
【GNN】第五章:传统图机器学习算法:Deepwalk、Node2Vec、PageRank
摘要:本文介绍了三种传统图机器学习算法——DeepWalk、Node2Vec和PageRank,用于将图数据嵌入低维向量空间。DeepWalk通过随机游走生成节点序列,类似NLP的滑窗操作,再使用Word2Vec训练得到节点嵌入向量。Node2Vec在DeepWalk基础上引入有偏随机游走策略,通过调整参数p和q控制游走方向,能捕捉节点不同特性。PageRank则用于计算节点重要性排名。文章还演示
【GNN】第五章:传统图机器学习算法:Deepwalk、Node2Vec、PageRank
这些算法都是用来进行图数据信息嵌入的,就是把图数据中的节点、边、子图、整图等信息,嵌入或者说映射成一个低维的、稠密的向量。
一、DeepWalk
DeepWalk是深度学习思想用于图嵌入的开山之作。
论文名称:DeepWalk:Online Learning of Social Representations,发表于2014年的KDD学术会议上, 原作者还有这个论文的一个PPT。
论文下载地址:https://arxiv.org/pdf/1403.6652
1、完全随机游走
我们知道word2vec是通过滑窗操作,从文本语料中获取模型训练数据的。但是图数据和文本语料是天差地别的,那要向量化图数据中信息,滑窗肯定是不行的,于是人们想出了随机游走deepwalk的方法,来从图数据中获取训练模型的训练数据。
所以随机游走等同于滑窗操作。也所以随机游走也同滑窗思想一样简单易懂,就是在一个图数据中随机选中一个节点,然后人为规定随机游走几步、游走几次,就自动生成了一系列游走序列。那这些游走序列就等同于滑窗操作生成的训练文本,就可以直接送入CBOW或者Skip-gram训练了,进而获取图数据中的节点的嵌入向量。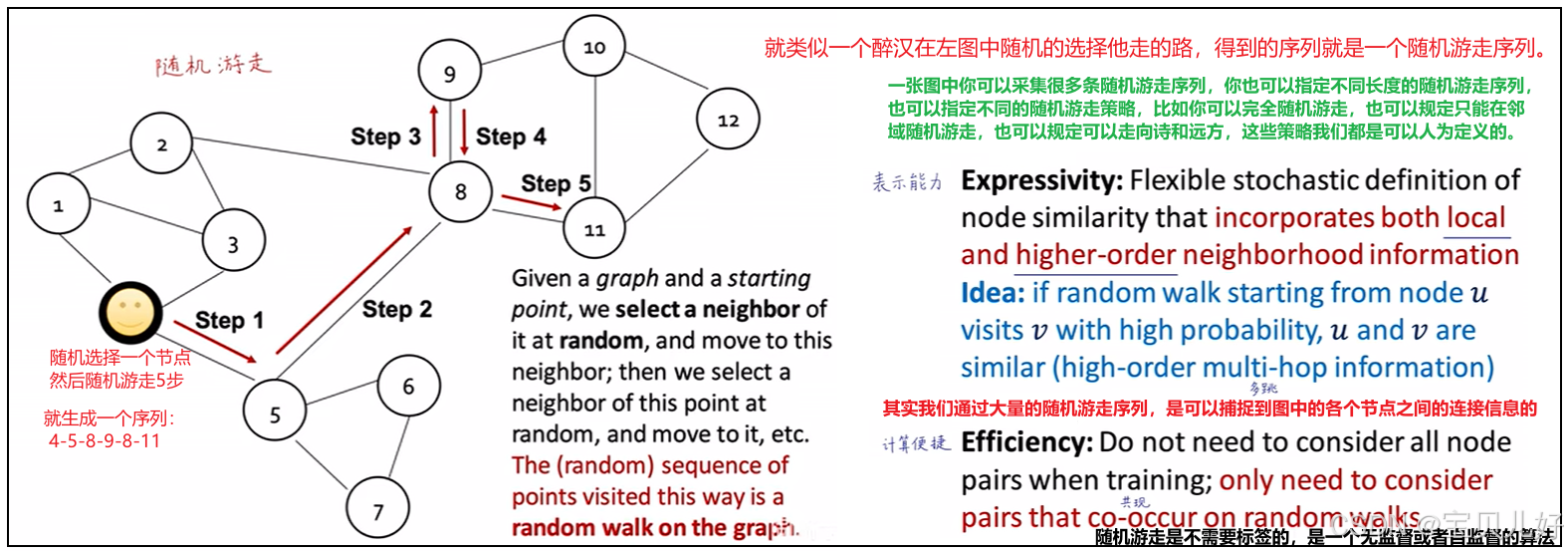
完全随机游走也叫均匀随机游走,通俗的类比就是,你假设有一个醉汉,这个醉汉在图中完全随机的选择他走的路,得到的序列就是一个随机游走序列。
下面我用一个例子来展示一下随机游走在图节点嵌入中的作用:
#1、导入西游记三元组文件
import pandas as pd
df = pd.read_csv(r'D:\pytorch-data\四大名著\西游记\triples.csv')
df[:5] 
#2、将三元组转化为图数据
import networkx as nx
G = nx.from_pandas_edgelist(df, 'head', 'tail')
#3、将图数据可视化
plt.rcParams['font.sans-serif'] = ['SimHei'] #显示正文
plt.rcParams['axes.unicode_minus'] = False #显示正负号
plt.figure(figsize=(20, 12))
pos = nx.spring_layout(G, seed=10)
nx.draw(G, pos, with_labels=True, node_size=20)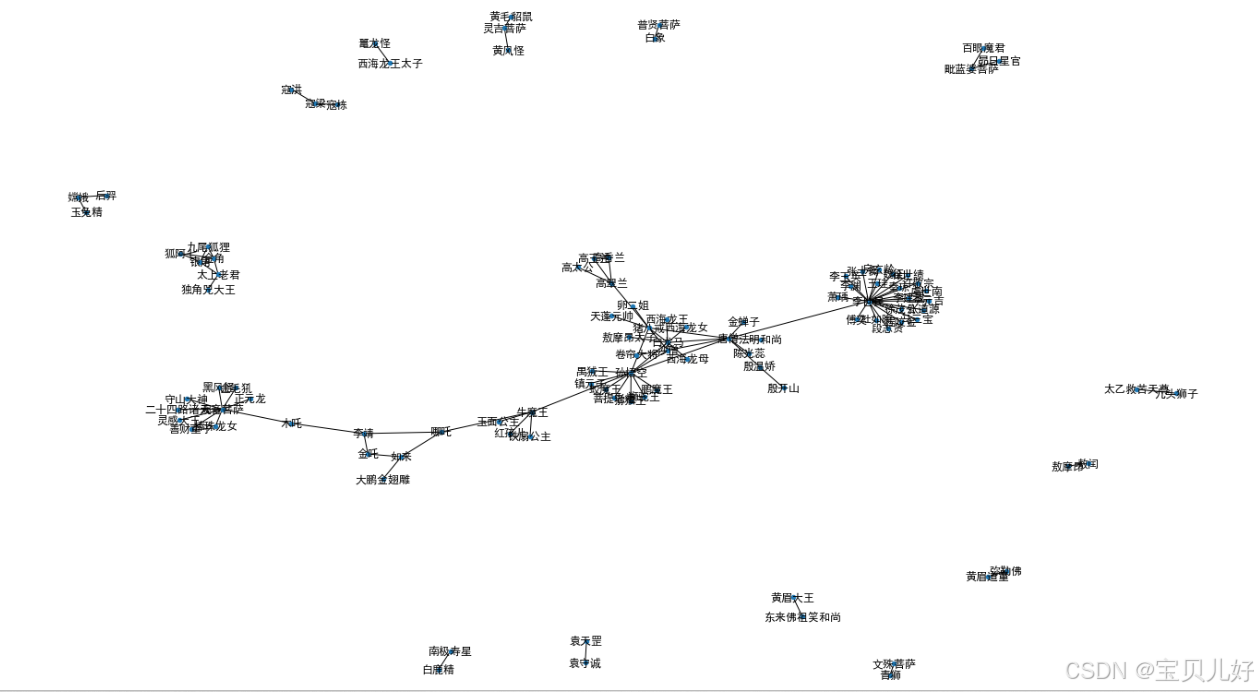
#4、写随机游走函数
def get_one_randomwalk(node, path_length): #输入一个要游走的起始点,和游走的步数
randomwalk_list = [node]
for i in range(path_length):
temp = list(G.neighbors(node))
if i > 0:
temp.remove(randomwalk_list[-2])
if len(temp) == 0:
break
next_node = random.choice(temp)
randomwalk_list.append(next_node)
node = next_node
return randomwalk_list
def get_randomwalks(G, path_length, path_num): #某个起始点要随机游走几次
all_nodes = list(G.nodes())
random_walks = []
for node in all_nodes:
for i in range(path_num):
sample = get_one_randomwalk(node, path_length)
random_walks.append(sample)
return random_walks
#5、获取随机游走序列
randomwalks = get_randomwalks(G, 5, 10)
len(randomwalks)
randomwalks
#6、用gensim库中的word2vec进行节点嵌入
from gensim.models import Word2Vec
model = Word2Vec(vector_size=16, #你想嵌入成多少维的向量
window=2, #窗口宽度,就是左边看2个词,右边看2个词
sg=1, #skip-gram用中心才来预测周围词。sg=0是CBOW:用周围词来预测中心词
hs=0, #不加分层softmax
negative=10, #负采样
alpha=0.03, #初始学习率
min_alpha=0.0007, #最小学习率
seed=0)
model.build_vocab(randomwalks, progress_per=2)
model.train(randomwalks, total_examples=model.corpus_count, epochs=100, report_delay=1)
#导出向量
nodes = list(G.nodes())
node_vec_dic = {}
for i in nodes:
vect = list(model.wv.get_vector(i))
node_vec_dic[i] = vect
node_vec_df = pd.DataFrame(node_vec_dic).T
node_vec_df[:5]
#7、PCA降维看看嵌入的效果
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_2d = pca.fit_transform(node_vec_df)
pca_2d.shape
_ = plt.figure(figsize=(25,16))
_ = plt.scatter(pca_2d[:,0], pca_2d[:,1], s=200)
for i, label in enumerate(nodes):
_ = plt.text(pca_2d[i,0], pca_2d[i,1], label)
plt.show()
#8、TSNE降维看看嵌入的效果
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, n_iter=500)
embed_tsne = tsne.fit_transform(node_vec_df)
embed_tsne.shape
_ = plt.figure(figsize=(25,16))
_ = plt.scatter(embed_tsne[:,0], embed_tsne[:,1], s=200)
for i, label in enumerate(nodes):
_ = plt.text(embed_tsne[i,0], embed_tsne[i,1], label)
plt.show()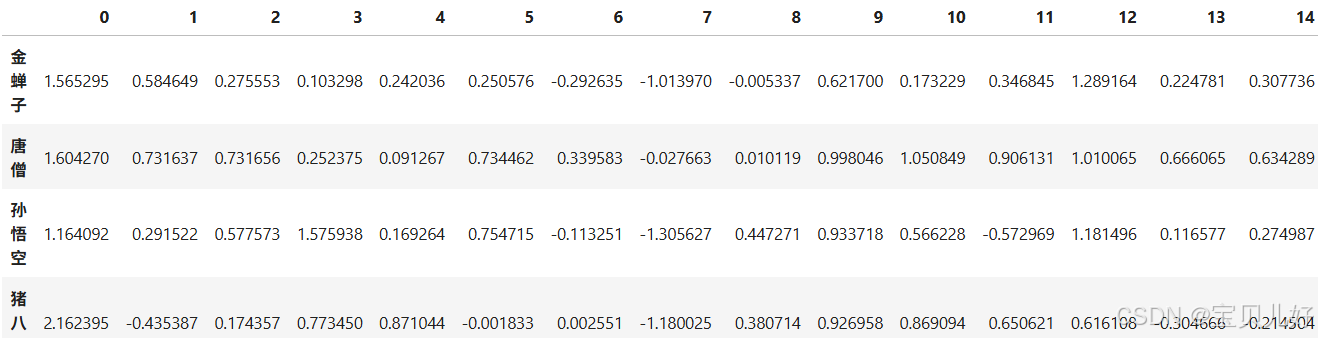
通过这个例子我们可以看到,deepwalk是不需要标签的,是一个无监督或者自监督的算法。通过大量的随机游走序列,我们是可以捕捉到图中的各个节点之间的连接信息的。
在原作者的PPT中还有如何构造损失函数、随机梯度下降、采集负样本等相关的数学公式和数学推导,这些我就不截图了,因为我个人感觉写一些代码,指定一些规则,随机游走序列就生成了,没必要数学证明吧。
2、有偏随机游走Biased Walks
从上面的例子中,我们可以直观的看到,随机游走就是从图数据中获取、可以直接喂入模型的训练数据的策略或者方法。
一张图中你可以采集很多条随机游走序列,你也可以指定不同长度的随机游走序列,也可以指定不同的随机游走策略,比如你可以完全随机游走,也可以规定只能在邻域随机游走,也可以规定可以走向诗和远方,这些策略我们都是可以人为定义的。
Node2Vec算法中的随机游走策略就是有偏的随机游走,有的也叫二阶随机游走,它有深度搜索和宽度搜索,就是我说的邻域游走和远方游走。但是不管怎样,它都是从图数据中生成训练数据的一种策略而已。下图是作者PPT中的截图: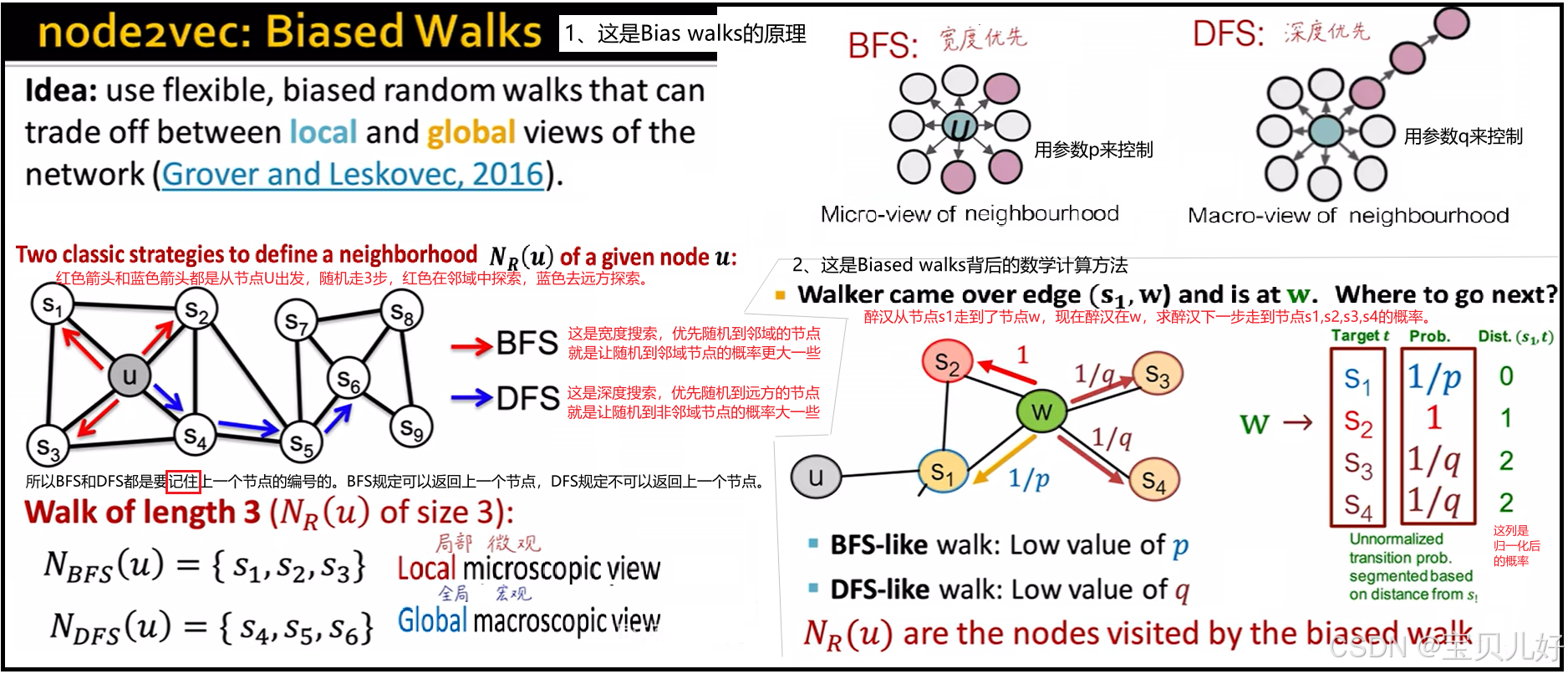
原作者PPT中说:不同p、q组合,可以实现不同的搜索,进而达到不同的效果。比如,p大q小,就是优先探索远方,而优先探索远方得到的数据序列,其生成的节点嵌入更容易反映同质社群这个属性。p小q大,是优先探索近邻,而优先探索近邻得到的数据序列更多反映的是局部微观区域,所以这些序列生成的节点嵌入就更容易反映节点的功能角色信息,比如是否是中枢节点、桥接节点、边缘节点等这些信息。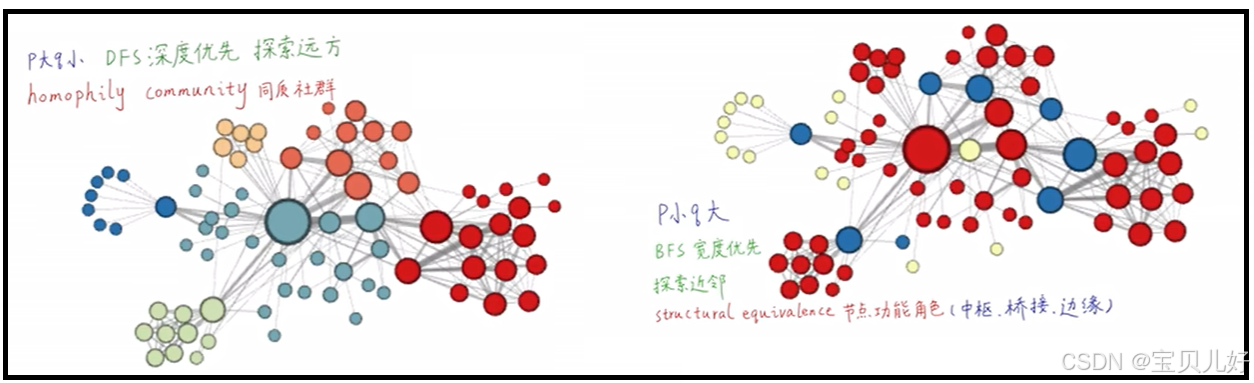
上图效果看似非常好,但是在实际操作中,p和q是很难调的,所以我们也是很难能达到这个效果的。
除了上述node2vec中打包的有偏游走策略,还有比如下图所示的这些游走策略,以及你选择的标准:
3、匿名游走
均匀随机游走和有偏随机游走都是"窗口"的思想,所以一般都是用来进行图节点嵌入的。如果我们想对整图进行嵌入呢?一般有下面几种解决方案:
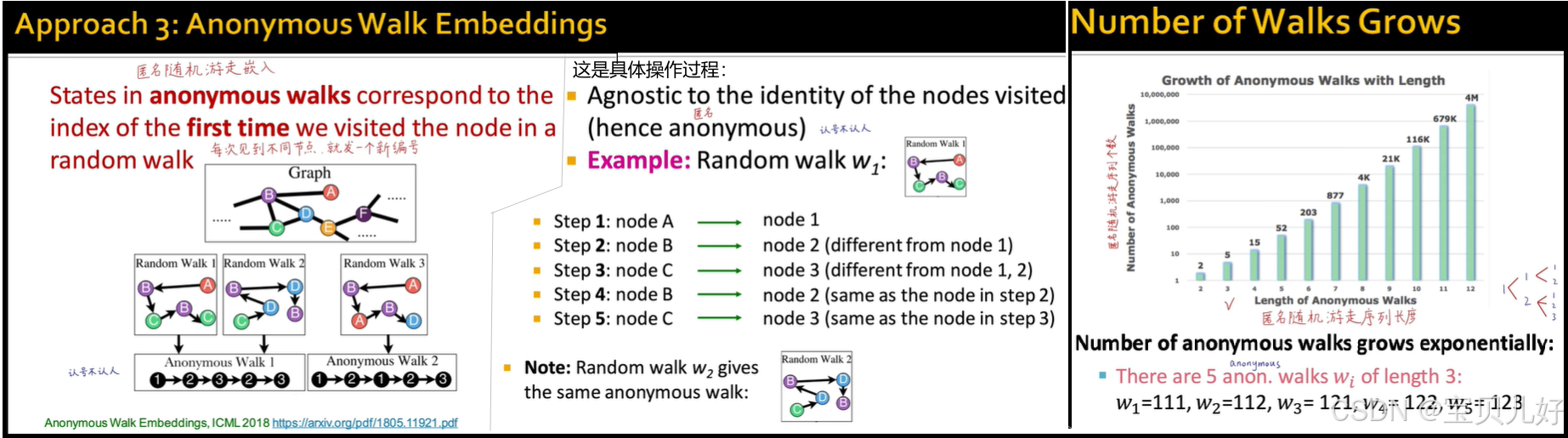
方法3就是匿名游走。匿名游走的个数,随步数呈几何级数增长。比如3个节点有5种匿名随机游走,4个节点有15种匿名随机游走。 以3个节点为例,我们把每种匿名随机游走的可能路径个数当作那个维度上的向量值,这样就生成了一个5维的向量,这个5维向量就可以用来表示整图。
匿名游走的论文链接是:https://arxiv.org/pdf/1805.11921 ,感兴趣的同学翻翻原论文吧。
二、Node2Vec
node2vec论文下载地址: https://arxiv.org/pdf/1607.00653
node2vec的前身是Word2Vec。Word2Vec是NLP领域中的把词嵌入成向量的算法。node2vec就是借鉴Word2Vec,二者无太多区别。前面我浩浩荡荡写了三万多字的Word2vec:【GNN】第四章:表示学习算法Word2Vec、CBOW、Skip-gram、hierarchical softmax、负采样_gcn-CSDN博客 就是为本篇的Node2vec打基础的。所以对word2vec有深刻理解了,node2vec就轻车熟路了。
Node2Vec算法是通过随机游走Deepwalk的方法,构造无监督或者说是自监督学习任务,来实现图数据嵌入的。所以也叫图表示学习算法,Node Embedding。也所以Node2Vec算法中实际上是打包了bias deepwalk算法的。所以这里我就通过例子来展示一下即可:
#1、导入西游记三元组文件
import pandas as pd
df = pd.read_csv(r'D:\pytorch-data\四大名著\西游记\triples.csv')
#2、将三元组转化为图数据
import networkx as nx
G = nx.from_pandas_edgelist(df, 'head', 'tail')
#3、构建Node2Vec模型
from node2vec import Node2Vec
node2vec = Node2Vec(G, dimensions=16, #嵌入的维度
p=2, q=0.5, #回家参数、外出参数
walk_length=5, #随机游走最大长度
num_walks=10, #每个节点作为起始节点生成的随机游走个数
workers=2) #并行线程数
#论文中给出的经验参数组合:
#p=1, q=0.5, n_clusters=6 DFS深度优先搜索,挖掘同质社群
#p=1, q=2, n_clusters=3 BFS宽度优先搜索,挖掘节点的结构功能。
#4、训练模型,生成节点的嵌入向量
model = node2vec.fit(window=3, #skip-gram窗口大小
min_count=1, #忽略出现次数低于此阈值的节点(词)
batch_words=4) #每个线程处理的数据量
#5、导出向量
nodes = list(G.nodes())
node_vec_dic = {}
for i in nodes:
vect = list(model.wv.get_vector(i))
node_vec_dic[i] = vect
node_vec_df = pd.DataFrame(node_vec_dic).T
node_vec_df[:5]#6、PCA降维看看嵌入的效果
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_2d = pca.fit_transform(node_vec_df)
pca_2d.shape
_ = plt.figure(figsize=(25,16))
_ = plt.scatter(pca_2d[:,0], pca_2d[:,1], s=200)
for i, label in enumerate(nodes):
_ = plt.text(pca_2d[i,0], pca_2d[i,1], label)
plt.show()
#7、TSNE降维看看嵌入的效果
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, n_iter=500)
embed_tsne = tsne.fit_transform(node_vec_df)
embed_tsne.shape
_ = plt.figure(figsize=(25,16))
_ = plt.scatter(embed_tsne[:,0], embed_tsne[:,1], s=200)
for i, label in enumerate(nodes):
_ = plt.text(embed_tsne[i,0], embed_tsne[i,1], label)
plt.show()#8、社群检测
from networkx.algorithms import community
cluster = community.label_propagation_communities(G)
len(cluster)
cluster
dic = {}
for index, name in enumerate(list(cluster)):
for i in name:
dic[i] = index
color = []
for i in list(G.nodes):
color.append(dic[i])
plt.figure(figsize=(16,8))
nx.draw(G, node_size=50, node_color=color)
三、PageRank
pagerank是谷歌的发家算法,是最早计算网络页面重要性的算法。
#1、导入西游记三元组文件
import pandas as pd
df = pd.read_csv(r'D:\pytorch-data\四大名著\西游记\triples.csv')
#2、将三元组转化为图数据
import networkx as nx
G = nx.from_pandas_edgelist(df, 'head', 'tail')
#3、调包networkx中的pagerank算法
pagerank = nx.pagerank(G)
node_importance = sorted(pagerank.items(), key=lambda x:x[1], reverse=True)
node_importance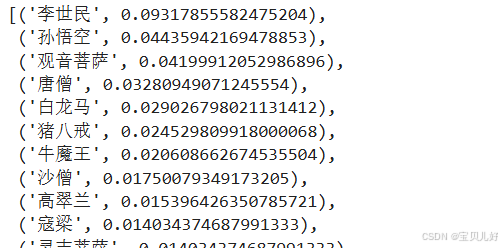
四、小结
1、基于随机游走的图信息嵌入算法都可以通过矩阵分解得到
2、基于随机游走的图信息嵌入算法的优缺点
(1)无法立刻泛化到新加入的节点。就是一个图中加入了一个新节点,那么就得重新游走,重新训练模型,之前的都不能用了。
(2)无法获取整体信息。因为随机游走还是类似NLP中的滑窗的效果,就是不管你的窗口有多大,你还只是一个窗口而已,你也是看不到全局信息的。除非你用匿名游走,或者直接上深度图神经网络来学习。
(3)只使用到图中的节点的连接信息,而没有利用图中的节点自身的属性信息、社群信息等。要充分利用这些信息,就只能上深度图神经网络了,所以下一章节我们就开启本系列的核心部分:深度图神经网络。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 20
20 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)