
langchain学习笔记——Ollama大模型本地部署
大模型本地部署、大模型网关部署、快速构建一个带有知识库的问答系统
前言
本篇笔记主要内容来自小破站楼兰老师的教学视频,再加上自己的一些理解,看一遍相当于看了一遍视频教程,可以节省很多时间,属于入门教程,此外基础的环境搭建,大模型对接,相关基础概念,交互方式,存储记忆,tools工具调用,RAG等内容可以按顺序看我之前的笔记快速入门。
tips:有些我觉得值得记下来的内容我懒得打字,太消耗时间,就直接截图了,希望不要介意~
入门篇一基础概念及快速搭建
入门篇二LCEL链式表达式
入门篇三Redis实现记忆
入门篇四记忆整合LCEL链
入门篇五tools工具调用
入门篇六RAG基础
小目标

Ollama本地部署deepseek
Ollama是一个可以在本地运行的大模型服务平台:ollama
Ollama安装与基本使用
点击下载并选择对应版本
下载完之后在cmd中看看版本以及help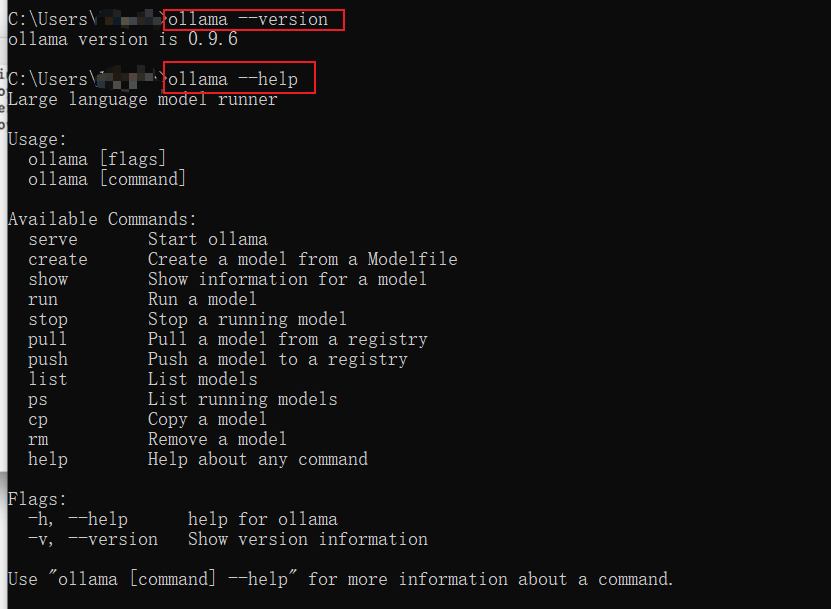
这些命令也很简单,见面知意
ollama中支持的大语言模型: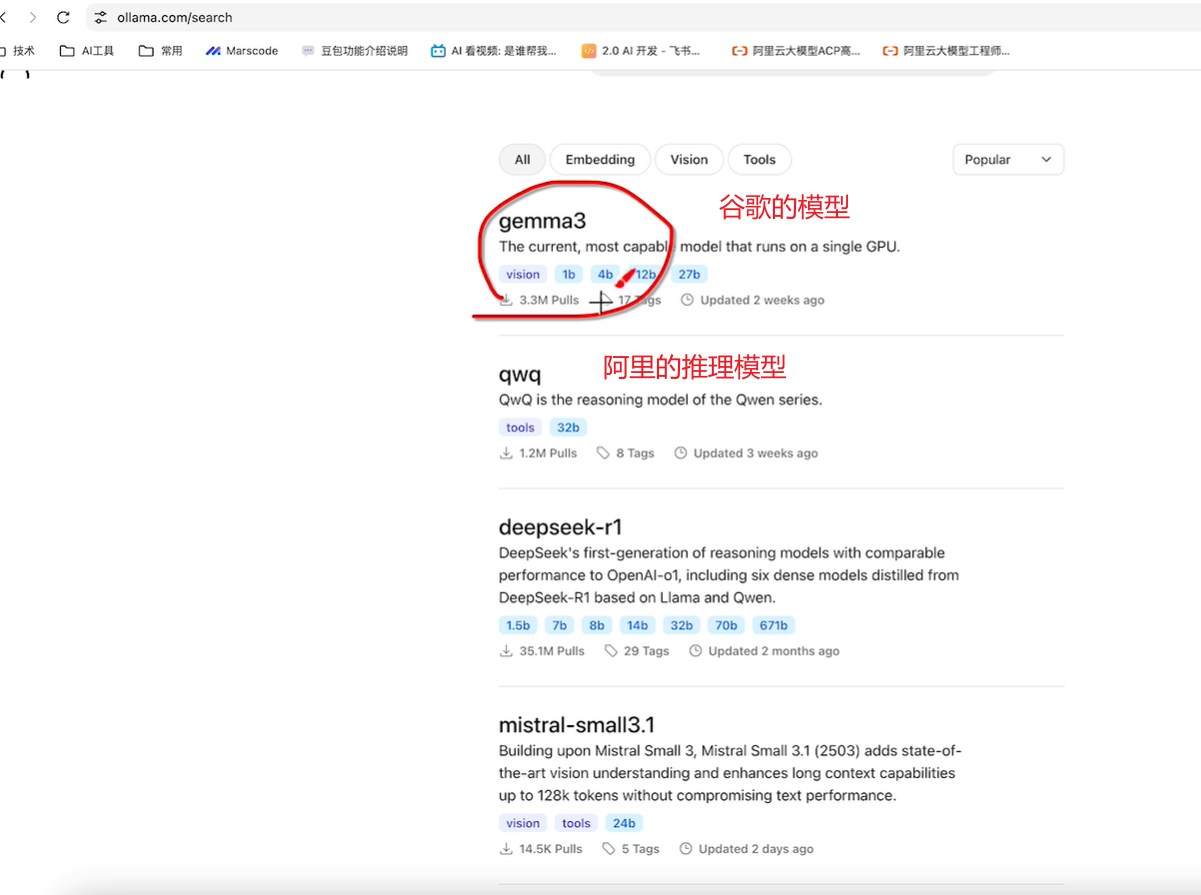
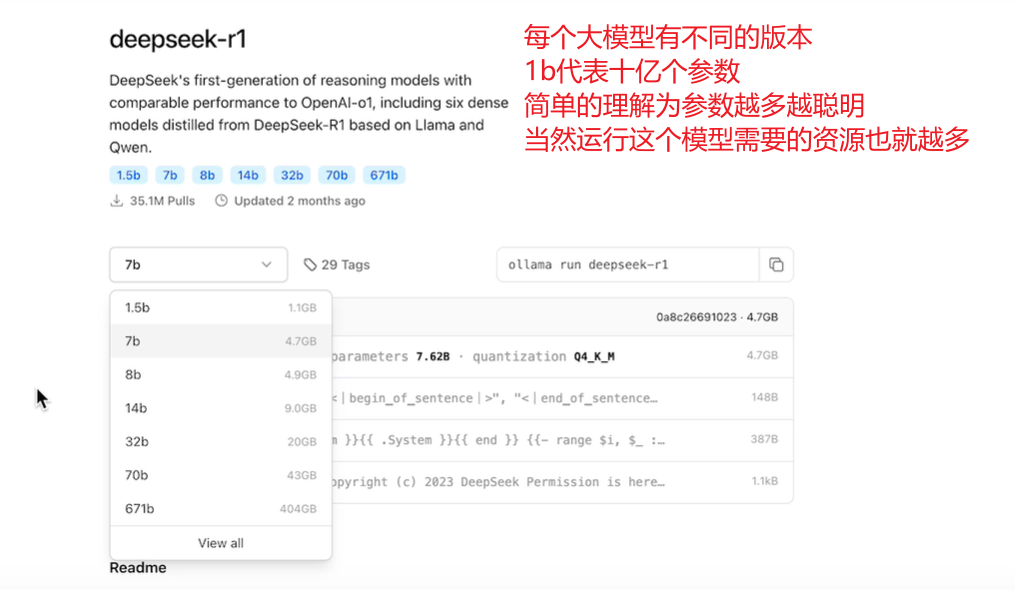
我们这里选择最小的模型,输入命令会自动下载并启动:ollama run deepseek-r1
我这边已经下好了,可以键入ollama list看看有哪些模型:
运行测试一下:ollama run deepseek-r1:1.5b
ctrl + d退出
额外的补充:
本地应用调用Ollama模型
代码很简单:
import os
from langchain_community.chat_models import ChatOllama
from langchain_openai import ChatOpenAI
def ollamaModel(context):
llm = ChatOllama(model="deepseek-r1:1.5b", base_url="http://localhost:11434")
response = llm.invoke(context)
return response
def chatDeepSeekModel(context):
llm = ChatOpenAI(model="deepseek-r1:1.5b",base_url="http://localhost:11434/v1",openai_api_key="123")
response = llm.invoke(context)
return response
if __name__ == '__main__':
# res = ollamaModel("你是谁?")
res = chatDeepSeekModel("讲一个简短的笑话")
print(res.content)
11434是ollama的默认端口
主要有两种方式,一种是ollama提供的,还有是ollama也兼容openai的接口协议,所以也可以使用openai的接口来调用,不过地址哪里要多一个/r1,以及传入一个apikey,这个apikey随意传即可。
测试一下:
咋是英文的…
调用ollama的的Embedding模型
直接下载下来即可:ollama pull nomic-embed-text
调用:
安装依赖:pip install langchain_ollama
langchain_ollama 中有一个类是OllamaEmbeddings,就是Embedding的实现类
代码:
from langchain_ollama import OllamaEmbeddings
ollama_embeddings = OllamaEmbeddings(model="nomic-embed-text", base_url="http://localhost:11434")
embedding = ollama_embeddings.embed_query("我是小林")
print("embedding=",embedding)
print("size=",len(embedding))


关于模型大小和显存需求
20G表示参数需要20G,如果你需要用模型来做推理,基本上大致需要2倍大小的显存即40G,如果是要做微调大致需要3倍。
目前openai的模型似乎没有开源
部署One-API大模型网关
基本概念
用本地机器部署大模型毕竟还是收到一点资源的限制,往往很难去跑满血的版本。
我们对大模型的应用可以拆开,对于那些不需要传递敏感信息的功能,可以去调用一些开源的大模型来用,对于某一些像rag这种有敏感信息的,再切换到本地模型去处理,提供过协调来让质量得到提高。
当然对于用户来说对接太麻烦了,一会用这个用这个一会用那个。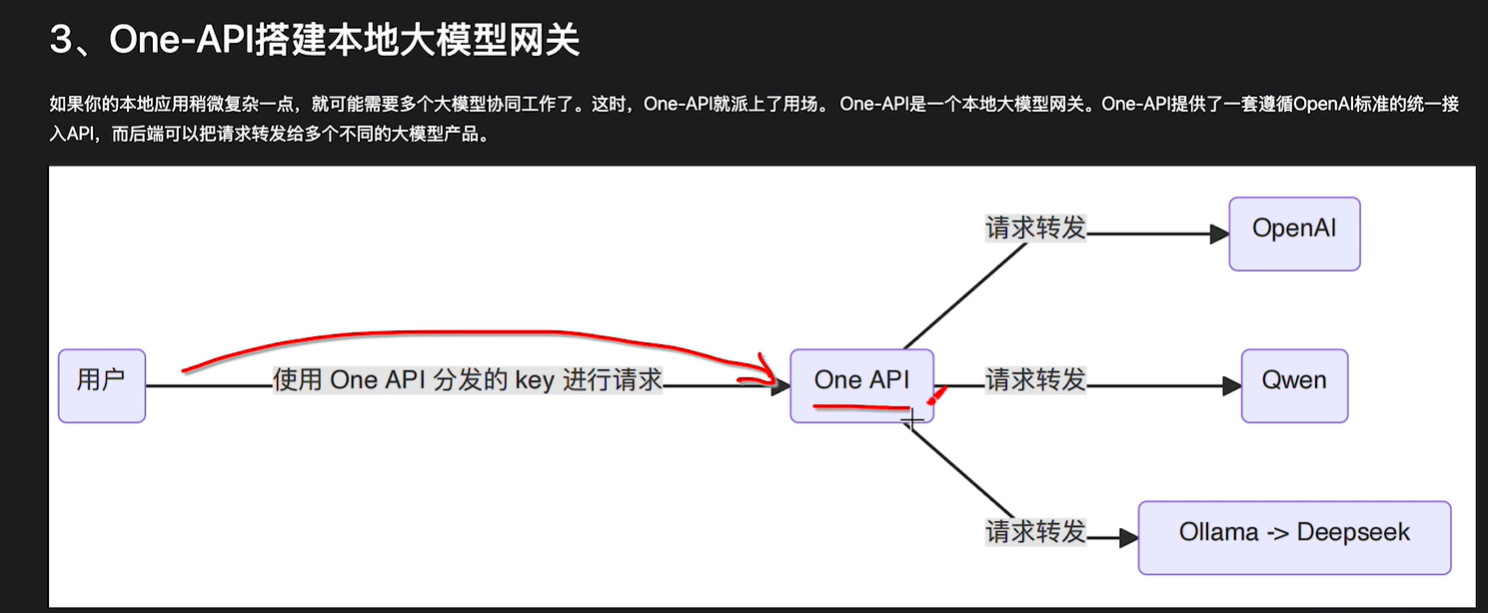
One-API的安装与部署
官网:One-API
一点说明:竟然是一个应用,那么他有一些自己需要保管的信息,元数据,SQLite是基于内存的数据库,不需要部署对应的服务,直接跑就可以了,如果是mysql的则需要搭建一个数据库,把数据保存到数据库中: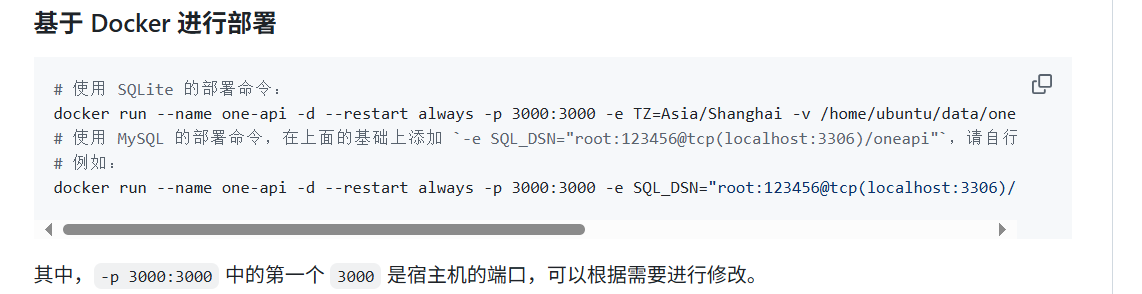
docker run --name one-api -d --restart always -p 3000:3000 -e TZ=Asia/Shanghai -v /home/ubuntu/data/one-api:/data justsong/one-api
这里把/home/ubuntu/data/one-api改成自己的,笔者把ubuntu改成了自己的用户名(虚拟机中装的docker)
可以键入docker ps看一下运行中的服务:
访问一下Oon-API的页面:
这里笔者是虚拟机中部署的,所以localhost改为虚拟机的地址,此外接口默认是3000,这在我们部署的命令那里的3000就是这个设置:
这里首次进来是需要登录的
默认是root 123456
现在需要做一些配置
首先是渠道:即One-API后端可以对接哪些大模型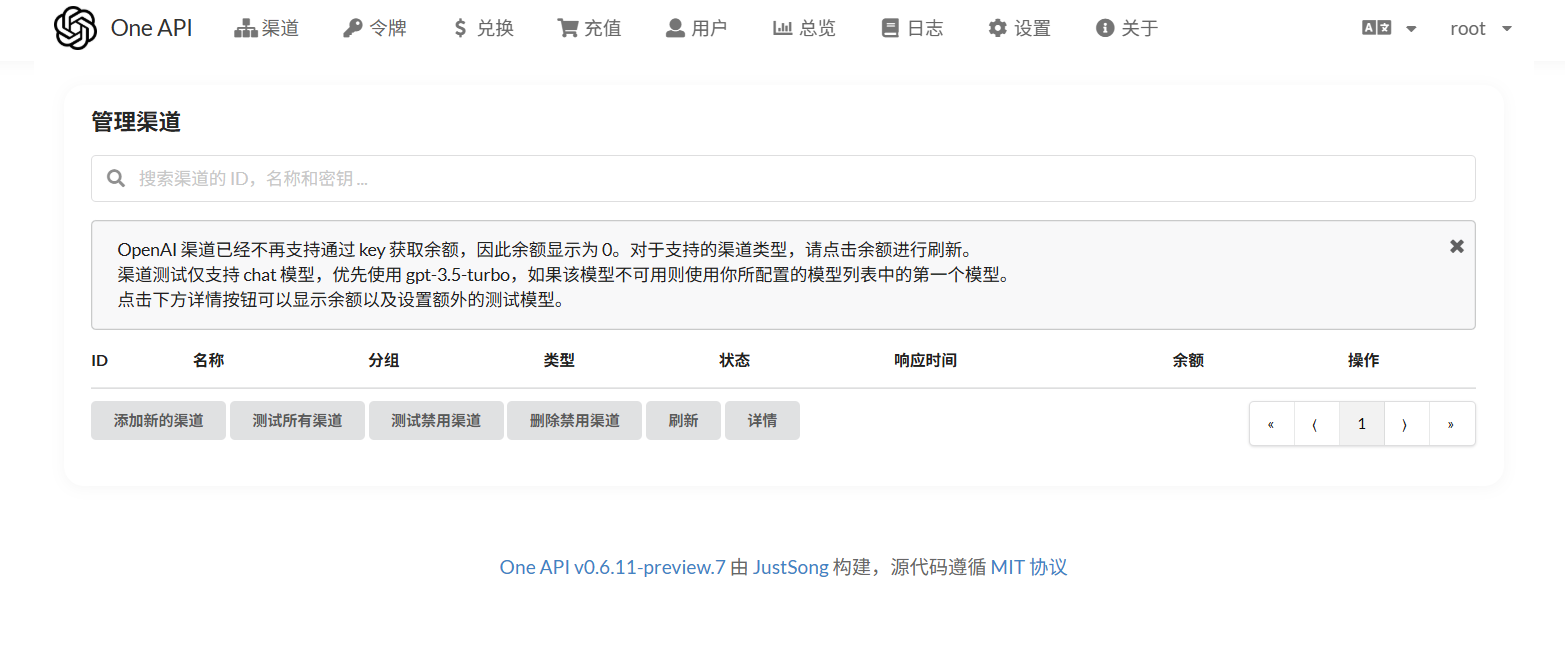
添加渠道: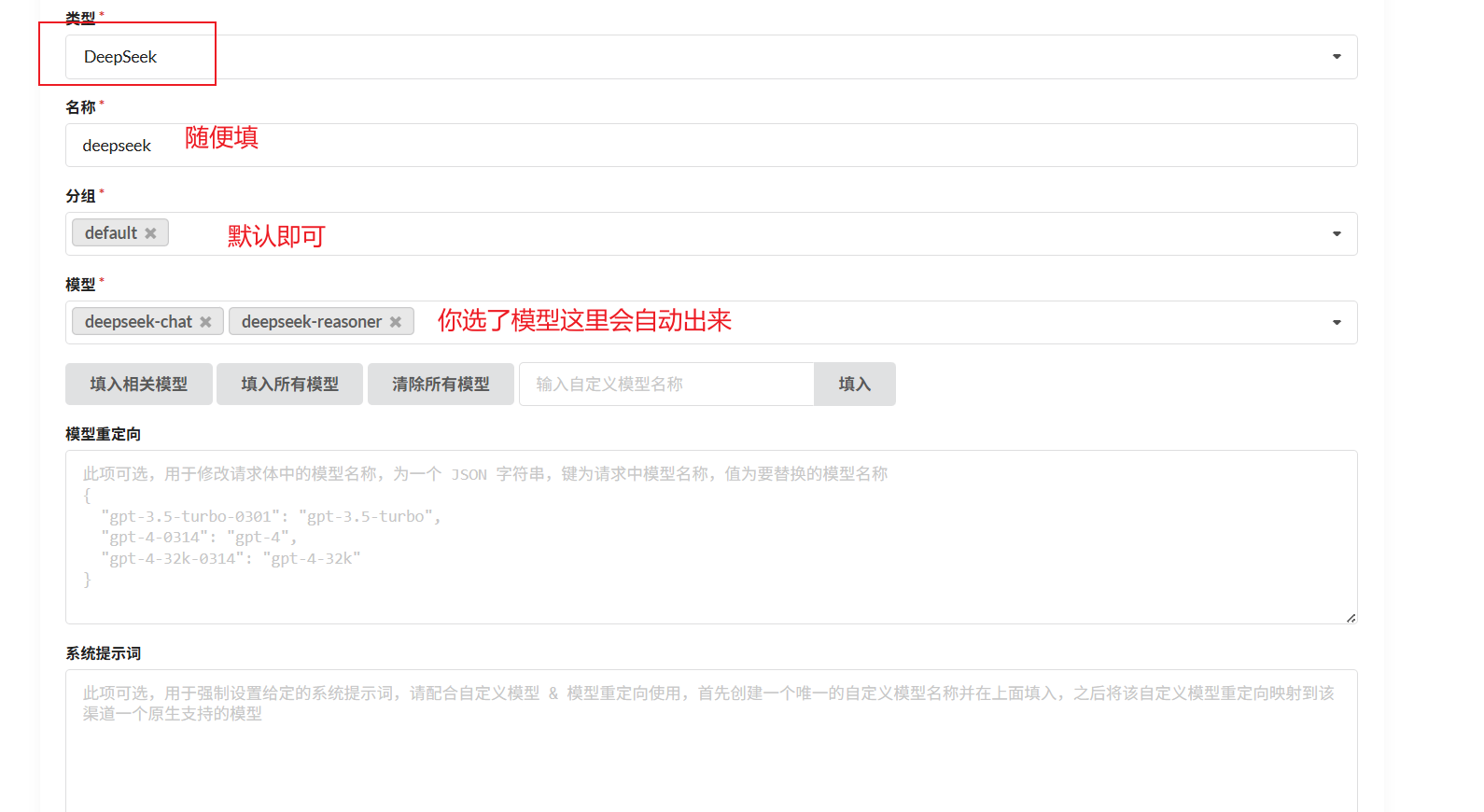
下面还有一栏密钥填入即可。
点击测试可以测试一下:但这里为啥输出GPT-4o呢…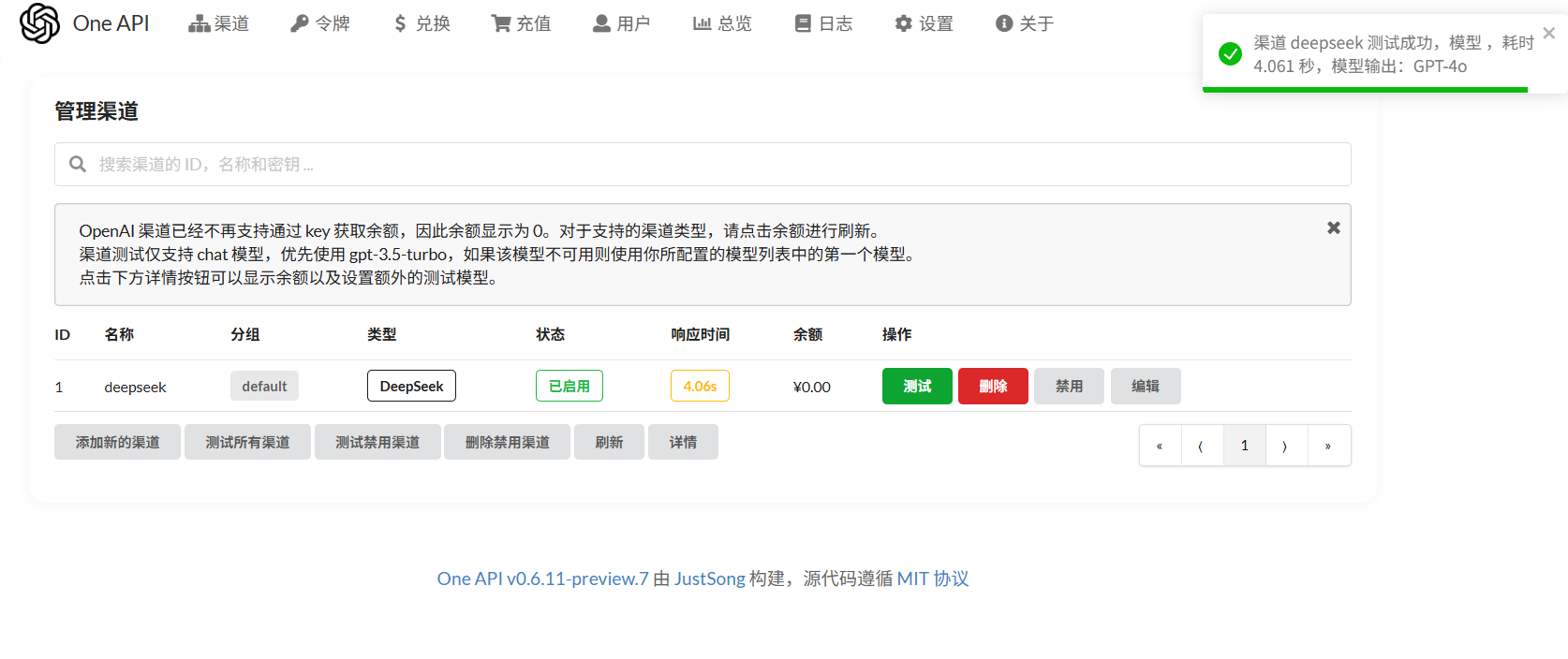
也可以配置Ollama的
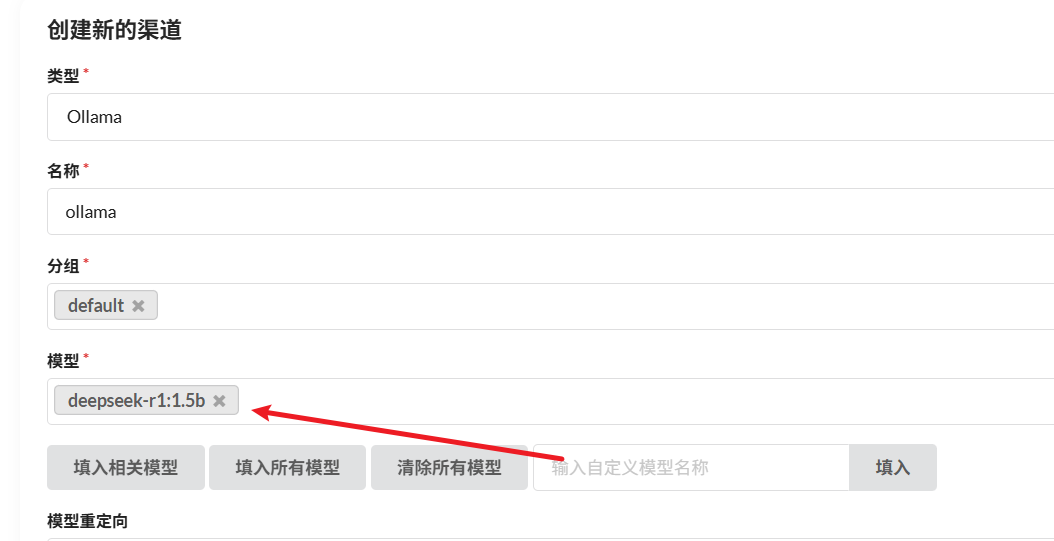
注意这里代理:
docker运行在宿主机上,oneapi运行在docker里,外界访问宿主机,把请求发给docker,docker转给oneapi,如果你的本地模型部署在宿主机上,就还要在访问ollama,这里的代理地址即提供了这个功能
不过我的宿主机是虚拟机,外面是我的windows主机,所以代理地址是我的本机ip,第一次测试的时候拒绝。
排查过程:
确认Windows端Ollama监听状态:netstat -ano | findstr :11434
没问题,监听的是0.0.0.0
确认虚拟机与主机的网络连通性:ping 192.168.56.1
也没问题
尝试端口扫描:telnet 192.168.56.1 11434
显示被拒绝,可能被防火墙屏蔽了
以管理员身份打开powershell输入命令:New-NetFirewallRule -DisplayName "Ollama" -Direction Inbound -Action Allow -Protocol TCP -LocalPort 11434
都没啥用…最后打开ollama的设置: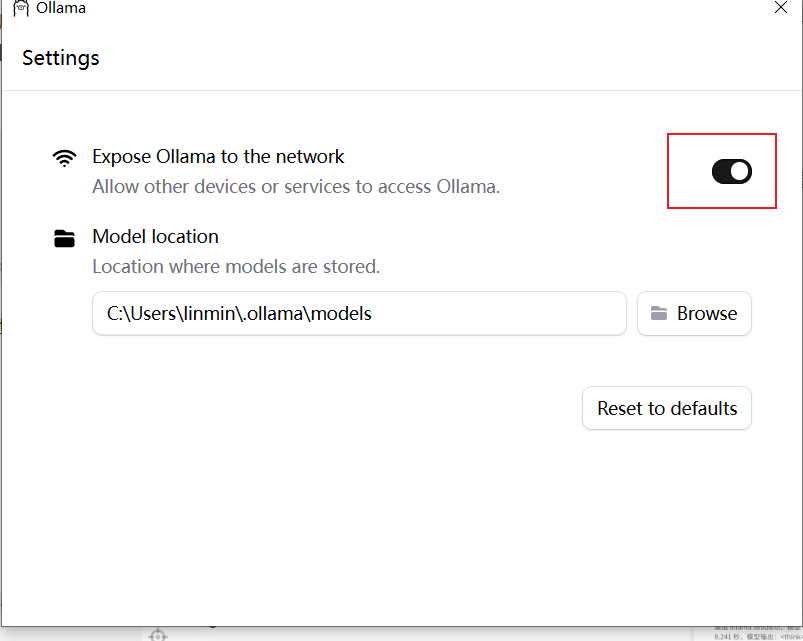
暴露到network打开就好了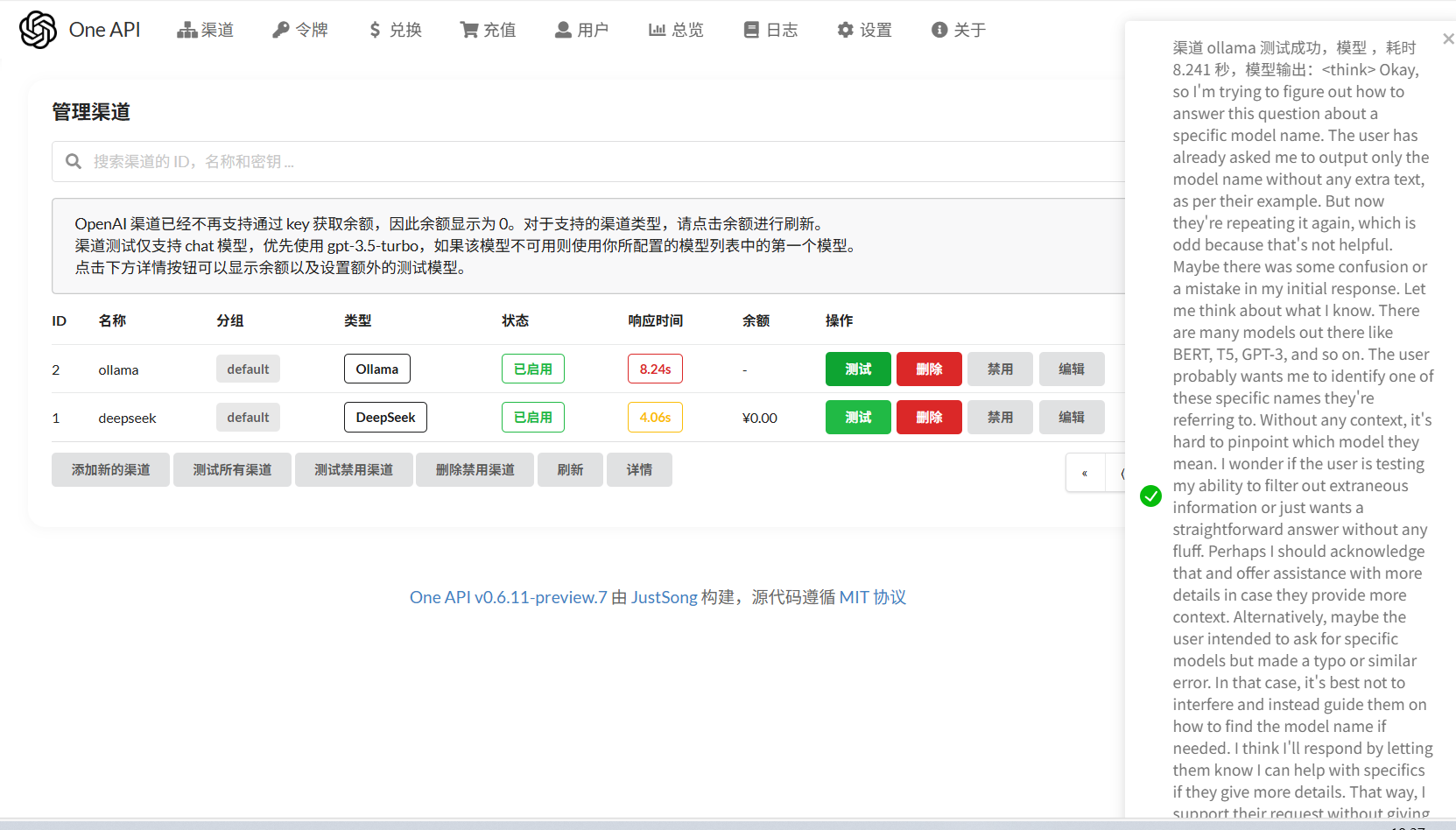
终于成功了
接下来要获得一个oneapi的apikey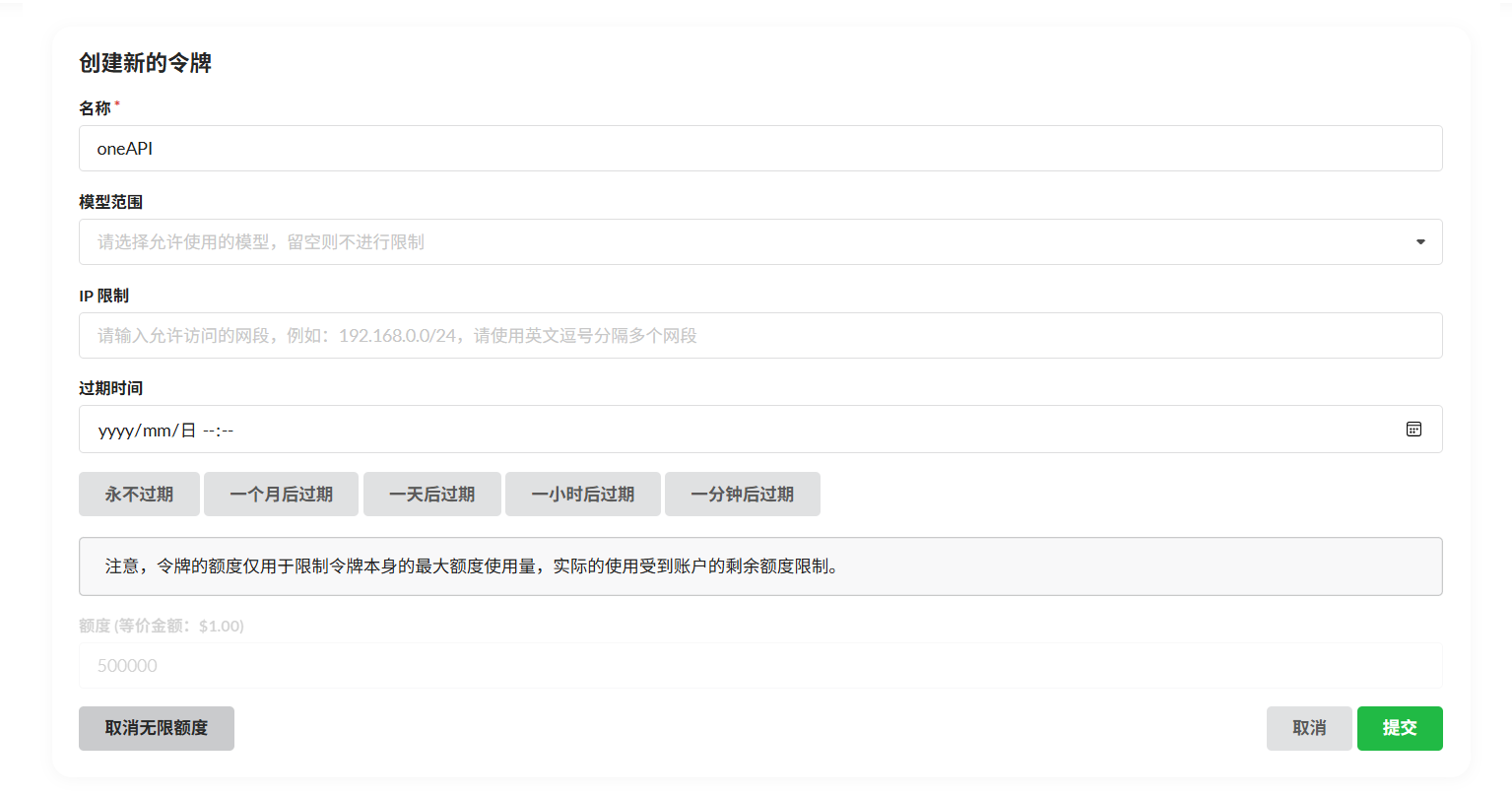
通过One-API访问大模型
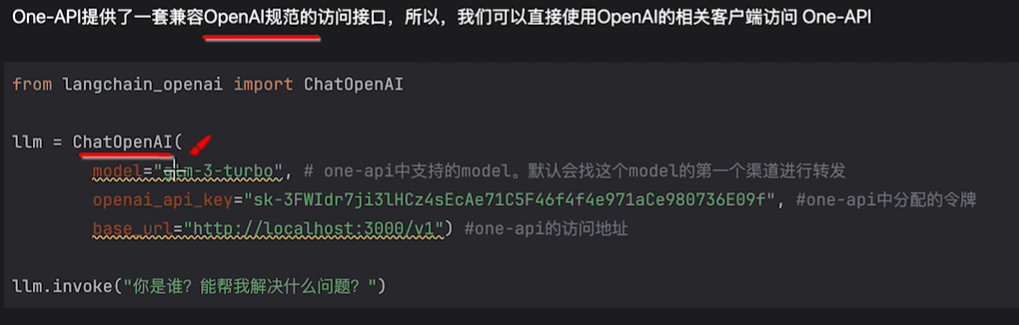
代码:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="deepseek-r1:1.5b", # oneapi中支持的model 默认会找这个model的第一个渠道进行转发
openai_api_key="sk-j59Q1OcVra02tVhMA645FdA45c4443B2B29a8e1481240eF4", # oneapi中分配的令牌
base_url="http://192.168.51.130:3000/v1" # one-api的访问地址 我这里是虚拟机中部署的所以不是localhost
)
res = llm.invoke("你是谁?")
print(res.content)
看一下结果:
换成deepseek-chat试试:
oneapi会根据模型的名字找对应的渠道,如果2个渠道里面有同样的模型名字,那么会找到第一个匹配的渠道。尽量不要让渠道里面的模型一样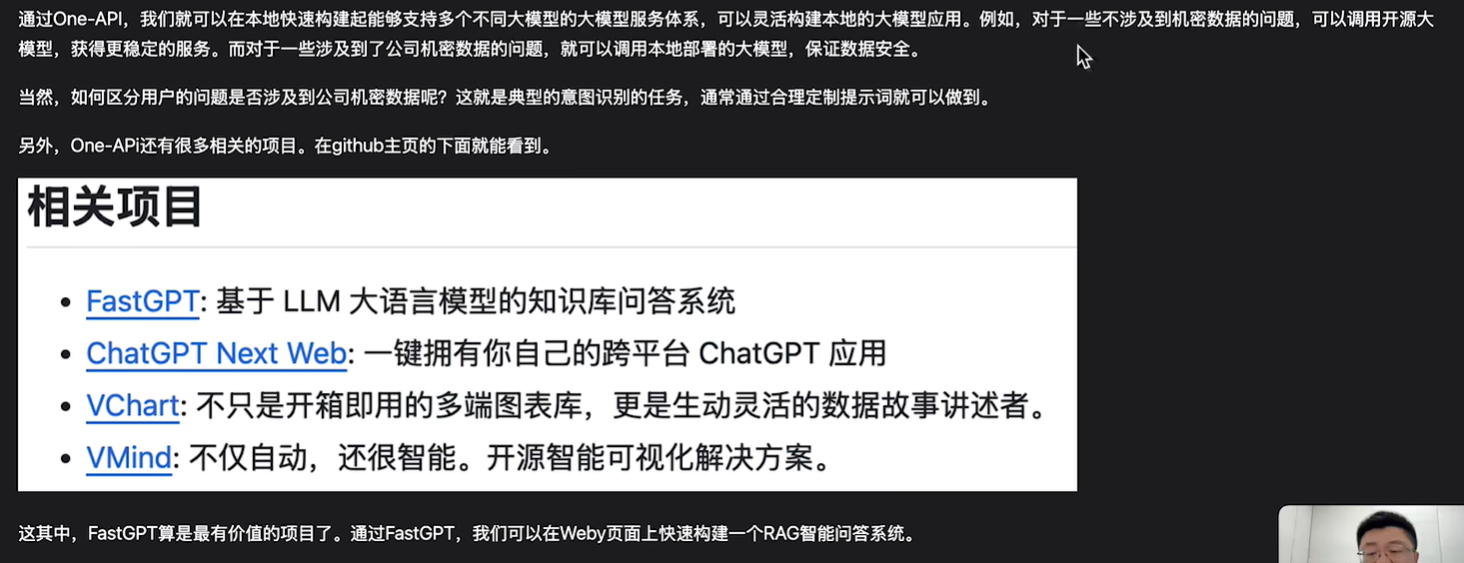
FastGPT搭建本地知识库

1-下载docker-compose.yml文件
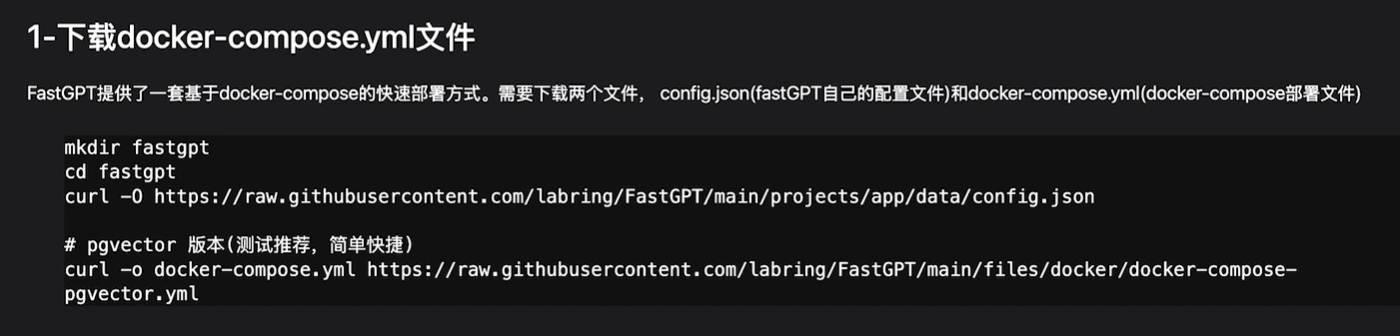
这是一种基于docker的快速部署的方式,依赖于它提供的一种compose文件来构建,这是docker的一种组合服务,总共需要哪些镜像,把他们打包起来了。
我们可以建一个文件,把它下下来:
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml
这里的第二个docker-compose文件是docker需要的服务配置文件
第一个config.json是fastgpt需要的配置文件
老师的版本需要在配置文件里改一下模型,新版本会在第一次访问的时候检测到没有模型让我们自己添加,所以这两个配置文件基本不用动
修改一下端口就好(因为我之前docker部署了oneapi占用了3000端口,fastgpt默认也会占用这个端口,所以我把fastgpt端口改成3080了,如果你没有冲突为问题可以不改)
2-启动并添加模型
两个文件下完后之后运行命令:
docker compose down #重启时需要
docker compose up -d
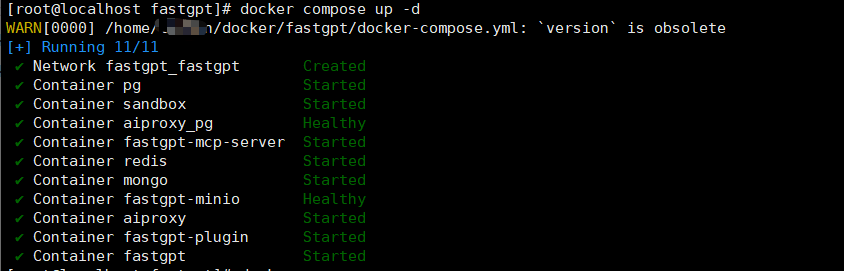
localhost访问3000(笔者是3080端口,我用windows主机访问就是192.168.51.130:3080)
看看页面:第一次登录root 1234
第一次访问还没有模型,会提醒让你配置模型
点击模型渠道像上文中的One-API一样配置两个语言模型: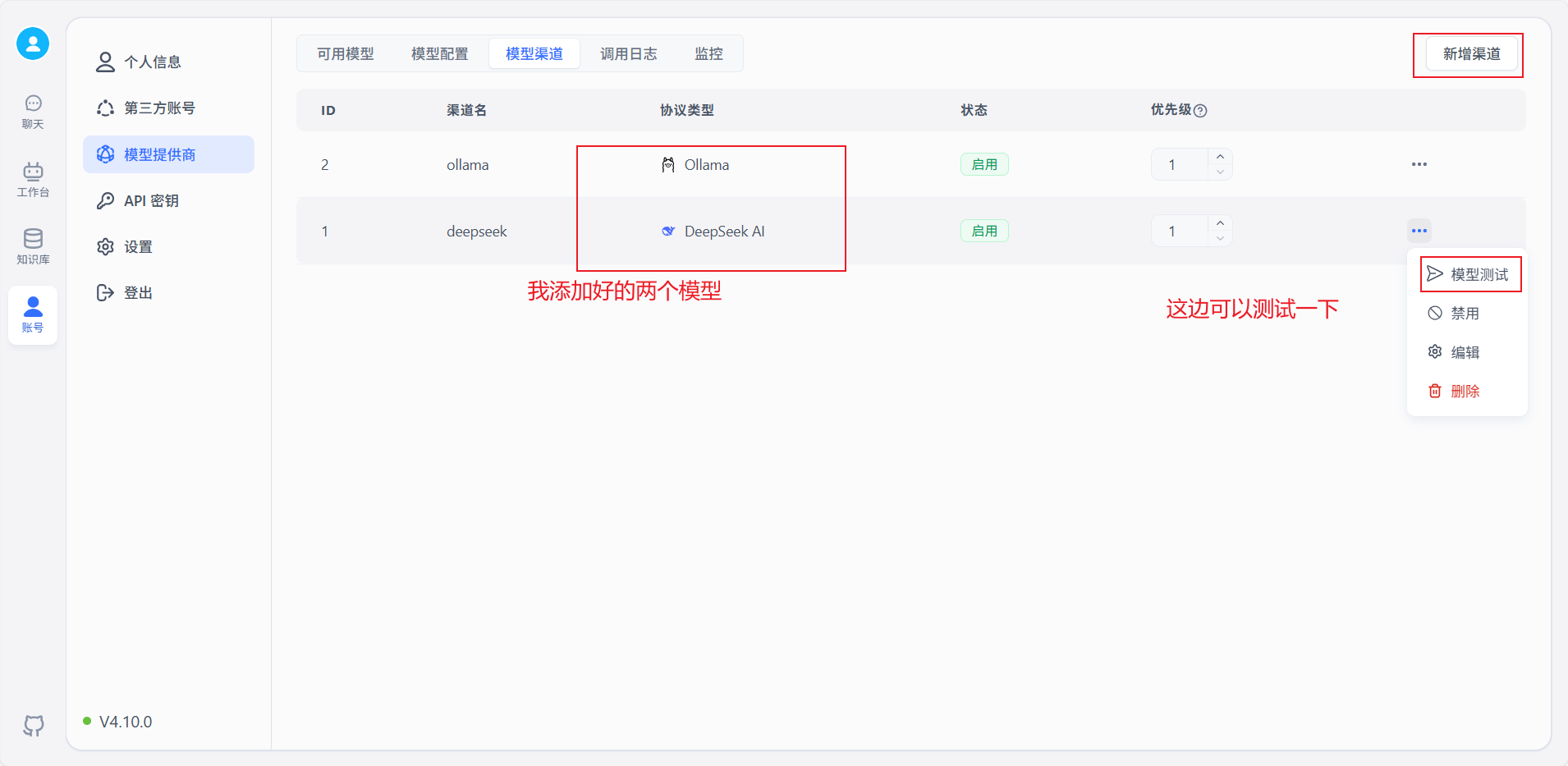
再添加一个索引模型: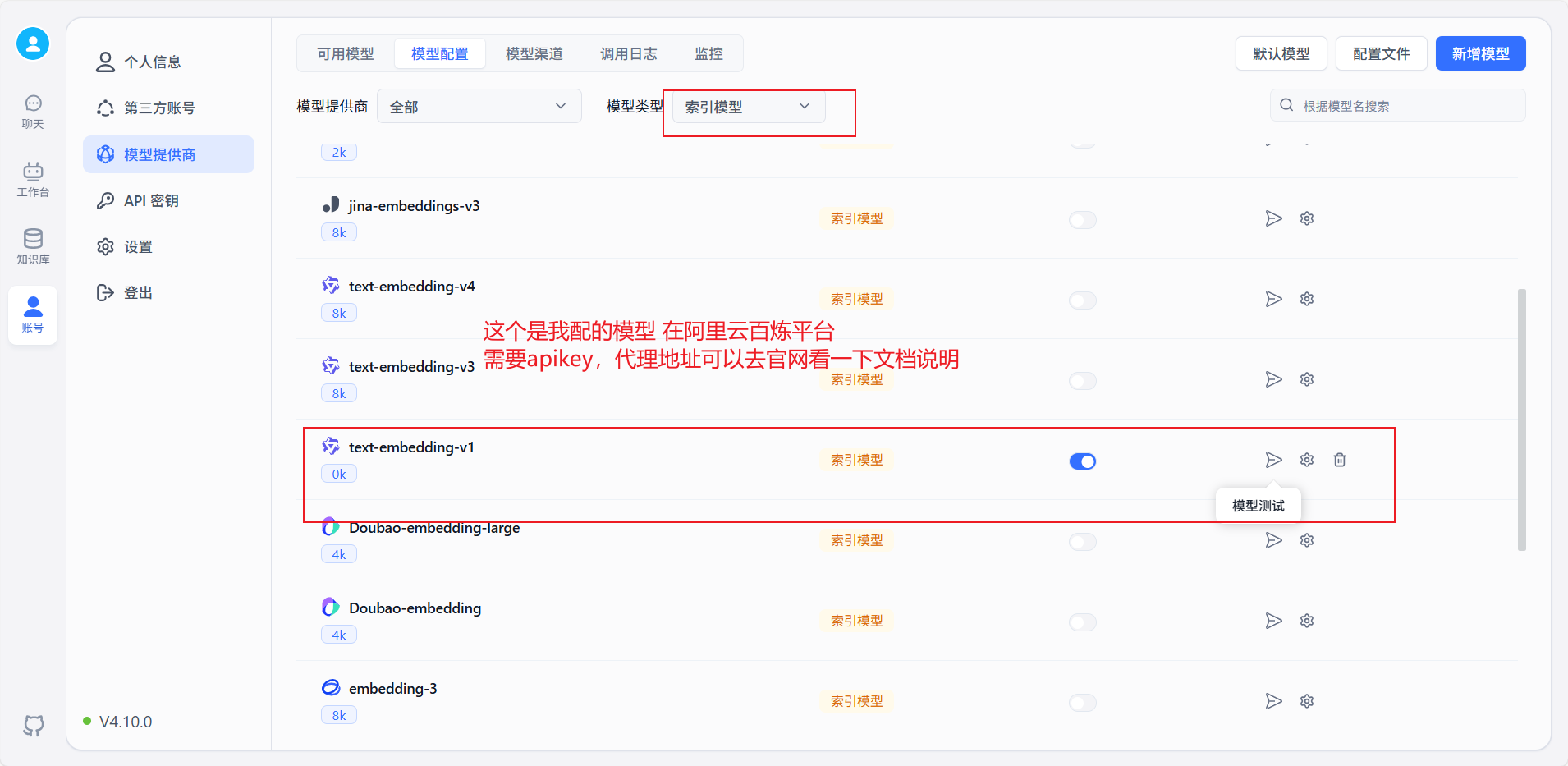
3-知识库构建:
创建一个简单的txt知识库文档:
创建一个知识库
看看结果: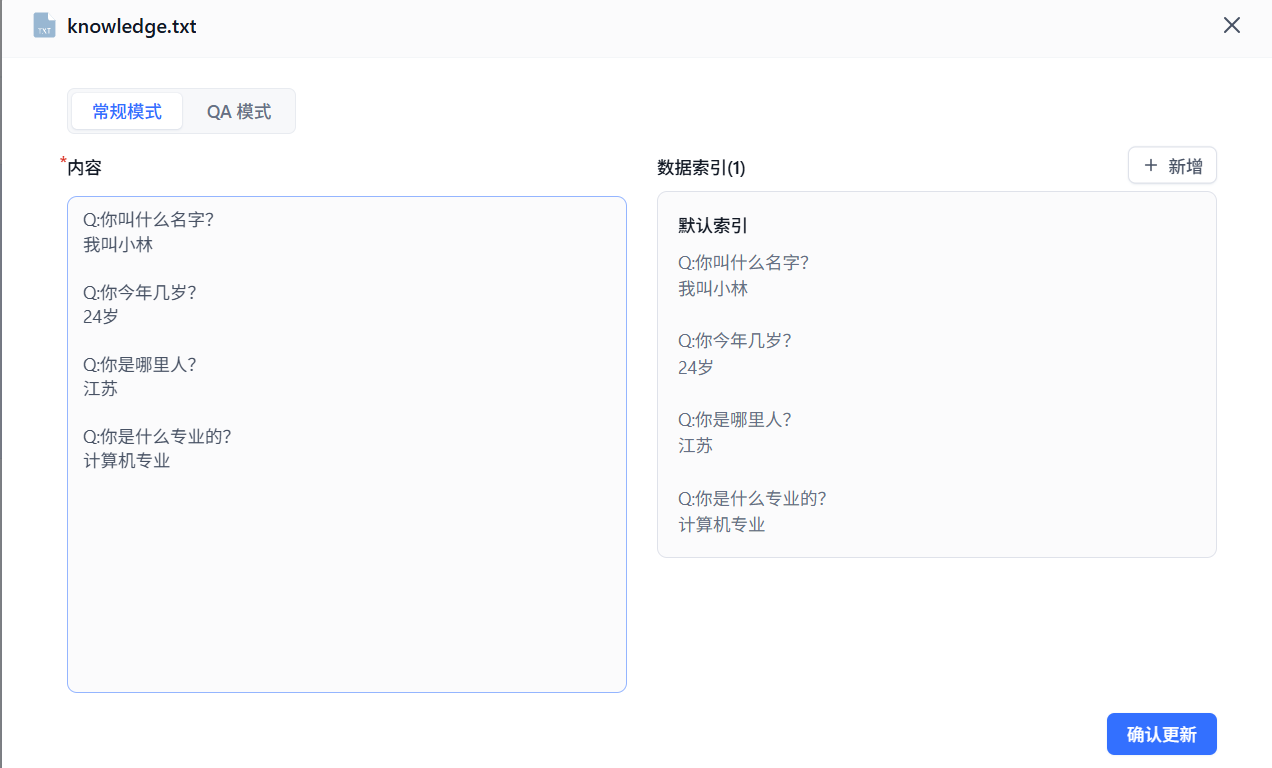
4-简易问答机器人构建
按图示步骤来即可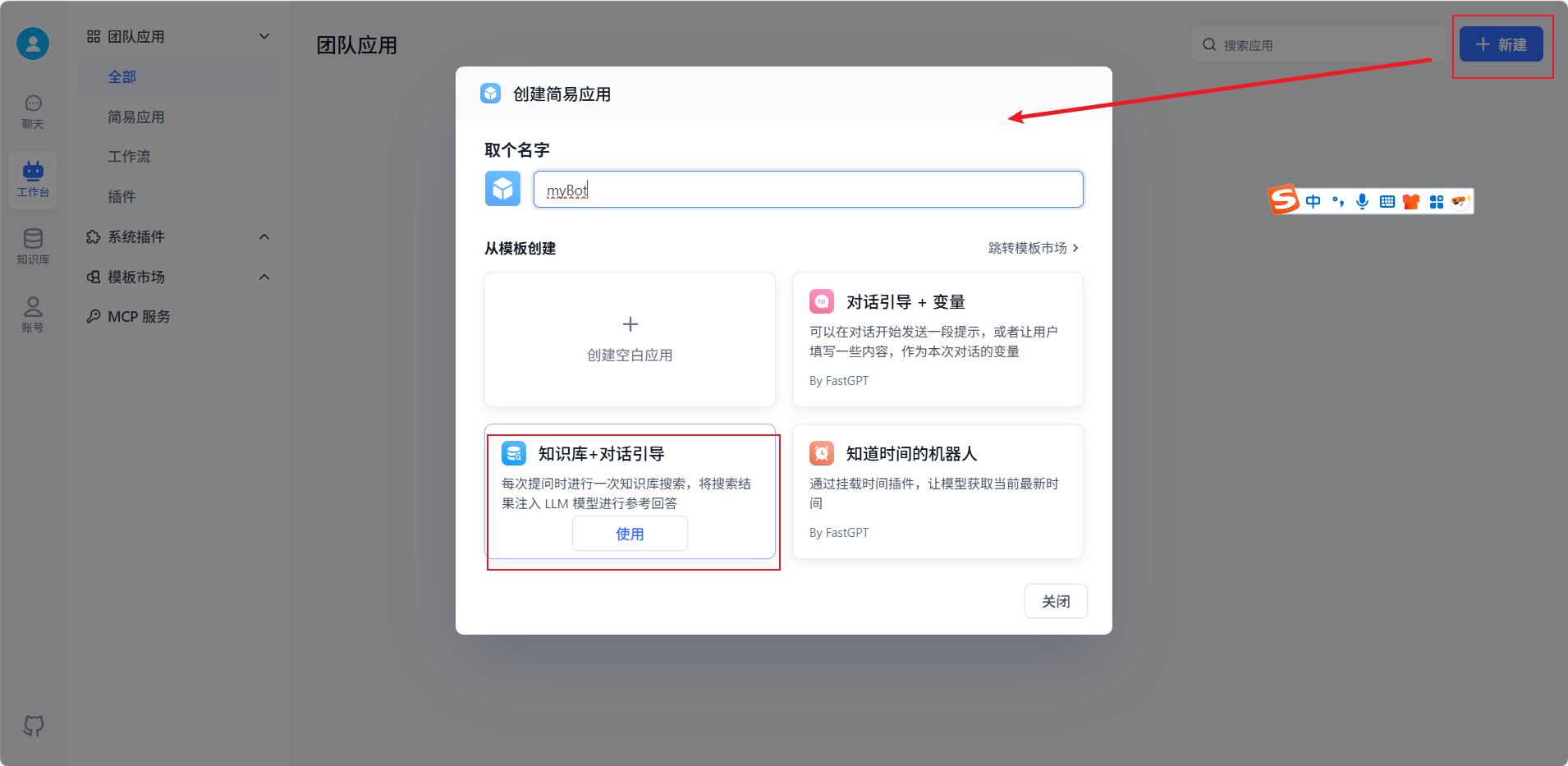
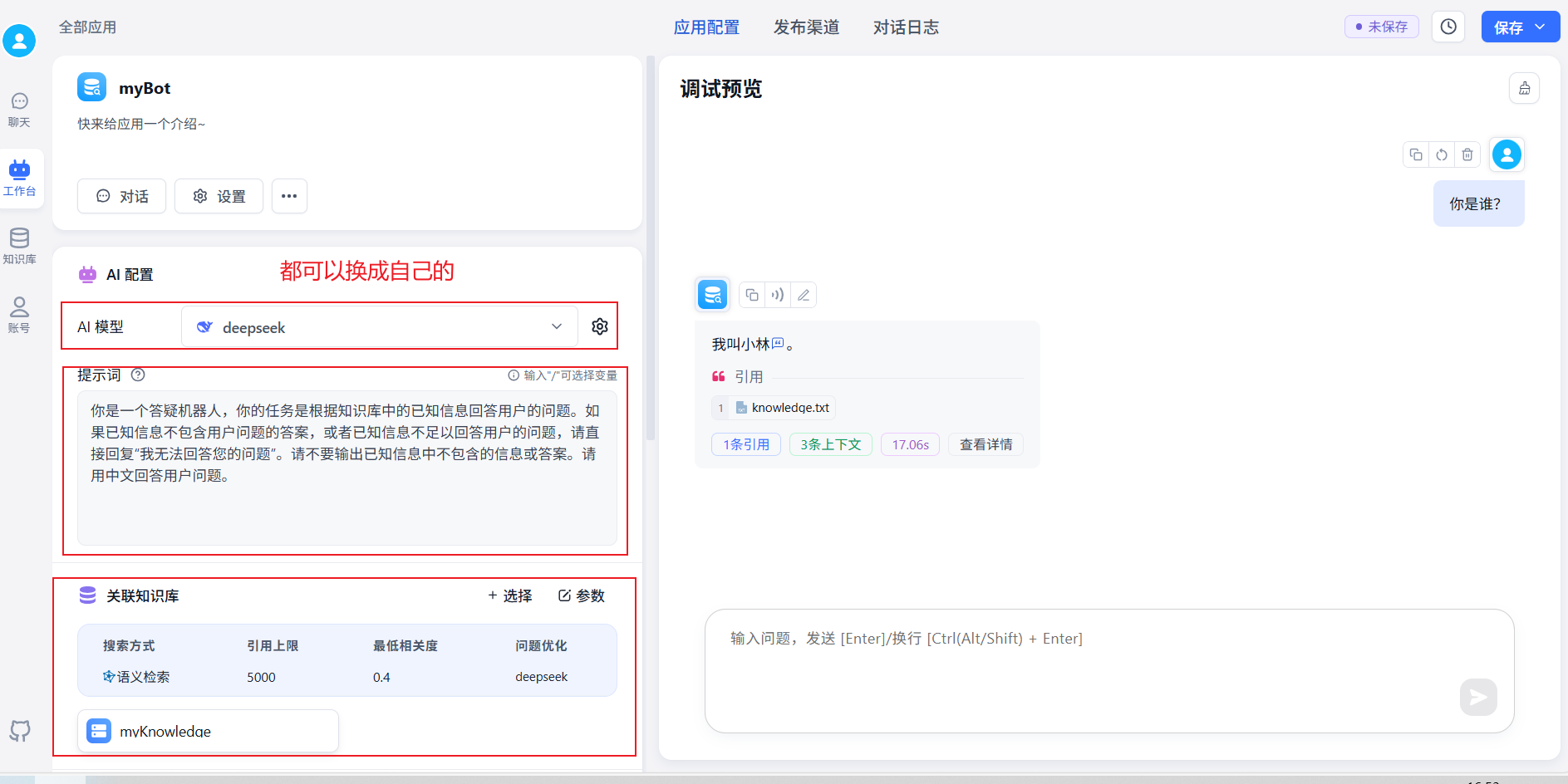
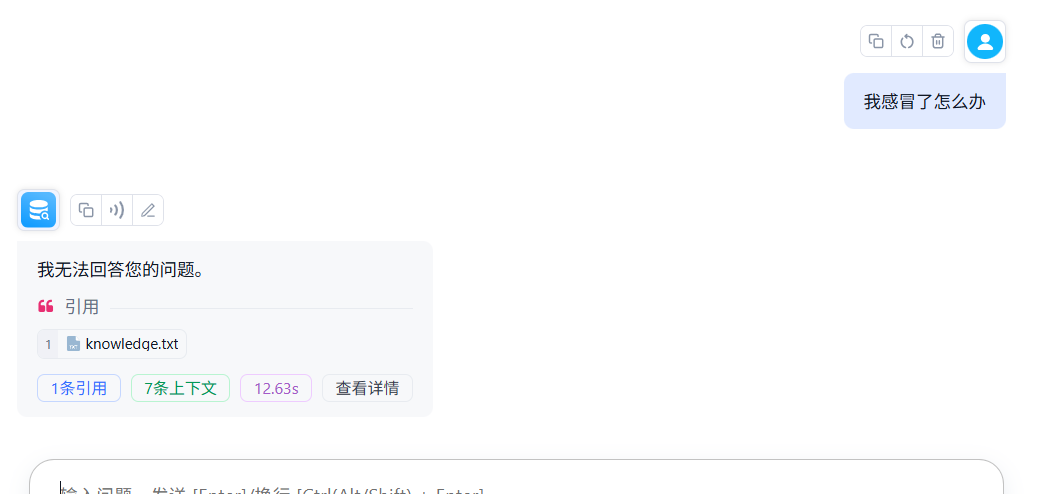
点击查看详情可以看到对话背后的流程: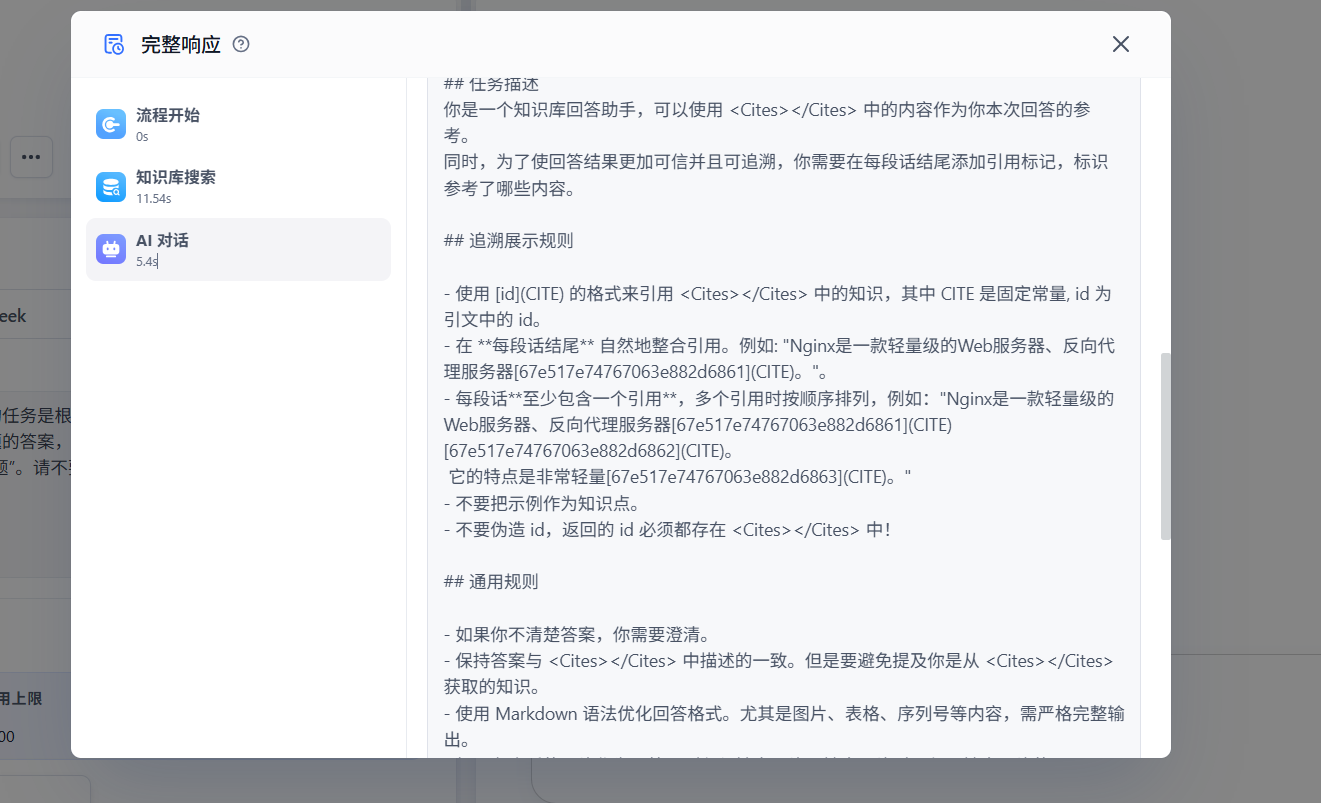
在测试一些其他问题: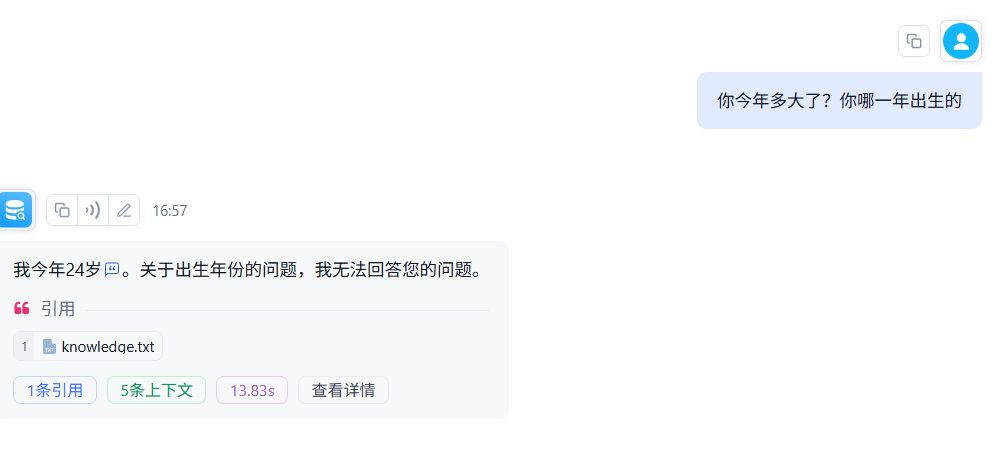
此外这里还可以创建工作流,就是用图形化的方式来构建chain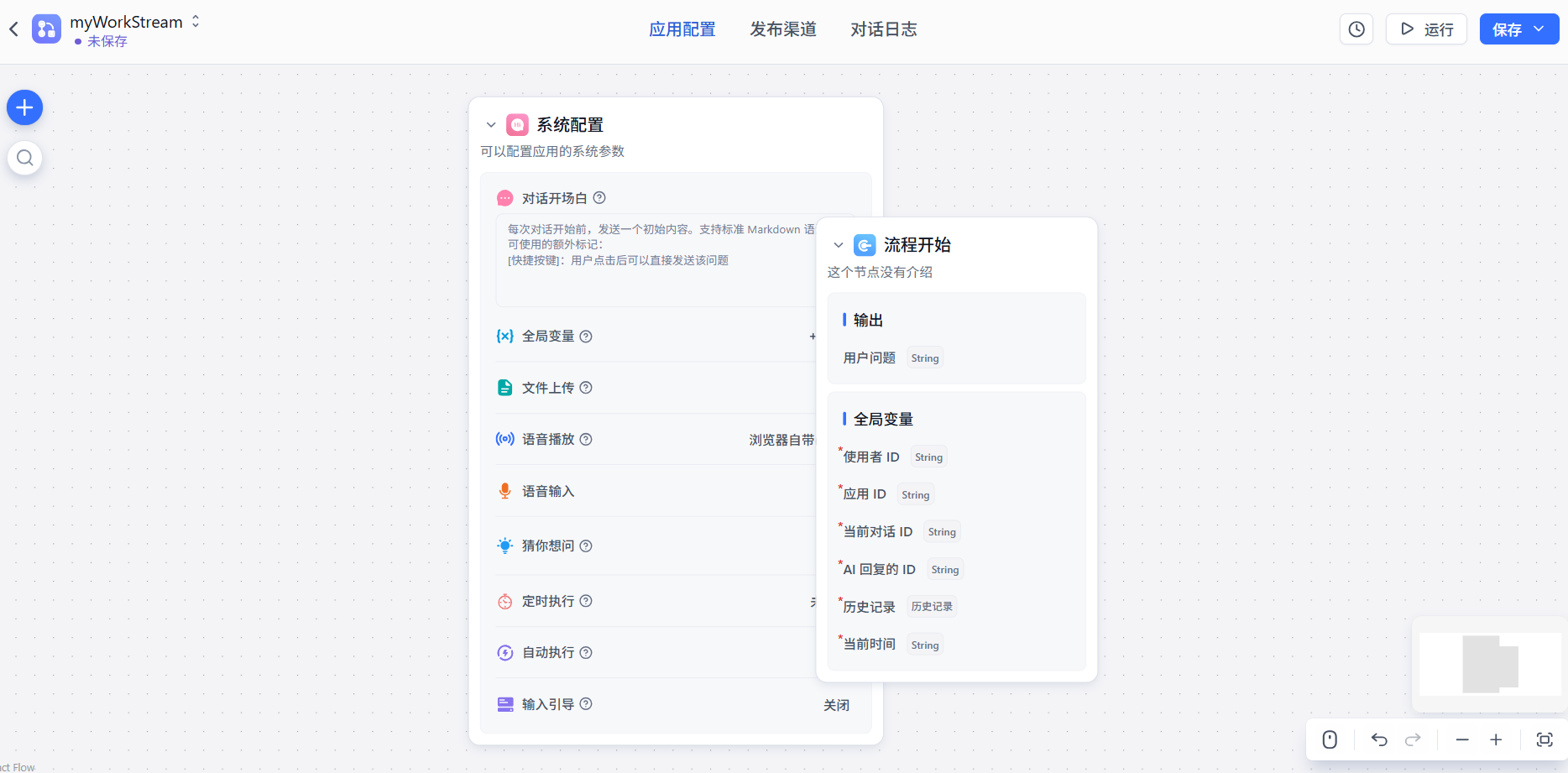
其实这个和dify、coze都是一样的,工作流的本质其实就是chain,只不过变成了图形化的方式来声明。
此外
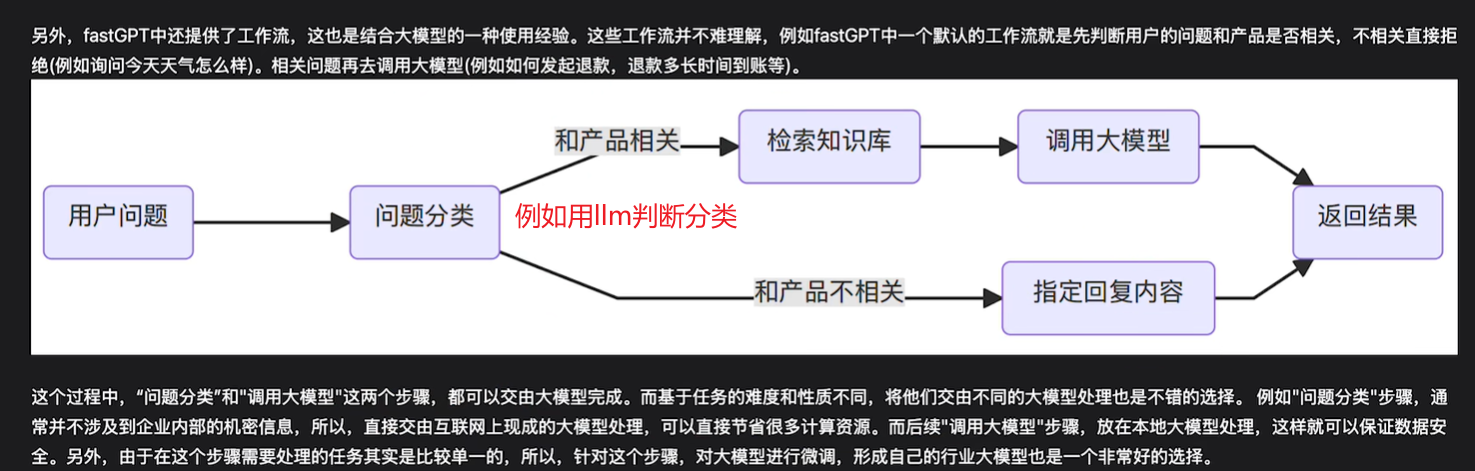
总结
本节我们学习了如何基于Ollama去部署本地大模型,如何基于One-API部署大模型网关,以及基于FastGPT生成一个知识库小对话小机器人。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)