
6. 吴恩达机器学习课程-作业6-SVM
fork了别人的项目,自己重新填写,我的代码如下https://gitee.com/fakerlove/machine-learning/tree/master/code代码原链接文章目录6. 吴恩达机器学习课程-作业6-SVM6.1 支持向量机6.1.1 题目介绍6.1.2 可视化数据6.1.3 代码6.2 基于高斯核的支持向量机6.2.1 题目介绍6.2.2 可视化数据6.2.3 代码6.2.
fork了别人的项目,自己重新填写,我的代码如下
https://gitee.com/fakerlove/machine-learning/tree/master/code
文章目录
6. 吴恩达机器学习课程-作业6-SVM
6.1 支持向量机
6.1.1 题目介绍
在本练习的前半部分,您将使用支持向量机(svm)与各种示例2D数据集。
用这些数据集做实验,将帮助您对支持向量机如何工作以及如何使用高斯函数有一个直观的了解内核支持向量机。
在接下来的练习中,你将使用支撑构建垃圾邮件分类器的向量机。
6.1.2 可视化数据
import scipy.io as sio
import numpy as np
from matplotlib import pyplot as plt
import scipy.optimize as opt
from sklearn.metrics import classification_report
from time import *
def plot_scatter(x1, x2, y):
"""
绘制散点图
:param x1: ndarray,横坐标数据
:param x2: ndarray,纵坐标数据
:param y: ndarray,标签
:return: None
"""
plt.scatter(x1, x2, c=y.flatten())
plt.xlabel("x1")
plt.ylabel("X2")
if __name__ == '__main__':
begin_time = time()
print("========程序开始============")
data1 = sio.loadmat("data\\ex6data1.mat")
X = np.array(data1["X"])
y = np.array(data1["y"])
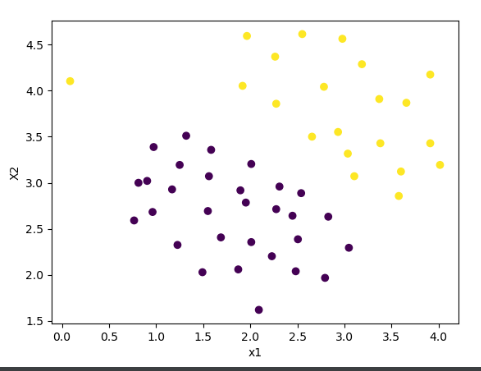
plot_scatter(X[..., 0], X[..., 1], y)
plt.show()
print("========程序结束============")
end_time = time()
run_time = end_time - begin_time
print('该循环程序运行时间:', run_time) # 该循环程序运行时间: 1.4201874732
6.1.3 代码
下面直接进行模型的创建和训练,C就是我们的参数,可以自己指定核函数,这里直接用线性的也就是没有核函数,因为是线性可分的
# 下面直接进行模型的创建和训练,C就是我们的参数,可以自己指定核函数,这里直接用线性的也就是没有核函数,因为是线性可分的
model = svm.SVC(C=1, kernel='linear')
# y.ravel() 把y一维向量
model.fit(X, y.ravel())
下面画出决策边界,这里需要反复用到,因此也封装一下。这里因为考虑到决策边界不一定是直线,所以我们画等高线的方法实现。
def plot_boundary(model, X, title):
"""
绘制决策边界
:param model: <class 'sklearn.svm._classes.SVC'>,训练好的模型
:param X: ndarray,训练数据
:param title: str,图片的题目
:return: None
"""
x_max, x_min = np.max(X[..., 0]), np.min(X[..., 0])
y_max, y_min = np.max(X[..., 1]), np.min(X[..., 1])
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 1000), np.linspace(y_min, y_max, 1000))
p = model.predict(np.concatenate((xx.ravel().reshape(-1, 1), yy.ravel().reshape(-1, 1)), axis=1))
plt.contour(xx, yy, p.reshape(xx.shape))
plt.title(title)
使用函数
plot_boundary(model, X, "SVM Decision Boundary with C = 1 (Example Dataset 1)")
plt.show()
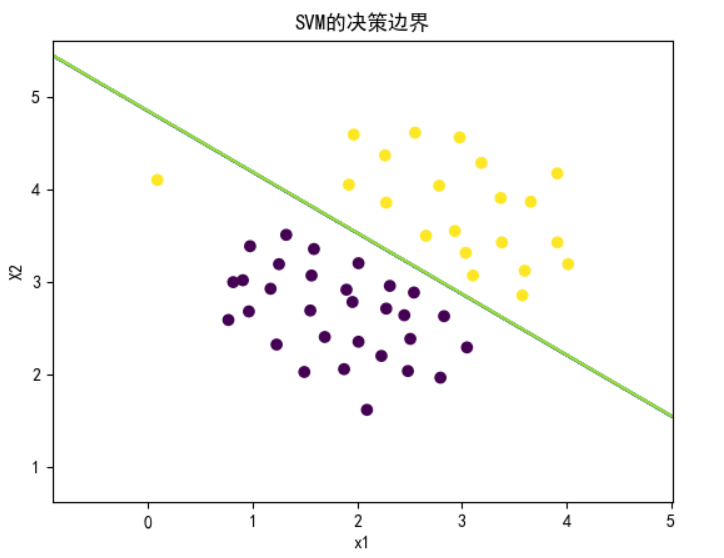
修改C到100,可以看到异常点影响到了分类的效果。有点点过拟合的味道,具体的我们最后总结。
总代码如下
import scipy.io as sio
import numpy as np
from matplotlib import pyplot as plt
import scipy.optimize as opt
from sklearn.metrics import classification_report
from time import *
from sklearn import svm
def plot_scatter(x1, x2, y):
"""
绘制散点图
:param x1: ndarray,横坐标数据
:param x2: ndarray,纵坐标数据
:param y: ndarray,标签
:return: None
"""
plt.scatter(x1, x2, c=y.flatten())
plt.xlabel("x1")
plt.ylabel("X2")
def plot_boundary(model, X, title):
"""
绘制决策边界
:param model: <class 'sklearn.svm._classes.SVC'>,训练好的模型
:param X: ndarray,训练数据
:param title: str,图片的题目
:return: None
"""
x_max, x_min = np.max(X[..., 0]), np.min(X[..., 0])
y_max, y_min = np.max(X[..., 1]), np.min(X[..., 1])
xx, yy = np.meshgrid(np.linspace(x_min - 1, x_max + 1, 1000), np.linspace(y_min - 1, y_max + 1, 1000))
p = model.predict(np.concatenate((xx.ravel().reshape(-1, 1), yy.ravel().reshape(-1, 1)), axis=1))
plt.contour(xx, yy, p.reshape(xx.shape))
plt.title(title)
if __name__ == '__main__':
begin_time = time()
print("========程序开始============")
data1 = sio.loadmat("data\\ex6data1.mat")
X = np.array(data1["X"])
y = np.array(data1["y"])
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
plot_scatter(X[..., 0], X[..., 1], y)
# 下面直接进行模型的创建和训练,C就是我们的参数,可以自己指定核函数,这里直接用线性的也就是没有核函数,因为是线性可分的
model = svm.SVC(C=1, kernel='linear')
# y.ravel() 把y一维向量
model.fit(X, y.ravel())
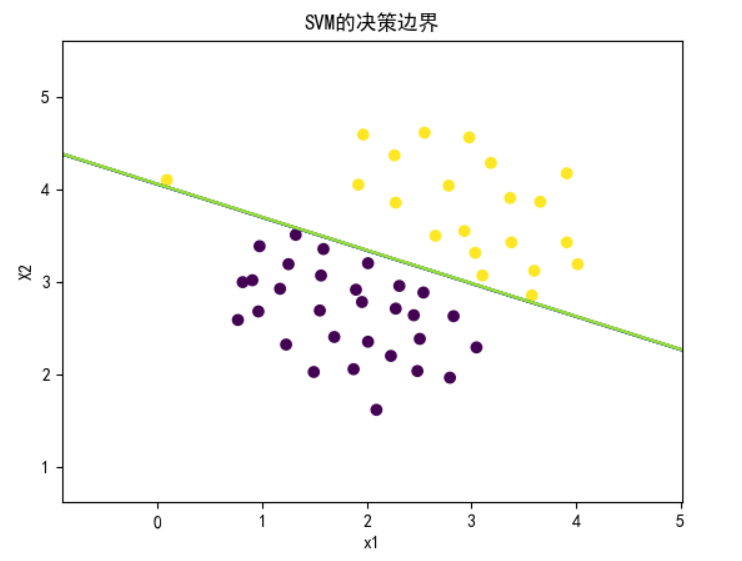
plot_boundary(model, X, "SVM的决策边界")
plt.show()
print("========程序结束============")
end_time = time()
run_time = end_time - begin_time
print('该循环程序运行时间:', run_time) # 该循环程序运行时间: 1.4201874732
6.2 基于高斯核的支持向量机
6.2.1 题目介绍
在这部分练习中,您将使用支持向量机进行非线性分类。
特别是,你将使用带有高斯核的支持向量机非线性可分的数据集。
6.2.2 可视化数据
为了用支持向量机找到非线性决策边界,我们需要首先实现一个高斯核函数。你可以把高斯核看作一个相似性函数,它测量两个例子之间的“距离”,
x i , x j x_i,x_j xi,xj 高斯核也被带宽参数σ参数化,σ决定相似性度量减少(到0)的速度。
随着例子的进一步分离。
import scipy.io as sio
import numpy as np
from matplotlib import pyplot as plt
import scipy.optimize as opt
from sklearn.metrics import classification_report
from time import *
from sklearn import svm
def plot_scatter(x1, x2, y):
"""
绘制散点图
:param x1: ndarray,横坐标数据
:param x2: ndarray,纵坐标数据
:param y: ndarray,标签
:return: None
"""
plt.scatter(x1, x2, c=y.flatten())
plt.xlabel("x1")
plt.ylabel("X2")
if __name__ == '__main__':
begin_time = time()
print("========程序开始============")
data1 = sio.loadmat("data\\ex6data2.mat")
X = np.array(data1["X"])
y = np.array(data1["y"])
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
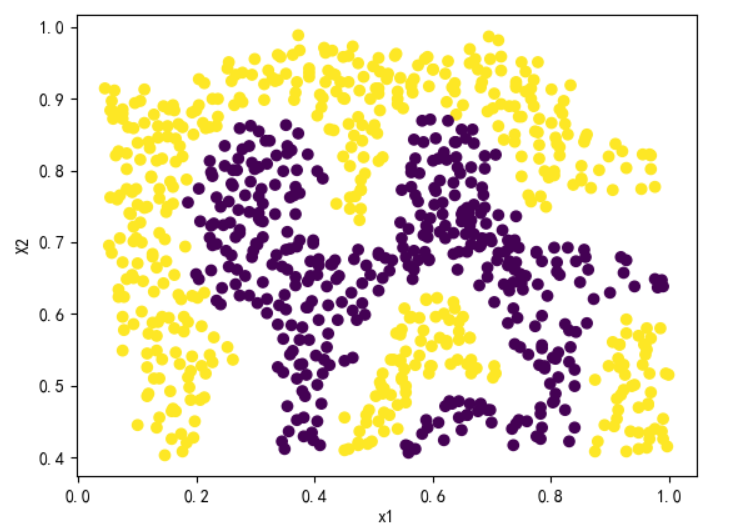
plot_scatter(X[..., 0], X[..., 1], y)
plt.show()
print("========程序结束============")
end_time = time()
run_time = end_time - begin_time
print('该循环程序运行时间:', run_time) # 该循环程序运行时间: 1.4201874732
6.2.3 代码
可以看到这里的数据不是线性可分的,因此需要使用核函数了。
高斯核函数是一个常用的选择
K g a u s s i o n ( x ( i ) , x ( j ) ) = e − ∣ x ( i ) − x ( j ) ∣ 2 2 σ 2 = e − ∑ k = 1 n ( x k ( i ) − x k ( j ) ) 2 σ 2 K_{gaussion(x^{(i)},x^{(j)})}=e^{-\frac{|x^{(i)}-x^{(j)}|^2}{2\sigma^2}}=e^{-\frac{\sum_{k=1}^n(x_k^{(i)}-x_k^{(j)})}{2\sigma^2}} Kgaussion(x(i),x(j))=e−2σ2∣x(i)−x(j)∣2=e−2σ2∑k=1n(xk(i)−xk(j))
def gaussian_kernel(x1, x2, sigma):
return np.exp(-np.sum(np.power(x1 - x2, 2)) / (2 * sigma ** 2))
下面对数据2进行分类,使用高斯核函数。sklearn.svm.SVC中并没有直接的高斯核函数,我么可以通过使用rbf函数配合gamma参数实现,rbf和高斯核函数大致相同,只是将底部换成了gamma,
sigma = 0.1
gamma = 1 / (2 * np.power(sigma, 2))
'''
高斯核函数中的gamma越大,相当高斯函数中的σ越小,此时的分布曲线也就会越高越瘦。
高斯核函数中的gamma越小,相当高斯函数中的σ越大,此时的分布曲线也就越矮越胖,smoothly,higher bias, lower variance
'''
model = svm.SVC(C=1, kernel='rbf', gamma=gamma)
model.fit(X, y.ravel())
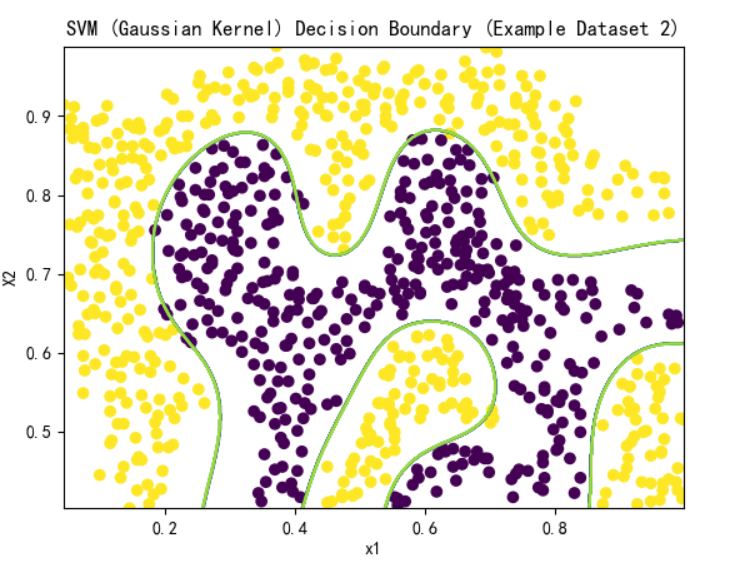
plot_boundary(model, X, "SVM (Gaussian Kernel) Decision Boundary (Example Dataset 2)")
plt.show()
可以说分类效果是非常的nice了
import scipy.io as sio
import numpy as np
from matplotlib import pyplot as plt
import scipy.optimize as opt
from sklearn.metrics import classification_report
from time import *
from sklearn import svm
def plot_scatter(x1, x2, y):
"""
绘制散点图
:param x1: ndarray,横坐标数据
:param x2: ndarray,纵坐标数据
:param y: ndarray,标签
:return: None
"""
plt.scatter(x1, x2, c=y.flatten())
plt.xlabel("x1")
plt.ylabel("X2")
def plot_boundary(model, X, title):
"""
绘制决策边界
:param model: <class 'sklearn.svm._classes.SVC'>,训练好的模型
:param X: ndarray,训练数据
:param title: str,图片的题目
:return: None
"""
x_max, x_min = np.max(X[..., 0]), np.min(X[..., 0])
y_max, y_min = np.max(X[..., 1]), np.min(X[..., 1])
xx, yy = np.meshgrid(np.linspace(x_min - 1, x_max + 1, 1000), np.linspace(y_min - 1, y_max + 1, 1000))
p = model.predict(np.concatenate((xx.ravel().reshape(-1, 1), yy.ravel().reshape(-1, 1)), axis=1))
plt.contour(xx, yy, p.reshape(xx.shape))
plt.title(title)
if __name__ == '__main__':
begin_time = time()
print("========程序开始============")
data2 = sio.loadmat("data\\ex6data1.mat")
X = np.array(data2["X"])
y = np.array(data2["y"])
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
plot_scatter(X[..., 0], X[..., 1], y)
# 下面直接进行模型的创建和训练,C就是我们的参数,可以自己指定核函数,这里直接用线性的也就是没有核函数,因为是线性可分的
model = svm.SVC(C=1, kernel='linear')
# y.ravel() 把y一维向量
model.fit(X, y.ravel())
plot_boundary(model, X, "SVM的决策边界")
plt.show()
print("========程序结束============")
end_time = time()
run_time = end_time - begin_time
print('该循环程序运行时间:', run_time) # 该循环程序运行时间: 1.4201874732
6.2.4 例三选择多参数
import scipy.io as sio
import numpy as np
import matplotlib.pyplot as plt
import scipy.optimize as opt
from sklearn.metrics import classification_report
from time import *
from sklearn import svm
def plot_scatter(x1, x2, y):
"""
绘制散点图
:param x1: ndarray,横坐标数据
:param x2: ndarray,纵坐标数据
:param y: ndarray,标签
:return: None
"""
plt.scatter(x1, x2, c=y.flatten())
plt.xlabel("x1")
plt.ylabel("X2")
def gaussian_kernel(x1, x2, sigma):
"""
核函数
:param x1: x_i
:param x2: x_j
:param sigma:
:return:
"""
return np.exp(-np.sum(np.power(x1 - x2, 2)) / (2 * sigma ** 2))
def plot_boundary(model, X, title):
"""
绘制决策边界
:param model: <class 'sklearn.svm._classes.SVC'>,训练好的模型
:param X: ndarray,训练数据
:param title: str,图片的题目
:return: None
"""
x_max, x_min = np.max(X[..., 0]), np.min(X[..., 0])
y_max, y_min = np.max(X[..., 1]), np.min(X[..., 1])
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 1000), np.linspace(y_min, y_max, 1000))
p = model.predict(np.concatenate((xx.ravel().reshape(-1, 1), yy.ravel().reshape(-1, 1)), axis=1))
plt.contour(xx, yy, p.reshape(xx.shape))
plt.title(title)
if __name__ == '__main__':
begin_time = time()
print("========程序开始============")
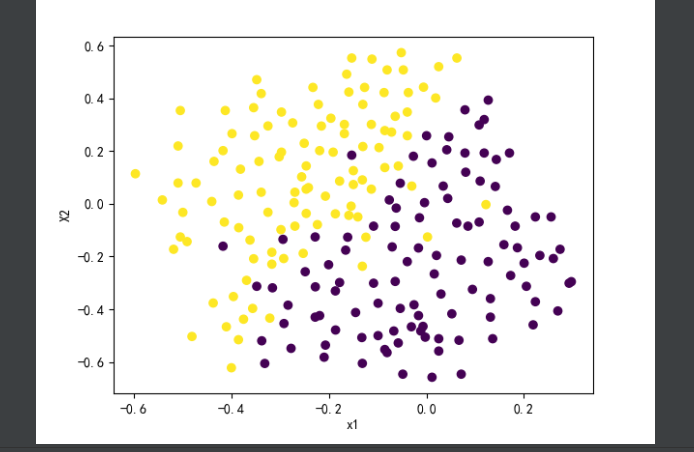
data3 = sio.loadmat("data\\ex6data3.mat")
X = np.array(data3["X"])
y = np.array(data3["y"])
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
plot_scatter(X[..., 0], X[..., 1], y)
# plot.show()
Xval = np.array(data3['Xval'])
yval = np.array(data3['yval'])
xx, yy = np.meshgrid(np.array([0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30]), np.array([0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30]))
parameters = np.concatenate((xx.ravel().reshape(-1, 1), yy.ravel().reshape(-1, 1)), axis=1)
score = np.zeros(1)
for C, sigma in parameters:
gamma = 1 / (2 * np.power(sigma, 2))
model = svm.SVC(C=C, kernel='rbf', gamma=gamma)
model.fit(X, y.ravel())
score = np.append(score, model.score(Xval, yval.ravel()))
res = np.concatenate((parameters, score[1:].reshape(-1, 1)), axis=1)
index = np.argmax(res, axis=0)[-1]
print("参数的最好选择是 :C=", res[index][0], ",sigma=", res[index][1], ",得分=", res[index][2])
# the best choice of parameters:C= 1.0 ,sigma= 0.1 ,score= 0.965
plt.show()
print("========程序结束============")
end_time = time()
run_time = end_time - begin_time
print('该循环程序运行时间:', run_time) # 该循环程序运行时间: 1.4201874732
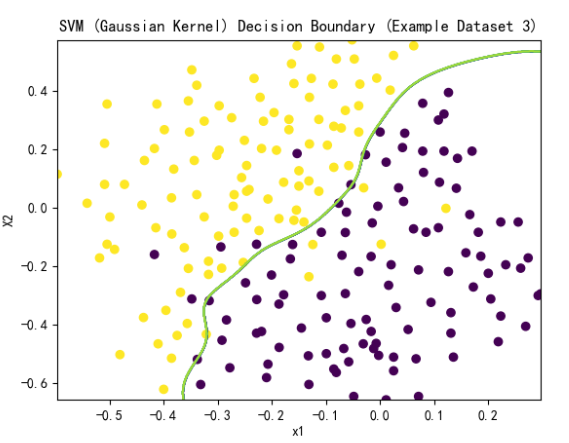
选出的C=1,sigma=0.1时,模型得分最高。以此训练模型,画出决策边界
sigma = 0.1
C = 1.0
gamma = 1 / (2 * np.power(sigma, 2))
model = svm.SVC(C=C, kernel='rbf', gamma=gamma)
model.fit(X, y.ravel())
plot_boundary(model, X, "SVM (Gaussian Kernel) Decision Boundary (Example Dataset 3)")
6.3 关于垃圾邮件分类
6.3.1 题目介绍
如今,许多电子邮件服务都提供能够对电子邮件进行分类的垃圾邮件过滤器,进入垃圾邮件和非垃圾邮件与高准确性。
在本部分练习中,您将使用支持向量机构建自己的垃圾邮件过滤器。
您将训练一个分类器来分类给定的电子邮件x是否为垃圾邮件(y = 1)或非垃圾邮件(y = 0)。
特别是,您需要转换每个将电子邮件转换为特征向量 x ∈ R n x\in R^n x∈Rn
下面的练习将会向您介绍如何从一个电子邮件。
在本练习的其余部分中,您将使用该脚本ex6 spam.m。
本练习所包含的数据集基于SpamAssassin公共语料3为本练习的目的,你将只使用电子邮件的正文(不包括电子邮件的标题)。
6.3.2 预处理的邮件
- 所有字母小写化
- 移除html标签,eg:<p></p>
- 将所有的URL用httpaddr代替
- 将所有的邮箱用emailaddr代替
- 将所有的数字用number代替
- 将所有的$符号用dollar代替
- 提取每个词的词干
- 移除多余的空白字符
import re
from nltk.stem.porter import PorterStemmer
代替的部分我们使用正则表达式去完成,词干提取使用nltk.stem.porter.PorterStemmer实现。
def process_email(content):
"""
处理邮件文本
:param content: str,邮件文本
:return: list,单词列表
"""
content = content.lower()
content = re.sub(r'<.*>', '', content) # 移除html标签
content = re.sub(r'http[s]?://.+', 'httpaddr', content) # 移除url
content = re.sub(r'[\S]+@[\w]+.[\w]+', 'emailaddr', content) # 移除邮箱
content = re.sub(r'[\$][0-9]+', 'dollar number', content) # 移除$,解决dollar和number连接问题
content = re.sub(r'\$', 'dollar number', content) # 移除单个$
content = re.sub(r'[0-9]+', 'number', content) # 移除数字
content = re.sub(r'[\W]+', ' ', content) # 移除字符
words = content.split(' ')
if words[0] == '':
words = words[1:] # 分开时会导致开始空格处多出一个空字符
porter_stemmer = PorterStemmer()
for i in range(len(words)):
words[i] = porter_stemmer.stem(words[i]) # 提取词干
return words
一般会将邮件的单词进行编码,用数字去代替,以便于实现特征的向量化。
这里的数字是由全部数据集的出现的比较多的单词进行排序的,作业中直接提供了。我们直接完成单词到序号的映射。
def mapping(word, vocab):
"""
单词映射为编号
:param word: str,单词
:param vocab: list,编号 表
:return: int,编号
"""
for i in range(len(vocab)):
if word == vocab[i]:
return i
return None
6.3.3 从邮件中提取特征
特征提取就是运用刚才上面的两步内容,实现从邮件到特征向量的转化。
def email_features(email, vocab):
"""
邮件单词列表转化为特征向量
:param email: list,邮件的单词列表
:param vocab: list,编号表
:return: ndarray,特征向量
"""
features = np.zeros((len(vocab, )))
for word in email:
index = mapping(word, vocab)
if index is not None:
features[index] = 1
return features
6.3.4 垃圾邮件分类训练支持向量机
作业中后面没有用到上面的,直接提供了处理好的训练数据,但是推荐大家实现。我这里直接训练模型,这里由于数据量还是比较大,这里不用核函数效果更好,具体的选择方法我在最后总结。
train_data = sio.loadmat("data\\spamTrain.mat")
train_X = train_data['X'] # (4000,1899)
train_y = train_data['y'] # (4000,1)
test_data = sio.loadmat("data\\spamTest.mat")
test_X = test_data['Xtest'] # (1000,1899)
test_y = test_data['ytest'] # (1000,1)
model = svm.SVC(kernel='linear') # 这里的n比较大,选用线性核函数效果好
model.fit(train_X, train_y.ravel())
print(model.score(train_X, train_y.ravel()), model.score(test_X, test_y.ravel()))
#0.99975 0.978
6.3.5 测试
f = open("data\\vocab.txt")
vocab = [] # python中的下标从0起,因此与作业中有所不同
for l in f.readlines():
s = l.split('\t')[-1].split('\n')[0]
vocab.append(s)
#
print(mapping('anyon', vocab))
#
print(email_features("aa hello", vocab))
x = email_features(process_email(open("data\\emailSample2.txt").read()), vocab)
# 预测是否是垃圾邮件,0表示emailSample2.txt 中的内容是垃圾邮件
print(model.predict(x.reshape(1, -1)))#[0]
这里来总结一下
- 当特征数量相对于训练集数量很大时,使用逻辑回归或者是使用线性核函数的支持向量机
- 当特征数量很少,训练集数据量一般,使用高斯核函数的支持向量机
- 当特征数量很少,训练集数据很大,可以考虑添加更多特征,然后使用逻辑回归或者是使用线性核函数的支持向量机
fork了别人的项目,自己重新填写,我的代码如下
https://gitee.com/fakerlove/machine-learning/tree/master/code

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)