
十本必读的机器学习论文!超详细整理总结
机器学习算法是 AI 系统执行任务的规则或流程,通过对数据的分析学习,自动挖掘规律和模式,用于预测、分类、聚类等任务,实现智能化数据分析处理。依据输入数据(标记或未标记),对数据模式评估,用于预测或分类。比如判断邮件是否为垃圾邮件(分类),预测股票价格(预测)。评估模型预测结果。与已知示例对比,衡量模型准确性,如计算预测值和真实值的差值。若模型与训练数据拟合欠佳,调整权重缩小已知样本与模型估计的差
机器学习算法是 AI 系统执行任务的规则或流程,通过对数据的分析学习,自动挖掘规律和模式,用于预测、分类、聚类等任务,实现智能化数据分析处理 。其工作原理涉及三个关键部分:
决策过程:依据输入数据(标记或未标记),对数据模式评估,用于预测或分类 。比如判断邮件是否为垃圾邮件(分类),预测股票价格(预测)。
误差函数:评估模型预测结果。与已知示例对比,衡量模型准确性,如计算预测值和真实值的差值 。
模型优化过程:若模型与训练数据拟合欠佳,调整权重缩小已知样本与模型估计的差异,重复 “评估 - 优化”,直至达精度要求 。
即插即用缝合模块+CVPR可复现论文![]() https://www.bilibili.com/opus/1057395247213969429?spm_id_from=333.1387.0.0
https://www.bilibili.com/opus/1057395247213969429?spm_id_from=333.1387.0.0
1. “ImageNet Classification with Deep Convolutional Neural Networks” by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton (2012)
这项研究展示了一个深度神经网络,它将 120 万张高分辨率 ImageNet 照片分为 1,000 个组。该网络有五个卷积层、三个全连接层和一个 1,000路 softmax 分类器。它有 6000 万个参数和 650,000 个神经元。测试集上的 top-1 和 top-5 错误率分别为 37.5% 和 17.0%,其表现明显优于早期模型。

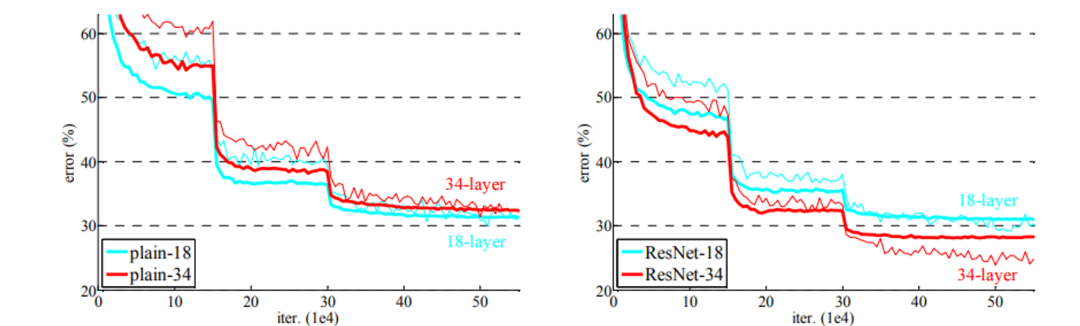
2. “Deep Residual Learning for Image Recognition” by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun (2015)
训练更深的神经网络面临巨大挑战。本文介绍了一种残差学习框架,旨在简化比以前使用的更深的网络的训练过程。该框架不是学习未引用的函数,而是重新制定层以根据先前层的输入学习残差函数。实证结果表明,这些残差网络更容易优化,并且受益于深度的增加,从而实现更高的准确性。
3. “A Few Useful Things to Know About Machine Learning” by Pedro Domingos (2012)
Pedro Domingos 的《关于机器学习你需要知道的几件事》探讨了机器学习算法如何在不需要人工指导的情况下从数据中学习。本文强调了机器学习对许多行业的重要性,包括网络搜索、垃圾邮件过滤和股票交易。根据麦肯锡全球研究所的报告,预测分析将引领下一波创新浪潮。尽管教科书丰富,但许多实践能力仍然难以掌握,这导致机器学习的发展速度放缓。Domingos 提供了重要的见解,以加快利用机器学习创建应用程序。
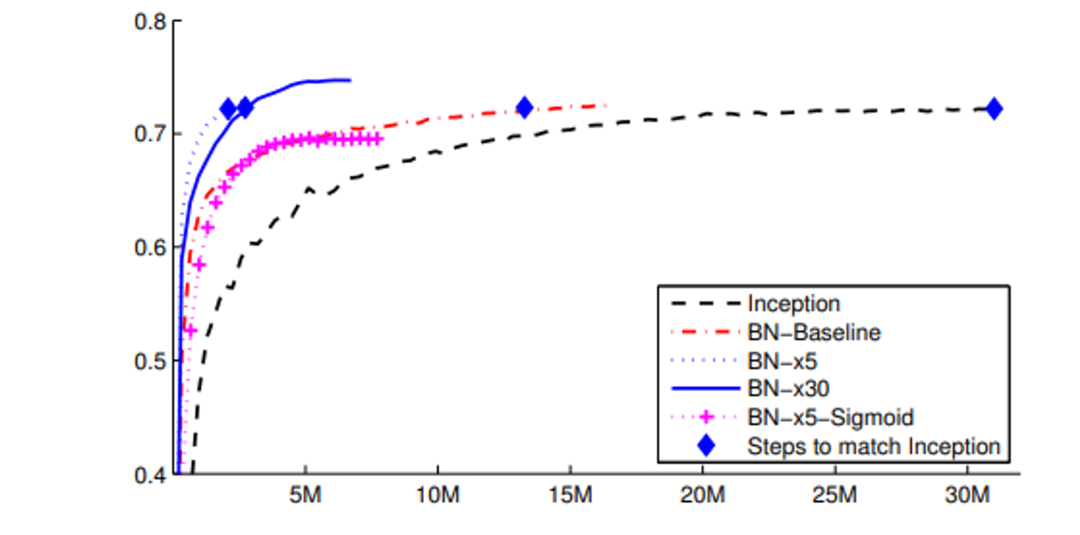
4. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift by Sergey Ioffe, Christian Szegedy (2015)
本文探讨了深度神经网络中的内部协变量偏移问题,即随着前一层参数的更新,每一层的输入分布都会发生变化。这种偏移使训练变得复杂,因为需要降低学习率并谨慎初始化参数。本文介绍了批量归一化,它在训练过程中对每一层的输入进行归一化,从而减轻了这种偏移,并以更高的学习率和不太严格的初始化要求实现了更快的收敛。
5. “Sequence to Sequence Learning with Neural Networks” by Ilya Sutskever, Oriol Vinyals, and Quoc V. Le (2014)
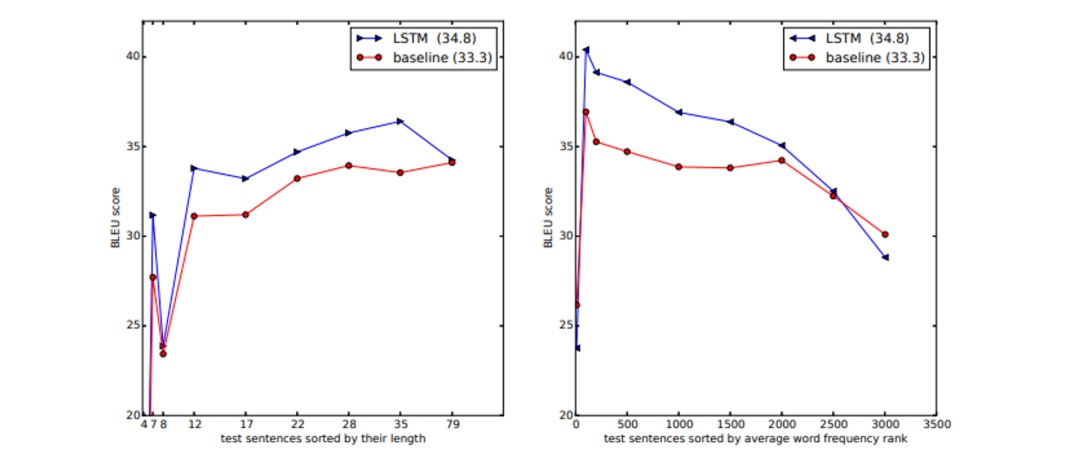
Sutskever、Vinyals 和 Le (2014) 的出版物“使用神经网络进行序列到序列学习”介绍了一种使用深度神经网络 (DNN) 处理序列到序列任务的新方法。论文中描述的技术使用多层长短期记忆 (LSTM) 网络将输入序列映射到固定维度向量,然后将其解码为目标序列。正如它在 WMT-14 的英语到法语翻译数据集上的出色表现所证明的那样,它获得了 34.8 的 BLEU 分数——超越了传统的基于短语的系统并接近最先进的结果——该技术在翻译任务中特别有效。
6. “Generative Adversarial Nets” by Ian Goodfellow et al. (2014)
Ian Goodfellow 等人 (2014) 的论文《生成对抗网络》介绍了一种通过对抗方法训练生成模型的开创性框架。其核心思想围绕生成模型 (G) 和判别模型 (D) 之间的双人博弈展开。生成模型旨在生成与真实数据难以区分的数据样本,而判别模型则试图区分真实样本和 G 生成的样本。这种对抗设置通过最大化 D 犯错的可能性来有效地改进 G,从而形成一种学习复杂数据分布的强大技术。这项研究为训练生成模型提供了重要见解,而无需依赖马尔可夫链或近似推理网络等传统技术。通过采用反向传播同时训练两个模型,该方法简化了学习过程并提高了生成样本的质量。本文介绍了该框架生成高质量样本能力的实验证据。它还概述了其潜在应用,标志着对机器学习和生成建模的重大贡献。
7. “High-Speed Tracking with Kernelized Correlation Filters” by João F. Henriques, Rui Caseiro, Pedro Martins, and Jorge Batista (2014)
论文“使用核化相关滤波器进行高速跟踪”提出了一种提高对象跟踪算法效率和性能的新方法。该研究引入了一种分析模型,该模型利用由平移图像块组成的数据集的属性来优化跟踪。通过认识到这些数据集形成一个循环矩阵,作者应用离散傅里叶变换来大幅降低存储要求和计算复杂度。该技术简化了跟踪过程,同时保持了高精度。

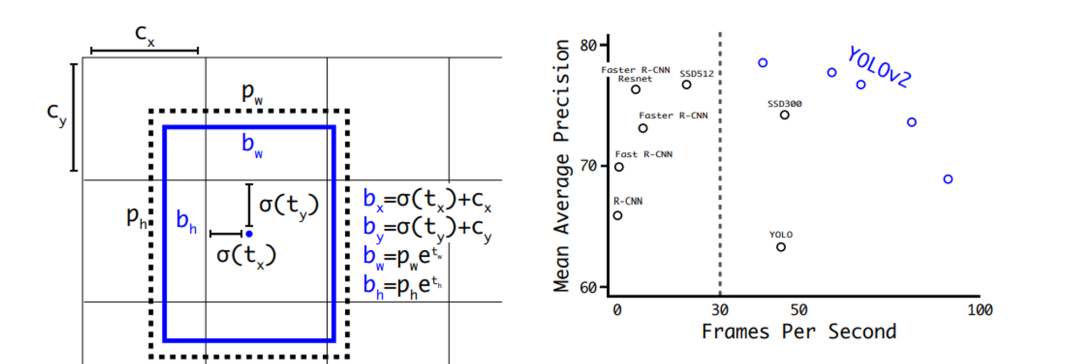
8. “YOLO9000: Better, Faster, Stronger” by Joseph Redmon and Santosh Divvala (2016)
改进的实时物体识别系统 YOLO9000 在出版物“YOLO9000:更好、更快、更强”中进行了介绍。此版本的 YOLO 系统实现了卓越的性能指标,可检测超过 9000 个项目类别,并击败了 SSD 和 Faster R-CNN with ResNet 等竞争方法。在 VOC 2007 数据集上,YOLOv2 以每秒 67 帧的速度获得 76.8 mAP,在 COCO 上以每秒 40 帧的速度获得 78.6 mAP,取得了令人鼓舞的结果。
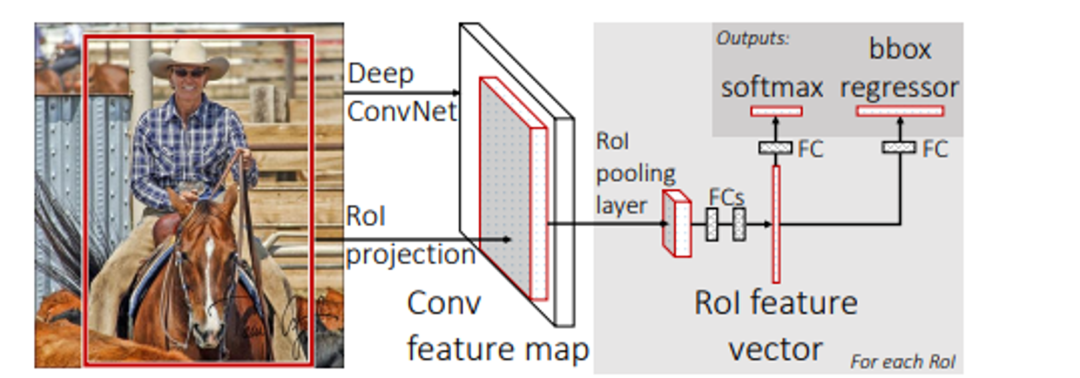
9. “Fast R-CNN” by Ross Girshick (2015)
随着 Fast R-CNN 方法的诞生,物体检测取得了显著进展,正如 Ross Girshick 在研究“Fast R-CNN”中所报告的那样。该方法更好地利用了深度卷积网络,从而提高了物体检测性能。为了更快、更准确地对物体进行分类,Fast R-CNN 改进了早期技术。它使用了许多尖端方法,大大加快了测试和训练阶段。特别是,与原始 R-CNN 相比,Fast R-CNN 评估测试样本的速度提高了 213 倍,训练深度 VGG16 网络的速度提高了 9 倍。它还实现了更高的准确度,如 PASCAL VOC 2012 数据集上的平均准确度 (mAP) 所示。
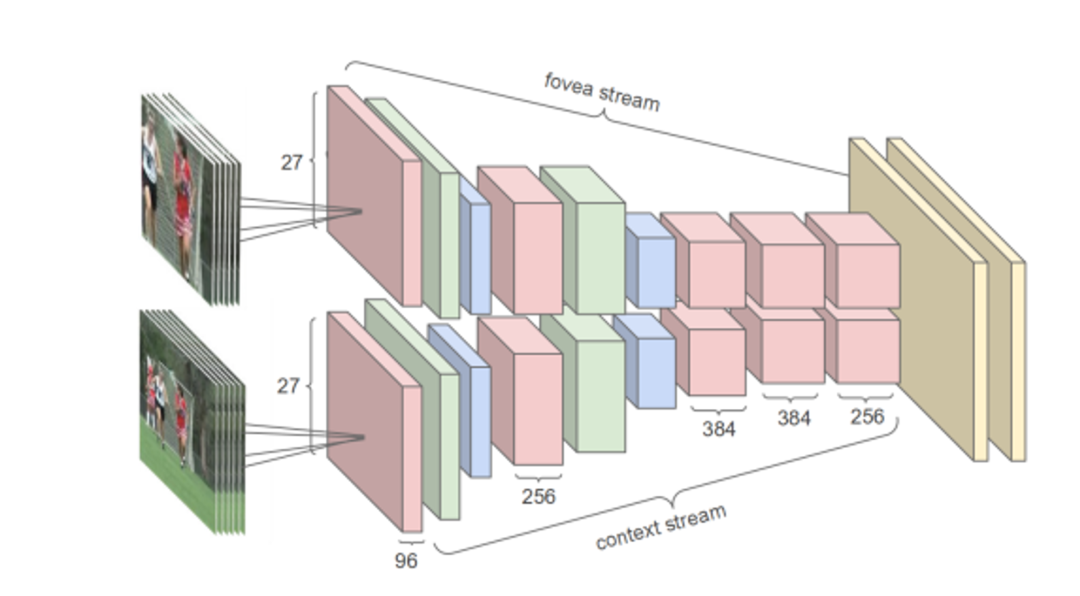
10. Large-scale Video Classification with Convolutional Neural Networks by Fei-Fei, L., Karpathy, A., Leung, T., Shetty, S., Sukthankar, R., & Toderici, G. (2014)
这项研究“使用卷积神经网络进行大规模视频分类”使用 100 万个 YouTube 视频数据集(分为 487 个类别),评估了 CNN 在视频分类中的应用。为了加快训练速度,作者建议采用多分辨率、中央凹结构。论文详细说明了最佳时空 CNN 如何超越基于特征的强大基线,将性能从 55.3% 提高到 63.9%。然而,与单帧模型相比,改进幅度不大,从 59.3% 提高到 60.9%。论文显示,通过在 UCF-101 数据集上重新训练顶层,性能显著提高,从 43.9% 提高到 63.3%。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 9
9 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)