
更全更快更强!HetuMoE开源:万亿大模型MoE训练系统
来自于Google的Switch Transformer和GShard,根据Gate网络计算结果,将token分配给打分最高的一个/两个expert。2. Top k来自于Google,根据Gate网络计算结果,将token分配给前k个打分最高的expert。图5. Google Top k Gate示意图3. k Top 1来自于阿里巴巴M6,将experts分为k组,将token分配给每组打分
一、问题背景:
Transformer 模型架构在数据挖掘中变得越来越重要,并在自然语言处理、计算机视觉 、图学习和推荐系统等广泛的应用中取得了令人瞩目的成果。近年来,通过增加数据量和模型参数量可以提高 Transformer模型的表现质量 [1]。然而,由于可用硬件设备(GPU,TPU等)的计算能力有限,增加模型的参数量会极大地增加模型的训练成本。为了高效训练大模型,一种可行的方式是引入条件计算,具体来说是稀疏门控混合专家 (Mixture-of-experts, 简称MoE)。如图1所示,MoE将网络中的1个专家扩展为N个专家,增加了模型的参数量,输入数据通过稀疏门控网络(Gating)被分到对应的k个专家进行处理, k通常取1或2。在k固定的情况下,增加专家数量N,模型扩大了参数量而保持计算代价基本不变[2]。
图1. MoE模型的工作原理[2].
二、相关工作:
现有的MoE训练系统包括:DeepSpeed、Tutel、FastMoE等,这些系统虽然提供了MoE分布式训练的支持,并采用了一些底层优化技术,但在实际使用中,仍然面临着如下挑战:
- 只支持简单的Top k算子,对其他Gate网络功能支持不完善
- Gate网络执行效率会成为系统的主要瓶颈AllToAll网络通信会成为主要瓶颈
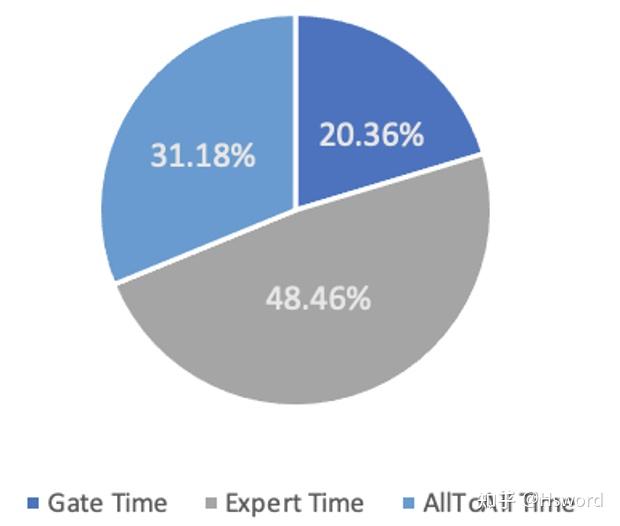
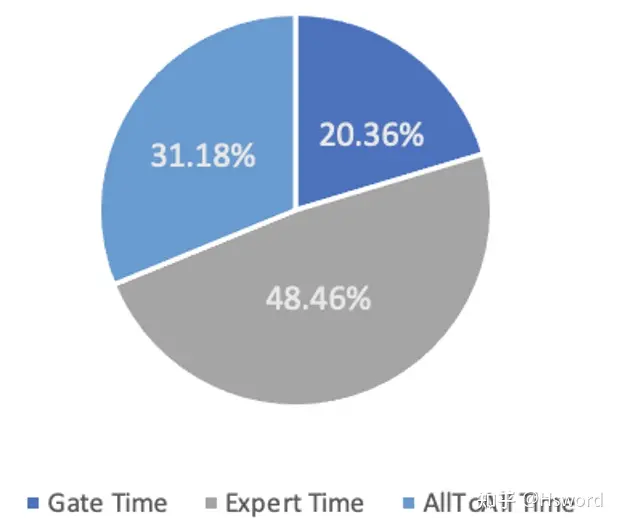
图2. 在8卡A100节点运行DeepSpeed MoE-Layer不同步骤时间占比
如上图所示,我们在带有NVLink的在8卡A100节点上执行DeepSpeed的MoE-Layer,可以发现Gate计算时间占比已经超过了一半,其中包括31%的Gate计算时间以及20%的AllToAll通信时间。这还仅仅只是单机8卡内部通信的情况,当扩展到多机场景,跨机通信代价会更为恶劣。如在100Gb网络下两机16卡环境,AllToAll通信代价占比会达到总时间的99%以上。
三、系统设计:
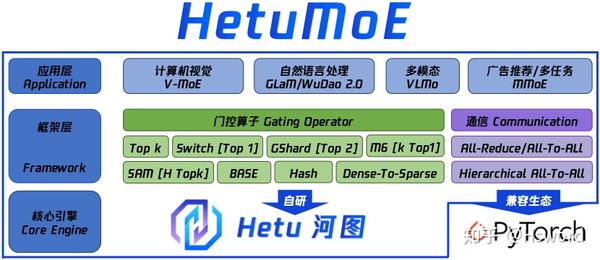
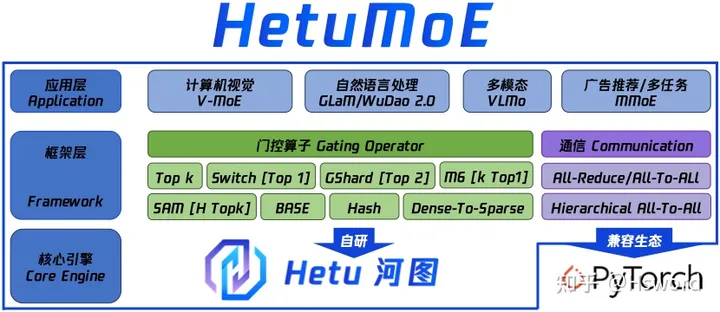
图3. HetuMoE的架构图.
HetuMoE系统简介:
为了解决上述问题,PKU-DAIR实验室河图(Hetu)团队基于Hetu深度学习框架,研发了一款高性能分布式MoE训练系统HetuMoE,在功能上,支持多种主流Gate网络算子,如:早期的Top k[3],Switch[4]的Top 1,GSahrd[5]的Top 2,Hash[6], M6[7]的k Top 1, SAM[8]的H Top k,BaseLayer[9]以及Hetu团队提出的Dense-To-Sparse[10]等;在性能上,除了支持常规的All-Reduce和AllToAll通信算子,还针对单网卡异构网络开发了层次通信算子Hierarchical AllToAll。总体上来说,与现有的主流MoE系统相比,HetuMoE在Gating算法的支持和网络通信优化上均拥有较大的优势。
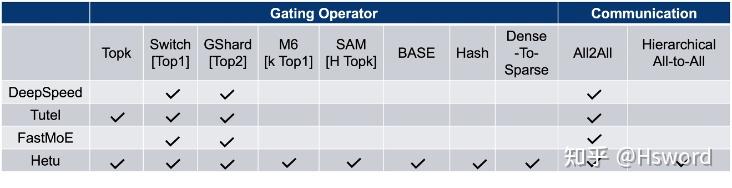
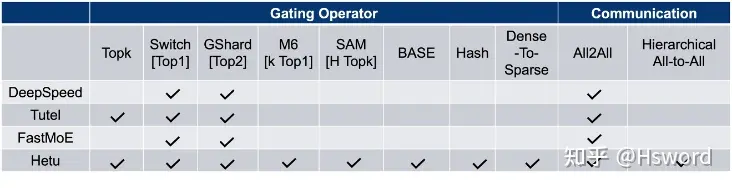
图4. 现有的主流MoE系统对比
Gate算子支持介绍:
1. Top 1/Top 2
来自于Google的Switch Transformer和GShard,根据Gate网络计算结果,将token分配给打分最高的一个/两个expert。
2. Top k
来自于Google,根据Gate网络计算结果,将token分配给前k个打分最高的expert。
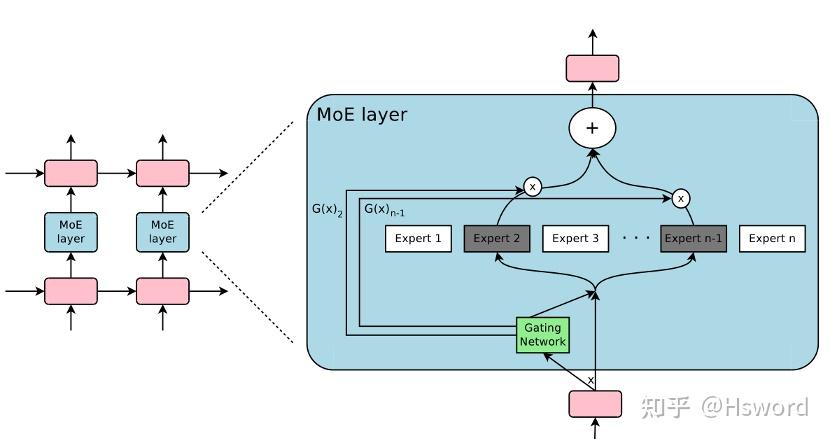
图5. Google Top k Gate示意图
3. k Top 1
来自于阿里巴巴M6,将experts分为k组,将token分配给每组打分最高的expert。
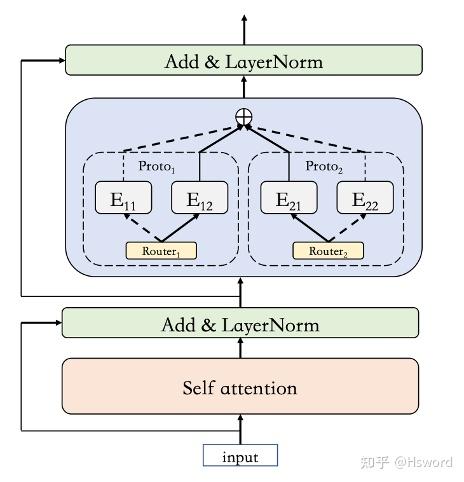
图5. 阿里巴巴M6中的k Top 1 Gate示意图
4. Hierarchical Top k,简称H Top k
来自于华为SAM,将experts分为若干组,选取一组的Top k结果作为最终分配策略。
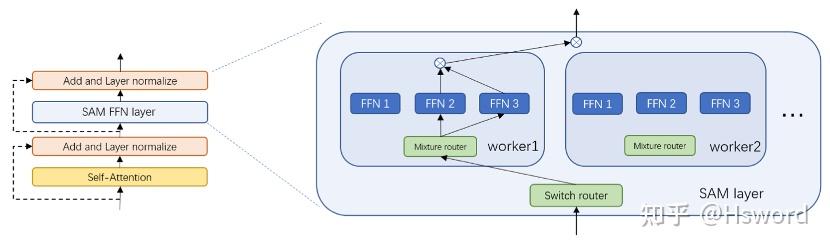
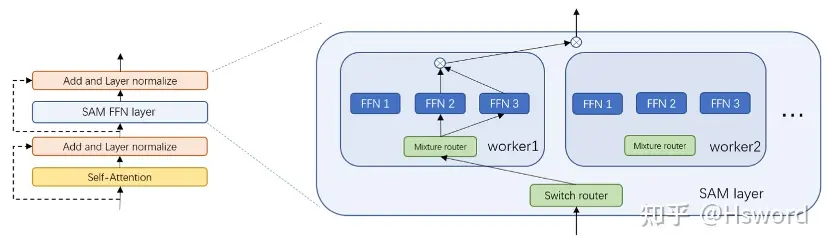
图6. 华为SAM中的H Top k Gate示意图
5. BASE
来自于Facebook,将token-expert分配问题建模为线性分配问题,进行优化求解,以达到最优负载均衡的效果。
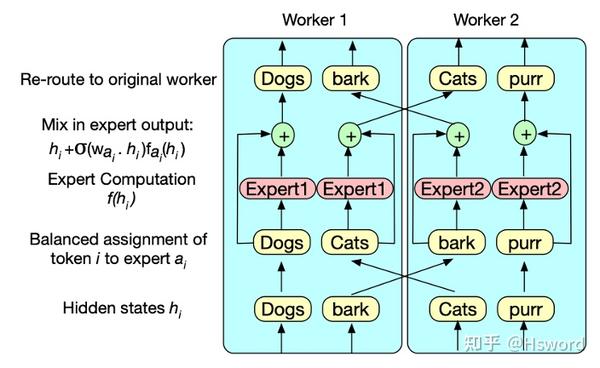
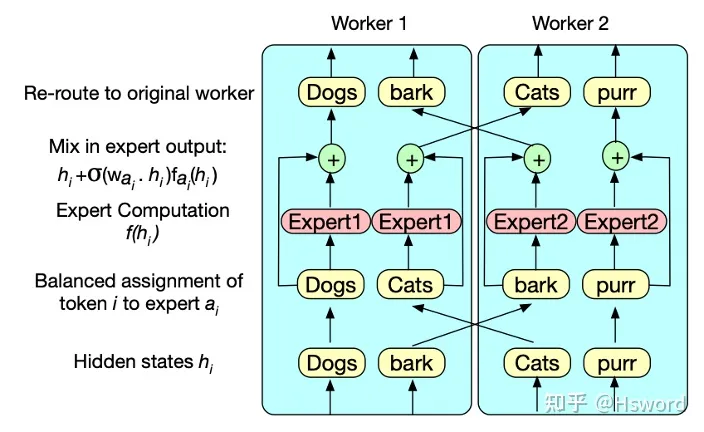
图7. Facebook BASE Gate示意图
6. Hash
来自于Facebook,将token按照给定的Hash函数映射给expert。
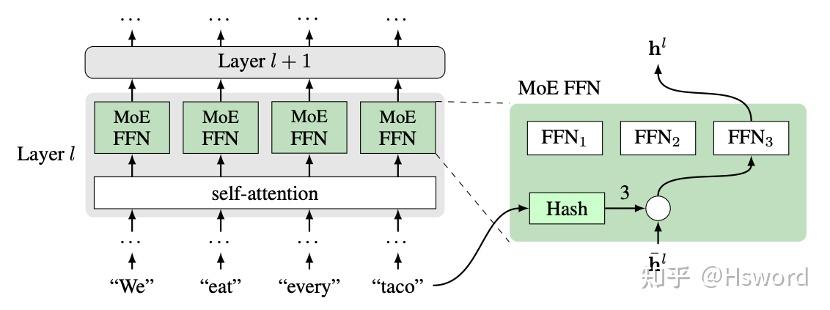
图8. Facebook Hash Gate示意图
7. Dense-To-Sparse
来自于河图团队,提出了一种动态自适应可学习的Gate机制DTS,在训练早期,token会倾向于使用较多的experts;随着模型逐渐收敛,逐渐趋向于更稀疏的expert选取。
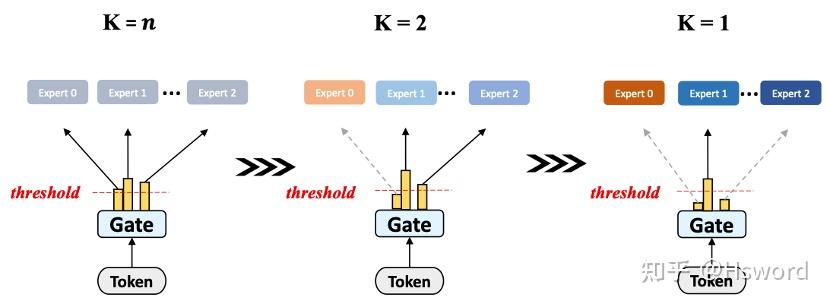
图9. 河图团队Dense-To-Sparse Gate示意图
四、系统实现和优化:
MoE系统的执行流程可以抽象为下图:input tokens首先经过gate network,获得token到expert的映射。基于此映射,对input tokens做Layout Transform操作,把发往同一个expert的tokens放在物理上连续的存储空间。然后启动All2All通信,将数据发往对应的expert所在的device。Expert收到分配给自己的数据后,进行计算,并将计算结果再通过All2All发回原有位置,最后进行一个Reverse Layout Transform,是之前Layout Transform的逆过程,将计算结果放回原有的位置。


图10. MoE系统执行流程抽象
技术点1: Top k算子优化
相比于PyTorch实现的通用Top k算子,我们对MoE模型中常见的Top k(k较小)进行了优化。Hetu Top k的效率相对PyTorch提高约25%。
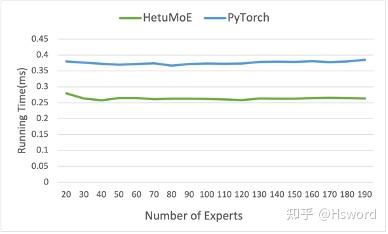
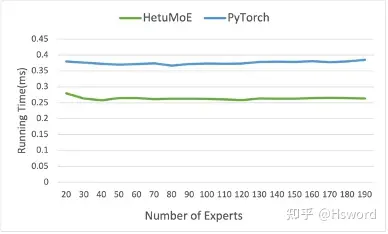
图11 (a). TopK算子优化结果(不同Expert数量)
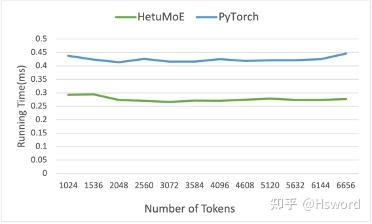
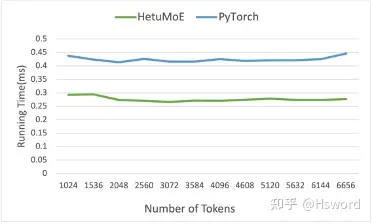
图11 (b). TopK算子优化结果(不同Token数量)
技术点2: Layout Transform算子优化
在使用Gate确定token对应的expert index后,需要进行Layout Transform,将发往同一个expert的token放在物理上连续的存储空间。Expert计算结束后,需要进行相反的操作,将计算结果发往原来的位置。


图12. Layout Transform操作示意图。
我们对上述操作进行了kernel的优化,分别测试batch size为16,32,64时的结果,性能相对于Tutel提升约26%。
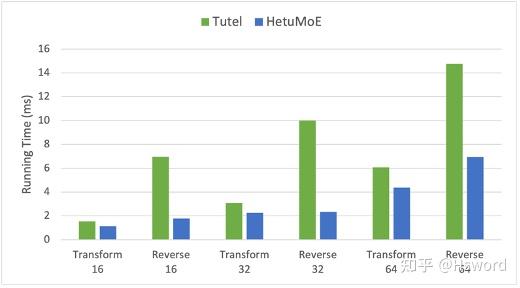
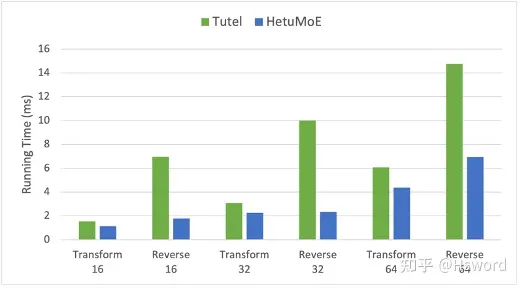
图13. Layout Transform实验结果
技术点3: Hierarchical AllToAll优化
NCCL并未实现专用的AllToAll通信算子,而是并行化Send/Recv操作。如图8所示,每个GPU有长度为4的数据需要进行AllToAll操作。GPU0会启动4个点对点通信(P2P),每个P2P通信的消息大小为1。对于 NN N 个节点,每个节点 GGG 张GPU,每个GPU数据量为 BBB 的情形下,点对点通信量为 BNG\frac{B}{NG}\frac{B}{NG} 。
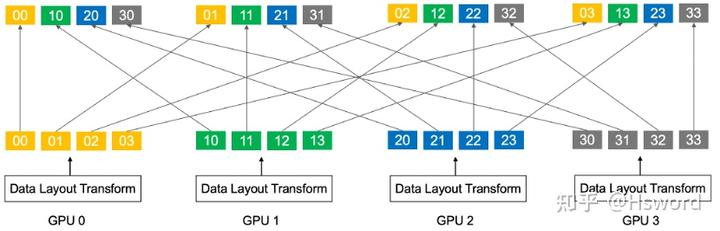
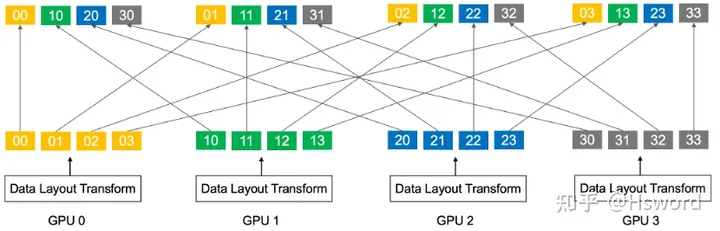
图14. AllToAll操作示意图
当机器增多时,由于点对点通信量过小,无法充分利用网络带宽。我们采取了Hierarchical AllToAll的优化, 实现了混合网络通信优化(NvLink和NiC)和消息聚合。
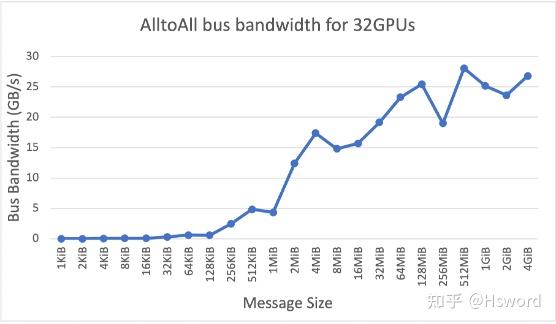
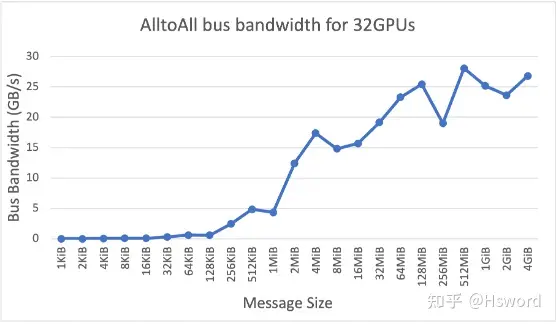
图15. NCCL AllToALl在不同Message Size大小下的带宽利用情况
如图9所示,首先在单个节点内,将单机内各GPU的数据通过NvLink传输到距离网卡(NiC)最近的GPU上(Gather),有效的利用了机器内的高速NvLink带宽。 其次进行Layout Transform,将发往同一个节点的数据放在物理上连续的存储空间。然后,在节点之间发起AllToAll通信,将聚合后的小心进行一次性通信。等每个机器取得自己所需的数据后,再进行一次Layout Transform,将数据按GPU id进行组织。最后将数据通过NvLink分发给各GPU(Scatter)。 通过Hierarchical AllToAll,我们利用了混合的网络链路,并将网卡间的信息传输量从原有的 BNG\frac{B}{NG}\frac{B}{NG} 提升到了 BGN\frac{BG}{N}\frac{BG}{N} ,将消息大小提升了 G2G2G2 倍。
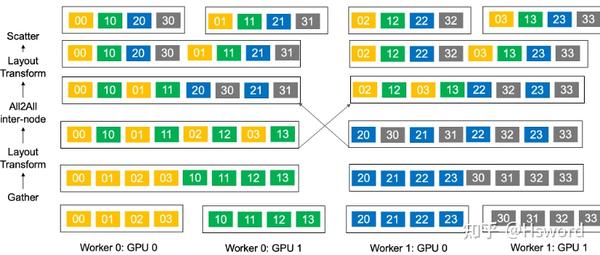
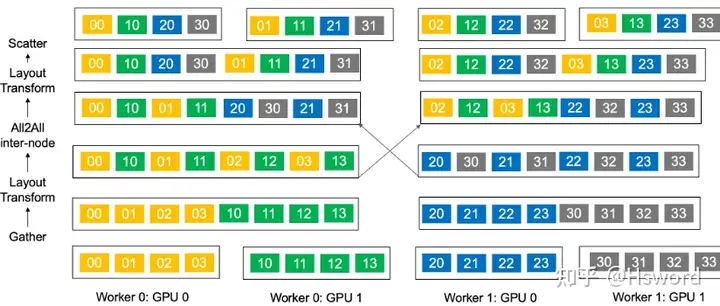
图16. Hierarchical AllToAll操作示意图
实验数据显示,在4节点32卡情形下,层次AllToAll获得1.66倍的加速;在8节点64卡情形下,层次AllToAll获得2倍加速。
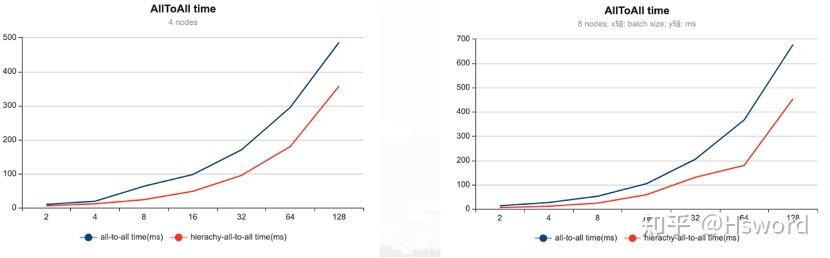
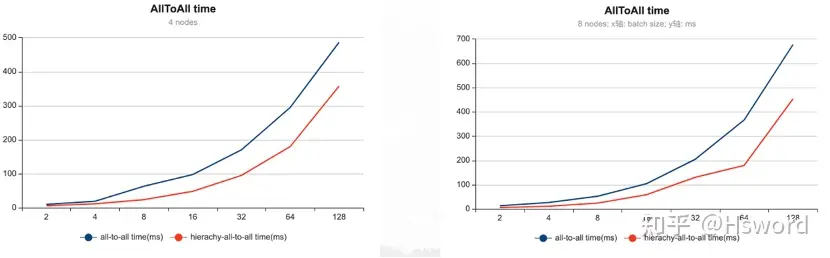
图17. Hierarchical AllToAll实验结果
五、实验对比结果:
我们对比的MoE的系统包括FastMoE,Tutel和DeepSpeed。在我们的Titan RTX集群(机器间1Gbps网络,机器内PCIe 2.0)下,我们对比了上述系统在Swtich和GShard Gate下MoE Layer的实验效果, 每块GPU下Expert的数量固定为2。 每个expert具体为hidden size为2048的FeedForward Network。 输入数据的sequence length为1024, embedding dimension为2048。
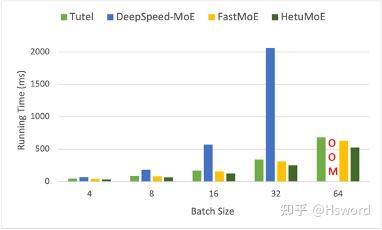
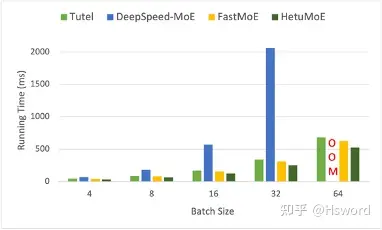
图18 (a). 端到端性能对比(Switch)
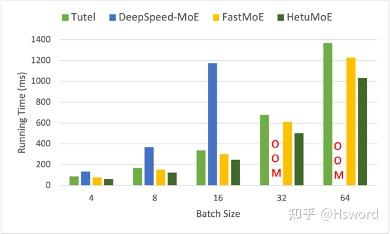
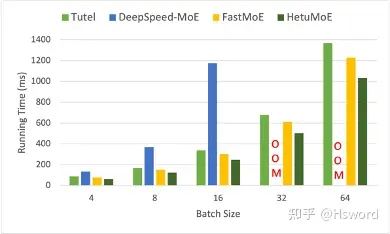
图18 (b). 端到端性能对比(GShard)
实验表明,HetuMoE性能显著优于现有的MoE系统,在执行MoE Layer上有至少15%的性能提升。对于Switch Gate(Top 1),在batch size=32的情况下,相比于DeepSpeed最高可达8.1倍的加速比。
目前我们已经与腾讯公司展开合作,在真实场景下进行上述技术和系统的落地应用,为构建万亿规模的大规模预训练模型提供系统性支持。我们的系统已经开源在Github,欢迎大家star:

如果我们的工作对您有帮助,欢迎引用我们的论文:

此外,我们Hetu团队还维护了一份MoE论文列表,帮助大家跟进相关工作。该列表初步分为了算法、应用、系统三部分,现已经更新了超过30篇相关工作,并且还会持续更新,推荐给大家,欢迎大家star,fork和参与pr。
Awesome-Mixture-of-Experts-Papersgithub.com/codecaution/Awesome-Mixture-of-Experts-Papers
河图(Hetu)是由北京大学数据与智能实验室(PKU-DAIR)自主研发的分布式深度学习系统,相比现有的老牌分布式深度学习框架,在系统功能性、系统复杂性和系统易用性上有诸多创新贡献,如自动分布式并行策略、一致性协议和通信架构、算子优化、显存优化、编译优化等方面。目前实验室围绕河图AI框架已经展开了多方面的研究工作,包括机器学习/深度学习系统优化、AutoML、图机器学习、AI4DB等,发布了多个开源项目,不断丰富完善河图生态,相关成果被SIGMOD、VLDB、ICML、KDD、ICDE、CVPR等国际顶级会议收录,并与腾讯、阿里巴巴、快手等多家企业展开合作和应用。
参考
- ^Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
- ^Du N, Huang Y, Dai A M, et al. GLaM: Efficient Scaling of Language Models with Mixture-of-Experts[J]. arXiv preprint arXiv:2112.06905, 2021.
- ^Shazeer N, Mirhoseini A, Maziarz K, et al. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer[J]. arXiv preprint arXiv:1701.06538, 2017.
- ^Fedus W, Zoph B, Shazeer N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity[J]. arXiv preprint arXiv:2101.03961, 2021.
- ^Lepikhin D, Lee H J, Xu Y, et al. Gshard: Scaling giant models with conditional computation and automatic sharding[J]. arXiv preprint arXiv:2006.16668, 2020.
- ^Roller S, Sukhbaatar S, Weston J. Hash layers for large sparse models[J]. Advances in Neural Information Processing Systems, 2021, 34.
- ^Yang A, Lin J, Men R, et al. M6-t: Exploring sparse expert models and beyond[J]. arXiv preprint arXiv:2105.15082, 2021.
- ^Jiang H, Zhan K, Qu J, et al. Towards More Effective and Economic Sparsely-Activated Model[J]. arXiv preprint arXiv:2110.07431, 2021.
- ^Lewis M, Bhosale S, Dettmers T, et al. Base layers: Simplifying training of large, sparse models[C]//International Conference on Machine Learning. PMLR, 2021: 6265-6274.
- ^Nie X, Cao S, Miao X, et al. Dense-to-Sparse Gate for Mixture-of-Experts[J]. arXiv preprint arXiv:2112.14397, 2021.

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)