
PYTHON银行机器学习:回归、随机森林、KNN近邻、决策树、高斯朴素贝叶斯、支持向量机SVM分析营销活动数据|数据分享...
全文下载链接:http://tecdat.cn/?p=26219该数据(查看文末了解数据获取方式)与银行机构的直接营销活动相关,营销活动基于电话。通常,需要与同一客户的多个联系人联系,以便访问产品(银行定期存款)是否会(“是”)或不会(“否”)订阅(点击文末“阅读原文”获取完整代码数据)。银行数据集我们的数据集描述y - 客户是否订阅了定期存款?(二进制:'是','否')相关视频我们的目标是选择最
全文下载链接:http://tecdat.cn/?p=26219
该数据(查看文末了解数据获取方式)与银行机构的直接营销活动相关,营销活动基于电话。通常,需要与同一客户的多个联系人联系,以便访问产品(银行定期存款)是否会(“是”)或不会(“否”)订阅(点击文末“阅读原文”获取完整代码数据)。
银行数据集
我们的数据集描述
y - 客户是否订阅了定期存款?(二进制:'是','否')
相关视频
我们的目标是选择最好的回归模型来让客户订阅或不订阅定期存款。我们将使用如下算法:
-
线性回归
-
随机森林回归
-
KNN近邻
-
决策树
-
高斯朴素贝叶斯
-
支持向量机
选择最佳模型的决定将基于:
-
准确性
-
过采样
数据准备
在本节中,我们加载数据。我们的数据有 45211 个变量。
输入变量:
银行客户数据
1 - 年龄(数字)
2 - 工作:工作类型(分类:'行政'、'蓝领'、'企业家'、'女佣'、'管理'、'退休'、'自雇'、'服务'、'学生'、'技术员'、'失业'、'未知')
3 - 婚姻:婚姻状况(分类:'离婚'、'已婚'、'单身'、'不详';注:'离婚'指离婚或丧偶)。
4 - 教育(分类:'基础4年'、'基础6年'、'基础9年'、'高中'、'文盲'、'专业课程'、'大学学位'、'未知')
5 - 违约:是否有违约的信贷?(分类: '没有', '有', '未知')
6-住房:是否有住房贷款?(分类: '否', '是', '未知')
7 - 贷款:有个人贷款吗?
8 - contact: 联系通信类型(分类:'手机', '电话')。
9 - 月:最后一次联系的年份月份(分类:'一月', '二月', '三月', ..., '十一月', '十二月')
10 - day\_of\_week:最后一次联系的星期(分类:'mon', 'tue', 'wed', 'thu', 'fri')
11 - 持续时间:最后一次联系的持续时间,以秒为单位(数字)。
12 - 活动:在这个活动期间为这个客户进行的接触次数(数字,包括最后一次接触)。
13 - pdays: 在上次活动中最后一次与客户联系后的天数(数字,999表示之前没有与客户联系)。
14 - 以前:在这次活动之前,为这个客户进行的接触次数(数字)。
15 - 结果:上次营销活动的结果(分类:"失败"、"不存在"、"成功")。
社会和经济背景属性
16 - emp.var.rate:就业变化率--季度指标(数值)。
17 - cons.price.idx:消费者价格指数--月度指标(数值)。
18 - cons.conf.idx:消费者信心指数--月度指标(数字)。
19 - euribor3m:银行3个月利率--每日指标(数值)
20 - nr.employed: 雇员人数 - 季度指标(数字)
输出变量(所需目标):
-
y - 客户是否认购了定期存款?(二进制: '是', '否')
data.head(5)
我们的下一步是查看变量的形式以及是否存在缺失值的问题。
df1 = data.dtypes
df1
df2 = data.isnull().sum()
df2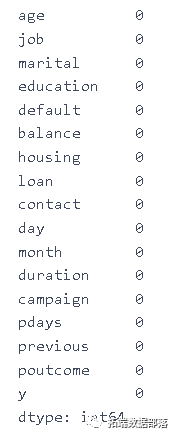
我们的下一步是计算所有变量的值。
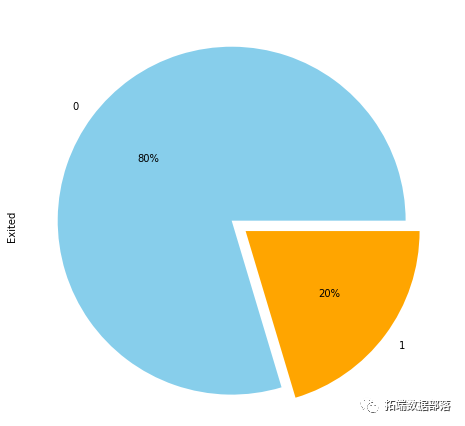
data\['y'\].value_counts()
data\['job'\].value_counts()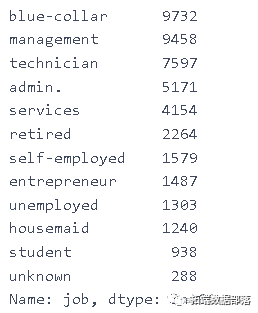
data\['marital'\].value_counts()
data\['education'\].value_counts()
data\['housing'\].value_counts()
data\['loan'\].value_counts()
data\['contact'\].value_counts()
data\['month'\].value_counts()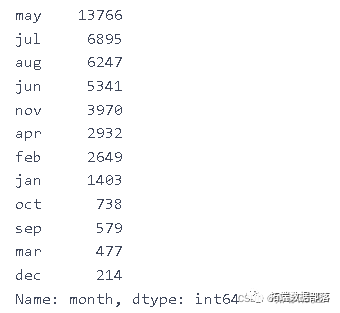
data\['poutcome'\].value_counts()
描述性统计
数值总结
data.head(5)
改变因变量 y 的值。代替 no - 0 和代替 yes - 1。
data\['y'\] = data\['y'\].map({'no': 0, 'yes': 1})data.columns
对于我们的每个变量,我们绘制一个箱线图来查看是否有任何可见的异常值。
plt.figure(figsize=\[10,25\])
ax = plt.subplot(611)
sns.boxplot(data\['age'\],orient="v")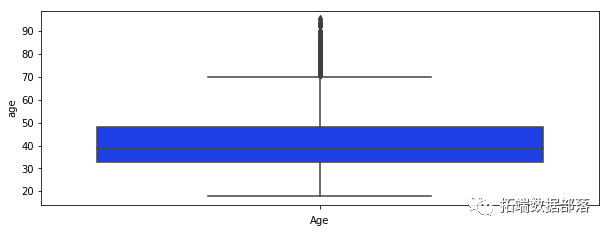
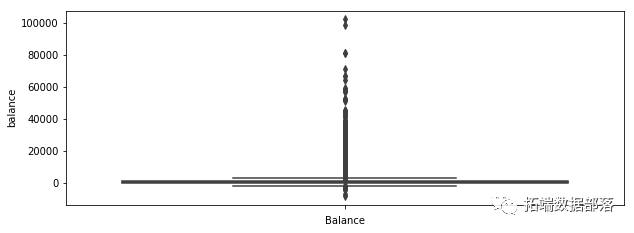
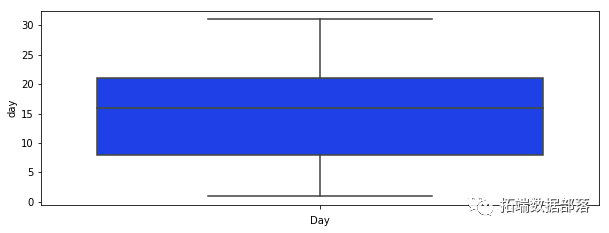
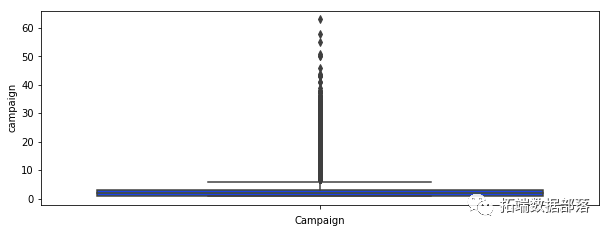
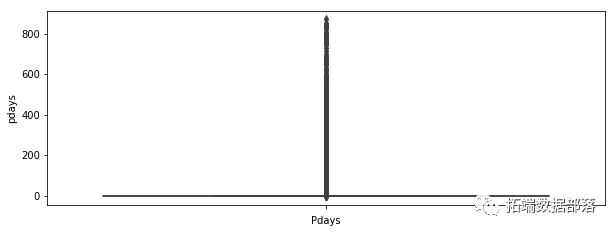
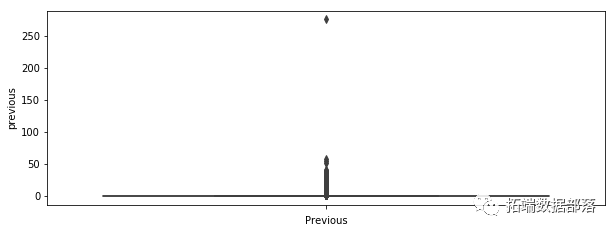
我们可以看到许多可见的异常值,尤其是在 balance 、 campaign 、 pdays 的情况下。在 pdays ,我们可以看到很多变量都在分位数范围之外。这个变量是一个特例,它被解码为 -1,这就是我们的图看起来像这样的原因。在表示变量之前的箱线图的情况下,它表示在此活动之前执行的联系数量,在这种情况下,我们还可以注意到许多超出分位数范围的值。
直方图
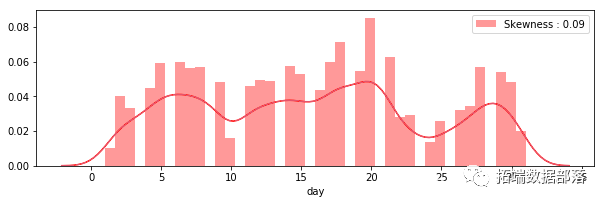
我们的下一步是查看连续变量的分布和直方图
我们可以看到没有一个变量具有正态分布。
plt.figure(figsize=\[10,20\])
plt.subplot(611)
g = sns.distplot(data\["age"\], color="r")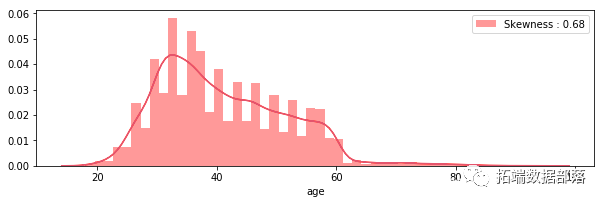




我们的下一步是查看因变量 y 与每个变量或连续变量之间的关系。
g = sns.FacetGrid(data, col='y',size=4)
g.map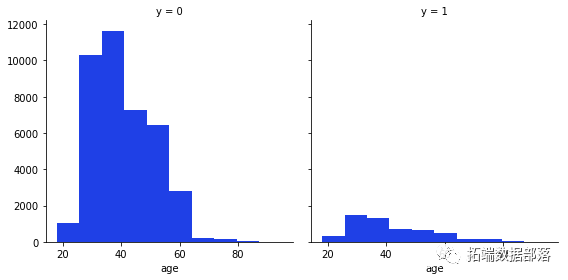
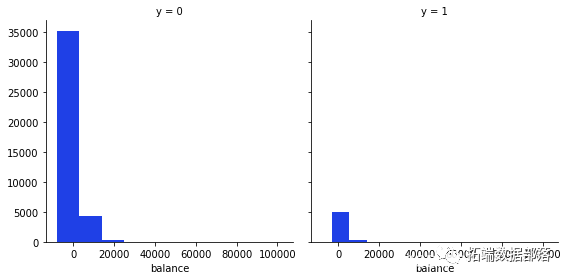
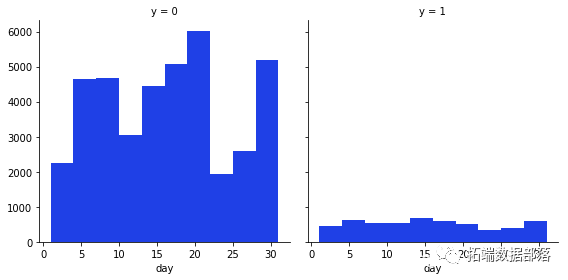
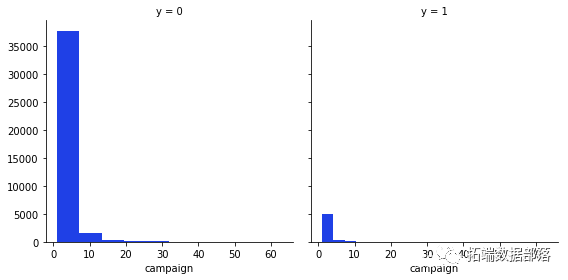
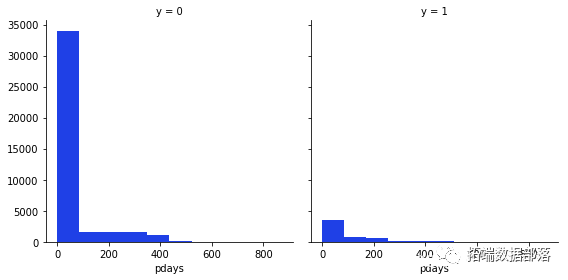
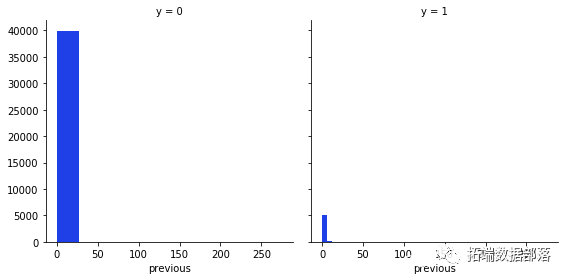
从这些变量中我们可以得到的最有趣的观察是,大多数说不的人年龄在20-40岁之间,在月底的第20天,大多数人也拒绝了这个提议。
分类总结
我们制作仅包含分类变量的数据子集,以便更轻松地绘制箱线图
data_categorical = data\[\['job',
'marital',
'education',
'default', 'housing',
'loan','month', 'y'\]\]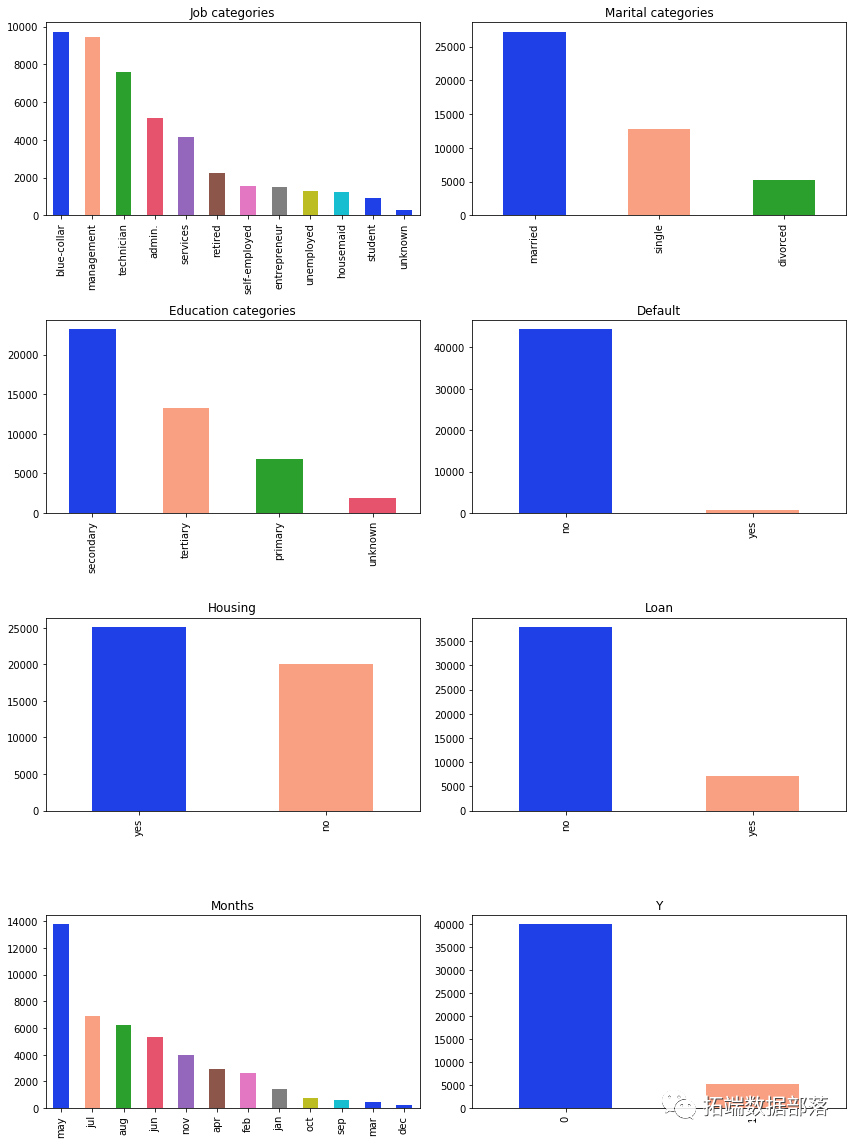
我们还查看了分类变量,看看是否有一些有趣的特征
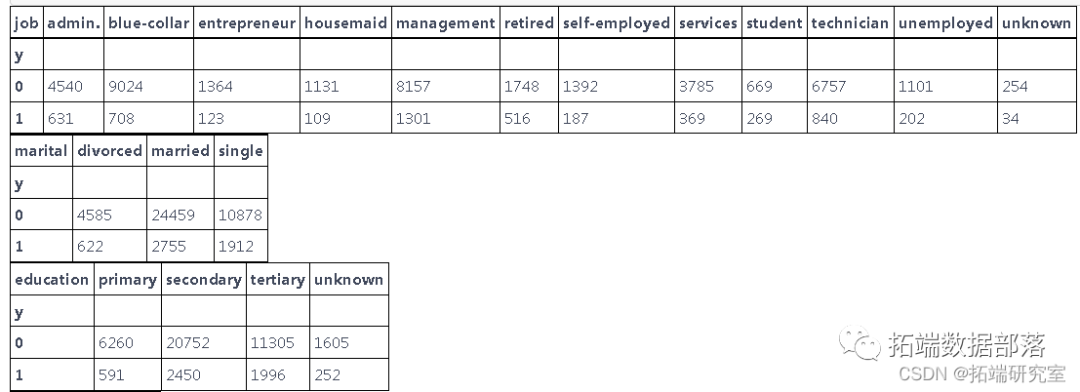
从上面的条形图中可以看出,最有趣的结果来自变量:婚姻状况、教育和工作。
从代表婚姻状况的图表来看,大多数人都已婚。
正如我们在代表教育的图表上看到的那样 - 最大的是接受过中等教育的人数。
在约伯的情况下,我们可以看到大多数人都有蓝领和管理工作。
我们还想在马赛克图上查看我们的分类变量与 y 变量之间的关系。
plt.rcParams\['font.size'\] = 16.0
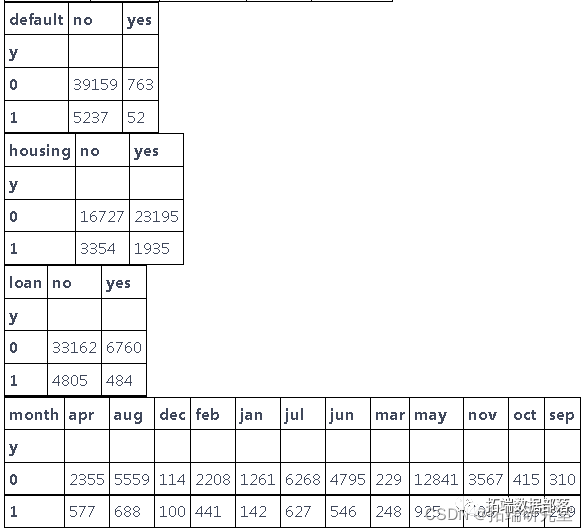
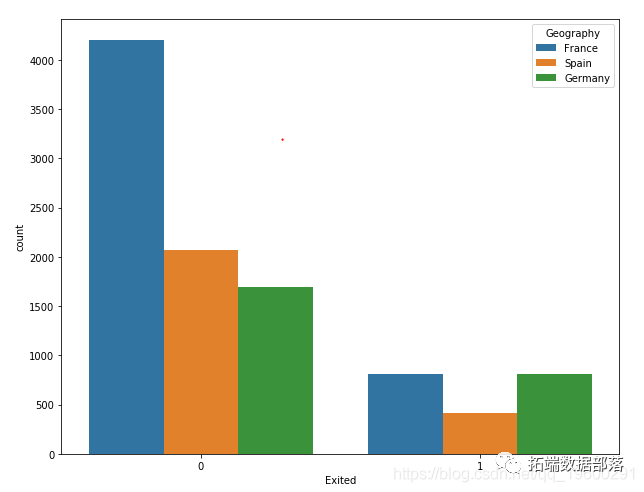
正如我们所见,大多数人都拒绝了该提议。就地位而言,已婚的人说“不”最多。
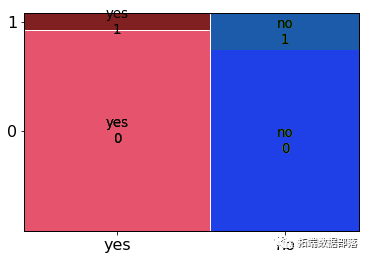
在可变违约的情况下,大多数没有违约信用的人也拒绝了该提案。
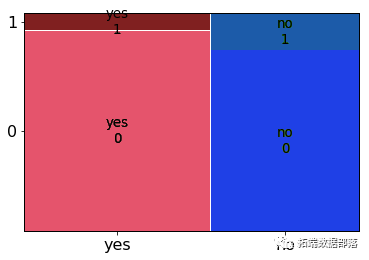
大多数有住房贷款的人也拒绝了该提议。
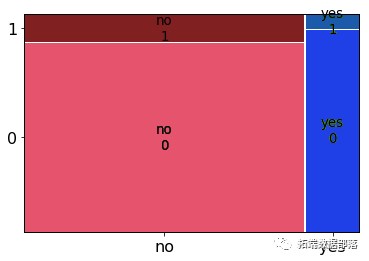
大多数没有贷款的人拒绝了这个提议。
点击标题查阅往期内容


左右滑动查看更多
01
02
03
04
数据挖掘
data.head(5)
我们想更深入地研究我们的变量,看看我们是否可以用它们做更多的事情。
我们的下一步是使用 WOE 分析。
finv, IV = datars(data,data.y)
IV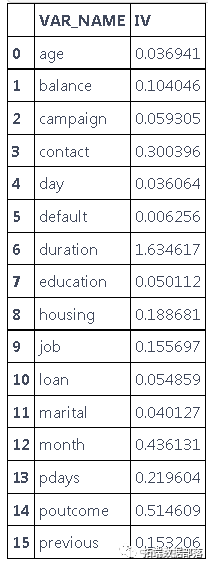
基于对我们有用的 WOE 分析变量是:pdays、previous、job、housing、balance、month、duration、poutcome、contact。
在下一步中,我们决定根据 WOE 结果和变量的先前结果删除无用的列。
我们删除的其中一个列是 poutcome,尽管它的 WOE 很高,但我们决定删除它,因为从 prevois 分析中我们看到它有许多未知的观察结果。
在可变持续时间的情况下,我们也可以看到WOE相当大,甚至可以说这个结果有点可疑。我们决定根据 WOE 结果放弃它,因为我们的模型应该根据过去的数据说明是否建议给某个人打电话。
在可变接触的情况下,我们放弃了它,因为对我们来说,接触形式在我们的模型中没有用。
我们还删除了变量 day 因为它对我们没有用,因为这个变量代表天数,而该变量的 WOE 非常小。我们删除的最后一个变量是变量 pdays,尽管这个变量 WOE 的结果非常好,但它对我们来说并不是一个有用的变量。
我们分析中剩下的列:

特征选择和工程
要执行我们的算法,我们首先需要将字符串更改为二进制变量。
data = pd.get_dummies(data=data, columns = \['job', 'marital', 'education' , 'month'\], \
prefix = \['job', 'marital', 'education' , 'month'\])
我们更改了列的名称。
data.head(5)
创建虚拟变量后,我们进行了 Pearson 相关。
age = pearsonr(data\['age'\], data\['y'\])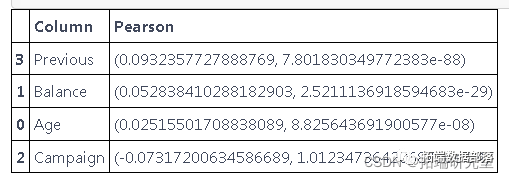
sns.heatmap(corr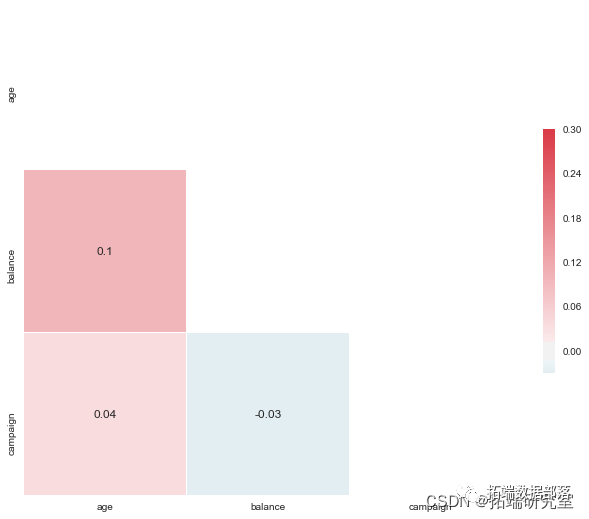
我们选择了数字列来检查相关性。正如我们所看到的,没有相关性。
我们查看因变量和连续变量之间的关系。
pylab.show()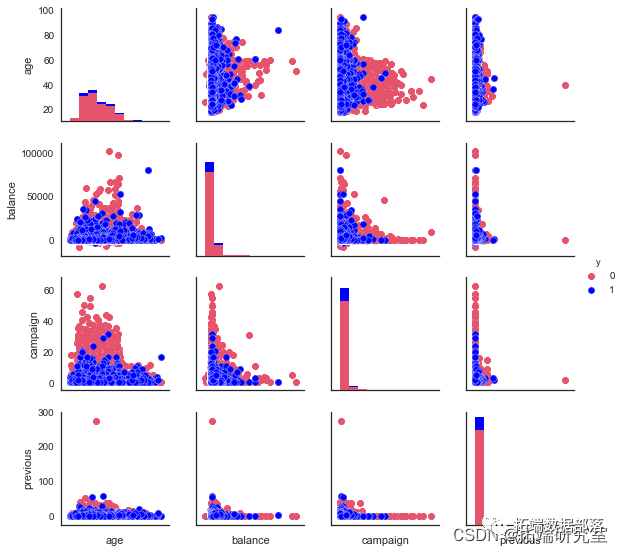
交叉验证
经过所有准备工作,我们终于可以将数据集拆分为训练集和测试集。
算法的实现
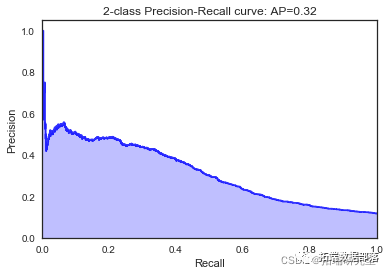
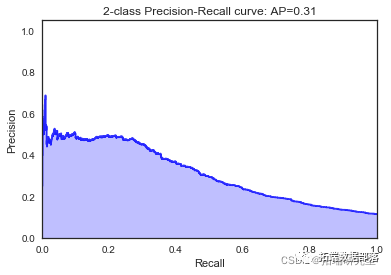
逻辑回归
K=5
kf = KFold(n_splits=K, shuffle=True)
logreg = LogisticRegression()\[\[7872 93\]
\[ 992 86\]\]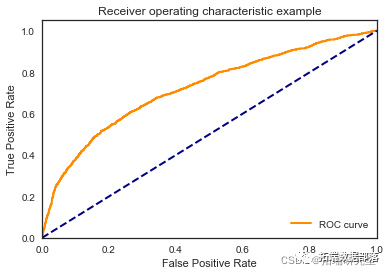
\[\[7919 81\]
\[ 956 86\]\]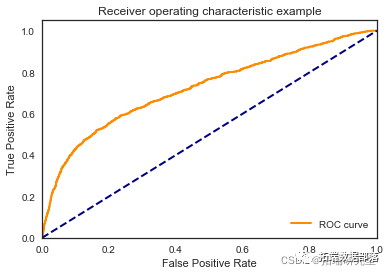
\[\[7952 60\]
\[ 971 59\]\]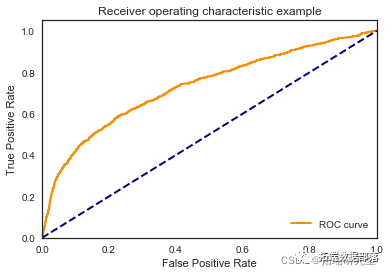
\[\[7871 82\]
\[1024 65\]\]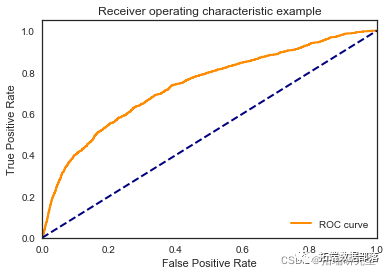
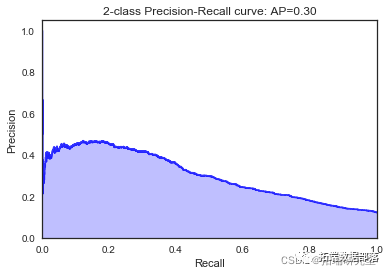
\[\[7923 69\]
\[ 975 75\]\]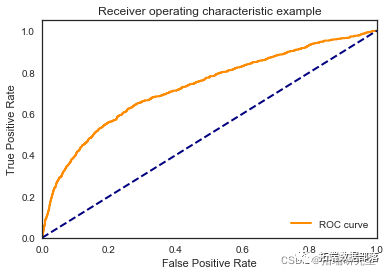
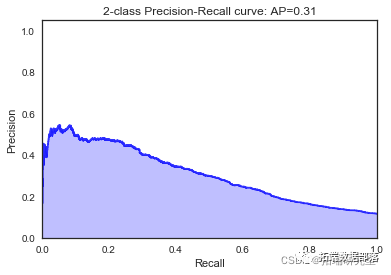
决策树
dt2 = tree.DecisionTreeClassifier(random\_state=1, max\_depth=2)\[\[7988 0\]
\[1055 0\]\]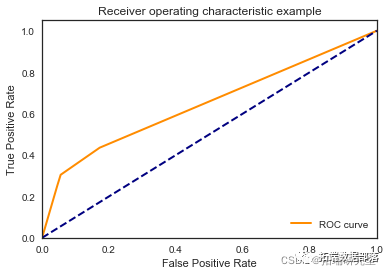
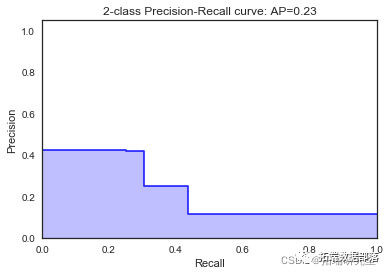
\[\[7986 0\]
\[1056 0\]\]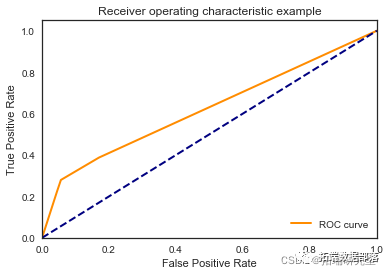
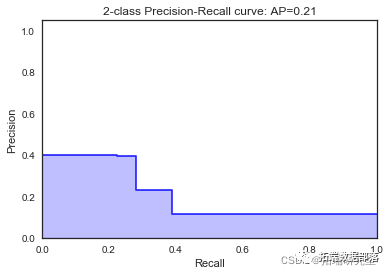
\[\[7920 30\]
\[1061 31\]\]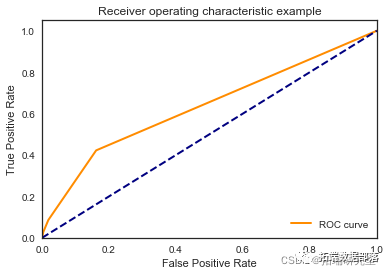
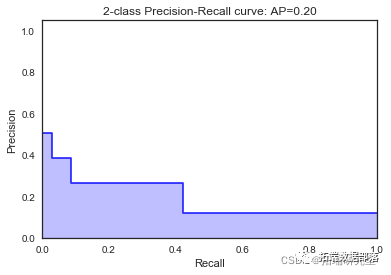
\[\[8021 0\]
\[1021 0\]\]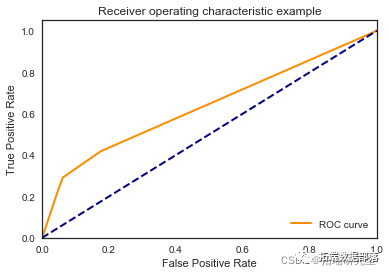
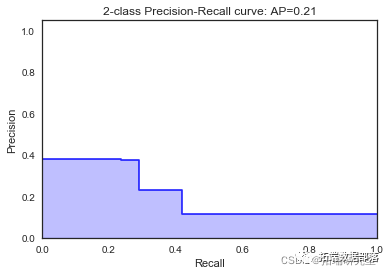
\[\[7938 39\]
\[1039 26\]\]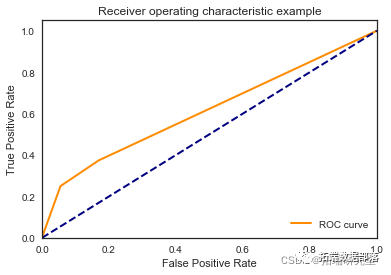
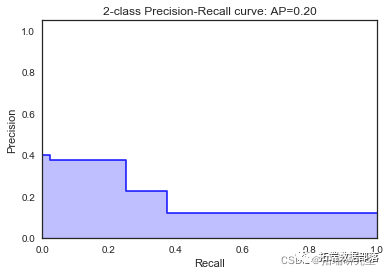
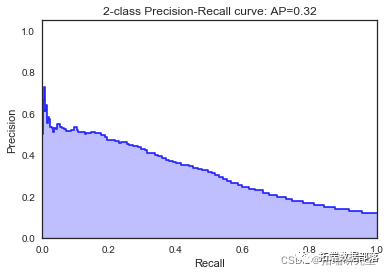
随机森林
random_forest = RandomForestClassifier\[\[7812 183\]
\[ 891 157\]\]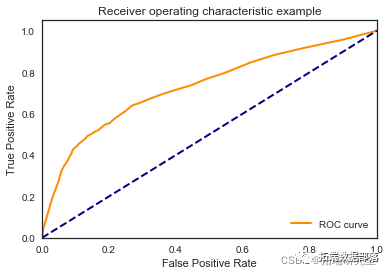
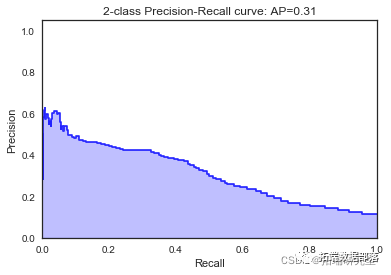
\[\[7825 183\]
\[ 870 164\]\]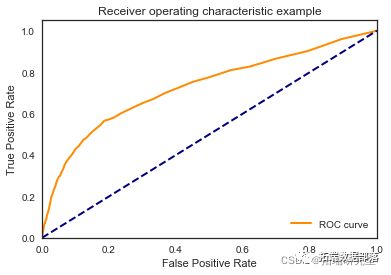
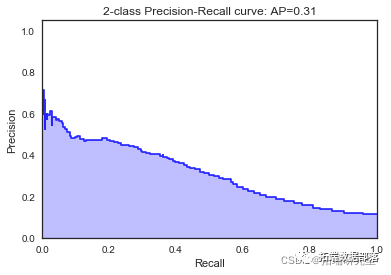
\[\[7774 184\]
\[ 915 169\]\]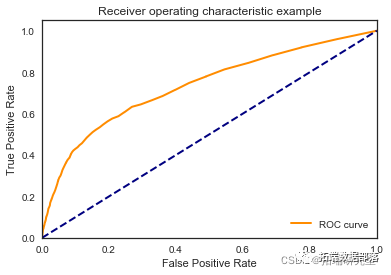
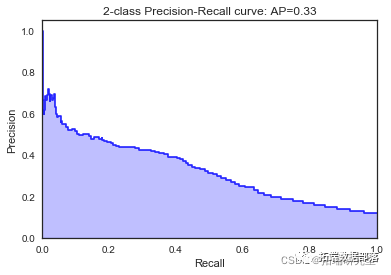
\[\[7770 177\]
\[ 912 183\]\]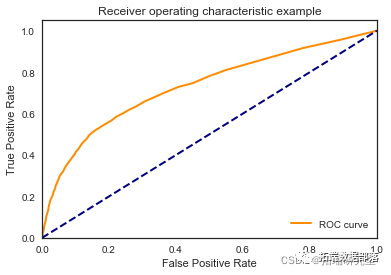
\[\[7818 196\]
\[ 866 162\]\]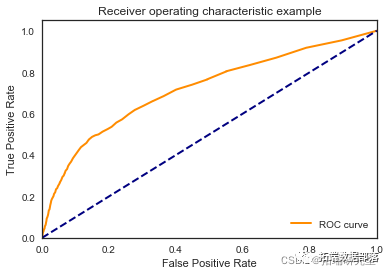
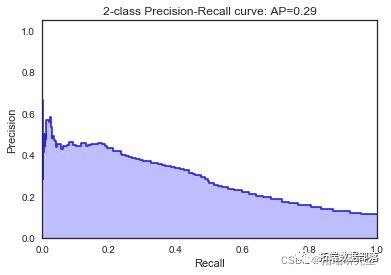
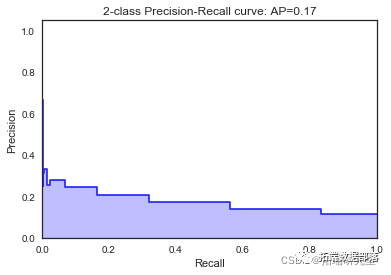
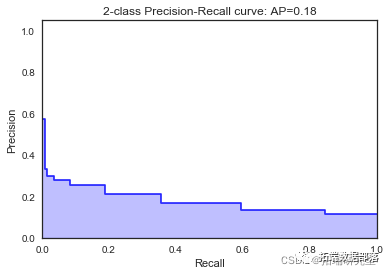
KNN近邻
classifier = KNeighborsClassifier(n_neighbors =13,metric = 'minkowski' , p=2)
print("Mean accuracy: ",accuracyknn/K)
print("The best AUC: ", bestaucknn)\[\[7952 30\]
\[1046 15\]\]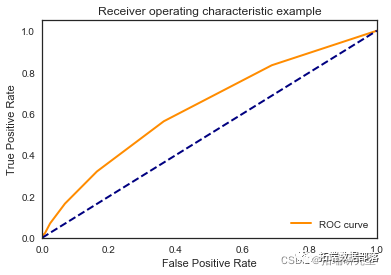
\[\[7987 30\]
\[1010 15\]\]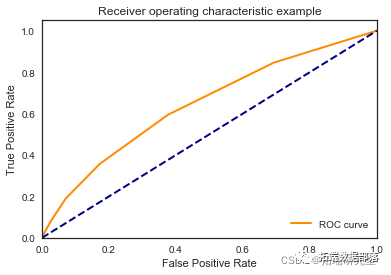
\[\[7989 23\]
\[1017 13\]\]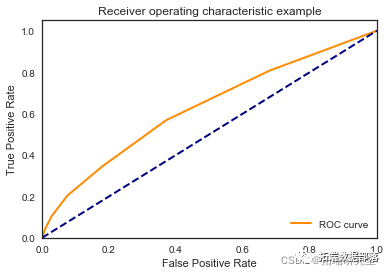
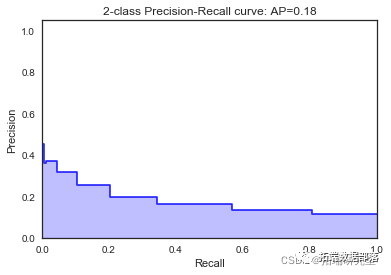
\[\[7920 22\]
\[1083 17\]\]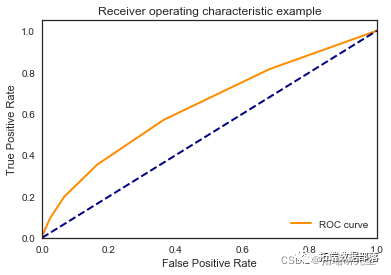
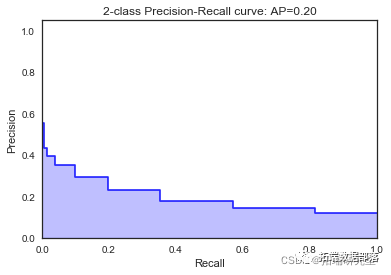
\[\[7948 21\]
\[1052 21\]\]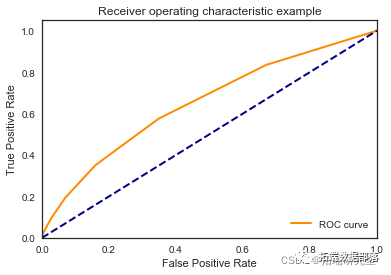
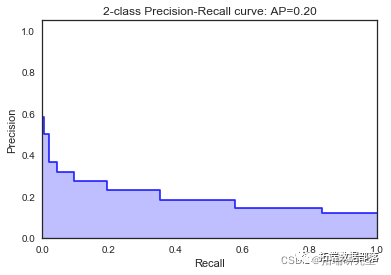
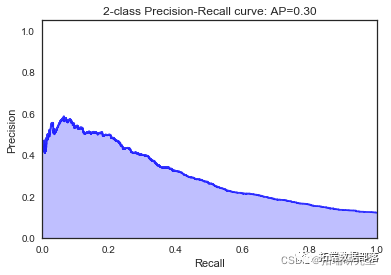
高斯朴素贝叶斯
kf = KFold(n_splits=K, shuffle=True)
gaussian = GaussianNB()\[\[7340 690\]
\[ 682 331\]\]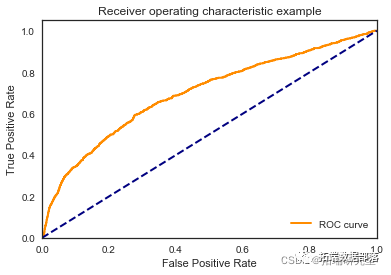
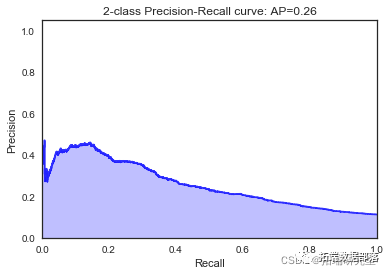
\[\[7321 633\]
\[ 699 389\]\]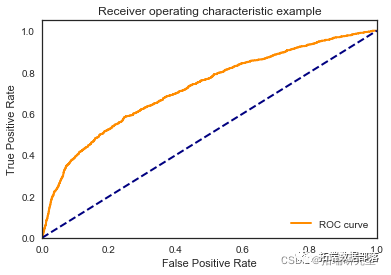
\[\[7291 672\]
\[ 693 386\]\]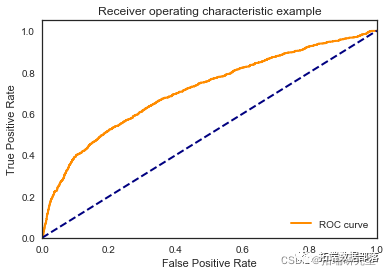
\[\[7300 659\]
\[ 714 369\]\]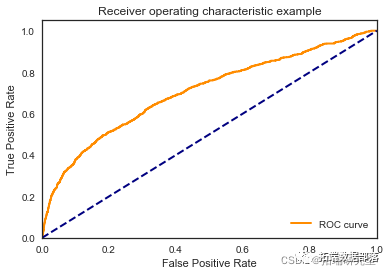
\[\[7327 689\]
\[ 682 344\]\]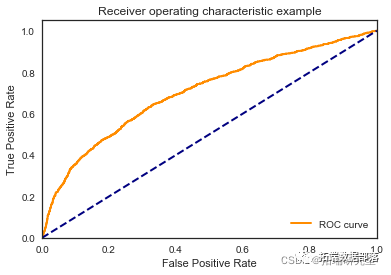
``````
models = pd.DataFrame({
'Model': \['KNN', 'Logistic Regression',
'Naive Bayes', 'Decision Tree','Random Forest'\],
'Score': \[ accuracyknn/K, accuracylogreg/K,
accuracygnb/K, accuracydt/K, accuracyrf/K\],
'BestAUC': \[bestaucknn,bestauclogreg,bestaucgnb,
bestaucdt,bestaucrf\]})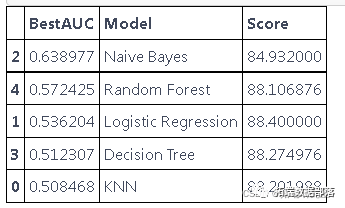
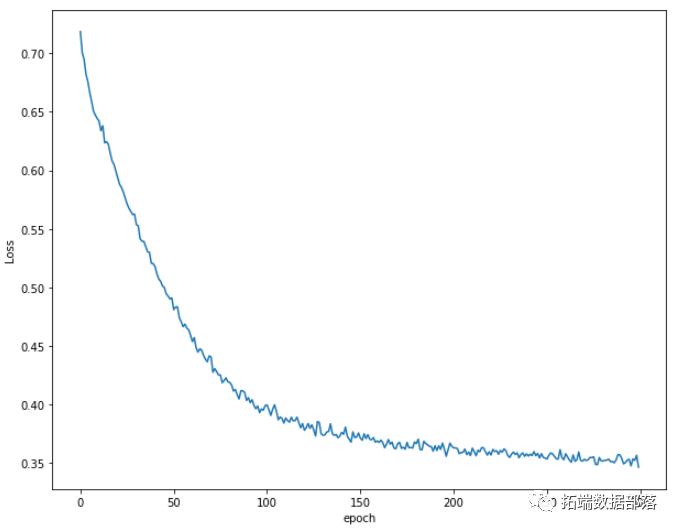
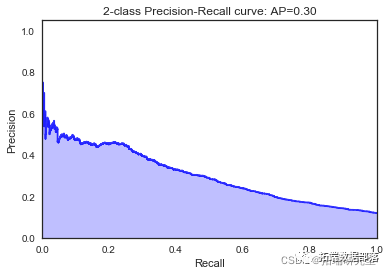
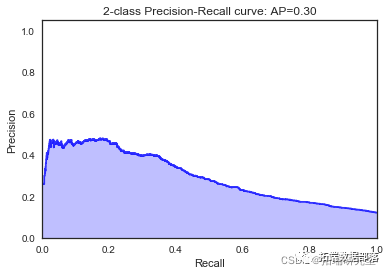
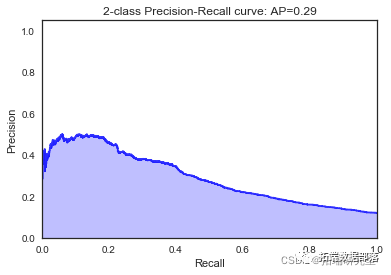
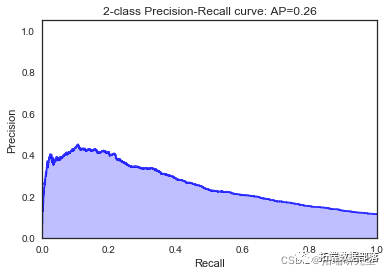
我们看到根据 AUC 值的最佳模型是朴素贝叶斯我们不应该太在意最低的 R2 分数,因为数据非常不平衡(很容易预测 y=0)。在混淆矩阵中,我们看到它预测了漂亮的价值真正值和负值。令我们惊讶的是,决策树的 AUC 约为 50%。
欠采样
我们尝试对变量 y=0 进行欠采样
gTrain, gValid = train\_test\_split
逻辑回归
predsTrain = logreg.predict(gTrainUrandom)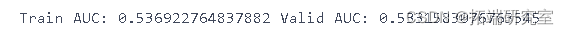
predsTrain = logreg.predict(gTrain20Urandom)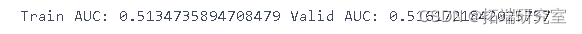
predsTrain = logreg.predict(gTrrandom)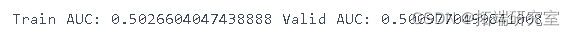
决策树
print("Train AUC:", metrics.roc\_auc\_score(ygTrds))
随机森林
print("Train AUC:", metrics.roc\_auc\_score(ygTr, predsTrain),
"Valid AUC:", metrics.roc\_auc\_score(ygVd, preds))
KNN近邻
print("Train AUC:", metrics.roc\_auc\_score(ygTrm, predsTrain),
"Valid AUC:", metrics.roc\_auc\_score(ygVal10, preds))
高斯朴素贝叶斯
print("Train AUC:", metrics.roc\_auc\_score(ygTraom, predsTrain),
"Valid AUC:", metrics.roc\_auc\_score(ygid, preds))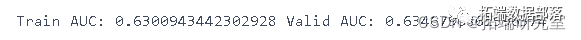
过采样
我们尝试对变量 y=1 进行过采样
feates = datolist()
print(feures)
feaes.remove('y')
print(gTrainOSM.shape)(31945, 39)
``````
smt = SMOT(32345, 39)
``````
smt = SMOT(32595, 39)
``````
ygTrain10OSM=gTrain10OSM\['y'\]
gTrain10OSM=gTrain10OSM.drop(columns=\['y'\])逻辑回归
print("Train AUC:", metrics.roc\_auc\_score(ygTrin10SM, predsTrain),
"Valid AUC:", metrics.roc\_auc\_score(ygValid, preds))
决策树
dt2.fit(,ygTranOS)
predsTrain = dtpreict(TrainOSM)
preds = dt2.predict(gValid)
随机森林
random_forest.fit(rainOSM, ygTranOS)
predsTrain = random_forest.prect(gTraiOSM)
p
KNN近邻
classifier.fit(granOSM, yTanOSM)
predsTrain = classifier.predict(gTaiSM)
preds = classifier.predict(Vaid)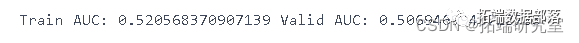
高斯朴素贝叶斯
gaussian.fit(gTriOM, ygrainM)
predsTrain = gaussian.predcti)
结论
我们看到欠采样和过采样变量 y 对 AUC 没有太大帮助。
数据获取
在下面公众号后台回复“银行数据”,可获取完整数据。

本文摘选《PYTHON银行机器学习:回归、随机森林、KNN近邻、决策树、高斯朴素贝叶斯、支持向量机SVM分析营销活动数据》,点击“阅读原文”获取全文完整资料。

本文中的银行数据分享到会员群,扫描下面二维码即可加群!


点击标题查阅往期内容
R语言用FNN-LSTM假近邻长短期记忆人工神经网络模型进行时间序列深度学习预测4个案例
Python中TensorFlow的长短期记忆神经网络(LSTM)、指数移动平均法预测股票市场和可视化
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类

![]()


技术共进,成长同行——讯飞AI开发者社区
更多推荐



 0
0 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)