
langchain入门学习笔记
langchain快速入门
前言
本篇笔记内容主要来源于b站楼兰老师的课程,看了此篇笔记相当于看了一遍视频课程,可以节省很多时间,文字内容一方面是老师的讲解,另一方面有我自己的一些理解。
什么是langchain
用python开发的一个应用构建的框架
构建什么样的应用:基于ai大模型构建的本地应用
本质上是为了让我们把ai大模型用的更好
why?已经有ai大模型了,为啥还要有langchain呢
当我们想要深度去使用ai大模型的时候,想要用的更好,一般会有一些不太理想的地方
例如:
1.结果不稳定
相同问题问不同大语言模型,甚至同一个模型,得到的结果不太确定,在需要精确的场景下就不太好。
2.工作流不灵活
有时候不光要和模型聊天,还要给出一些整体的解决方案。例如生成海报,不只是让大模型根据提示词生成海报,可能还需要大模型先帮我生成图片的提示词,再用提示词调用大模型调用图片生成的模型来生成图片,所以需要更复杂的工作流。虽然可以用扣子等工具来帮我们做,但是这些工具前提是插件都已经实现了,解决问题也把我们限制在一个框里面,如果要做一些更精确复杂的事情就很难了。我们需要一个框架,我们在框架的基础上快速地加入任何自己的想法。
3.内容无法定制
大语言模型属于全知全能的模型,不管是会的还是不会的,都会给一个看起来比较靠谱的答案,但有时只需要正对领域内的小问题给出答案,例如开一个电商小店,我的智能客服只需要给客户推荐自己小店里的东西,此时并不需要参考全网的资料,只需要参考内部的资料即可,这里需要对大模型的能力,行为做一些限制。
4.无法结合业务能力
已经开发好的一些“能力”,例如淘宝京东,各种小工具,难道大模型出来了以往这些“能力”都不要了吗,需要一个框架让我们能够结合大模型强大的语言理解能力和业务能力结合起来。
why langchain?
起步最早,最成熟
langchain的各种框架
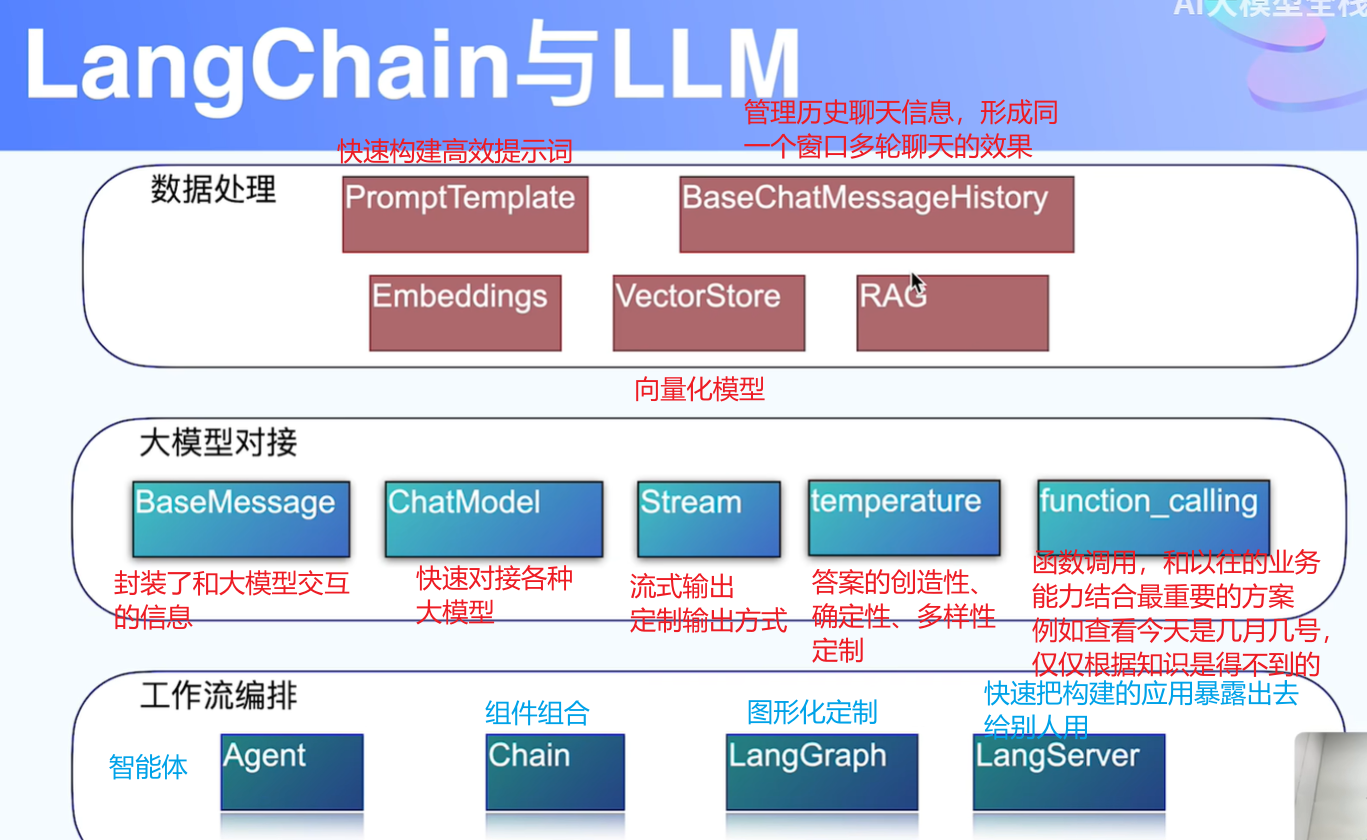
踩在别人建好的桥上过河!
环境搭建
基础


anaconda的安装网上教程很多,这边就不多赘述了,笔者之前装过,这边就不演示了。
常见命令
查看conda版本:conda --version
创建一个python环境:conda create -n
tips:创建环境的时候要科学上网(我报了网络错误)
查看创建的环境:conda env list
激活环境:conda activate langchain_env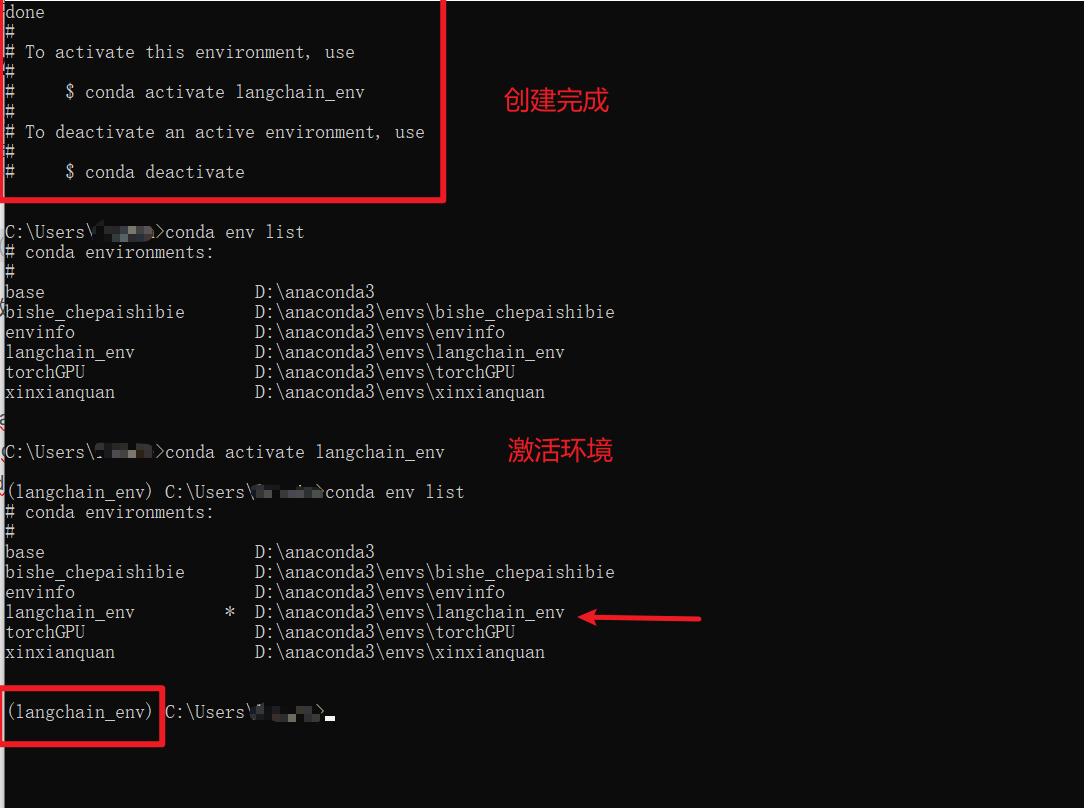
在环境下看一下python的版本:
其他一些常见命令,这里就不演示了,可以自己试试看:
这里面conda install和pip install的区别:
anaconda提供的一个图形化界面:
在环境里写python代码: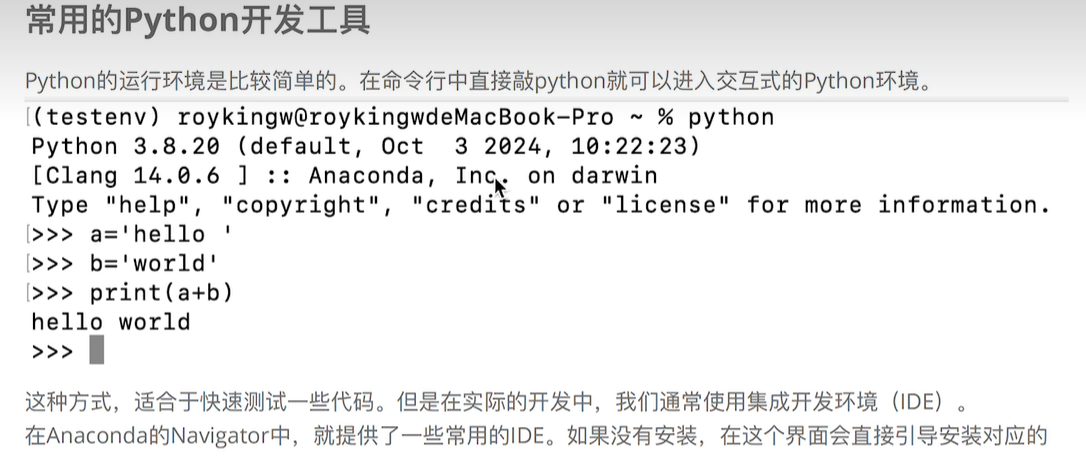
pycharm安装
这个网上也很多,不多做介绍
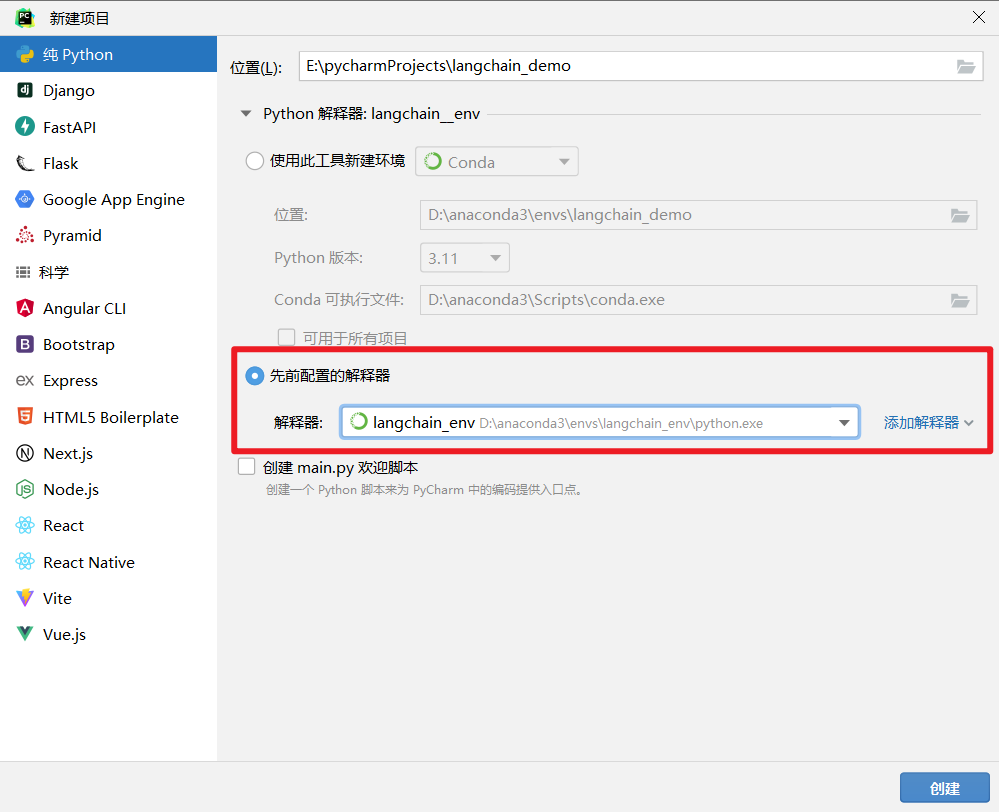
创建一个demo项目
jupyter安装
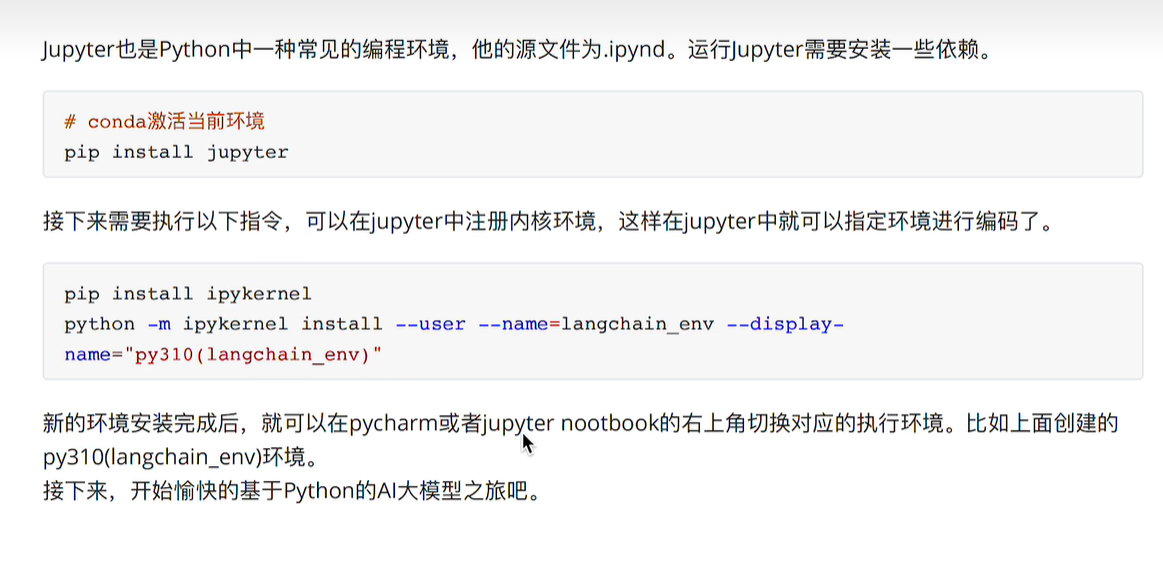
按步骤来即可
启动jupyter服务
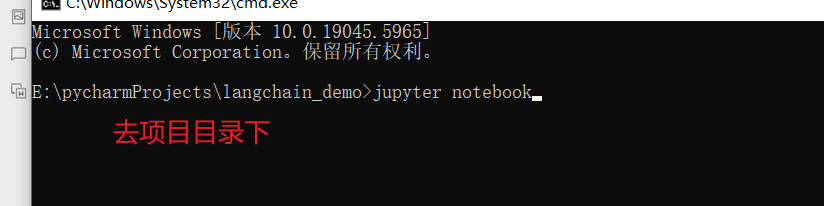
会启动一个页面服务:
测试一下:
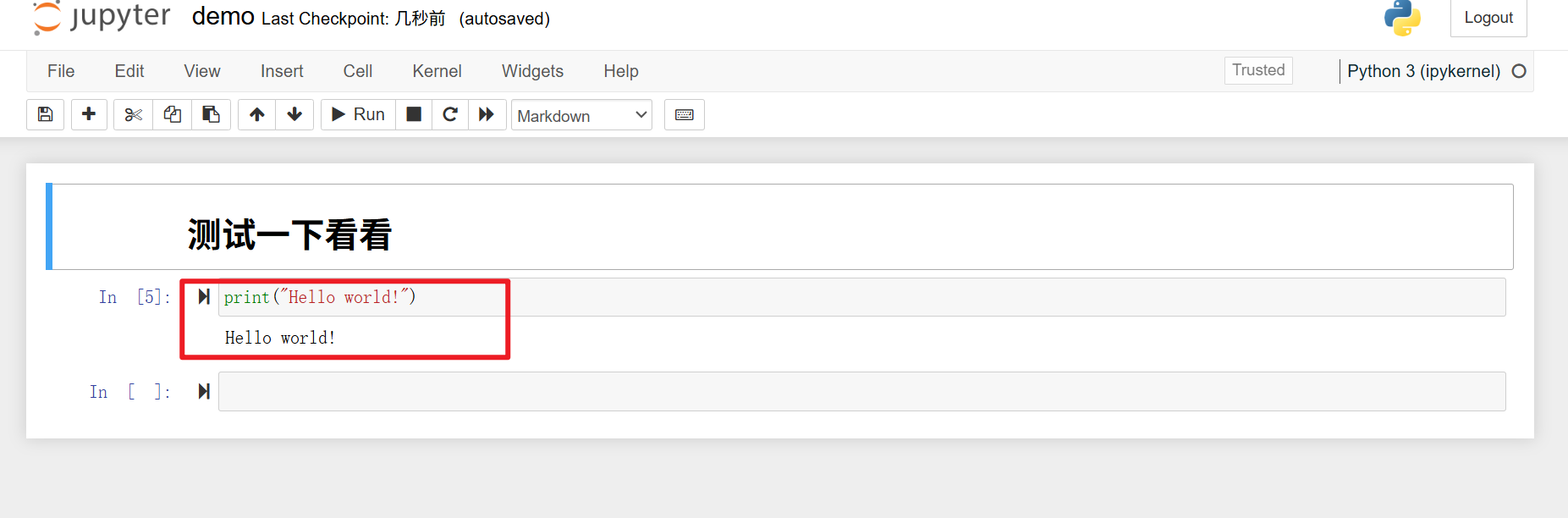
langchain快速上手
再次介绍
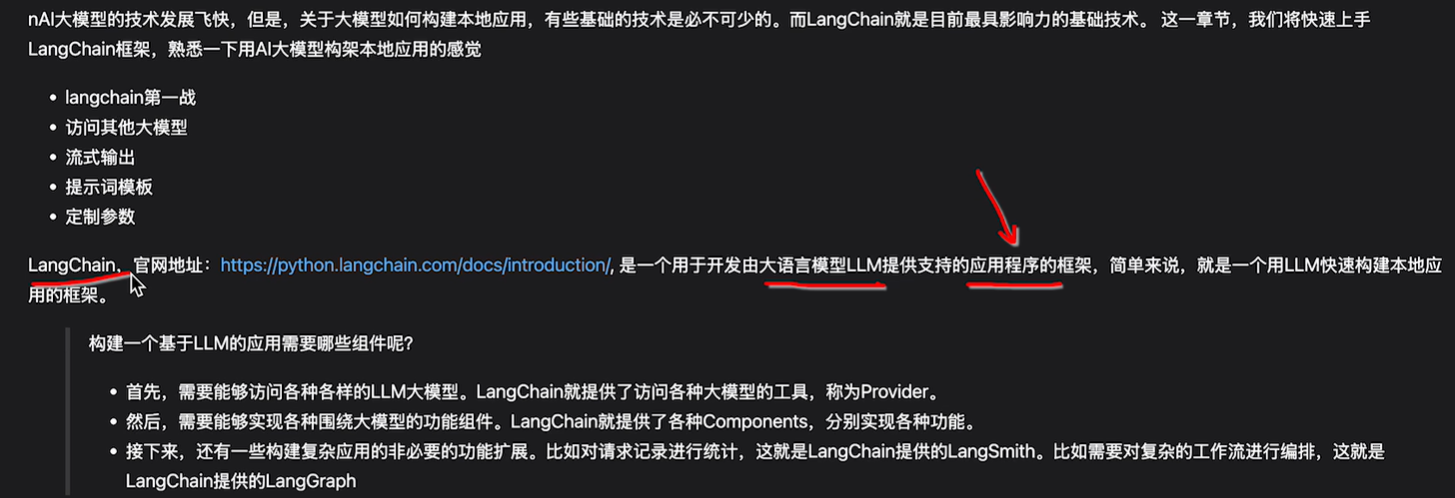
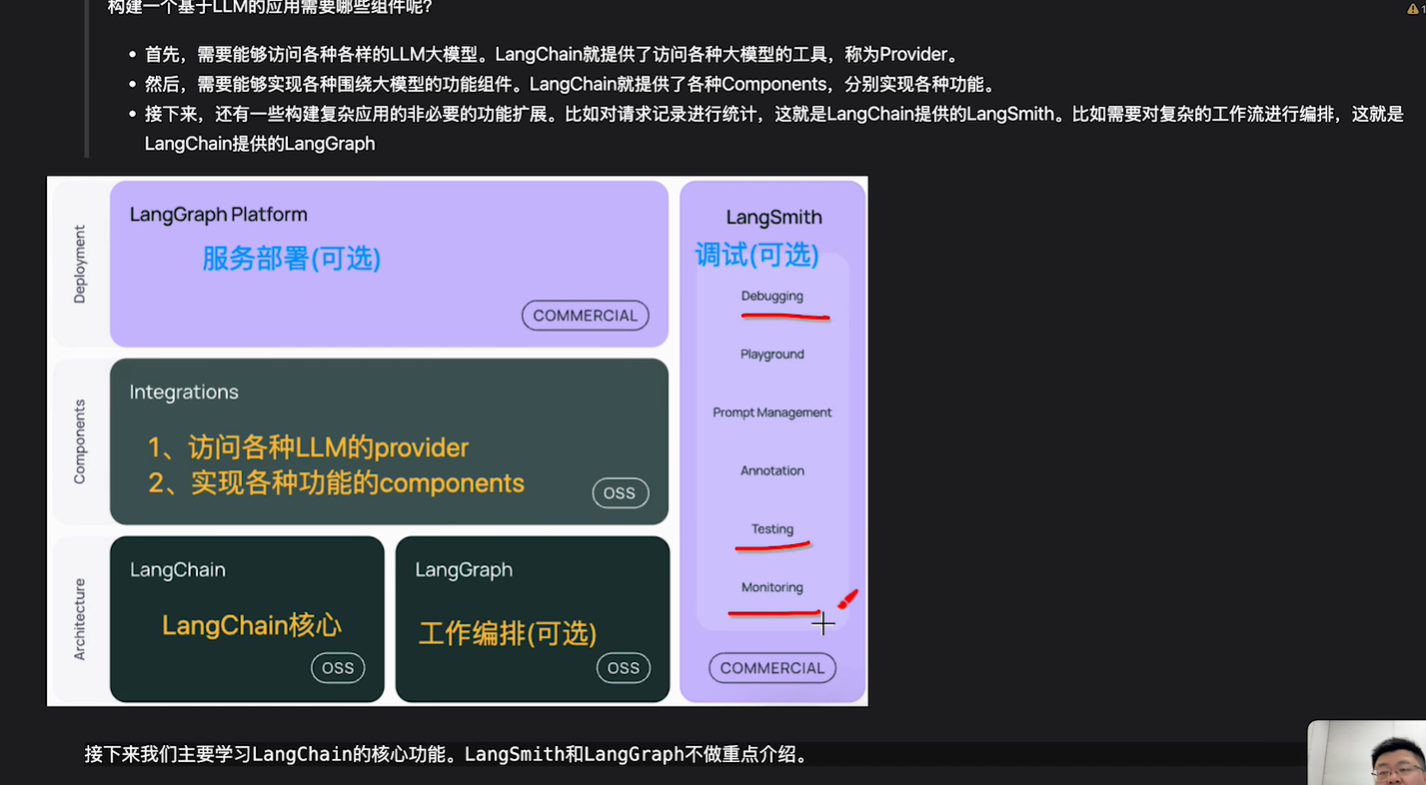
langGraph,要和大模型进行多次交互,例如先判断是不是要给用户介绍产品,还是简单的聊天,后续再根据情况做交互…
访问各种LLM的provider:例如访问openai的,访问deepseek的等的各种实现
langSmith:主要是做监控,例如监控访问了哪些大模型,大模型调用了几次
langchain第一战
依赖包安装
第一个包对接了一些主流的产品,如openai
community涉及到一些影响力没那么大的产品,例如kimi,tongyi等大模型
smith相关
smith.langchain.com
要先去官网申请一个key
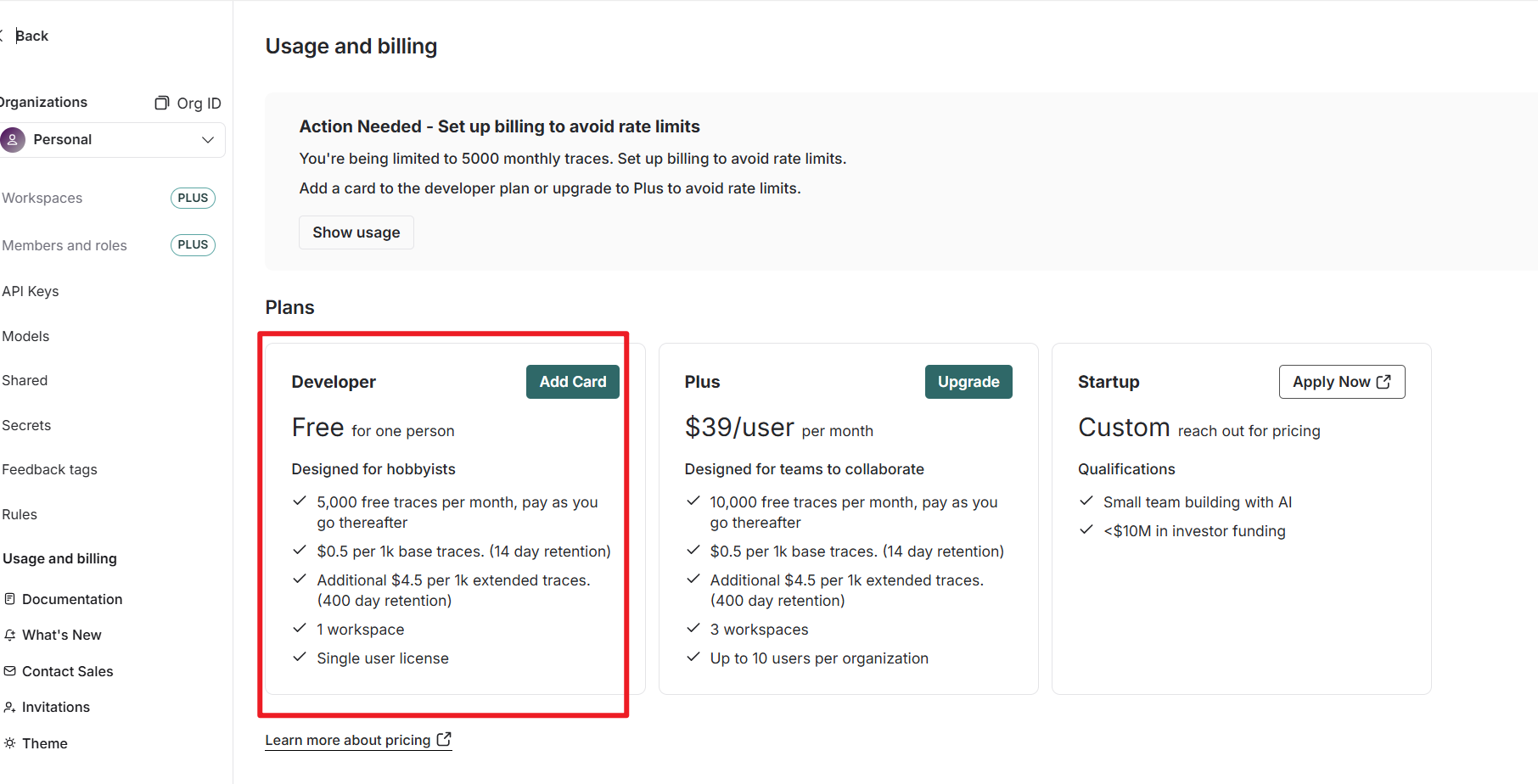
个人是免费的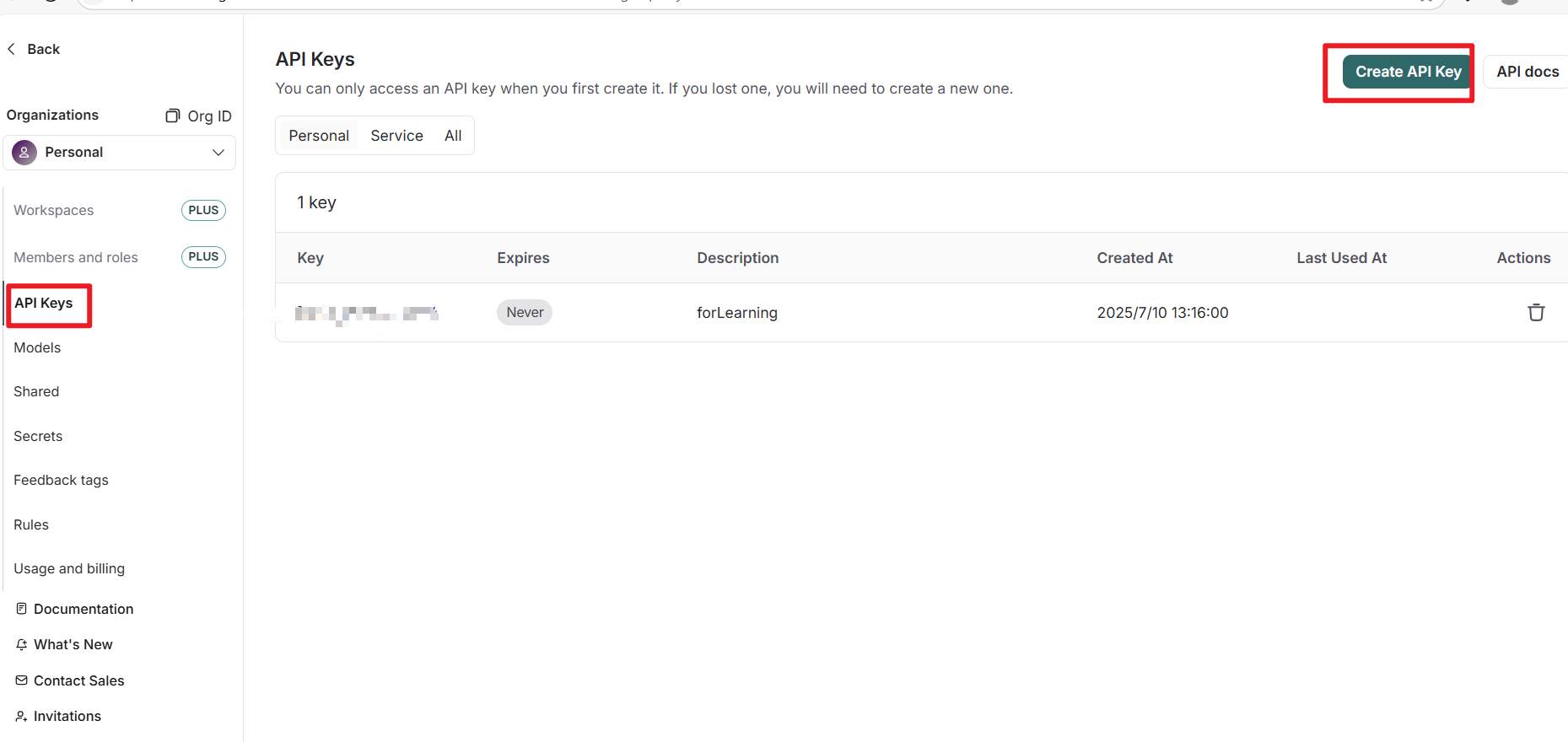
环境变量设置:
把apikey设置到环境变量中,这边重点是如何管理这些key,未来可能会和很多大模型交互,apikey作为身份的认证,进行计费什么的都会基于apikey来做
写一个load_key,py脚本来读取key: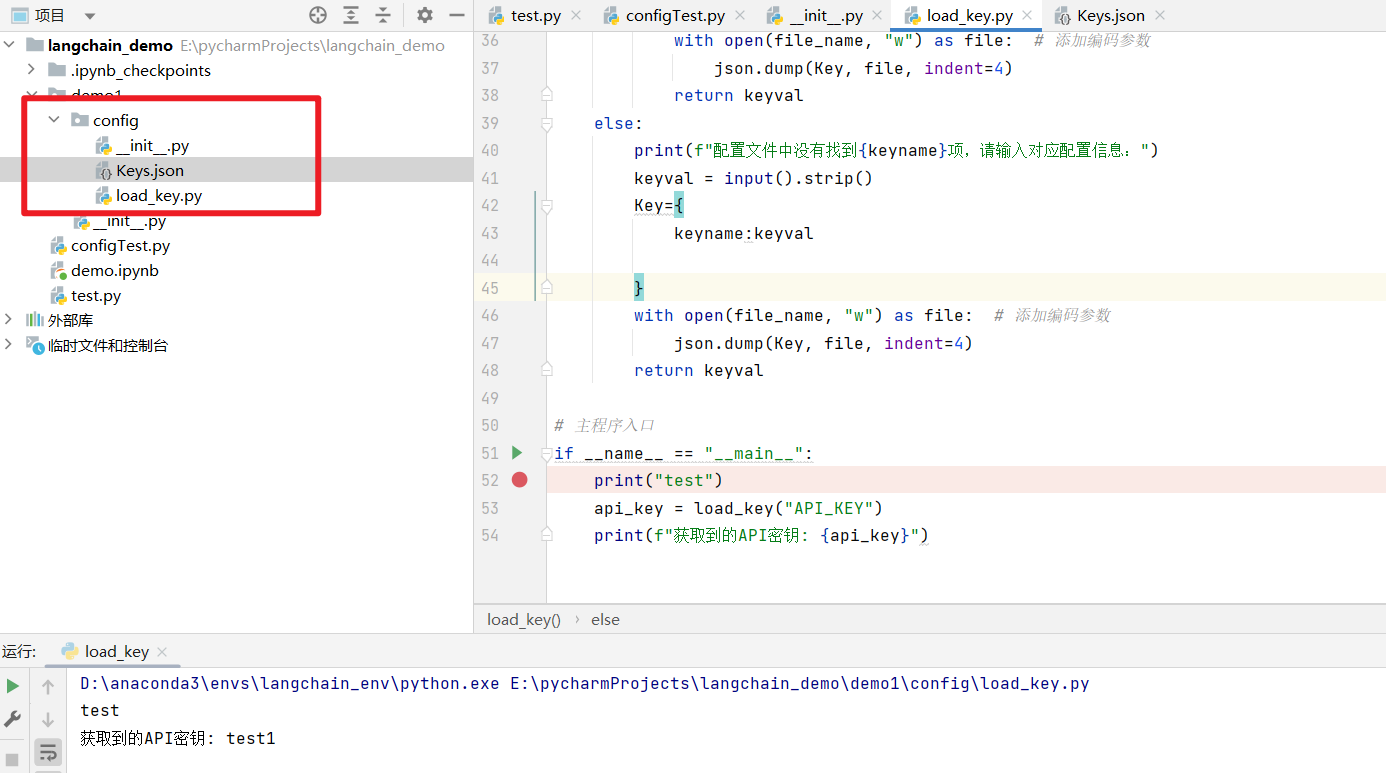
import json
import os.path
import getpass
def load_key(keyname: str) -> str: # 修正返回类型为str
"""
从JSON配置文件加载密钥,若不存在则提示用户输入
参数:
keyname: 要获取的密钥名称
返回:
密钥值
"""
file_name = "Keys.json"
# 初始化密钥字典
key_data = {}
# 检查配置文件是否存在
if os.path.exists(file_name):
with open(file_name, "r") as file: # 添加编码参数
Key = json.load(file)
# 检查密钥是否存在且非空
if keyname in Key and Key[keyname]:
return Key[keyname]
else:
# 请求用户输入新密钥
print(f"配置文件中没有找到{keyname}项,请输入对应配置信息:")
keyval = input().strip()
# 更新密钥字典
Key[keyname] = keyval
# 保存更新后的配置
with open(file_name, "w") as file: # 添加编码参数
json.dump(Key, file, indent=4)
return keyval
else:
print(f"配置文件中没有找到{keyname}项,请输入对应配置信息:")
keyval = input().strip()
Key={
keyname:keyval
}
with open(file_name, "w") as file: # 添加编码参数
json.dump(Key, file, indent=4)
return keyval
# 主程序入口
if __name__ == "__main__":
print("test")
api_key = load_key("API_KEY")
print(f"获取到的API密钥: {api_key}")
这里用不用smith不关键,关键的是如何加载各种key
快速访问大模型
第一个关键组件:chat_models,用来和大语言模型聊天的模块
其中有一个init_chat_model,是初始化模块的方法
这里默认调用的是openai,此处关键参数是provider,模型是哪个,以及api-key,这里要申请,我申请了deepseek的api,后面会再演示另一种接入方法。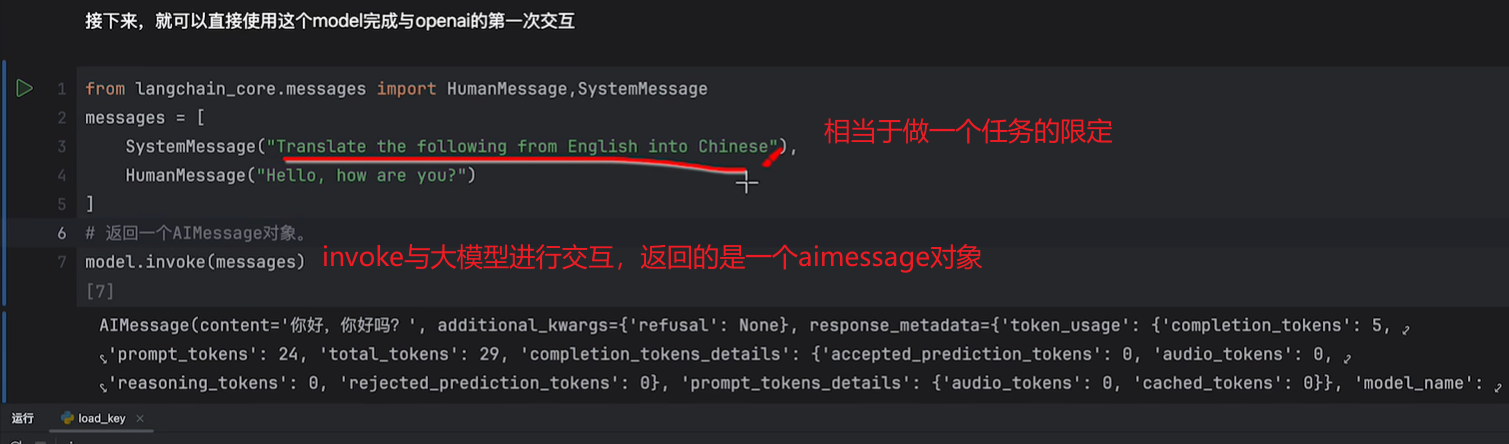
这里返回的aimessage对象:
除了返回的这个翻译结果,还有很多补充信息
例如respense_metadata里面记录了token的信息,token是为了计算费用的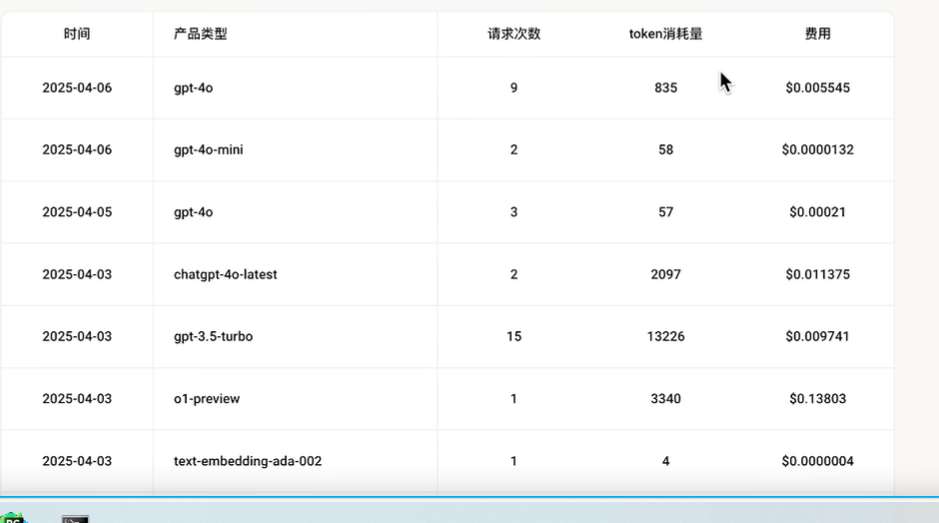
从应用层面,就是大模型计费的依据,本质上就是,你的一句话,或者这些信息,可以拆分成多少个独立的单元,一个单元可以是一个字,也可以是一个词甚至是一个标点符号,具体看大模型如何去理解。大模型是把各种各样的token做组合,搭积木,可以浅显的理解token越多,消耗的算力越多。例如这里面,prompt_token=24(提示词,对应代码中的systemmessage),completion对应回答“你好,你好吗?”,token怎么算还要看大模型,可能觉得你是一个token,也可能你好是一个token,也可能标点是一个token。总之我们可以拿到比app,或者网页更多的信息。
与大模型交互时的不同类型消息: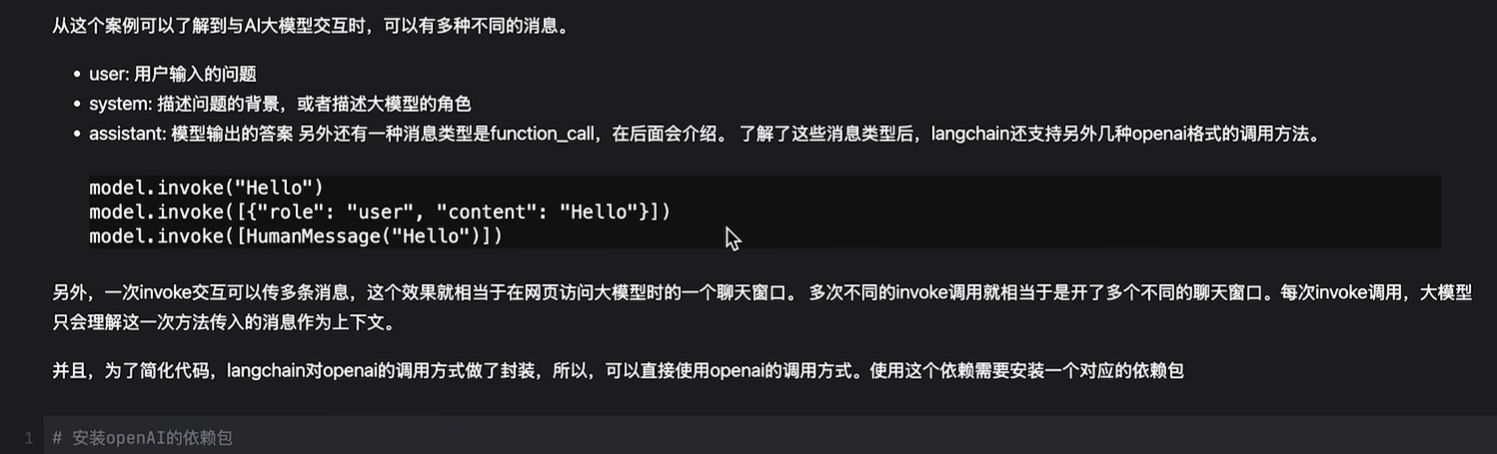
更灵活的方式
其实这种“原始的方式”不太灵活,还要记provider等信息
另一种方式是基于扩展的方式,为了简化代码,langchain针对不同的模型给出了不同的实现。
当然要引入对应的依赖,例如针对openai的: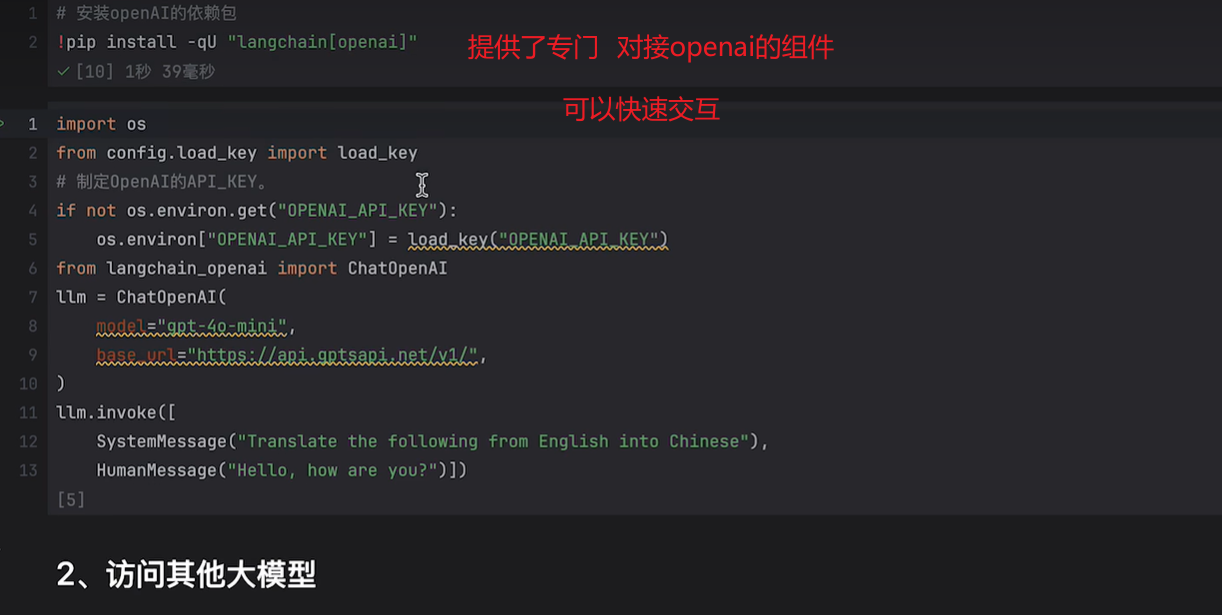
访问deepseek
安装deepseek依赖包:
pip install -U “langchain[deepseek]”
代码:
import os
from langchain_core.messages import HumanMessage
from config.load_key import load_key
if not os.environ.get("DEEPSEEK_API_KEY"):
os.environ["DEEPSEEK_API_KEY"]=load_key("DEEPSEEK_API_KEY")
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(model="deepseek-chat", )
message = llm.invoke([HumanMessage("请讲一个笑话给我听")])
print(message)
运行结果:
看看token消耗情况: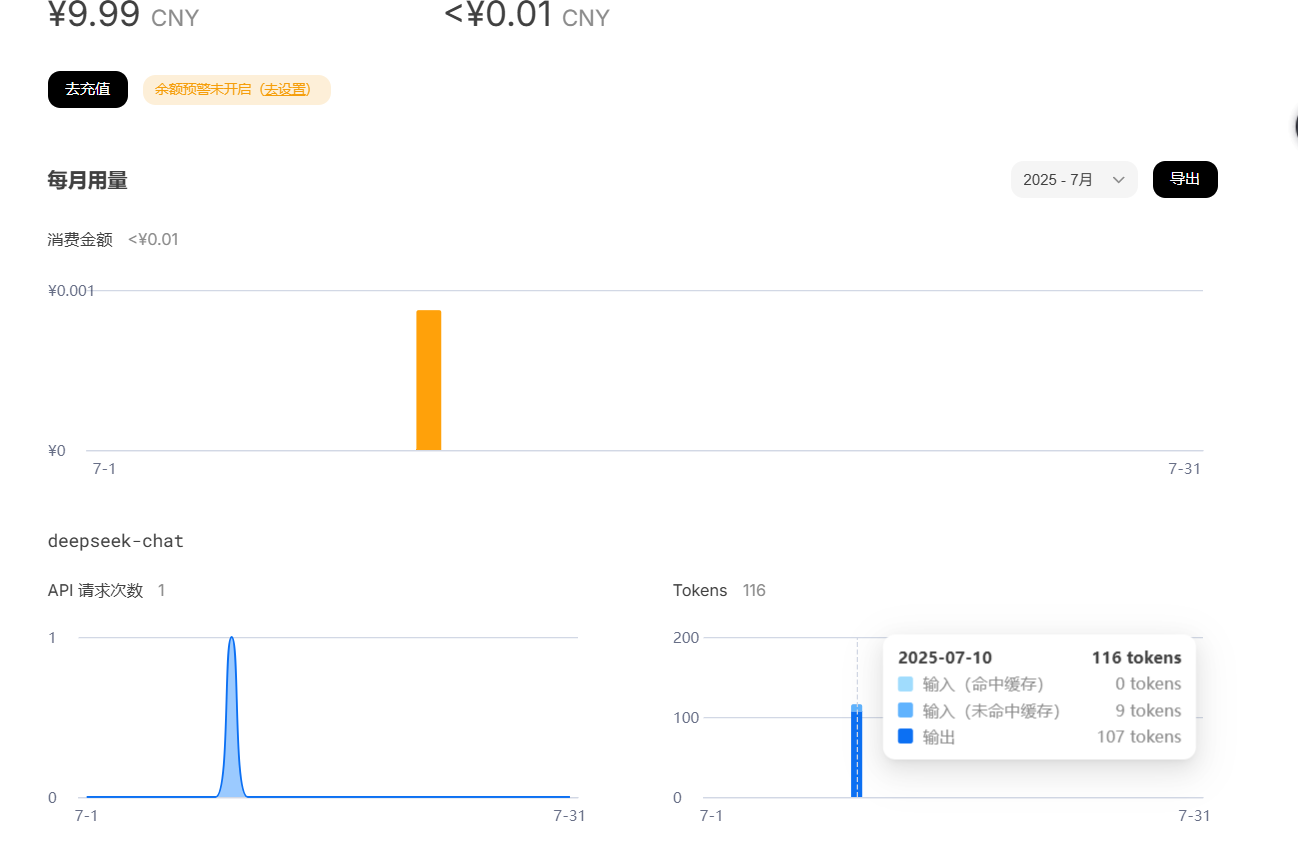
langchain提供的其他大模型的实现
去官网看一下
https://python.langchain.com/docs/integrations/providers/
其他的一些平台提供的模型
 例如阿里云百炼平台:阿里云百炼
例如阿里云百炼平台:阿里云百炼
如何接入:
很多模型在客户端设计层面都是参照openai的,所以很多都兼容了openai的标准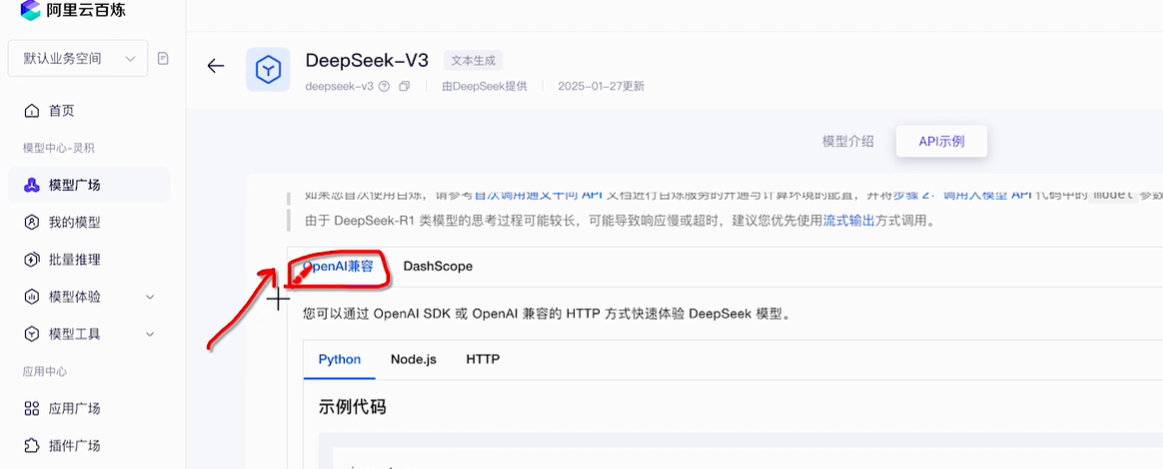
示例代码: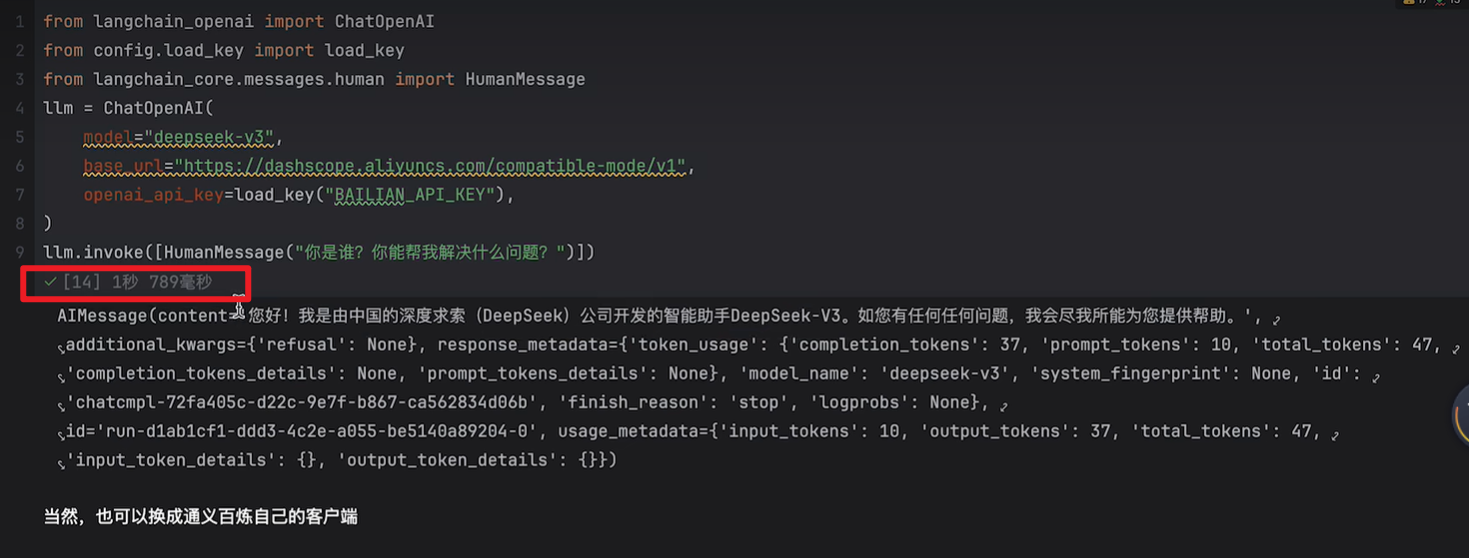
其他的交互方式: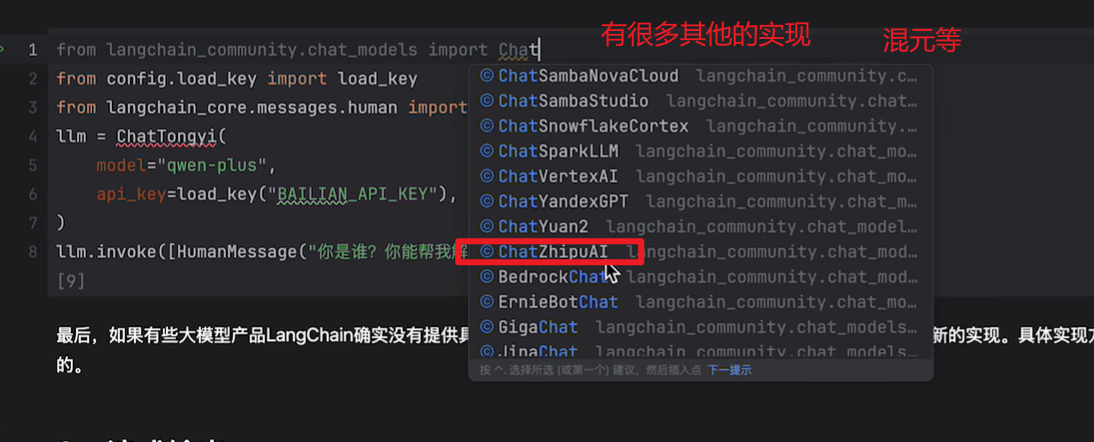
指定模型,指定api即可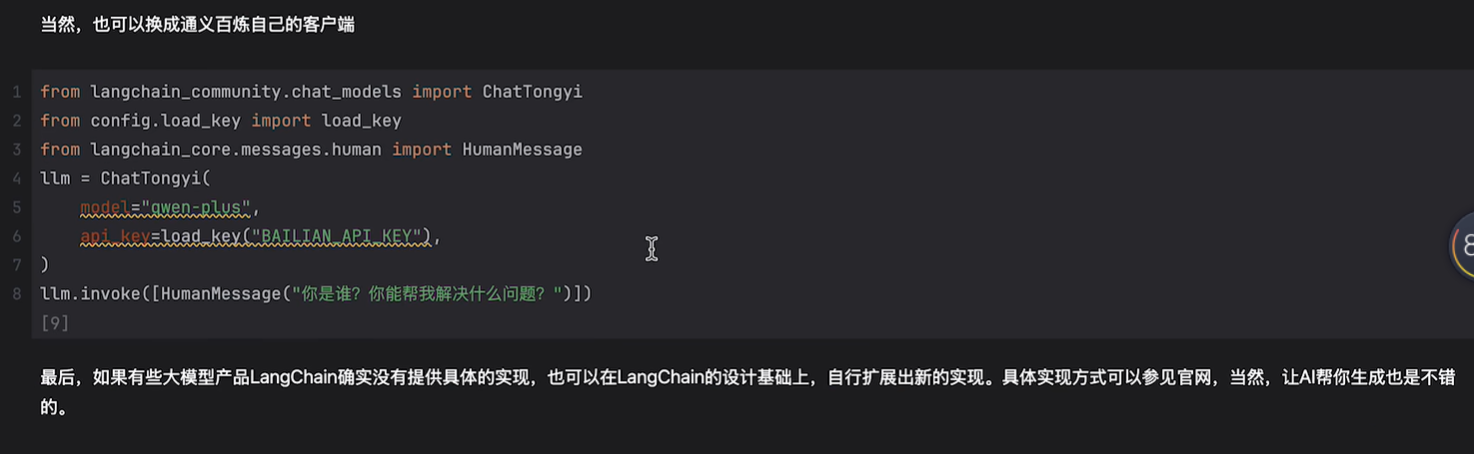
有些大模型擅长数学推理,有些大模型擅长翻译,写作,编程等。可以不同的输入调用不同的模型,提供更精确的帮助。
此外可能先经过这个大模型,再给那个大模型处理,这就是工作编排。
大模型的其他交互方式
流式输出
流式输出即输出结果会一个一个Token蹦出来。
代码:
import os
from langchain_core.messages import HumanMessage
from config.load_key import load_key
if not os.environ.get("DEEPSEEK_API_KEY"):
os.environ["DEEPSEEK_API_KEY"]=load_key("DEEPSEEK_API_KEY")
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(model="deepseek-chat", )
stream = llm.stream([HumanMessage("请讲一个笑话给我听")])
for chunk in stream:
print(chunk.text(),end="\n")
结果:
end=‘’:
提示词模板
每次都让用户去提交提示词是比较麻烦的
这里看看代码案例就懂了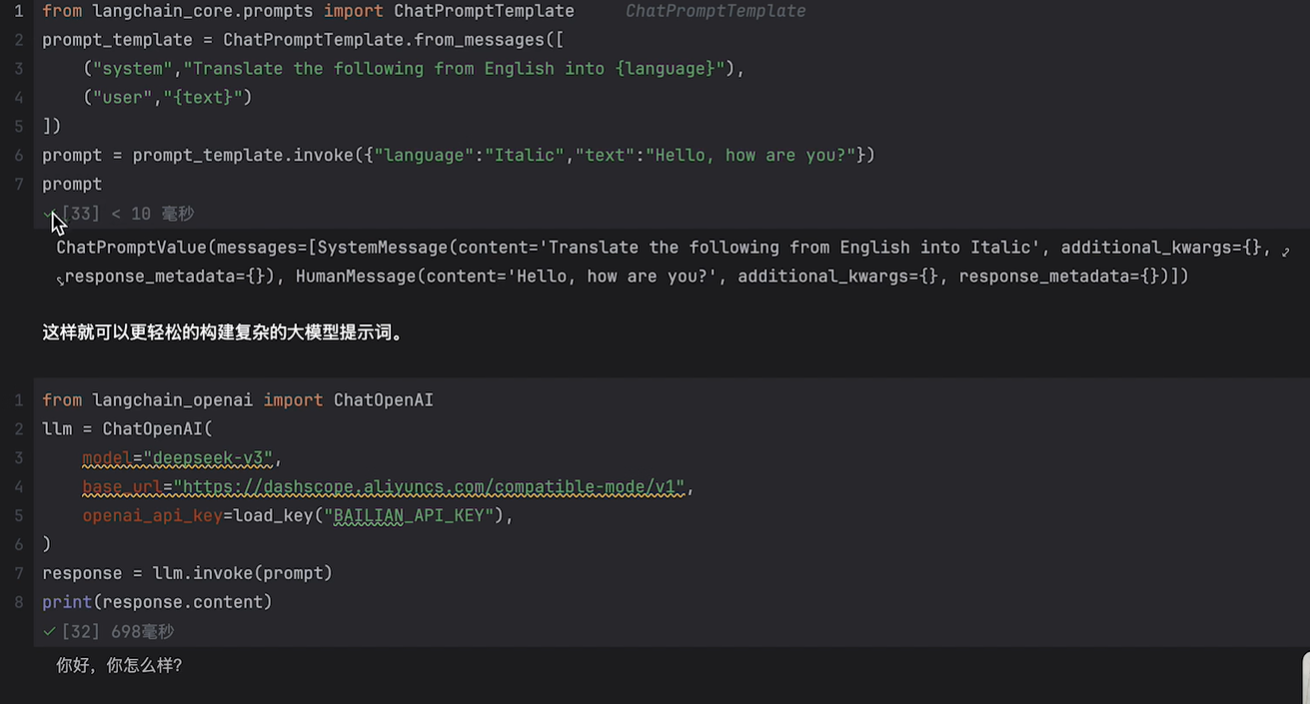
应用场景:不同“性格”的智能体(当然这里是最简单的智能体概念)
定制参数
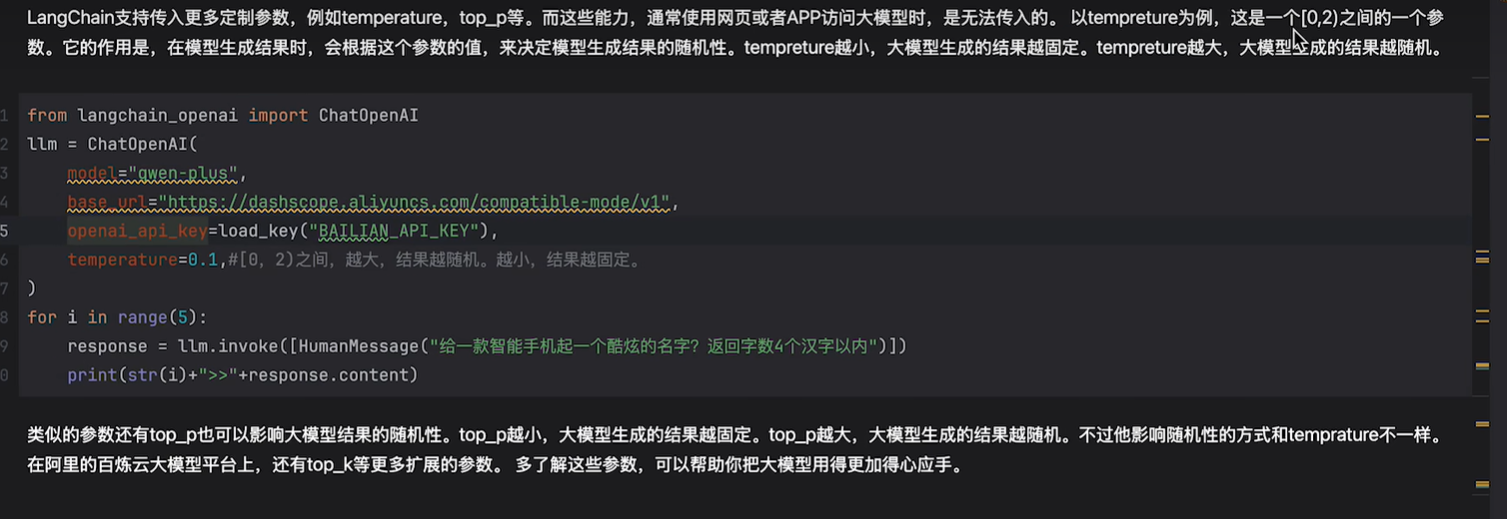
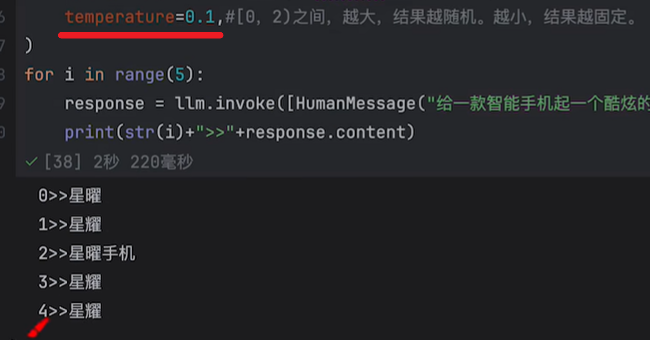
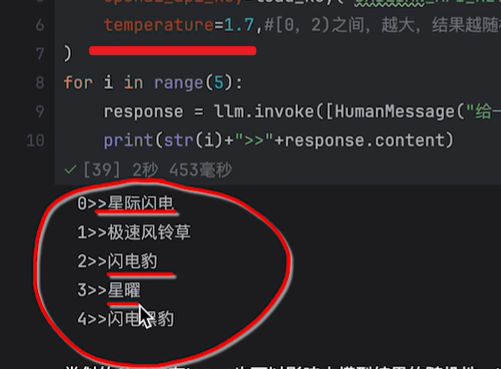
可以去源码里看看其他的一些参数:
还有max_tokens,top_p等参数

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 46
46 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)