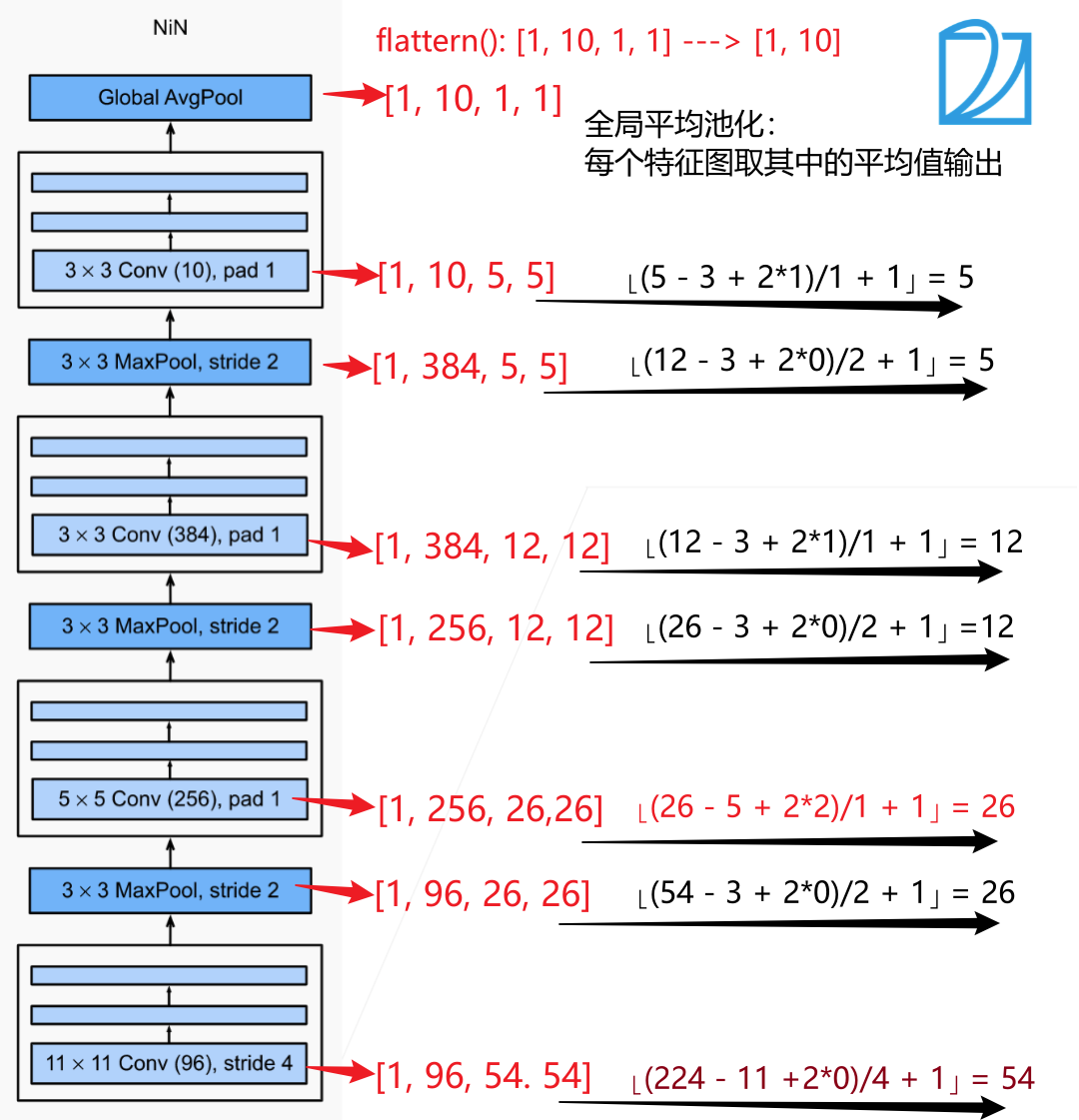
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0), # [1, 96, 54, 54]
nn.MaxPool2d(3, stride=2), # [1, 96, 26, 26]
nin_block(96, 256, kernel_size=5, strides=1, padding=2), # [1, 256, 26, 26]
nn.MaxPool2d(3, stride=2), # [1, 256, 12, 12]
nin_block(256, 384, kernel_size=3, strides=1, padding=1), # [1, 384, 12, 12]
nn.MaxPool2d(3, stride=2), # [1, 384, 5, 5]
nn.Dropout(0.5),
nin_block(384, 10, kernel_size=3, strides=1, padding=1), # [1, 10, 5, 5]
nn.AdaptiveAvgPool2d((1, 1)), # [1, 10, 1, 1]
nn.Flatten() # [1, 10*1*1] = [1, 10]
)
- 查看模型
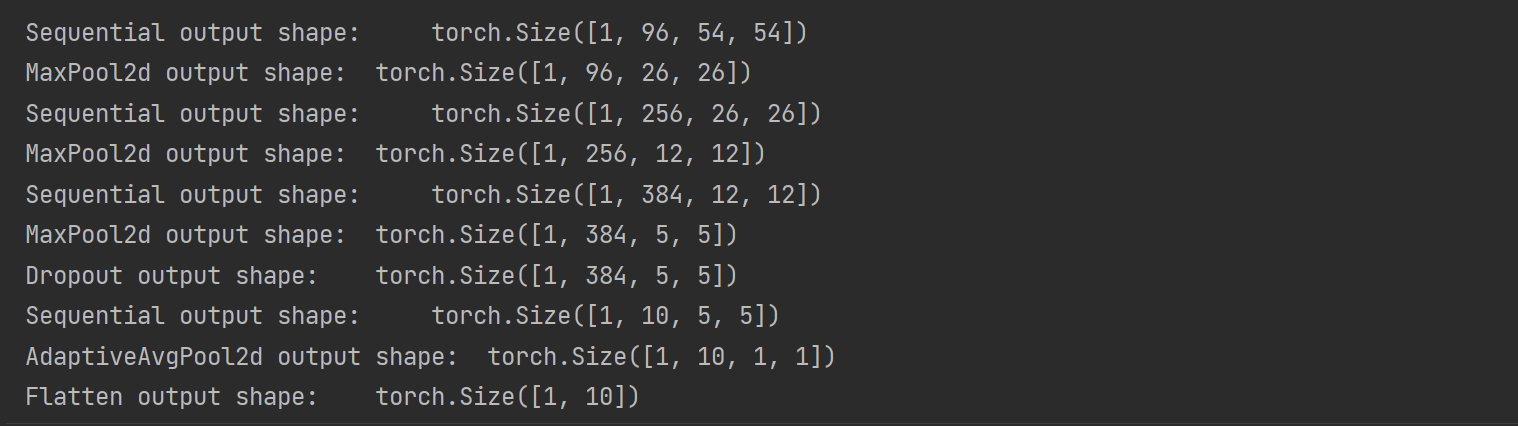
X =torch.rand(1, 1, 224, 224)
for layer in net:
X =layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
- 加载数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
- 训练模型
lr, num_epochs = 0.1, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
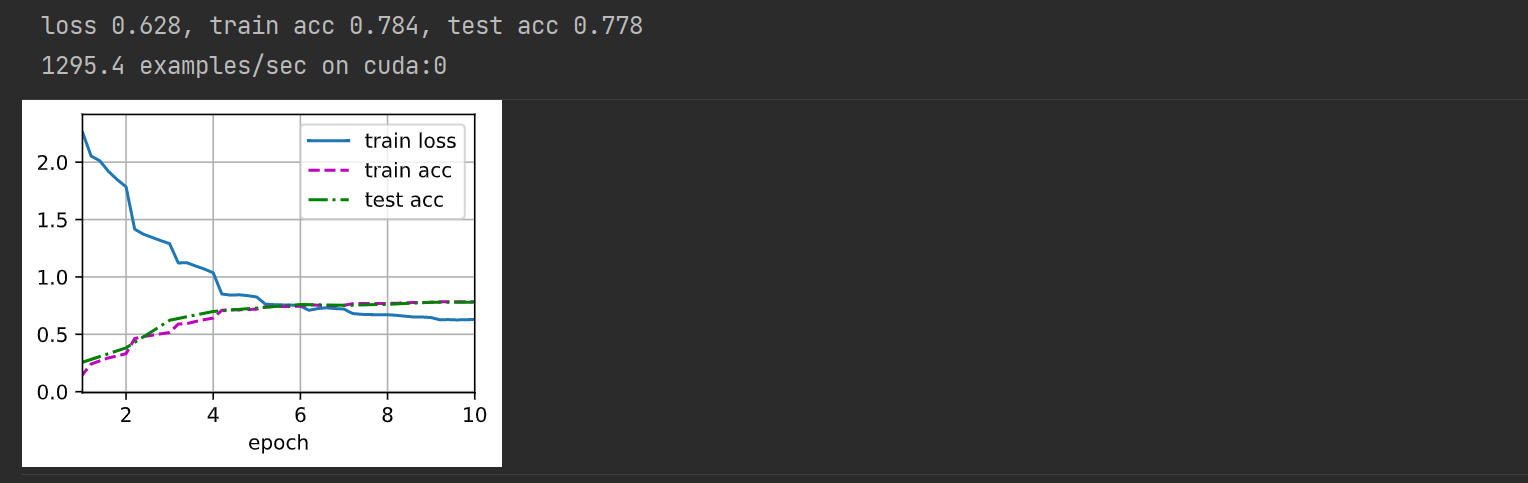
关于batch_size的疑问?
这里实验一开始将batch_size设为:
- batch_size=256,其余都没改
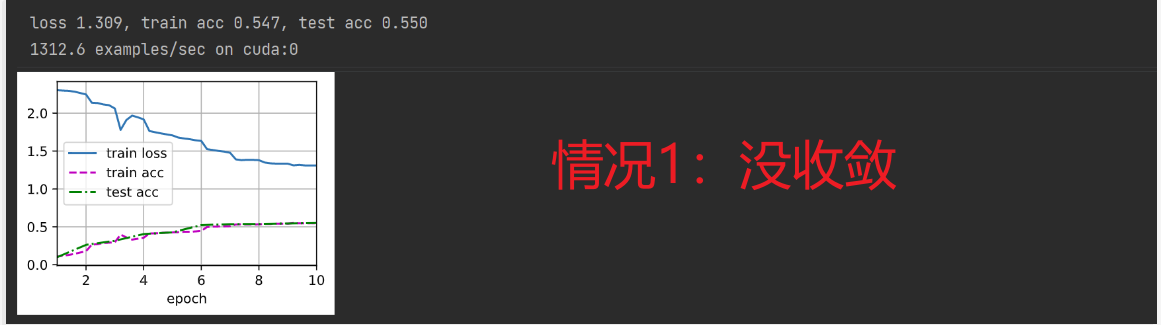
但是几次的实验结果却出乎意料,(其实出现了多种情况,并且大致有两种):
- 模型没收敛(个人觉得是batch size 调大,那么学习率lr也应该调大,或者将训练轮次epoch增加);
- 模型先收敛,最好是(train loss = 0.1, train_acc = 1.0, test acc = 1.0),然后在第5个epoch时, Train_loss突然升高,然后稳定(大概在2.5左右),train loss 和test loss 突然下降,然后稳定(在0.25左右)(很奇怪):
- 模型正常收敛,精度反而比之前要高。


然后进行将超参数修改为:
- batch_size = 256, num_epoches = 20, 其余都不变,(很奇怪,出现了跟第二种情况一样的结果)
- batch_size = 256, lr = 0.15, 其余都不变
发现模型仍然先收敛,然后欠拟合。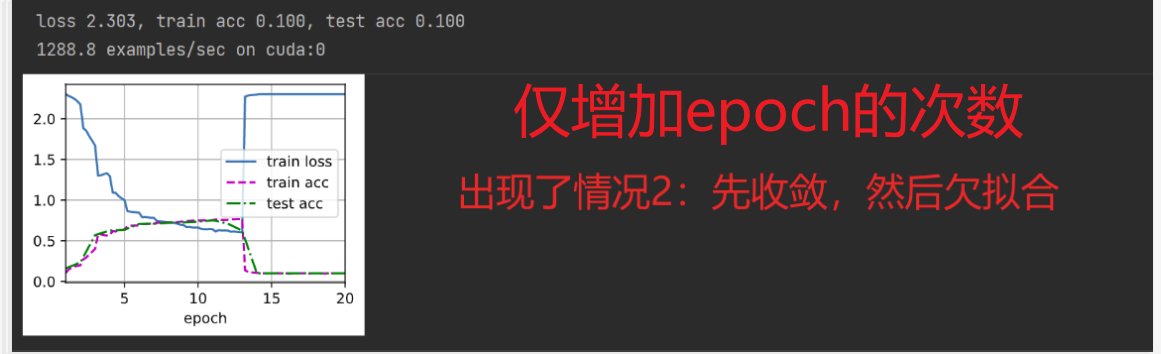

疑问?
batch_size不是越大越好吗?
网上的解释:
batch_size太小:
- 耗时长,训练效率低。
- 训练数据就会非常难收敛, 从而导致欠拟合。
batch_size太大:
- 大的batch_size减小训练时间,但是大的batch_size所需内存容量增加。
- 大的batch_size梯度计算更加稳定,但是可能会导致模型泛化能力下降。
网上的解决方案:
- batch size 的值越大,梯度也就越稳定,而 batch size 越小,梯度具有越高的随机性,但如果 batch size 太大,对于内存的需求就更高,同时也不利于网络跳出局部极小点。所以,需要设置一个合适的batchsize值,在训练速度和内存容量之间寻找到最佳的平衡点。
- 一般在Batchsize增加的同时,需要对所有样本的训练次数(epoch)增加(以增加训练次数达到更好的效果)这同样会导致耗时增加,因此需要寻找一个合适的batchsize值,在模型总体效率和内存容量之间做到最好的平衡。
- 个人理解就是多试几次, 像是在炼丹②由于上述两种因素的矛盾,batchsize增大到某个时候,达到时间上的最优。由于最终收敛精度会陷入不同的局部极值,因此batchsize增大到某些时候,达到最终收敛精度上的最优。
希望有大佬能帮忙解释一下,具体的batch_size的选择?

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)