
DeepSeek-Coder-V2:开源代码智能新标杆,比肩GPT-4 Turbo,上下文长度飙升至128K!
近年来,代码人工智能领域取得了显著进展,但闭源模型如GPT-4 Turbo、Claude 3 Opus和Gemini 1.5 Pro一直占据着领先地位。如今,DeepSeek-AI自豪地推出了,一个强大的开源混合专家 (MoE) 代码语言模型,旨在弥补这一差距,甚至在特定任务中超越这些顶尖闭源模型。DeepSeek-Coder-V2不仅在性能上实现了重大突破,还以其开源特性和强大的功能组合,为开发
近年来,代码人工智能领域取得了显著进展,但闭源模型如GPT-4 Turbo、Claude 3 Opus和Gemini 1.5 Pro一直占据着领先地位。如今,DeepSeek-AI自豪地推出了 DeepSeek-Coder-V2,一个强大的开源混合专家 (MoE) 代码语言模型,旨在弥补这一差距,甚至在特定任务中超越这些顶尖闭源模型。
目录
DeepSeek-Coder-V2不仅在性能上实现了重大突破,还以其开源特性和强大的功能组合,为开发者和研究者社区带来了前所未有的机遇。
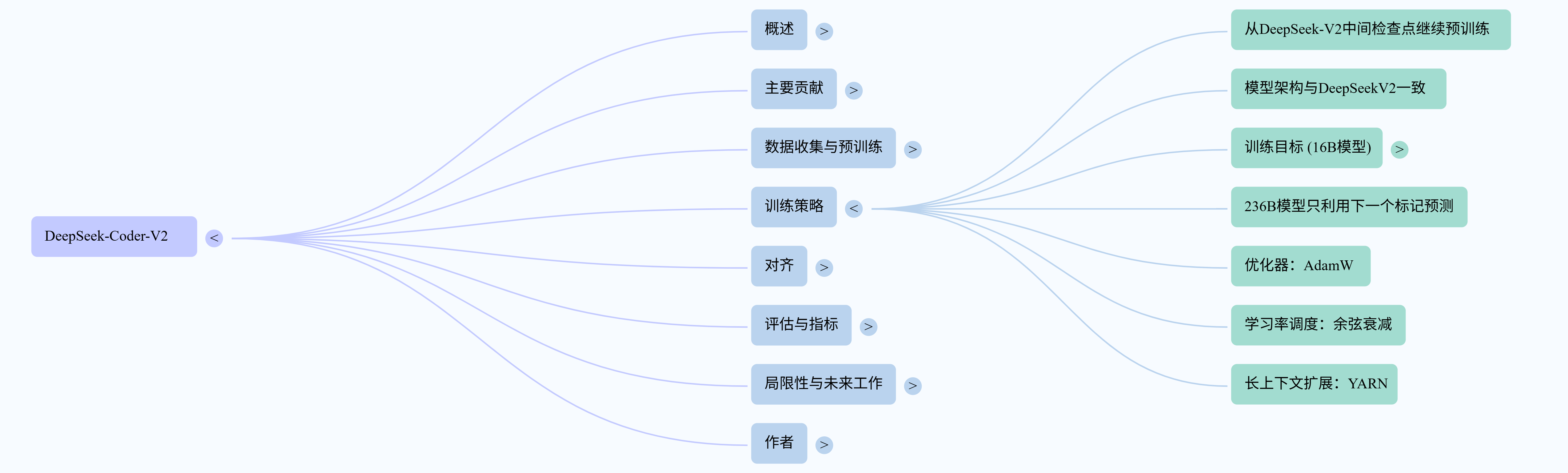
一、核心亮点:开源与卓越性能的结合
DeepSeek-Coder-V2基于DeepSeek-V2的中间检查点,并在此基础上进行了进一步的预训练,额外使用了 6万亿个token 的数据。这使得模型的总训练token量达到了 10.2万亿,其中4.2万亿来自DeepSeek-V2数据集,其余6万亿来自DeepSeek-Coder-V2数据集。
该模型的预训练数据集经过精心设计,由以下部分组成:
- 60% 源代码:涵盖了令人惊叹的 338种编程语言,远超DeepSeek-Coder原先的86种,并且包含来自GitHub和CommonCrawl的1.17万亿个代码相关token。
- 10% 数学语料库:规模约为DeepSeekMath语料库的两倍,包含2210亿个数学相关token。
- 30% 自然语言语料库:直接从DeepSeek-V2的训练语料库中采样,确保了模型在通用语言任务中保持竞争力。
二、技术创新:长上下文与强化学习
DeepSeek-Coder-V2的一个显著进步是其 上下文长度从16K扩展到了惊人的128K token。这使得模型能够处理更复杂、更大规模的编码任务,适应更长的代码输入。
在训练策略上,DeepSeek-Coder-V2采用了分阶段的预训练和对齐方法。它使用 AdamW优化器,并利用了填充中间 (FIM) 训练方法,这对于代码补全功能至关重要。在对齐阶段,模型首先通过指令训练数据集进行微调,该数据集结合了来自DeepSeek-Coder和DeepSeek-Math的代码和数学数据,以及来自DeepSeek-V2的通用指令数据。
更值得一提的是,DeepSeek-Coder-V2采用了 群体相对策略优化 (GRPO) 算法 进行强化学习,以使其行为与人类偏好对齐。为了克服编译器0-1反馈的局限性,团队开发了一个奖励模型来指导策略模型的训练,从而确保模型响应在编码任务中的正确性和与人类偏好的一致性。
三、性能表现:全方位超越
DeepSeek-Coder-V2在多项标准基准测试中展现出卓越的性能,证明了其与闭源模型相媲美的能力。
-
代码生成:
- 在 HumanEval 基准测试中取得了 90.2% 的得分。
- 在 MBPP 基准测试中取得了 76.2% 的得分,创下了EvalPlus评估流程的新SOTA最佳成绩。
- 在 LiveCodeBench (LCB) 上获得 43.4% 的得分,与GPT-4o持平,在大型模型中并列最高。
- 成为第一个在 SWEBench 上得分超过 10% 的开源模型。
-
数学推理:
- DeepSeek-Coder-V2展现出强大的数学推理能力,无论是基础的GSM8K还是高级的MATH、AIME 2024和Math Odyssey等竞赛级基准测试,其表现均能与GPT-4o、Gemini 1.5 Pro和Claude 3 Opus等顶级闭源模型相媲美。
- 在 MATH 基准测试中,准确率达到 75.7%,几乎与GPT-4o的最高准确率76.6%持平。
- 在 AIME 2024 竞赛中的表现甚至 超过了 这些闭源模型。
-
通用自然语言:
- DeepSeek-Coder-V2保持了与DeepSeek-V2相当的通用语言性能。例如,在MMLU上达到了 79.2% 的准确率。
- 在主观评价中,其在Arena-Hard上达到65.0分,MT-bench上达到8.77分,alignbench上达到7.84分,这些分数显著优于其他代码专用模型,甚至可与通用开源模型相媲美。
-
代码完成与修复:
- 在RepoBench v1.1数据集上的存储库级代码完成任务中,DeepSeek-Coder-V2-Lite-Base模型表现出色,其Python性能与DeepSeek-Coder-Base 33B模型相当,Java性能与DeepSeek-Coder-Base 7B模型相当。
- 在填充中间 (FIM) 代码完成任务中,DeepSeek-Coder-V2-Lite-Base在Python、Java和JavaScript三种编程语言上均取得了卓越成绩,最高平均分为 86.4%。
- 在代码修复方面,DeepSeek-Coder-V2-Instruct在Defects4J、SWE-Bench和Aider等基准测试中展现出顶级性能,在Aider上超越了所有其他列出的模型,包括闭源模型。
-
代码理解与推理:
- DeepSeek-Coder-V2-Instruct在CRUXEval基准测试中表现突出,其在CRUXEval-I-COT上得分为70.0%,在CRUXEval-O-COT上得分为75.1%,展现了其在开源模型中的领导地位。
四、展望未来
DeepSeek-Coder-V2的发布无疑是代码智能领域的一个里程碑。它不仅进一步推进了该领域的发展,也为开源社区注入了强大的活力。尽管在指令跟踪能力方面与GPT-4 Turbo等模型仍存在一定差距,开发团队已经明确表示,未来将更加专注于提升模型的指令跟踪能力,以更好地应对现实世界中复杂的编程场景,并提升开发流程的生产力。
DeepSeek-Coder-v2-2406.11931v1.pdf

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)