
AI-大模型(1)怎么计算模型推理需要多少GPU
GPU计算
·
1.GLM-9B-chat 为例
1.1参数:9B->90亿参数
FP32(4字节)一般用FP16这个版本
模型的大小: 18G
1.2.层数:40层
隐藏层维度:4096
KV_Cache:10个并发的推理
每个token显存*token数*用户数
(40*4096*2byte*2)*1k*10 =6G
token数:多少的内容和回复。上下文窗口内容是128K
1.3 推理过程中的缓存空间:(activation,buffer,overheads)
占总体资源的10%
(18+6+2.4=26.4G)
10个并发左右,大概就需要这么大的了。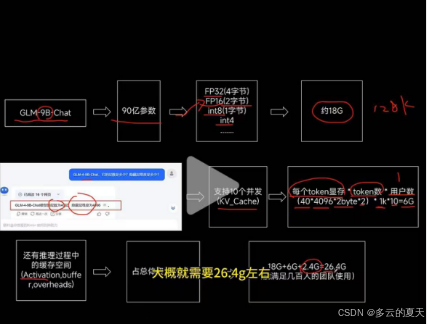

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 3
3 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)