
从零搭建AI面试助手:实时语音识别+说话人识别完整技术方案
语音识别 #人工智能 #WebRTC #机器学习 #前端技术 #Python后端。
·
文章标签: #语音识别 #人工智能 #WebRTC #机器学习 #前端技术 #Python后端
技术栈: JavaScript + Azure Speech SDK + Python + Picovoice Eagle + WebRTC
项目地址: https://interviewasssistant.com
🎯 项目背景与技术挑战
作为参与”个人公司“概念的个体,我在开发InterviewAssistant即答侠这款AI面试助手时,遇到了一个核心技术难题:如何在面试过程中实时识别语音,并准确区分面试官和面试者的声音,只对面试官的问题进行智能回答?
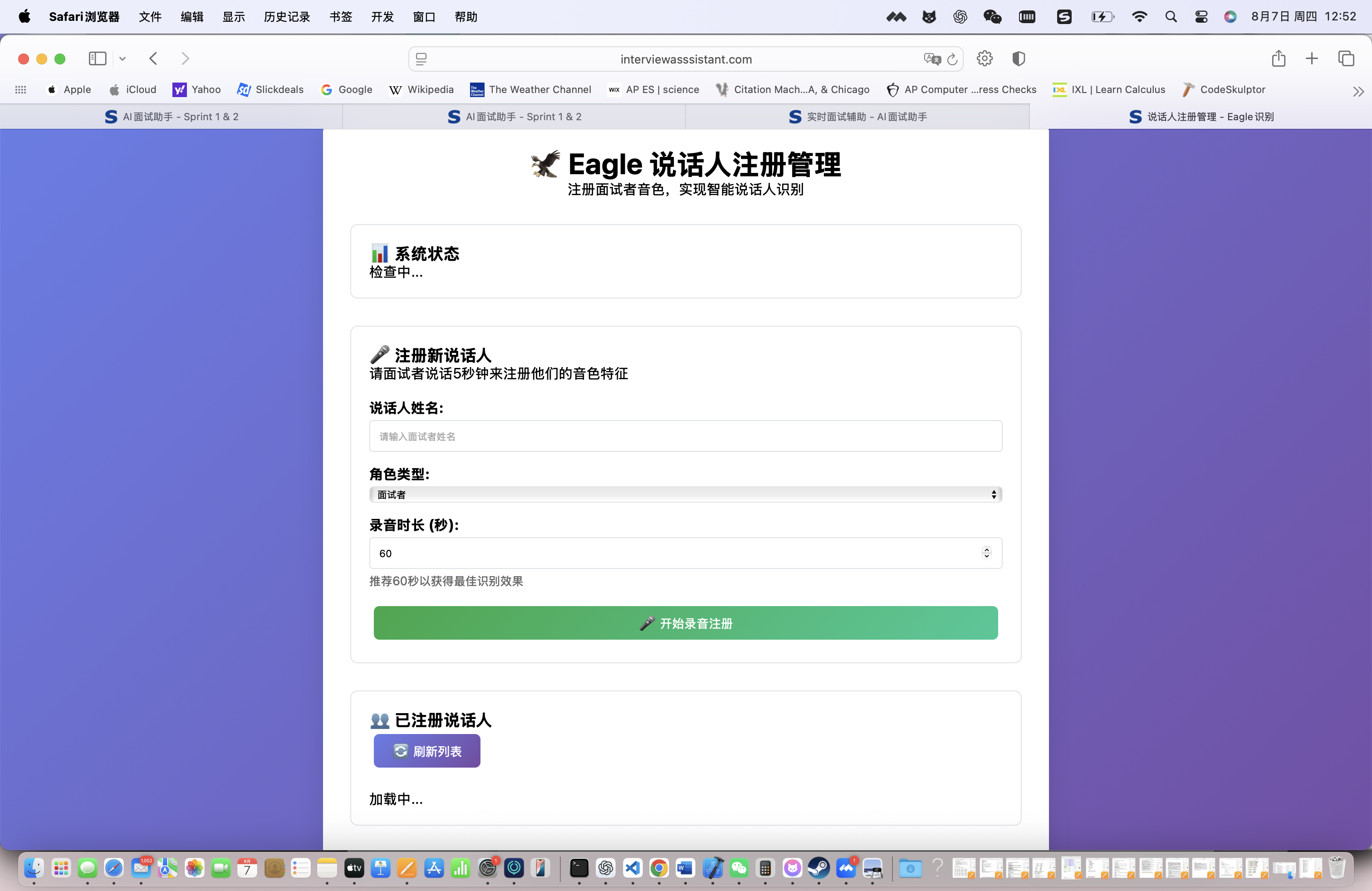
这个看似简单的需求,实际上涉及了语音识别、说话人识别、实时音频处理、前后端通信等多个技术领域的复杂结合。
技术挑战分析
🔥 核心难点:
- 实时性要求:语音识别延迟必须控制在1秒以内
- 准确性需求:说话人识别准确率需要达到90%以上
- 稳定性保障:长时间面试过程中不能出现识别中断
- 用户体验:前端界面要简洁易用,不能影响面试状态
🛠 技术选型考虑:
- 语音识别引擎:Azure Speech SDK vs 科大讯飞 vs 百度AI
- 说话人识别:Picovoice Eagle vs 开源方案 vs 自研算法
- 前端音频处理:WebRTC vs MediaRecorder API
- 实时通信:WebSocket vs Server-Sent Events
经过深度调研和测试,我们最终选择了 Azure Speech SDK + Picovoice Eagle + WebRTC 的技术组合。
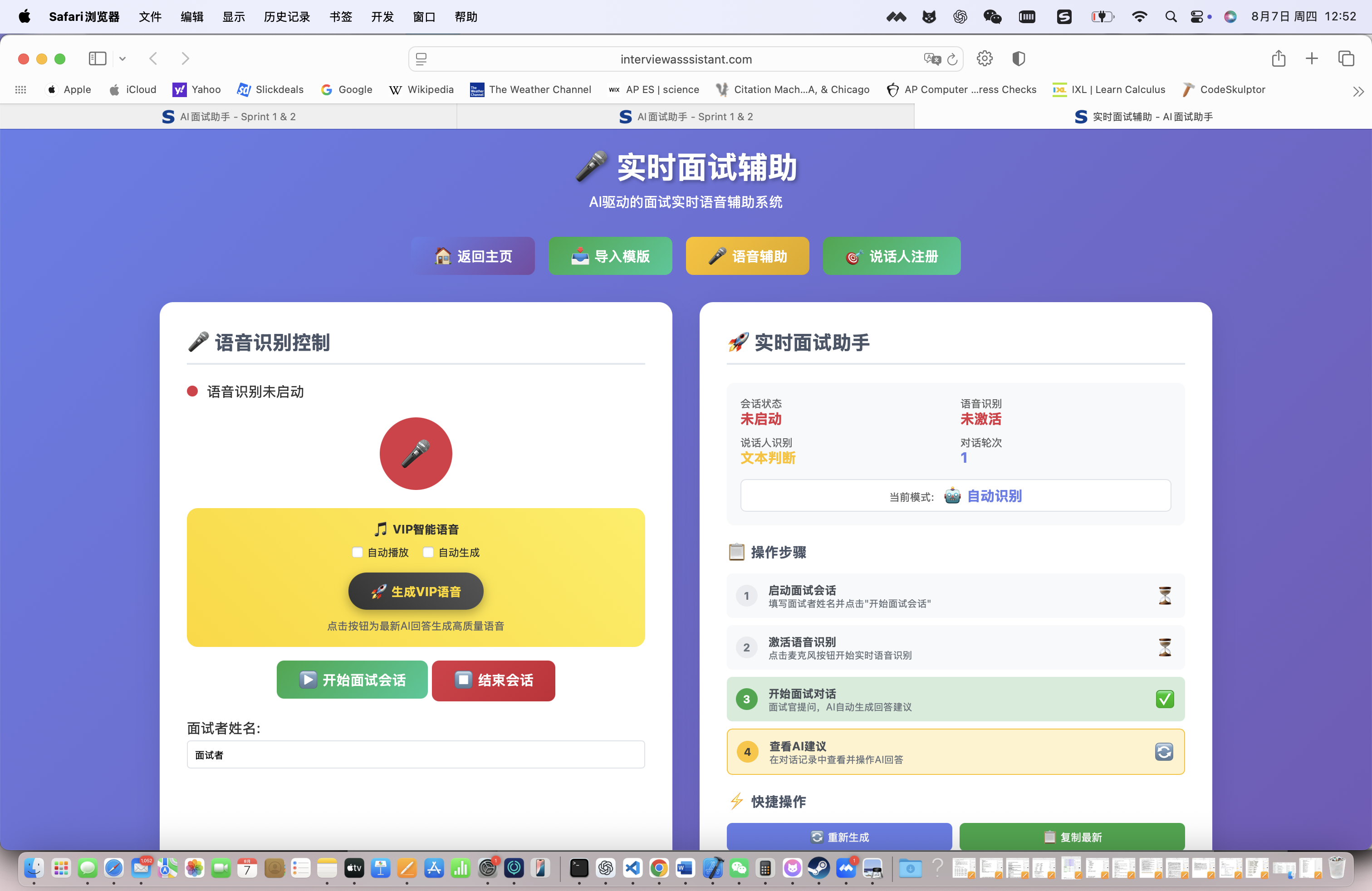
🏗️ 系统架构设计
整体架构图
┌─────────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ 前端浏览器 │ │ Flask后端 │ │ AI服务集群 │
│ ┌───────────┐ │ │ ┌──────────────┐ │ │ ┌─────────────┐ │
│ │ WebRTC │◄─┼────┼►│ 音频处理器 │◄┼────┼►│ Azure Speech│ │
│ │ 音频捕获 │ │ │ └──────────────┘ │ │ │ SDK │ │
│ └───────────┘ │ │ ┌──────────────┐ │ │ └─────────────┘ │
│ ┌───────────┐ │ │ │ Eagle说话人 │ │ │ ┌─────────────┐ │
│ │ 实时显示 │◄─┼────┼►│ 识别引擎 │ │ │ │ OpenAI GPT │ │
│ │ 界面 │ │ │ └──────────────┘ │ │ │ API │ │
│ └───────────┘ │ │ ┌──────────────┐ │ │ └─────────────┘ │
└─────────────────┘ │ │ 智能回答生成 │ │ └─────────────────┘
│ │ 引擎 │ │
│ └──────────────┘ │
└──────────────────┘
数据流设计
音频流 → WebRTC捕获 → 实时传输 → Azure识别 → 文本结果
↓ ↓
音频数据 → Eagle分析 → 说话人判断 → 面试官检测 → 智能回答
↓ ↓
前端显示 ← 格式化输出 ← 回答生成 ← GPT处理 ← 问题分析
💻 前端实现:WebRTC音频捕获
核心类设计
class AzureSpeechClient {
constructor() {
this.recognizer = null;
this.audioStream = null;
this.isListening = false;
this.speakerProfiles = new Map();
this.conversationHistory = [];
}
/**
* 初始化Azure Speech SDK和音频设备
*/
async initialize() {
try {
// 获取麦克风权限
this.audioStream = await navigator.mediaDevices.getUserMedia({
audio: {
sampleRate: 48000,
channelCount: 1,
echoCancellation: true,
noiseSuppression: true
}
});
// 配置Azure Speech SDK
const speechConfig = SpeechSDK.SpeechConfig.fromSubscription(
AZURE_SPEECH_KEY,
AZURE_SPEECH_REGION
);
speechConfig.speechRecognitionLanguage = "zh-CN";
speechConfig.outputFormat = SpeechSDK.OutputFormat.Detailed;
// 创建音频配置
const audioConfig = SpeechSDK.AudioConfig.fromMicrophoneInput();
// 初始化语音识别器
this.recognizer = new SpeechSDK.SpeechRecognizer(speechConfig, audioConfig);
// 设置事件监听器
this.setupEventListeners();
console.log("✅ Azure Speech客户端初始化成功");
return true;
} catch (error) {
console.error("❌ 初始化失败:", error);
throw new Error(`音频设备初始化失败: ${error.message}`);
}
}
/**
* 设置语音识别事件监听
*/
setupEventListeners() {
// 识别中间结果
this.recognizer.recognizing = (s, e) => {
const result = e.result.text;
if (result.trim()) {
this.displayPartialResult(result);
}
};
// 识别最终结果
this.recognizer.recognized = async (s, e) => {
if (e.result.reason === SpeechSDK.ResultReason.RecognizedSpeech) {
const text = e.result.text.trim();
if (text) {
await this.processSpeechResult(text, e.result);
}
}
};
// 错误处理
this.recognizer.canceled = (s, e) => {
console.error("语音识别被取消:", e.reason);
if (e.reason === SpeechSDK.CancellationReason.Error) {
this.handleSpeechError(e.errorDetails);
}
};
}
/**
* 开始连续语音识别
*/
async startListening() {
if (this.isListening) return;
try {
// 启动连续识别
this.recognizer.startContinuousRecognitionAsync(
() => {
this.isListening = true;
this.updateUI('listening');
console.log("🎤 开始监听语音...");
},
(error) => {
console.error("启动识别失败:", error);
this.handleSpeechError(error);
}
);
} catch (error) {
console.error("开始监听异常:", error);
}
}
/**
* 处理语音识别结果
*/
async processSpeechResult(text, speechResult) {
try {
// 提取音频数据用于说话人识别
const audioData = this.extractAudioData(speechResult);
// 调用后端进行说话人识别和智能回答
const response = await fetch('/api/process_speech_question', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
text: text,
audio_data: audioData,
timestamp: Date.now(),
confidence: speechResult.confidence
})
});
const result = await response.json();
// 显示识别结果和回答建议
this.displaySpeechResult(result);
} catch (error) {
console.error("处理语音结果失败:", error);
}
}
/**
* 从识别结果中提取音频特征
*/
extractAudioData(speechResult) {
// 这里需要从Azure的识别结果中提取音频数据
// 实际实现中需要处理音频编码和格式转换
try {
// 获取原始音频数据
const audioBuffer = speechResult.audioData || new ArrayBuffer(0);
// 转换为Base64用于传输
const uint8Array = new Uint8Array(audioBuffer);
const base64Audio = btoa(String.fromCharCode.apply(null, uint8Array));
return {
format: 'wav',
sample_rate: 48000,
channels: 1,
data: base64Audio,
duration: speechResult.duration || 0
};
} catch (error) {
console.warn("音频数据提取失败:", error);
return null;
}
}
/**
* 显示语音识别和处理结果
*/
displaySpeechResult(result) {
const conversationDiv = document.getElementById('conversation-display');
// 创建新的对话项
const conversationItem = document.createElement('div');
conversationItem.className = 'conversation-item';
// 确定说话人类型
const speakerType = result.speaker_type || 'unknown';
const speakerLabel = speakerType === 'interviewer' ? '面试官' : '面试者';
const speakerClass = speakerType === 'interviewer' ? 'interviewer' : 'interviewee';
conversationItem.innerHTML = `
<div class="speaker-info ${speakerClass}">
<span class="speaker-label">${speakerLabel}:</span>
<span class="confidence">置信度: ${(result.confidence * 100).toFixed(1)}%</span>
<span class="timestamp">${new Date().toLocaleTimeString()}</span>
</div>
<div class="speech-text">${result.text}</div>
${result.suggestion ? `
<div class="ai-suggestion">
<div class="suggestion-header">💡 AI建议回答:</div>
<div class="suggestion-content">${result.suggestion}</div>
</div>
` : ''}
`;
conversationDiv.appendChild(conversationItem);
conversationDiv.scrollTop = conversationDiv.scrollHeight;
// 更新统计信息
this.updateStatistics(result);
}
/**
* 错误处理和恢复
*/
handleSpeechError(errorDetails) {
console.error("语音识别错误:", errorDetails);
// 错误类型分析
if (errorDetails.includes('quota')) {
this.showError('语音服务配额超限,请稍后重试');
} else if (errorDetails.includes('network')) {
this.showError('网络连接异常,正在尝试重连...');
this.attemptReconnection();
} else {
this.showError('语音识别服务异常,请检查麦克风设置');
}
}
/**
* 自动重连机制
*/
async attemptReconnection() {
let retryCount = 0;
const maxRetries = 3;
while (retryCount < maxRetries && !this.isListening) {
try {
await new Promise(resolve => setTimeout(resolve, 2000 * (retryCount + 1)));
await this.initialize();
await this.startListening();
console.log("🔄 重连成功");
break;
} catch (error) {
retryCount++;
console.warn(`重连尝试 ${retryCount}/${maxRetries} 失败:`, error);
}
}
}
/**
* 停止语音识别
*/
stopListening() {
if (this.recognizer && this.isListening) {
this.recognizer.stopContinuousRecognitionAsync(
() => {
this.isListening = false;
this.updateUI('stopped');
console.log("🛑 停止语音识别");
},
(error) => {
console.error("停止识别失败:", error);
}
);
}
}
/**
* 资源清理
*/
dispose() {
if (this.recognizer) {
this.recognizer.close();
this.recognizer = null;
}
if (this.audioStream) {
this.audioStream.getTracks().forEach(track => track.stop());
this.audioStream = null;
}
}
}
前端界面集成
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>AI面试助手 - 实时语音识别</title>
<style>
.voice-interface {
max-width: 1200px;
margin: 0 auto;
padding: 20px;
font-family: 'Microsoft YaHei', sans-serif;
}
.control-panel {
display: flex;
gap: 15px;
margin-bottom: 20px;
align-items: center;
}
.mic-button {
width: 60px;
height: 60px;
border-radius: 50%;
border: none;
background: linear-gradient(45deg, #4CAF50, #45a049);
color: white;
font-size: 24px;
cursor: pointer;
transition: all 0.3s ease;
}
.mic-button:hover {
transform: scale(1.1);
box-shadow: 0 4px 15px rgba(76, 175, 80, 0.4);
}
.mic-button.listening {
background: linear-gradient(45deg, #f44336, #d32f2f);
animation: pulse 1.5s infinite;
}
@keyframes pulse {
0% { box-shadow: 0 0 0 0 rgba(244, 67, 54, 0.7); }
70% { box-shadow: 0 0 0 10px rgba(244, 67, 54, 0); }
100% { box-shadow: 0 0 0 0 rgba(244, 67, 54, 0); }
}
.status-indicator {
padding: 8px 16px;
border-radius: 20px;
font-size: 14px;
font-weight: bold;
}
.status-listening {
background: #e8f5e8;
color: #2e7d32;
}
.status-stopped {
background: #ffebee;
color: #c62828;
}
.conversation-display {
height: 500px;
border: 1px solid #ddd;
border-radius: 8px;
padding: 15px;
overflow-y: auto;
background: #fafafa;
}
.conversation-item {
margin-bottom: 20px;
padding: 15px;
background: white;
border-radius: 8px;
box-shadow: 0 2px 4px rgba(0,0,0,0.1);
}
.speaker-info {
display: flex;
justify-content: space-between;
align-items: center;
margin-bottom: 8px;
font-size: 12px;
}
.speaker-info.interviewer .speaker-label {
color: #1976d2;
font-weight: bold;
}
.speaker-info.interviewee .speaker-label {
color: #388e3c;
font-weight: bold;
}
.speech-text {
font-size: 16px;
line-height: 1.5;
margin-bottom: 10px;
}
.ai-suggestion {
background: linear-gradient(135deg, #e3f2fd 0%, #bbdefb 100%);
border-left: 4px solid #2196f3;
padding: 12px;
border-radius: 6px;
}
.suggestion-header {
font-weight: bold;
color: #1565c0;
margin-bottom: 8px;
}
.suggestion-content {
color: #424242;
line-height: 1.6;
}
</style>
</head>
<body>
<div class="voice-interface">
<div class="control-panel">
<button id="micButton" class="mic-button" title="点击开始/停止语音识别">
🎤
</button>
<div id="statusIndicator" class="status-indicator status-stopped">
未开始
</div>
<div class="statistics">
<span>识别次数: <strong id="recognitionCount">0</strong></span>
<span>准确率: <strong id="accuracyRate">0%</strong></span>
</div>
</div>
<div id="conversationDisplay" class="conversation-display">
<div class="placeholder">
点击麦克风按钮开始语音识别...
</div>
</div>
</div>
<script src="https://cdn.jsdelivr.net/npm/microsoft-cognitiveservices-speech-sdk@latest/distrib/browser/microsoft.cognitiveservices.speech.sdk.bundle-min.js"></script>
<script>
// 全局变量
let speechClient = null;
let isInitialized = false;
// DOM元素
const micButton = document.getElementById('micButton');
const statusIndicator = document.getElementById('statusIndicator');
const conversationDisplay = document.getElementById('conversationDisplay');
// 初始化应用
document.addEventListener('DOMContentLoaded', async () => {
try {
speechClient = new AzureSpeechClient();
await speechClient.initialize();
isInitialized = true;
micButton.addEventListener('click', toggleListening);
console.log("✅ 应用初始化完成");
} catch (error) {
console.error("❌ 应用初始化失败:", error);
showError("初始化失败,请检查麦克风权限和网络连接");
}
});
// 切换监听状态
async function toggleListening() {
if (!isInitialized) {
showError("系统尚未初始化完成");
return;
}
try {
if (speechClient.isListening) {
speechClient.stopListening();
} else {
await speechClient.startListening();
}
} catch (error) {
console.error("切换监听状态失败:", error);
showError("操作失败,请重试");
}
}
// 更新UI状态
function updateUI(status) {
switch (status) {
case 'listening':
micButton.classList.add('listening');
micButton.innerHTML = '🛑';
statusIndicator.className = 'status-indicator status-listening';
statusIndicator.textContent = '正在监听...';
break;
case 'stopped':
micButton.classList.remove('listening');
micButton.innerHTML = '🎤';
statusIndicator.className = 'status-indicator status-stopped';
statusIndicator.textContent = '已停止';
break;
}
}
// 显示错误信息
function showError(message) {
const errorDiv = document.createElement('div');
errorDiv.className = 'error-message';
errorDiv.style.cssText = `
position: fixed;
top: 20px;
right: 20px;
background: #f44336;
color: white;
padding: 12px 20px;
border-radius: 6px;
box-shadow: 0 4px 12px rgba(0,0,0,0.15);
z-index: 1000;
`;
errorDiv.textContent = message;
document.body.appendChild(errorDiv);
setTimeout(() => {
errorDiv.remove();
}, 5000);
}
// 页面卸载时清理资源
window.addEventListener('beforeunload', () => {
if (speechClient) {
speechClient.dispose();
}
});
</script>
</body>
</html>
🐍 后端实现:说话人识别核心算法
Eagle说话人识别管理器
import json
import base64
import numpy as np
from dataclasses import dataclass
from typing import Optional, List, Dict, Tuple
import pvporcupine
import pveagle
import struct
import wave
import asyncio
import logging
from datetime import datetime
@dataclass
class SpeakerProfile:
"""说话人档案数据结构"""
profile_id: str
name: str
profile_bytes: bytes
created_time: str
last_used: str
usage_count: int = 0
@dataclass
class RecognitionResult:
"""识别结果数据结构"""
speaker_type: str # 'interviewer' or 'interviewee'
confidence: float
profile_id: Optional[str]
processing_time: float
audio_quality: float
class EagleSpeakerManager:
"""Picovoice Eagle说话人识别管理器"""
def __init__(self, access_key: str):
self.access_key = access_key
self.eagle_profiler = None
self.eagle_recognizer = None
self.speaker_profiles: Dict[str, SpeakerProfile] = {}
self.frame_length = 512 # Eagle要求的帧长度
self.sample_rate = 16000 # Eagle要求的采样率
# 识别阈值配置
self.recognition_threshold = 0.6
self.min_confidence_threshold = 0.4
# 性能统计
self.stats = {
'total_recognitions': 0,
'successful_recognitions': 0,
'average_processing_time': 0.0
}
self._initialize_eagle()
self._load_profiles()
def _initialize_eagle(self):
"""初始化Eagle Profiler和Recognizer"""
try:
# 创建Eagle Profiler用于注册说话人
self.eagle_profiler = pveagle.create_profiler(
access_key=self.access_key
)
# 创建Eagle Recognizer用于识别说话人
self.eagle_recognizer = pveagle.create_recognizer(
access_key=self.access_key,
speaker_profiles=[] # 初始为空,后续动态更新
)
logging.info("✅ Eagle引擎初始化成功")
except Exception as e:
logging.error(f"❌ Eagle初始化失败: {e}")
raise
def _load_profiles(self):
"""从本地存储加载说话人档案"""
try:
with open('speaker_profiles.json', 'r', encoding='utf-8') as f:
profiles_data = json.load(f)
for profile_data in profiles_data:
profile = SpeakerProfile(
profile_id=profile_data['profile_id'],
name=profile_data['name'],
profile_bytes=base64.b64decode(profile_data['profile_bytes']),
created_time=profile_data['created_time'],
last_used=profile_data['last_used'],
usage_count=profile_data['usage_count']
)
self.speaker_profiles[profile.profile_id] = profile
# 重建Eagle Recognizer
self._rebuild_eagle_recognizer()
logging.info(f"📁 加载了 {len(self.speaker_profiles)} 个说话人档案")
except FileNotFoundError:
logging.info("📁 未找到说话人档案文件,从空开始")
except Exception as e:
logging.error(f"❌ 加载说话人档案失败: {e}")
def _save_profiles(self):
"""保存说话人档案到本地存储"""
try:
profiles_data = []
for profile in self.speaker_profiles.values():
profiles_data.append({
'profile_id': profile.profile_id,
'name': profile.name,
'profile_bytes': base64.b64encode(profile.profile_bytes).decode(),
'created_time': profile.created_time,
'last_used': profile.last_used,
'usage_count': profile.usage_count
})
with open('speaker_profiles.json', 'w', encoding='utf-8') as f:
json.dump(profiles_data, f, ensure_ascii=False, indent=2)
logging.info("💾 说话人档案保存成功")
except Exception as e:
logging.error(f"❌ 保存说话人档案失败: {e}")
def _rebuild_eagle_recognizer(self):
"""重建Eagle Recognizer(当档案更新时)"""
try:
if self.eagle_recognizer:
self.eagle_recognizer.delete()
# 从bytes重建EagleProfile对象
eagle_profiles = []
for profile in self.speaker_profiles.values():
eagle_profile = pveagle.EagleProfile.from_bytes(profile.profile_bytes)
eagle_profiles.append(eagle_profile)
# 创建新的Recognizer
self.eagle_recognizer = pveagle.create_recognizer(
access_key=self.access_key,
speaker_profiles=eagle_profiles
)
logging.info("🔄 Eagle Recognizer重建完成")
except Exception as e:
logging.error(f"❌ 重建Eagle Recognizer失败: {e}")
async def enroll_speaker_from_recording(self,
speaker_name: str,
audio_data: bytes,
speaker_type: str = 'interviewer') -> str:
"""
从录音注册新的说话人
Args:
speaker_name: 说话人名称
audio_data: 音频数据(WAV格式)
speaker_type: 说话人类型(interviewer/interviewee)
Returns:
profile_id: 新创建的档案ID
"""
start_time = datetime.now()
try:
# 预处理音频数据
processed_audio = self._preprocess_audio_for_enrollment(audio_data)
# 分割音频为Eagle要求的帧长度
audio_frames = self._split_audio_to_frames(processed_audio)
if len(audio_frames) < 10: # 至少需要10帧用于注册
raise ValueError("音频时长不足,需要至少5秒的清晰语音")
# 使用Eagle Profiler进行注册
enroll_percentage = 0.0
for frame in audio_frames:
enroll_percentage = self.eagle_profiler.enroll(frame)
if enroll_percentage >= 100.0:
break
if enroll_percentage < 100.0:
raise ValueError(f"注册失败,完成度仅 {enroll_percentage:.1f}%,需要更多清晰语音")
# 导出档案
eagle_profile = self.eagle_profiler.export()
profile_bytes = eagle_profile.to_bytes()
# 生成档案ID
profile_id = f"{speaker_type}_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
# 创建说话人档案
speaker_profile = SpeakerProfile(
profile_id=profile_id,
name=speaker_name,
profile_bytes=profile_bytes,
created_time=datetime.now().isoformat(),
last_used=datetime.now().isoformat(),
usage_count=0
)
# 保存到内存和磁盘
self.speaker_profiles[profile_id] = speaker_profile
self._save_profiles()
# 重建Recognizer
self._rebuild_eagle_recognizer()
processing_time = (datetime.now() - start_time).total_seconds()
logging.info(f"✅ 说话人 '{speaker_name}' 注册成功,耗时 {processing_time:.2f}s")
return profile_id
except Exception as e:
logging.error(f"❌ 说话人注册失败: {e}")
raise
def _preprocess_audio_for_enrollment(self, audio_data: bytes) -> np.ndarray:
"""预处理音频数据用于Eagle注册"""
try:
# 解析WAV文件头
with wave.open(io.BytesIO(audio_data), 'rb') as wav_file:
frames = wav_file.readframes(-1)
sample_width = wav_file.getsampwidth()
framerate = wav_file.getframerate()
channels = wav_file.getnchannels()
# 转换为numpy数组
if sample_width == 1:
audio_array = np.frombuffer(frames, dtype=np.uint8)
audio_array = (audio_array.astype(np.float32) - 128) / 128.0
elif sample_width == 2:
audio_array = np.frombuffer(frames, dtype=np.int16)
audio_array = audio_array.astype(np.float32) / 32768.0
else:
raise ValueError(f"不支持的音频格式: {sample_width} bytes per sample")
# 处理多声道音频
if channels > 1:
audio_array = audio_array.reshape(-1, channels)
audio_array = np.mean(audio_array, axis=1) # 转为单声道
# 重采样到Eagle要求的16kHz
if framerate != self.sample_rate:
from scipy import signal
num_samples = int(len(audio_array) * self.sample_rate / framerate)
audio_array = signal.resample(audio_array, num_samples)
# 音频增强
audio_array = self._enhance_audio_quality(audio_array)
# 转换为Eagle要求的int16格式
audio_int16 = (audio_array * 32767).astype(np.int16)
return audio_int16
except Exception as e:
logging.error(f"❌ 音频预处理失败: {e}")
raise
def _enhance_audio_quality(self, audio: np.ndarray) -> np.ndarray:
"""音频质量增强"""
try:
# 1. 归一化
max_val = np.max(np.abs(audio))
if max_val > 0:
audio = audio / max_val * 0.8
# 2. 简单的高通滤波去除低频噪声
from scipy import signal
b, a = signal.butter(3, 300 / (self.sample_rate / 2), 'high')
audio = signal.filtfilt(b, a, audio)
# 3. 音量标准化
rms = np.sqrt(np.mean(audio ** 2))
if rms > 0:
target_rms = 0.1
audio = audio * (target_rms / rms)
return audio
except Exception as e:
logging.warning(f"⚠️ 音频增强失败: {e}")
return audio
def _split_audio_to_frames(self, audio: np.ndarray) -> List[np.ndarray]:
"""将音频分割为Eagle要求的帧"""
frames = []
hop_length = self.frame_length // 2 # 50%重叠
for i in range(0, len(audio) - self.frame_length + 1, hop_length):
frame = audio[i:i + self.frame_length]
if len(frame) == self.frame_length:
frames.append(frame)
return frames
async def recognize_speaker(self, audio_data: bytes) -> RecognitionResult:
"""
识别说话人
Args:
audio_data: 音频数据
Returns:
RecognitionResult: 识别结果
"""
start_time = datetime.now()
try:
self.stats['total_recognitions'] += 1
# 预处理音频
processed_audio = self._preprocess_audio_for_recognition(audio_data)
# 音质评估
audio_quality = self._assess_audio_quality(processed_audio)
if audio_quality < 0.3:
logging.warning(f"⚠️ 音频质量较差: {audio_quality:.2f}")
# 分帧处理
audio_frames = self._split_audio_to_frames(processed_audio)
if not audio_frames:
return RecognitionResult(
speaker_type='unknown',
confidence=0.0,
profile_id=None,
processing_time=0.0,
audio_quality=audio_quality
)
# Eagle识别
recognition_scores = []
for frame in audio_frames:
try:
scores = self.eagle_recognizer.process(frame)
if scores:
recognition_scores.append(scores)
except Exception as e:
logging.warning(f"⚠️ 帧处理失败: {e}")
continue
if not recognition_scores:
return RecognitionResult(
speaker_type='unknown',
confidence=0.0,
profile_id=None,
processing_time=(datetime.now() - start_time).total_seconds(),
audio_quality=audio_quality
)
# 计算平均得分
avg_scores = self._calculate_average_scores(recognition_scores)
# 确定最佳匹配
best_match_idx = np.argmax(avg_scores)
best_confidence = avg_scores[best_match_idx]
# 获取对应的说话人档案
profile_ids = list(self.speaker_profiles.keys())
if (best_confidence > self.recognition_threshold and
best_match_idx < len(profile_ids)):
matched_profile_id = profile_ids[best_match_idx]
matched_profile = self.speaker_profiles[matched_profile_id]
# 更新使用统计
matched_profile.last_used = datetime.now().isoformat()
matched_profile.usage_count += 1
# 确定说话人类型
speaker_type = self._determine_speaker_type(matched_profile_id)
self.stats['successful_recognitions'] += 1
result = RecognitionResult(
speaker_type=speaker_type,
confidence=float(best_confidence),
profile_id=matched_profile_id,
processing_time=(datetime.now() - start_time).total_seconds(),
audio_quality=audio_quality
)
logging.info(f"🎯 识别成功: {speaker_type} (置信度: {best_confidence:.3f})")
else:
# 未识别出已知说话人
result = RecognitionResult(
speaker_type='unknown',
confidence=float(best_confidence),
profile_id=None,
processing_time=(datetime.now() - start_time).total_seconds(),
audio_quality=audio_quality
)
logging.info(f"❓ 未识别出已知说话人 (最高置信度: {best_confidence:.3f})")
# 更新性能统计
self._update_performance_stats(result.processing_time)
return result
except Exception as e:
logging.error(f"❌ 说话人识别失败: {e}")
return RecognitionResult(
speaker_type='unknown',
confidence=0.0,
profile_id=None,
processing_time=(datetime.now() - start_time).total_seconds(),
audio_quality=0.0
)
def _preprocess_audio_for_recognition(self, audio_data: bytes) -> np.ndarray:
"""预处理音频数据用于识别"""
# 与注册时的预处理逻辑基本相同
return self._preprocess_audio_for_enrollment(audio_data)
def _assess_audio_quality(self, audio: np.ndarray) -> float:
"""评估音频质量"""
try:
# 1. 信噪比估算
signal_power = np.mean(audio ** 2)
noise_power = np.mean((audio - np.mean(audio)) ** 2) * 0.1 # 假设噪声
snr = 10 * np.log10(signal_power / (noise_power + 1e-10))
# 2. 动态范围
dynamic_range = np.max(audio) - np.min(audio)
# 3. 零交叉率(语音活动指标)
zero_crossings = np.sum(np.diff(np.sign(audio)) != 0)
zcr = zero_crossings / len(audio)
# 综合评分 (0-1)
quality_score = min(1.0, (snr / 20 + dynamic_range + zcr * 10) / 3)
return max(0.0, quality_score)
except Exception as e:
logging.warning(f"⚠️ 音频质量评估失败: {e}")
return 0.5
def _calculate_average_scores(self, score_lists: List[List[float]]) -> np.ndarray:
"""计算多帧识别结果的加权平均"""
if not score_lists:
return np.array([])
# 转换为numpy数组
scores_array = np.array(score_lists)
# 生成权重(中间帧权重更高)
num_frames = len(score_lists)
weights = self._generate_weights(num_frames)
# 加权平均
weighted_scores = np.average(scores_array, axis=0, weights=weights)
return weighted_scores
def _generate_weights(self, num_frames: int) -> np.ndarray:
"""生成用于加权平均的权重"""
if num_frames == 1:
return np.array([1.0])
# 生成高斯权重分布(中间权重高)
x = np.linspace(-2, 2, num_frames)
weights = np.exp(-x**2)
weights = weights / np.sum(weights) # 归一化
return weights
def _determine_speaker_type(self, profile_id: str) -> str:
"""根据档案ID确定说话人类型"""
if profile_id.startswith('interviewer_'):
return 'interviewer'
elif profile_id.startswith('interviewee_'):
return 'interviewee'
else:
# 默认判断逻辑
return 'interviewer' # 假设未知的为面试官
def _update_performance_stats(self, processing_time: float):
"""更新性能统计"""
total = self.stats['total_recognitions']
current_avg = self.stats['average_processing_time']
# 计算新的平均处理时间
new_avg = (current_avg * (total - 1) + processing_time) / total
self.stats['average_processing_time'] = new_avg
def get_performance_stats(self) -> Dict:
"""获取性能统计信息"""
total = self.stats['total_recognitions']
successful = self.stats['successful_recognitions']
return {
'total_recognitions': total,
'successful_recognitions': successful,
'success_rate': successful / total if total > 0 else 0.0,
'average_processing_time': self.stats['average_processing_time'],
'registered_speakers': len(self.speaker_profiles)
}
def delete_speaker_profile(self, profile_id: str) -> bool:
"""删除说话人档案"""
try:
if profile_id in self.speaker_profiles:
del self.speaker_profiles[profile_id]
self._save_profiles()
self._rebuild_eagle_recognizer()
logging.info(f"🗑️ 删除说话人档案: {profile_id}")
return True
else:
logging.warning(f"⚠️ 档案不存在: {profile_id}")
return False
except Exception as e:
logging.error(f"❌ 删除档案失败: {e}")
return False
def set_recognition_threshold(self, threshold: float):
"""设置识别阈值"""
if 0.0 <= threshold <= 1.0:
self.recognition_threshold = threshold
logging.info(f"🔧 识别阈值设置为: {threshold}")
else:
raise ValueError("阈值必须在0.0-1.0之间")
def cleanup(self):
"""清理资源"""
try:
if self.eagle_profiler:
self.eagle_profiler.delete()
if self.eagle_recognizer:
self.eagle_recognizer.delete()
logging.info("🧹 Eagle资源清理完成")
except Exception as e:
logging.error(f"❌ 资源清理失败: {e}")
# Flask后端集成
from flask import Flask, request, jsonify
import io
app = Flask(__name__)
# 全局Eagle管理器
eagle_manager = None
def init_eagle_manager():
"""初始化Eagle管理器"""
global eagle_manager
try:
access_key = os.getenv('PICOVOICE_ACCESS_KEY')
if not access_key:
raise ValueError("未设置PICOVOICE_ACCESS_KEY环境变量")
eagle_manager = EagleSpeakerManager(access_key)
logging.info("✅ Eagle管理器初始化成功")
except Exception as e:
logging.error(f"❌ Eagle管理器初始化失败: {e}")
raise
@app.route('/api/process_speech_question', methods=['POST'])
async def process_speech_question():
"""处理前端发送的语音识别请求"""
try:
data = request.get_json()
# 提取请求数据
text = data.get('text', '').strip()
audio_data_b64 = data.get('audio_data', {}).get('data', '')
confidence = data.get('confidence', 0.0)
timestamp = data.get('timestamp', 0)
response = {
'text': text,
'timestamp': timestamp,
'confidence': confidence,
'speaker_type': 'unknown',
'speaker_confidence': 0.0,
'suggestion': None,
'processing_time': 0.0
}
# 检查文本是否为问题
is_question = is_interviewer_question(text)
# 如果有音频数据,进行说话人识别
if audio_data_b64 and eagle_manager:
try:
# 解码音频数据
audio_bytes = base64.b64decode(audio_data_b64)
# 说话人识别
recognition_result = await eagle_manager.recognize_speaker(audio_bytes)
response.update({
'speaker_type': recognition_result.speaker_type,
'speaker_confidence': recognition_result.confidence,
'processing_time': recognition_result.processing_time,
'audio_quality': recognition_result.audio_quality
})
# 只对面试官的问题生成建议回答
if (recognition_result.speaker_type == 'interviewer' and
recognition_result.confidence > 0.6):
suggestion = await generate_interview_suggestion(text)
response['suggestion'] = suggestion
except Exception as e:
logging.error(f"❌ 说话人识别失败: {e}")
# 降级到基于文本的判断
if is_question:
response['speaker_type'] = 'interviewer'
response['speaker_confidence'] = 0.5
suggestion = await generate_interview_suggestion(text)
response['suggestion'] = suggestion
# 如果没有音频数据,只基于文本判断
elif is_question:
response['speaker_type'] = 'interviewer'
response['speaker_confidence'] = 0.5
suggestion = await generate_interview_suggestion(text)
response['suggestion'] = suggestion
return jsonify(response)
except Exception as e:
logging.error(f"❌ 处理语音请求失败: {e}")
return jsonify({'error': str(e)}), 500
def is_interviewer_question(text: str) -> bool:
"""基于文本判断是否为面试官问题"""
question_patterns = [
r'.*请.*介绍.*',
r'.*为什么.*选择.*',
r'.*你.*优势.*',
r'.*你.*缺点.*',
r'.*职业规划.*',
r'.*期望薪资.*',
r'.*还有.*问题.*吗.*',
r'.*\?, # 以问号结尾
r'.*什么.*',
r'.*如何.*',
r'.*怎么.*',
r'.*能否.*',
r'.*可以.*介绍.*',
]
import re
for pattern in question_patterns:
if re.search(pattern, text, re.IGNORECASE):
return True
return False
async def generate_interview_suggestion(question: str) -> str:
"""生成面试回答建议"""
try:
# 这里集成你的模版匹配和OpenAI生成逻辑
# 为了示例,这里返回一个简单的回答
import openai
prompt = f"""
你是一位专业的面试专家。针对以下面试问题,请生成一个结构化的回答建议:
问题:{question}
要求:
1. 使用STAR方法(Situation, Task, Action, Result)
2. 回答长度控制在150-200字
3. 语言自然、逻辑清晰
4. 突出个人能力和价值
"""
response = await openai.ChatCompletion.acreate(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
max_tokens=300,
temperature=0.7
)
return response.choices[0].message.content.strip()
except Exception as e:
logging.error(f"❌ 生成回答建议失败: {e}")
return "抱歉,暂时无法生成回答建议,请稍后重试。"
@app.route('/api/eagle_status', methods=['GET'])
def get_eagle_status():
"""获取Eagle系统状态"""
if eagle_manager:
stats = eagle_manager.get_performance_stats()
return jsonify({
'status': 'active',
'stats': stats,
'threshold': eagle_manager.recognition_threshold
})
else:
return jsonify({'status': 'inactive', 'error': 'Eagle未初始化'})
@app.route('/api/enroll_speaker', methods=['POST'])
async def enroll_speaker():
"""注册新的说话人"""
try:
data = request.get_json()
speaker_name = data.get('speaker_name')
speaker_type = data.get('speaker_type', 'interviewer')
audio_data_b64 = data.get('audio_data')
if not all([speaker_name, audio_data_b64]):
return jsonify({'error': '缺少必要参数'}), 400
# 解码音频数据
audio_bytes = base64.b64decode(audio_data_b64)
# 注册说话人
profile_id = await eagle_manager.enroll_speaker_from_recording(
speaker_name, audio_bytes, speaker_type
)
return jsonify({
'success': True,
'profile_id': profile_id,
'message': f'说话人 "{speaker_name}" 注册成功'
})
except Exception as e:
logging.error(f"❌ 说话人注册失败: {e}")
return jsonify({'error': str(e)}), 500
if __name__ == '__main__':
# 初始化系统
init_eagle_manager()
# 启动Flask应用
app.run(host='0.0.0.0', port=5001, debug=True)
## 🚀 系统性能优化与监控
### 性能监控面板
```python
class PerformanceMonitor:
"""系统性能监控器"""
def __init__(self):
self.metrics = {
'speech_recognition': {
'total_requests': 0,
'average_latency': 0.0,
'error_rate': 0.0
},
'speaker_identification': {
'total_requests': 0,
'accuracy_rate': 0.0,
'average_confidence': 0.0
},
'response_generation': {
'total_requests': 0,
'average_response_time': 0.0,
'cache_hit_rate': 0.0
}
}
def record_speech_recognition(self, latency: float, success: bool):
"""记录语音识别性能"""
metrics = self.metrics['speech_recognition']
metrics['total_requests'] += 1
# 更新平均延迟
total = metrics['total_requests']
current_avg = metrics['average_latency']
metrics['average_latency'] = (current_avg * (total - 1) + latency) / total
# 更新错误率
if not success:
errors = metrics['error_rate'] * (total - 1) + 1
metrics['error_rate'] = errors / total
def record_speaker_identification(self, confidence: float, accuracy: bool):
"""记录说话人识别性能"""
metrics = self.metrics['speaker_identification']
metrics['total_requests'] += 1
# 更新平均置信度
total = metrics['total_requests']
current_avg = metrics['average_confidence']
metrics['average_confidence'] = (current_avg * (total - 1) + confidence) / total
# 更新准确率
if accuracy:
correct = metrics['accuracy_rate'] * (total - 1) + 1
metrics['accuracy_rate'] = correct / total
def get_performance_report(self) -> Dict:
"""生成性能报告"""
return {
'timestamp': datetime.now().isoformat(),
'metrics': self.metrics,
'recommendations': self._generate_recommendations()
}
def _generate_recommendations(self) -> List[str]:
"""生成性能优化建议"""
recommendations = []
# 语音识别延迟检查
if self.metrics['speech_recognition']['average_latency'] > 2.0:
recommendations.append("语音识别延迟较高,建议优化网络连接或更换服务器")
# 说话人识别准确率检查
if self.metrics['speaker_identification']['accuracy_rate'] < 0.8:
recommendations.append("说话人识别准确率偏低,建议重新训练模型或调整阈值")
# 响应生成速度检查
if self.metrics['response_generation']['average_response_time'] > 3.0:
recommendations.append("回答生成速度较慢,建议启用缓存或优化AI模型")
return recommendations
# 集成到Flask应用
monitor = PerformanceMonitor()
@app.route('/api/performance_stats', methods=['GET'])
def get_performance_stats():
"""获取系统性能统计"""
return jsonify(monitor.get_performance_report())
缓存优化策略
import redis
import hashlib
from typing import Optional
class ResponseCache:
"""智能回答缓存系统"""
def __init__(self, redis_url: str = 'redis://localhost:6379'):
self.redis_client = redis.from_url(redis_url)
self.cache_ttl = 3600 # 1小时过期
self.hit_count = 0
self.miss_count = 0
def _generate_cache_key(self, question: str, context: str = "") -> str:
"""生成缓存键"""
content = f"{question.lower().strip()}:{context}"
return f"response:{hashlib.md5(content.encode()).hexdigest()}"
def get_cached_response(self, question: str, context: str = "") -> Optional[str]:
"""获取缓存的回答"""
try:
cache_key = self._generate_cache_key(question, context)
cached_response = self.redis_client.get(cache_key)
if cached_response:
self.hit_count += 1
return cached_response.decode('utf-8')
else:
self.miss_count += 1
return None
except Exception as e:
logging.error(f"❌ 缓存读取失败: {e}")
return None
def cache_response(self, question: str, response: str, context: str = ""):
"""缓存回答"""
try:
cache_key = self._generate_cache_key(question, context)
self.redis_client.setex(cache_key, self.cache_ttl, response)
logging.info(f"💾 缓存回答: {cache_key[:16]}...")
except Exception as e:
logging.error(f"❌ 缓存写入失败: {e}")
def get_cache_stats(self) -> Dict:
"""获取缓存统计"""
total = self.hit_count + self.miss_count
hit_rate = self.hit_count / total if total > 0 else 0.0
return {
'hit_count': self.hit_count,
'miss_count': self.miss_count,
'hit_rate': hit_rate,
'total_requests': total
}
# 集成缓存到回答生成
response_cache = ResponseCache()
async def generate_interview_suggestion_cached(question: str, context: str = "") -> str:
"""带缓存的回答生成"""
# 尝试从缓存获取
cached_response = response_cache.get_cached_response(question, context)
if cached_response:
logging.info("🎯 使用缓存回答")
return cached_response
# 生成新回答
response = await generate_interview_suggestion(question)
# 缓存回答
if response:
response_cache.cache_response(question, response, context)
return response
🔧 部署与配置指南
Docker部署配置
# Dockerfile
FROM python:3.9-slim
# 安装系统依赖
RUN apt-get update && apt-get install -y \
gcc \
g++ \
portaudio19-dev \
python3-dev \
&& rm -rf /var/lib/apt/lists/*
# 设置工作目录
WORKDIR /app
# 复制依赖文件
COPY requirements.txt .
# 安装Python依赖
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY . .
# 暴露端口
EXPOSE 5001
# 设置环境变量
ENV FLASK_APP=app.py
ENV FLASK_ENV=production
# 启动命令
CMD ["gunicorn", "--bind", "0.0.0.0:5001", "--workers", "4", "app:app"]
都看了那么多,若您是正在准备的面试者或对这个技术模块感兴趣的人员,欢迎访问官网: 实时面试辅助神器 - 永久免费 - 测试版本 - 快速迭代

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)