
国产大模型全梳理:从 DeepSeek 到讯飞星火,谁才是当之无愧的 “老大”?
国产大模型全梳理:从 DeepSeek 到讯飞星火,谁才是当之无愧的 “老大”?
随着DeepSeek等国产模型的强势崛起,全球AI大模型竞赛已进入全新的激烈阶段。近期,XAI、OpenAI、谷歌、百度等国内外头部厂商纷纷宣布战略调整:原本闭源的高端AI模型陆续转向开源,主流AI产品也计划向用户免费开放。这一转变不仅打破了AI技术的专业壁垒,更意味着曾经"高高在上"的智能工具正加速走进普通人的生活。
然而,这些模型的实际能力究竟如何?彼此之间的差距体现在哪些方面?本文将聚焦国内主流AI大模型,从技术特性、核心能力到应用场景进行全面梳理。

1. DeepSeek:国产AI的"闪电黑马"
2023年7月,由量化资管巨头幻方量化孵化的DeepSeek正式成立。短短一年多时间,其模型已完成多轮迭代,目前性能已可与OpenAI o1-mini抗衡,堪称国产AI领域的"速度代表"。
技术层面,DeepSeek的核心竞争力来自两大创新:混合专家(MoE)架构与多头潜在注意力(MLA)机制。前者让模型仅调用部分参数即可维持高性能,后者则提升了上下文理解的精准度,两者结合使R1版本的训练成本仅约557.6万美元,大幅低于行业平均水平。更关键的是,其开源策略与针对中文语境的深度优化,吸引了数万开发者加入生态,加速了AI技术的落地。
目前,DeepSeek已成为跨平台适配的"香饽饽"——英伟达、AMD、微软、亚马逊云科技等国际巨头,以及华为云、腾讯云、阿里云等国内厂商,均已宣布支持其模型服务上架。
2. 豆包:性能反超GPT-4o的"字节力量"
字节跳动最新推出的豆包大模型1.5Pro,凭借大规模稀疏MoE架构实现了性能跃升。其激活参数的"杠杆效应"达到7倍(业界常规水平仅3倍),这意味着等效于7倍参数稠密模型的性能,却无需承担同等计算成本。在多项国际基准测试中,该模型的表现已超越GPT-4o,推理成本却降低了60%以上。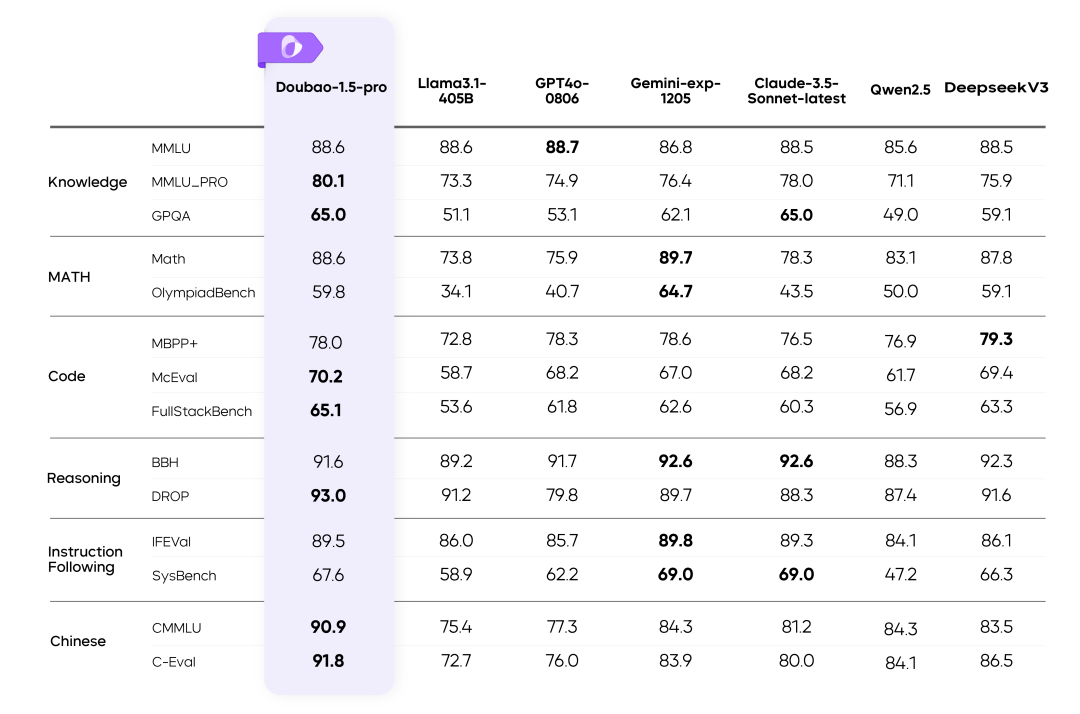
值得关注的是,豆包大模型1.5Pro的训练数据完全"原生"——未使用任何其他模型生成的数据,这保证了其输出内容的独特性与独立性。目前,Doubao-1.5-pro已在豆包App灰度上线,开发者可通过火山引擎直接调用API;而实时语音模型Doubao-1.5-realtime-voice-pro已全量覆盖豆包用户(需升级至7.2.0版本),语音交互延迟降低至0.5秒以内。
3. Kimi:文字生成领域的"全能选手"
在DeepSeek-R1发布两小时后,月之暗面迅速推出k1.5多模态思考模型,一举刷新了文字生成领域的SOTA(state-of-the-art)纪录。
从实测数据看,在short-CoT(短思考链)模式下,Kimi k1.5的数学解题、代码生成、视觉多模态理解及通用推理能力,较GPT-4o、Claude 3.5 Sonnet等领先550%;在long-CoT(长思考链)模式下,其数学、代码、多模态推理能力已追平OpenAI o1正式版。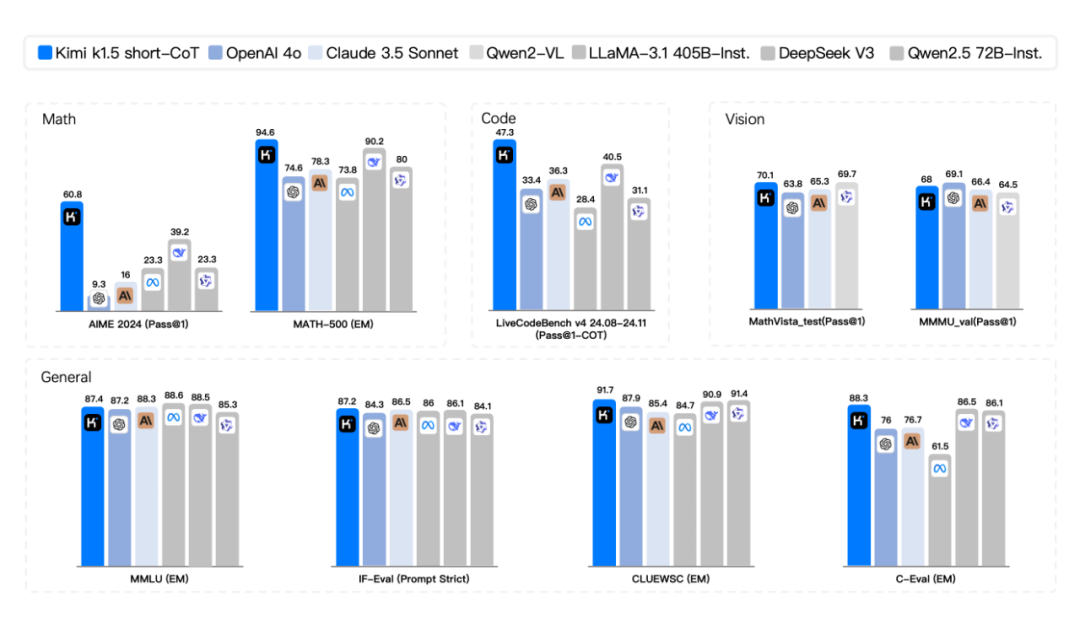
应用场景上,Kimi的长文处理能力尤为突出——可总结百万字文档、生成万字报告;数据处理支持Excel公式生成与数据分析;作为个人助理能同步管理日程、邮件;教育辅导中可实时解答数理化难题。不过,其响应速度在处理超长篇文本时仍有延迟,多文档同步解析能力及图片识别精度待提升。
4. 百度文心:加速普惠的"国民模型"
百度文心大模型的最新版本4.0 Turbo,主打"高效能"标签:运行速度较4.0提升30%,推理成本降低40%,尤其在检索增强能力上,可从千亿级数据库中精准定位信息,回答准确率提升至92%。
2月13日,百度宣布文心一言将于4月1日起全面免费,覆盖PC端与APP端所有用户,无需付费即可体验最新模型,同步上线的"深度搜索"功能还能联动模型进行多轮信息挖掘。更值得期待的是,百度计划未来几个月推出文心大模型4.5系列,预计在多模态交互(如文本-语音-视频联动)和行业解决方案(如医疗、教育)上有突破性升级。
5. GLM-4-Plus:智谱AI的"能力基座"
智谱AI推出的GLM-4-Plus,作为新一代基座大模型,撑起了全系列产品的能力天花板。在语言理解、逻辑推理、指令遵循、长文本输出等核心指标上,其表现与GPT-4o、405B Llama3.1持平,尤其在中文语境下的歧义消解能力领先15%。
2月10日,智谱BigModel开放平台上线GLM-4V-Plus-0111 beta版本。该模型在前两代基础上引入"原生可变分辨率"技术,视频理解精度提升20%,能解析短视频中的动作轨迹、场景转换,甚至识别画面中的文字信息并关联上下文。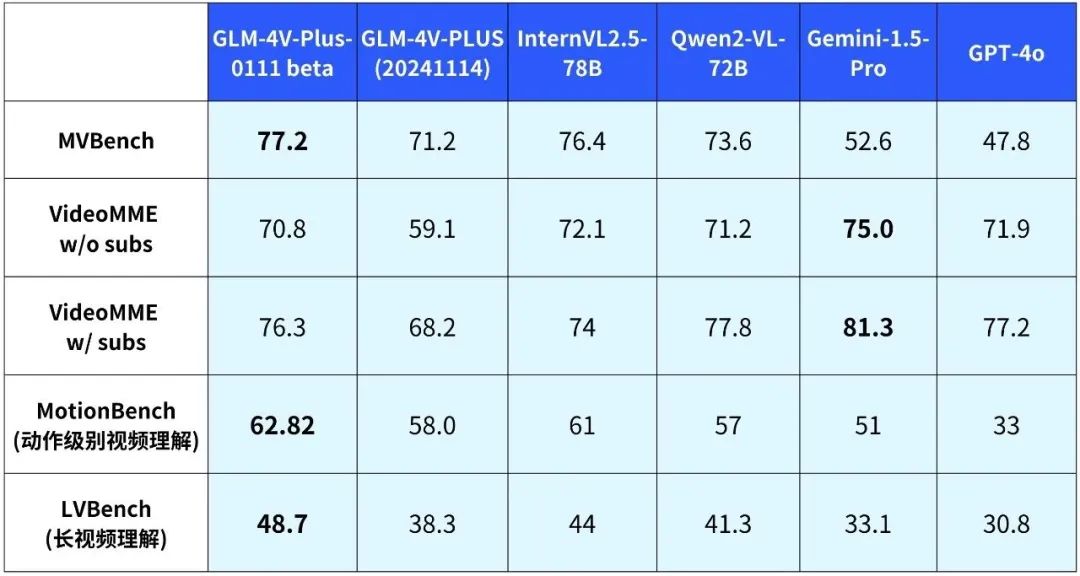
6. 混元大模型:全模态开源的"生态构建者"
腾讯混元大模型以"全模态开源"为核心竞争力,其开源矩阵涵盖文生文、文生图、文生3D、文生视频,是目前行业内覆盖最广的开源体系,性能获开源社区90%以上开发者认可。
技术优势体现在"强核心+高效率":多轮对话能记住50轮以上上下文,内容创作支持小说、文案、诗歌等多体裁,逻辑推理可解决数学应用题与逻辑谜题;训练效率较同类模型提升40%,推理速度提升25%。不过,其在复杂数学计算(正确率约70%)、编程任务(代码运行成功率约75%)上仍有提升空间,3D生成依赖预设模板,精细度待优化。
7. 通义千问:开源领域的"隐形冠军"
阿里通义千问在开源领域堪称"隐形冠军"——全球最大AI开源社区Huggingface最新榜单中,前十名开源模型有七款基于其二次训练。
其最新迭代的Qwen2.5-Max,预训练阶段使用超20万亿tokens数据,涵盖新闻、论文、小说、古籍等稀缺资源,语言知识覆盖度达98%;Qwen2.5-VL则基于Vision Transformer架构,结合SwiGLU和RMSNorm技术,不仅能识别常见物体,还能解析图片中的手写公式、流程图,与语言模型联动实现"看图写代码",图表理解准确率达88%。
8. Baichuan系列:全场景深度思考的"通才"
百川智能1月24日发布的Baichuan-M1-preview,是国内首个"三栖"深度思考模型——同时具备语言、视觉、搜索三大领域推理能力。在数学、代码等权威评测中,其表现超越o1-preview,尤其在中文长文本逻辑拆解上领先10%。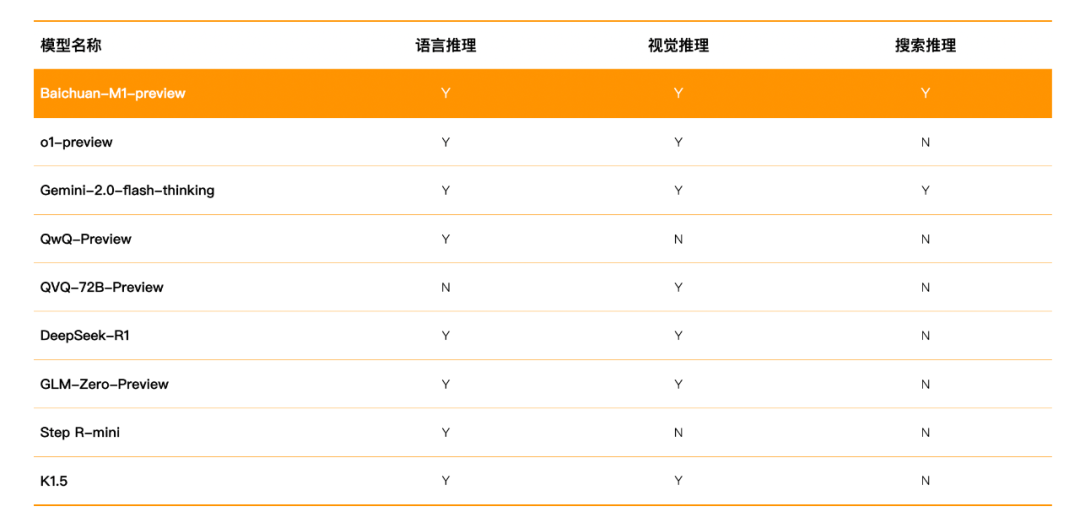
同期推出的Baichuan-M1-14B,作为前者的小尺寸版本,是行业首个开源医疗增强大模型。它在临床问答、病历分析上的表现接近o1-mini,且参数量更小(14B),更易在医疗机构本地化部署。
应用层面,Baichuan系列可胜任智能客服(支持方言识别)、智能写作(生成法律文书、学术摘要)、翻译(支持20种语言)等场景,但无法获取实时数据,对超专业领域问题(如量子物理)的解答精度有限。
9. Yi系列:ToB领域的"模式革新者"
零一万物的Yi系列大模型,正以"技术+生态"双轮驱动ToB领域的AI变革。其多模态矩阵覆盖语言、视觉、编程,在性能、成本、适用性上找到平衡点。
Yi-34B作为双语开源模型,支持200K超上下文窗口(约40万字文本),可处理长篇合同、小说;Yi-34B-Chat-0205经深度优化,适用于多文档对比分析、跨领域知识融合(如医疗+法律);Yi-VL-Plus支持1024*1024高分辨率图片输入,图表理解误差率低于5%,能识别工程图纸中的参数信息。通过开源生态与行业定制方案,Yi系列正推动ToB领域从"采购模型"向"共建生态"转型。
10. 讯飞星火大模型:深度推理的"解题高手"
科大讯飞的讯飞星火大模型,在"深度推理"赛道持续发力。最新版本4.0Turbo的数学解题正确率提升至85%,代码生成速度提高40%,中英文综合能力稳居业界前列,训练推理效率的提升使其能满足规模化落地需求(如教育机构百万级用户同时调用)。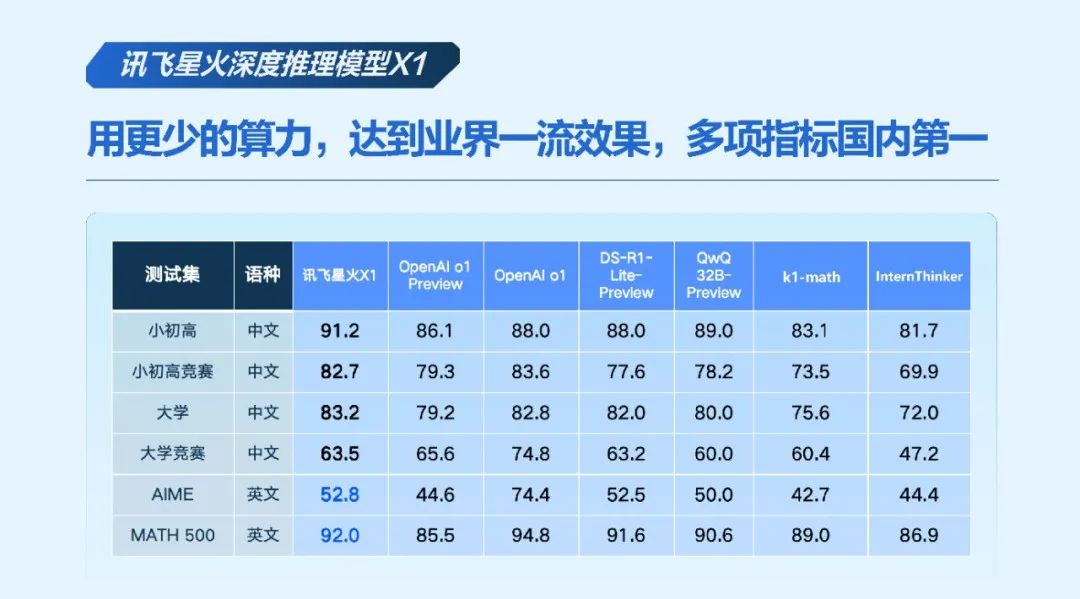
深度推理模型X1则采用"分步拆解-验证优化"模式:面对复杂问题时,会先分解为子问题,尝试多种解法并验证结果,最终优化策略。这使其在数学计算、逻辑推理上的表现尤为突出,复杂逻辑题解决率比普通模型高30%。
国内AI大模型正以"技术突破+生态普惠"双轮驱动向前奔跑。从DeepSeek的"高性能+低成本",到豆包的"原生数据训练",再到混元的"全模态开源",国产模型不仅在核心能力上追平国际一线水平,更在本土化适配、开源生态、应用落地等方面形成独特优势。
未来,随着更多模型开源、免费,AI技术将像水电一样融入日常生活,从智能客服到教育辅导,从内容创作到工业质检,全面渗透各行各业,成为推动社会进步与经济发展的新引擎。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 10
10 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)