
广西民族大学高级人工智能课程—头歌实践教学实践平台—自然语言处理语料库
广西民族大学高级人工智能课程—头歌实践教学实践平台—自然语言处理语料库
代码文件
import nltk
from nltk import data
import os
def task(setence):
yuliaoku_path = os.path.join(os.getcwd(), "yuliaoku")
# 通过指定的路径名加载语料库
data.path.append(yuliaoku_path)
######### Begin #########
# 分词的函数是word_tokenize
text = nltk.word_tokenize(setence)
print(nltk.pos_tag(text))
######### End #########题目描述
任务描述
本关任务:使用nltk进行分词。
相关知识
本关将介绍自然语言处理中的语料库。
语料库
基于统计的自然语言处理和基于深度学习的自然语言处理都需要大量的语言数据作为训练数据。存储这些数据的仓库就被称为语料库。
我们知道,在使用机器学习技术处理图像的时候,通常都是遇到具体的问题再去收集数据,形成数据库。这是因为图片的数量是难以穷尽的,不可能为所有的图像处理问题建立一个统一的数据仓库。但是自然语言处理中,有些数据其实是有限的,比如中文中的词语,而且几乎所有涉及中文的自然语言处理都可能用到这个数据库。所以为进行自然语言处理建立一些统一的数据库是有可能的。
语料库的历史
语料库的发展经历了如下几个历史阶段:
-
20世纪50年代中期之前:早期 这个时候的语料库实际上还不是为计算机技术准备的,而是主要用于方言学、语言教学、语言习得、句法和语义等领域。 -
1957到20世纪80年代初期:沉寂时期 -
20世纪80年代至今:复苏与发展时期,主要得益于计算机的迅速发展和机器学习的兴起,语料库在自然语言处理研究中的重要性越来越大。
语料库的分类
语料库根据其收集的语料的性质,分为如下几种:
-
分词语料库,分词就是我们上面提到的词语,分词语料库收集的是某种语言中的所有词语、短语或者词组。比如很多自然语言处理团队建设了中文分词语料库:人民日报在
1998年建立的中文分词语料库,以及一些中文分词算法内置的语料库,如jieba、THUOCL分词算法使用的语料库。 -
词性语料库,词性语料库是在分词语料库的基础上,为每个词添加了词性生成的语料库,所谓词性,指的是名词、动词、形容词、分词等对词语的分类。
-
命名实体语料库,指某个领域的常用名词组成的语料库,通常是为了解决特定领域的自然语言处理问题设立的语料库。比如医学领域的实体语料库,记录的是以医学专业名称为主的实体。
nltk的使用
nltk是一个非常成熟的开源语料库,由Steven Bird和Edward Loper在宾夕法尼亚大学计算机和信息科学系开发。
在使用之前,需要先通过pip3 install nltk命令来安装nltk库,然后还需要访问nltk的github主页来下载语料库。
判断停用词
我们可以使用nltk语料库来判断句子中的停用词,所谓停用词,就是那些出现频率较高,但是没有太大意义的代词、介词、定冠词等,比如英文中的the、it、he、that等,如下是一段判断停用词的程序:
from nltk.corpus import stopwordstokens = ['my', 'dog', 'has', 'flea', 'problems', 'help', 'please','maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid','my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him']stwords = stopwords.words('english')# 遍历所有的单词for token in tokens:if token in stwords:# 如果是停用词,则打印出来print(token)
程序的运行结果如下所示:
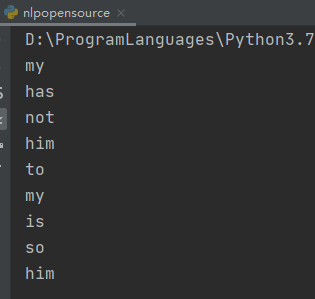
进行分词
我们还可以使用nltk进行分词,其程序如下所示:
import nltk# 分词的函数是word_tokenizetext = nltk.word_tokenize('I love the sunny March day')print(nltk.pos_tag(text))
结果如下所示:

词性和中文解释如下所示:
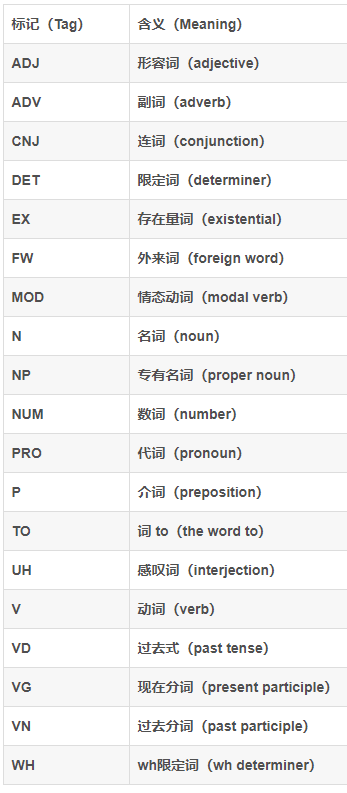
编程要求
根据提示,在右侧编辑器Begin和End之间补充代码,使用nltk对句子setence进行分词,并直接打印分词的结果。
测试说明
平台会打印分词结果,并将分词结果和正确的结果进行对比。
开始你的任务吧,祝你成功!

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 21
21 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)