
基于langChain使用Chroma向量数据库和Ollama的嵌入模型和Ollama3.2实现的一个RAG服务
ollama_embeddings = OllamaEmbeddings(model="llama3.2")# 使用llama3.2嵌入模型。"""PDF分块并存储到Chroma向量数据库(使用Ollama的llama3.2嵌入模型)"""persist_directory="chroma_storage"# 数据保存目录。llm = Ollama(model="llama3.2")# 显式指定模
·
实现的功能:
-
PDF处理:将PDF文件分块并存储到向量数据库(Chroma)。
-
问答查询:从向量数据库中检索相关内容,结合使用Ollama的llama3.2生成答案。
(考虑到调用openAi接口不是免费的,这里直接使用llama基础模型llama3.2,也省去了申请OPENAI_API_KEY的步骤,主要以学习为目的嘛) -
代码链接stevensu1/EC01: 基于langChain使用Chroma向量数据库和Ollama的嵌入模型Ollama3.2和实现的一个RAG服务
功能介绍:
项目启动后进入首页上传pdf文档(一个简单的知识库)
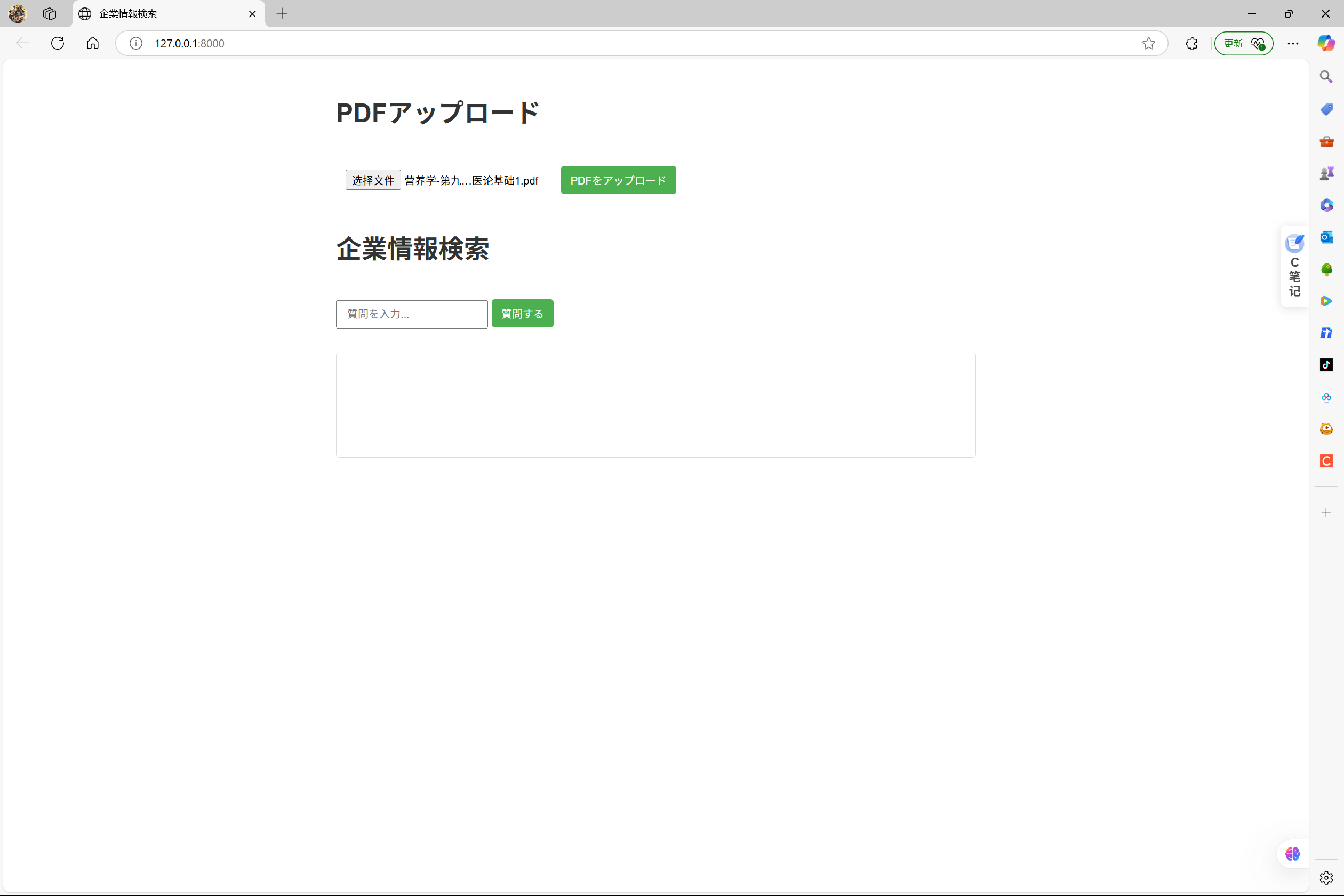
PDF处理函数 process_pdf
def process_pdf(pdf_path: str):
"""PDF分块并存储到Chroma向量数据库(使用Ollama的llama3.2嵌入模型)"""
# 1. 加载PDF文件
loader = PyPDFLoader(pdf_path)
pages = loader.load_and_split()
# 2. 文本分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(pages)
# 3. 初始化Ollama的嵌入模型(llama3.2)
ollama_embeddings = OllamaEmbeddings(model="llama3.2") # 使用llama3.2嵌入模型
# 4. 存储到Chroma向量数据库
Chroma.from_documents(
documents=splits,
embedding=ollama_embeddings,
persist_directory="chroma_storage" # 数据保存目录
)
从向量数据库Chroma中匹配检索信息并通过llama3.2生成返回
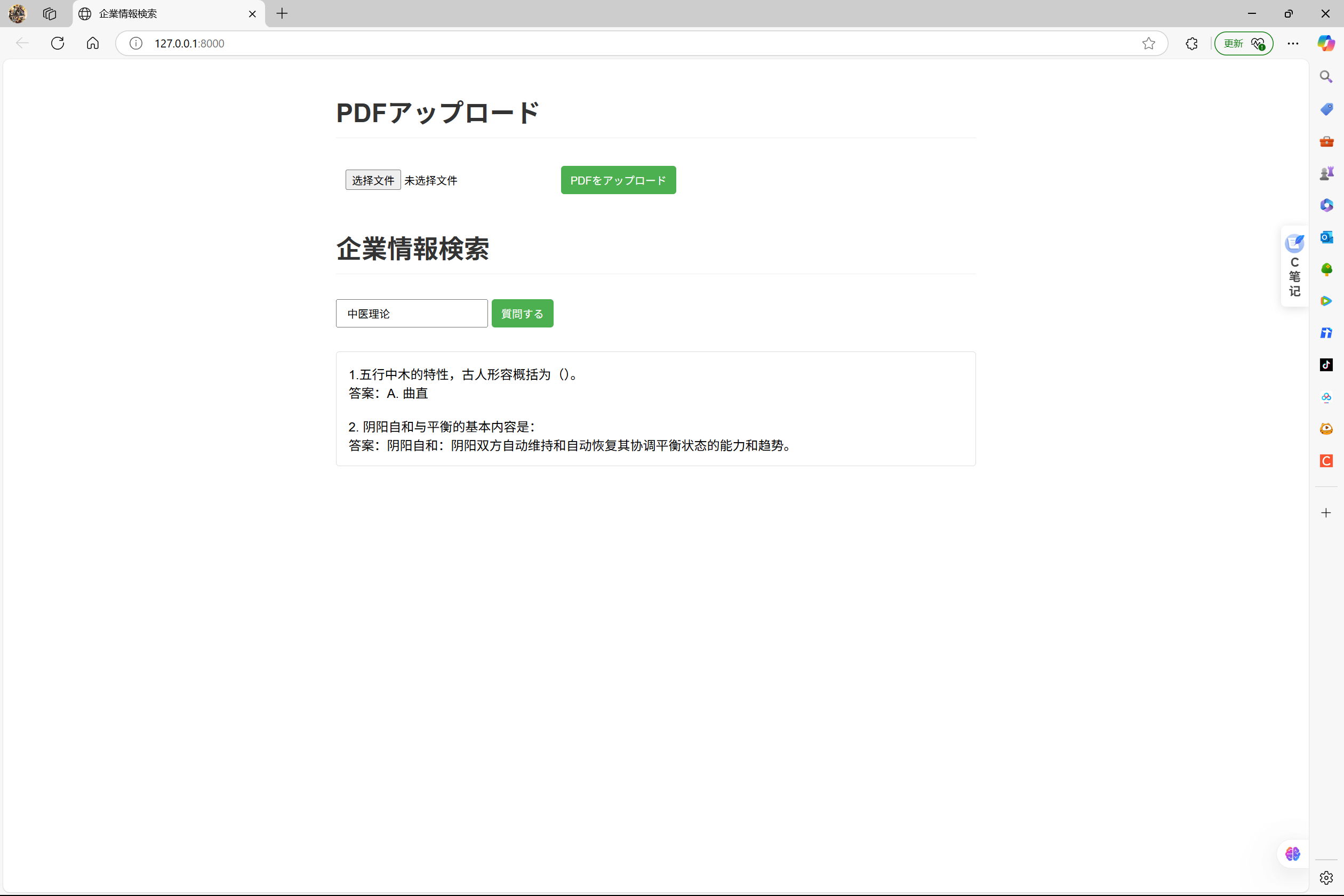
问答函数 rag_query
def rag_query(question: str) -> str:
"""基于Ollama的llama3.2模型进行RAG问答"""
# 1. 初始化Ollama的LLM(llama3.2)
llm = Ollama(model="llama3.2") # 显式指定模型
# 2. 加载向量数据库
ollama_embeddings = OllamaEmbeddings(model="llama3.2")
db = Chroma(
persist_directory="chroma_storage",
embedding_function=ollama_embeddings
)
# 3. 检索相关文档(Top 3)
retriever = db.as_retriever(search_kwargs={"k": 3})
relevant_docs = retriever.invoke(question)
# 4. 组合上下文
context = "\n\n".join([doc.page_content for doc in relevant_docs])
# 5. 构建提示词(llama3.23专用格式)
prompt = f"""请根据以下上下文回答问题:
上下文:{context}
问题:{question}
答案:"""
# 6. 调用llama3.2生成答案
response = llm.invoke(prompt)
return response

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)