
机器学习——SMO算法推导与实践
最后拉格朗日对偶问题,是要求解MAXλL(λ)=∑λi−∑i=1n∑j=1nλiλjxixjyiyj2MAX_λL(λ)=∑λ_i-\frac{∑_{i=1}^n∑_{j=1}^nλ_iλ_jx_ix_jy_iy_j}{2}MAXλL(λ)=∑λi−2∑i=1n∑j=1nλiλjxixjyiyj即,通过调整λ值,求解L函数极大值而Max:LMax: LMax:L可以转化为求M
一、 硬间隔-SMO算法推导
明天再说,啊。。。。感觉天空明朗了很多,即使现在已经很晚了
还是要打开柯南,看看电视,等待天气预报所说的台风天吧!
一时之间,忽然失去了用markdown语法写下推导过程的勇气。。。以上只是自己在线性可分的情况下,推导的smo算法但实际书本上给出的smo算法,是增加了软间隔后的smo算法
以上只是理解版本的推导,但实际要用在程序上理解,绝不能这么不严谨是的,我现在终于理解为什么为什么为什么课本要列出那么多奇奇怪怪的符号那都是非常简便的表达方式!
看了自己手动推的乱七八糟SMO,再看看人家推导的!SMO保姆级教学
我终于发现自己推导的漏洞百出
哭了,哭着重新在草稿纸继续推导吧~
最后拉格朗日对偶问题,是要求解
MAXλL(λ)=∑λi−∑i=1n∑j=1nλiλjxixjyiyj2MAX_λL(λ)=∑λ_i-\frac{∑_{i=1}^n∑_{j=1}^nλ_iλ_jx_ix_jy_iy_j}{2}MAXλL(λ)=∑λi−2∑i=1n∑j=1nλiλjxixjyiyj
即,通过调整λ值,求解L函数极大值
而Max:LMax: LMax:L可以转化为求Min:−LMin:- LMin:−L,即求解MinλL(λ)=∑i=1n∑j=1nλiλjxixjyiyj2−∑λiMin_λL(λ)=\frac{∑_{i=1}^n∑_{j=1}^nλ_iλ_jx_ix_jy_iy_j}{2}-∑λ_iMinλL(λ)=2∑i=1n∑j=1nλiλjxixjyiyj−∑λi
接下来,采用SMO算法,求解Min:LMin: LMin:L
①使最终数据符合KKT条件:
- λg(w,b)≤0,且要保证λ≥0,因此KKT条件的判断具体分为以下两种λg(w,b)≤0,且要保证λ≥0,因此KKT条件的判断具体分为以下两种λg(w,b)≤0,且要保证λ≥0,因此KKT条件的判断具体分为以下两种
- λi>0时,g(w,b)=0,即1−yi∗(Wxi+b)=0λ_i>0时,g(w,b)=0,即1-y_i*(Wx_i+b)=0λi>0时,g(w,b)=0,即1−yi∗(Wxi+b)=0
- λi=0时,g(w,b)≤0,即1−yi∗(Wxi+b)≤0λ_i = 0时,g(w,b)≤0,即1-y_i*(Wx_i+b)≤0λi=0时,g(w,b)≤0,即1−yi∗(Wxi+b)≤0
②λ要始终满足 Σλiyi=0Σλ_iyi=0Σλiyi=0
SMO算法思想:迭代+贪心
由于每条数据都对应一个λ值,即xi,yi,λix_i,y_i,λ_ixi,yi,λi,因此假设有n条数据,就有n个λ,直接求导非常困难
SMO算法提出:每次迭代2个λ,确保这2个λ都在自己能力范围内,都尽可能使L(λ)函数值达到最优,且始终保持 Σλiyi=0Σλ_iyi=0Σλiyi=0
这就像是贪心算法,局部最优,最终全局最优
简单点:每个人都拼尽全力让社会更美好,那么社会才会达到最美好
每道题都拿最高分,你就是rolling king or rolling queen
SMO思想,甚至还有先富带后富的先进理念,我无法同时让λ达到状态,但我可以每次2个,既可以保证Σλiyi=0Σλ_iyi=0Σλiyi=0,还可以逐次使L达到最优
1. 算法步骤总览
明确SMO的迭代+贪心的思想后,就可以简化为以下几个步骤:
①未知参数赋初值:
②选择2个迭代λ(用λ_1,λ_2分别代表选中的2个λ)
③求解迭代后的λ,并判断是否满足λ≥0条件
④计算当前的Wnew,bnewW_{new},b_{new}Wnew,bnew
⑤若全部满足KKT条件,或达到迭代次数,则停止SMO算法
看似简单的步骤,实则难于上青天
①未知参数赋初值
- λ:λ_i全赋值为0,这样即可保证Σλiyi=0Σλ_iyi=0Σλiyi=0
- W:W=∑λixi∗yi,因此W也全为0W=∑λ_ix_i*y_i,因此W也全为0W=∑λixi∗yi,因此W也全为0
- b:b没有条件限制要求,可以直接赋值为0
【需要注意:λ的个数为n,表示n条数据就有n个λ,W的个数为影响因素的个数(即有m种x,就有m个W)】
例如性别、年龄、收入这三个影响因素x,决定幸福感y,那么W就有3个
②选择2个迭代λ(用λ_1,λ_2分别代表选中的2个λ)
- λ1的选择方式:选择最偏离KKT条件的λ
如何判断偏离KKT条件的程度?
- λg(w,b)≤0,且要保证λ≥0,因此KKT条件的判断具体分为以下两种λg(w,b)≤0,且要保证λ≥0,因此KKT条件的判断具体分为以下两种λg(w,b)≤0,且要保证λ≥0,因此KKT条件的判断具体分为以下两种
-
λi>0时,g(w,b)=0,即1−yi∗(Wxi+b)=0λ_i>0时,g(w,b)=0,即1-y_i*(Wx_i+b)=0λi>0时,g(w,b)=0,即1−yi∗(Wxi+b)=0
-
λi=0时,g(w,b)≤0,即1−yi∗(Wxi+b)≤0λ_i = 0时,g(w,b)≤0,即1-y_i*(Wx_i+b)≤0λi=0时,g(w,b)≤0,即1−yi∗(Wxi+b)≤0
-
首先是违反KKT条件,其次违反程度通过g(w,b)值来衡量,即选择max:g(w,b)下的λiλ_iλi
但建议还是将违反KKT条件的程度,降序排列得到一个违反KKT条件的g(w,b)降序列表 -
这样,如果g(w,b)的最大值对应的λ1不满足迭代条件时,还可以退而求其次,选g(w,b)第二大对应的λ1
-
【判断1】若选不到λ1,说明所有λ都满足KKT条件,可停止SMO算法
-
- λ2的选择方式:选择能使λ2改变最大的λ
- 公式推导出的λ2new=λ2old+yi∗(E1−E2)K11+K22−2K12λ2_{new}=λ2_{old}+\frac{y_i*(E1-E2)}{K11+K22-2K12}λ2new=λ2old+K11+K22−2K12yi∗(E1−E2) ,当∣E1−E2∣大|E1-E2|大∣E1−E2∣大说明这两条对应的数据差距比较大【后续再公式推导】
- 【判断1】若当前|E1-E2|最大的λ2不满足条件要求,则重选λ,即退而求其次选|E1-E2|第二大对应的λ2
- 【判断2】若选不到λ2,则重新选λ1,再选λ2
- 重选λ1,是指选下一个偏离KKT条件的λ,而不是最偏离了【降序选择λ1】
λ2newλ2_{new}λ2new的公式推导:
求解MinλL(λ)=∑i=1n∑j=1nλiλjxixjyiyj2−∑λiMin_λL(λ)=\frac{∑_{i=1}^n∑_{j=1}^nλ_iλ_jx_ix_jy_iy_j}{2}-∑λ_iMinλL(λ)=2∑i=1n∑j=1nλiλjxixjyiyj−∑λi,已知所有λ均有初值
那么单独挑出λ1、λ2作为未知量来求L极值,并迭代,则需将其余的λ3…λn都当作常数
- 未知量:λ1、λ2
- 常数:λ3…λn
- 实际λ1、λ2本身是有旧值的,但我们要求解的是它们的新值,因此当作未知量来求导
step1: 因此先分离出L(λ)里含λ1和λ2的项,再进行求导:
第一部分:12∑i=1n∑j=1nλiλjxixjyiyj\frac{1}{2}∑_{i=1}^n∑_{j=1}^nλ_iλ_jx_ix_jy_iy_j21∑i=1n∑j=1nλiλjxixjyiyj
=12[λ12y12x1.x1+λ22y22x2.x2+2λ1λ1y1y2x1.x2+2(λ1y1x1+λ2y2x2)∑i=3nλiyixi+∑i=3n∑j=3nλiλjxixjyiyj]=\frac{1}{2}[ λ_1^2y_1^2x_1.x_1+λ_2^2y_2^2x_2.x_2+2λ_1λ_1y_1y_2x_1.x_2+2(λ_1y_1x_1+λ_2y_2x_2)∑^n_{i=3}λ_iy_ix_i+∑_{i=3}^n∑_{j=3}^nλ_iλ_jx_ix_jy_iy_j]=21[λ12y12x1.x1+λ22y22x2.x2+2λ1λ1y1y2x1.x2+2(λ1y1x1+λ2y2x2)∑i=3nλiyixi+∑i=3n∑j=3nλiλjxixjyiyj]
注:x1.x1x1.x1x1.x1中间的点,表示点积,因为xix_ixi本身是向量,向量相乘即为点积运算
第二部分:∑λi=λ1+λ2+∑i=3nλi∑λ_i=λ_1+λ_2+∑^n_{i=3}λ_i∑λi=λ1+λ2+∑i=3nλi
step2: 后续求导常数无用则删: 将第一、二部分常数删去后,再拼接成只含迭代变量的Q(λ1,λ2)函数
Q=12[λ12y12x1.x1+λ22y22x2.x2+2λ1λ1y1y2x1.x2+2(λ1y1x1+λ2y2x2)∑i=3nλiyixi]+λ1+λ2Q = \frac{1}{2}[ λ_1^2y_1^2x_1.x_1+λ_2^2y_2^2x_2.x_2+2λ_1λ_1y_1y_2x_1.x_2+2(λ_1y_1x_1+λ_2y_2x_2)∑^n_{i=3}λ_iy_ix_i]+λ_1+λ_2Q=21[λ12y12x1.x1+λ22y22x2.x2+2λ1λ1y1y2x1.x2+2(λ1y1x1+λ2y2x2)∑i=3nλiyixi]+λ1+λ2
step3: 将Q函数变为只含一个未知λ,再求导
由Σλiyi=0Σλ_iyi=0Σλiyi=0可得:λ1y1+λ2y2=−∑i=3nλi=−λ1oldy1−λ2oldy2λ_1y_1+λ_2y_2=-∑^n_{i=3}λ_i=-λ_{1old}y_1-λ_{2old}y_2λ1y1+λ2y2=−∑i=3nλi=−λ1oldy1−λ2oldy2
这里的λ1、λ2表示未知量,λ1old,λ2oldλ_{1old},λ_{2old}λ1old,λ2old则表示它们的旧值
∑i=3nλi=λ1oldy1+λ2oldy2,可视为常数A,方便简化计算∑^n_{i=3}λ_i=λ_{1old}y_1+λ_{2old}y_2,可视为常数 A,方便简化计算∑i=3nλi=λ1oldy1+λ2oldy2,可视为常数A,方便简化计算
给λ1y1+λ2y2=−Aλ_1y_1+λ_2y_2=-Aλ1y1+λ2y2=−A两边乘以y1,并移项可得:λ1 = -λ2y1y2-Ay1
将λ1=−λ2y1y2−Ay1代入Q函数λ1 = -λ2y1y2-Ay1代入Q函数λ1=−λ2y1y2−Ay1代入Q函数,即可得到只含未知量λ2的Q函数,并对λ2求导后,整理可得
Qλ2′=hahahahhahahahhahah放弃markdown语法写推导,太长辣救命Q'_{λ2} = hahahahhahahahhahah放弃markdown语法写推导,太长辣救命Qλ2′=hahahahhahahahhahah放弃markdown语法写推导,太长辣救命
然后再将A=∑i=3nλiA=∑^n_{i=3}λ_iA=∑i=3nλi代入Qλ2′Q'_{λ2}Qλ2′,并令Wxi+b−yi=Ei,表示预测值与真实值的差距Wx_i+b-y_i = E_i,表示预测值与真实值的差距Wxi+b−yi=Ei,表示预测值与真实值的差距
则令Qλ2′=0Q'_{λ2} =0Qλ2′=0,最终整理出λ2=λ2old+y2∗(E1−E2)x1.x1+x2.x2−2x1.x2λ2 = λ_{2old}+\frac{y2*(E1-E2)}{x1.x1+x2.x2-2x1.x2}λ2=λ2old+x1.x1+x2.x2−2x1.x2y2∗(E1−E2)
③求解迭代后的λ,并判断是否满足迭代条件
λ的条件要满足:λ≥0,即求解出的λ1、λ2都要满足≥0的条件
通过上一步可得到λ2=λ2old+y2∗(E1−E2)x1.x1+x2.x2−2x1.x2λ2 = λ_{2old}+\frac{y2*(E1-E2)}{x1.x1+x2.x2-2x1.x2}λ2=λ2old+x1.x1+x2.x2−2x1.x2y2∗(E1−E2)
因此可先判断λ2≥0:
- 如果λ2≥0,即继续往下
- 如果λ2不满足条件,则返回重选λ2
接着判断λ1,由λ1=−λ2y1y2−Ay1≥0λ_1 = -λ_2y_1y_2-Ay_1≥0λ1=−λ2y1y2−Ay1≥0可得
- 当y1y2 = 1时:λ2≤−Ay1λ2≤-Ay_1λ2≤−Ay1
- 当y1y2 = -1时:λ2≥Ay1λ2≥Ay_1λ2≥Ay1
- 如果满足任意一个条件,则继续往下
- 如果以上两个条件都不满足,则返回重选λ2
④计算当前的Wnew,bnewW_{new},b_{new}Wnew,bnew
计算出满足λ≥0的λ1和λ2后,可代入求解最新的WnewW_{new}Wnew
Wold=λ1oldy1x1+λ2oldy2x2+∑i=3nλiyixiW_{old} = λ_{1old}y_1x_1+λ_{2old}y_2x_2+∑^n_{i=3}λ_iy_ix_iWold=λ1oldy1x1+λ2oldy2x2+∑i=3nλiyixi
Wnew=λ1y1x1+λ2y2x2+∑i=3nλiyixiW_{new} = λ_{1}y_1x_1+λ_{2}y_2x_2+∑^n_{i=3}λ_iy_ix_iWnew=λ1y1x1+λ2y2x2+∑i=3nλiyixi
则Wnew=Wold+(λ1−λ1old)y1x1+(λ2−λ2old)y2x2W_{new} = W_{old}+(λ_{1}-λ_{1old})y_1x_1+(λ_{2}-λ_{2old})y_2x_2Wnew=Wold+(λ1−λ1old)y1x1+(λ2−λ2old)y2x2
可见,每次W的更新,都只与选择的两个λ有关
bnewb_{new}bnew,表示两条边界上的b1和b2的中间值
怎么判断是不是边界呢?
其实也就是当λ>0的时候,因此λ>0,则g(w,b)=0,这在之前的拉格朗日乘数法中已证明为支持向量,即边界
因此,则当λ1、λ2均大于0时,根据 g(w,b)=1−yi(Wnewxi+b)=0g(w,b) = 1-y_i(W_{new}x_i+b) = 0g(w,b)=1−yi(Wnewxi+b)=0
求出
b1new=y1−Wnewx1b_{1new}= y_1-W_{new}x_1b1new=y1−Wnewx1
b2new=y2−Wnewx2b_{2new}= y_2-W_{new}x_2b2new=y2−Wnewx2
则bnew=b1new+b2new2b_{new} = \frac{b_{1new}+b_{2new}}{2}bnew=2b1new+b2new
⑤若全部满足KKT条件,或达到迭代次数,则停止SMO算法
硬间隔情况下的推导比较简单,但实践起来困难重重,并且有些是想不通的
1、 选出违反KKT条件最严重的λ1,再选出|E1-E2|值最大的λ2,但计算出的λ1new、λ2newλ1_{new}、λ2_{new}λ1new、λ2new并不满足λ≥0的条件,因此需要重新选λ,但要怎么重新选呢?
- 先重新选λ2:将所有λ的|E1-E2|进行降序排列,再依次选择对应的λ2,直到λ1new、λ2newλ1_{new}、λ2_{new}λ1new、λ2new都满足λ≥0
- 如果所有的|E1-E2|>0的λ都选择了个遍,却依然无法满足λ≥0,则说明当前的λ1暂时选不出合适的λ2
- 则可以重新选择λ1,重新选择的是违反KKT条件程度第二的λ
- 如果选到了合适的λ2,则在完成λ1、λ2的迭代后,返回重新选λ1、λ2,开始新一轮的迭代。
但在实践过程中,即使数据是线性可分的,可一旦数据量很多的时候,就很难收敛了,并且经常在几个数据里来回震荡,无法完全满足KKT条件的同时还能满足迭代后的λ≥0
于是,为了解决这个问题,采取了限定迭代次数的方法
并且测试时,自己设计了线性关系,哎。。。总之就是
如果只有一个影响因素x,并且成线性关系时,数据量少的情况下(测试10条),是可以完全准确分类的。。。。
但是训练的过程。。。真的好慢好慢好慢啊。。。。只要我多加一个新的线性影响因素,还是10条数据。。。。。就会慢的要死,并且还很难收敛到所有λ都满足KKT条件,只有到10000次迭代次数自动停止后,才结束训练,不过好在10条数据内,2个影响因素,都还是100%的分类准确率
我甚至不敢测试多几条数据。。。。但还是英勇的选择了100条数据进行训练…
果然还是无法完全收敛满足KKT条件,超过迭代次数后停下来的
最终准确率还是降低了…差不多就得了…实际它都没迭代完。。。但数据量实在太大了
import numpy as np
import pandas as pd
import random
import matplotlib.pyplot as plt
import time
# 获取所需数据:
datas = pd.read_excel('./datas6.xlsx')
important_features = ['推荐分值','专业度','推荐类型']
# datas = pd.read_excel('./datas5.xlsx')
# important_features = ['推荐分值','推荐类型']
datas_1 = datas[important_features].head(100)
Y = datas_1['推荐类型']
X = datas_1.drop('推荐类型',axis=1)
X_features = X.columns
Y_features = '推荐类型'
rows,columns = datas_1.shape
Y=Y.where(Y!="高推荐",other=1) # 高推荐设置为1
Y=Y.where(Y!="低推荐",other=-1) # 低推荐设置为-1
class SMO():
def __init__(self,X,Y):
self.X = X
self.Y = Y
self.m = X.shape[1]
self.n = Y.shape[0]
self.lamb = np.zeros(self.n)
self.b = 0
self.W0 = np.zeros(self.m)
self.times = 10000
self.Finish = False
self.break_kkt = {}
self.break_kkt_list = []
self.E = None
def count_break_KKT(self):
del self.break_kkt
self.break_kkt = {}
self.g = 1-self.Y*((self.W0*self.X).sum(axis=1)+self.b)
# time.sleep(3)
for index,g_value in self.g.items():
a = self.lamb[index]
if a < 0:
raise Exception(f"lamb1_new为{lamb1_new},还是小于0")
elif a == 0 and g_value>0:
self.break_kkt[index] = abs(g_value)
elif a > 0 and g_value!=0:
self.break_kkt[index] = abs(g_value)
def run(self):
select_lamb1 = False
while not self.Finish and self.times>0:
if len(self.break_kkt_list) == 0:
self.count_break_KKT()
self.break_kkt_list = sorted(self.break_kkt.items(), key=lambda d: d[1], reverse=True)
if len(self.break_kkt_list) == 0:
print("已全部满足KKT")
break
# print(f"当前违反KKT条件的:{self.break_kkt_list}")
# time.sleep(3)
index1 = self.break_kkt_list.pop(0)[0]
x1 = self.X.iloc[index1]
y1 = self.Y[index1]
lamb1_old = self.lamb[index1]
self.E = (self.W0 * self.X).sum(axis=1) + self.b - self.Y
e1 = self.E[index1]
self.E1E2_all = e1-self.E
self.E1E2_abs = (e1-self.E).abs()
self.E1E2_sort = sorted(self.E1E2_abs.items(), key=lambda d: d[1], reverse=True)
# print(f"当前的E1E2排序:{self.E1E2_sort}")
# time.sleep(3)
self.times -= 1
for j in self.E1E2_sort:
index2 = j[0]
x2 = self.X.iloc[index2]
y2 = self.Y[index2]
lamb2_old = self.lamb[index2]
e1_e2 = self.E1E2_all[index2]
# print(f"选中的第{index1}和第{index2}的E差值为{e1_e2},参数:{self.lamb[index1], self.lamb[index2]}")
# time.sleep(3)
if e1_e2 == 0:
# print(f"由于两者的E差值为0,因此不进行迭代")
select_lamb1 = True
break
temp = sum(x1*x1+x2*x2-2*x1*x2)
A = -lamb1_old*y1-lamb2_old*y2
if temp==0:
# print("当前的index1和index2的X值一致,可以直接将index2的lamb2_new等同于lamb1_new")
# time.sleep(3)
continue
lamb2_new = lamb2_old + e1_e2*y2/temp
if lamb2_new<0:
continue
elif y1*y2 == 1:
if lamb2_new > -A*y1:
continue
elif y1*y2 == -1:
if lamb2_new < A*y1:
continue
lamb1_new = -lamb2_new*y1*y2-A*y1
time.sleep(3)
self.W0 = self.W0+(lamb1_new-lamb1_old)*y1*x1+(lamb2_new-lamb2_old)*y2*x2
self.W0 = np.array(self.W0)
b1_new = y1-sum(self.W0*x1)
b2_new = y2-sum(self.W0*x2)
self.b = np.array((b1_new+b2_new)/2)
self.lamb[index1]=lamb1_new
self.lamb[index2]=lamb2_new
print(f"新的lamb:{self.lamb},\nW0为{self.W0},b为{self.b}")
select_lamb1 = True
break
else:
print(f"可选的E2中:{self.E1E2_sort},没有满足条件的lamb2")
if select_lamb1:
select_lamb1 = False
self.count_break_KKT()
self.break_kkt_list = sorted(self.break_kkt.items(), key=lambda d: d[1], reverse=True)
if len(self.break_kkt_list)==0:
self.Finish = True
print("已全部服从KKT条件")
sum_lamb_y = sum(self.lamb*self.Y)
print(f"汇总后的值是否为零:{sum_lamb_y}")
print(self.lamb)
break
lambs = sorted([(index1,value1) for index1,value1 in enumerate(self.lamb)],key=lambda x:x[1],reverse=True)
index1 = lambs.pop(0)[0]
for index2,value2 in enumerate(lambs):
if self.Y[index1]!=self.Y[index2] and value2!=0:
print("++++++++++++++++++++++++++++++++++++")
x1 = self.X.iloc[index1]
x2 = self.X.iloc[index2]
print(self.W0*x1)
print((self.W0*x1).sum(axis=0))
b1_new = np.array(self.Y[index1]-(self.W0*x1).sum(axis=0))
b2_new = np.array(self.Y[index2]-(self.W0*x2).sum(axis=0))
b_new = (b1_new+b2_new)/2
self.b = b_new
print("++++++++++++++++++++++++++++++++++++")
break
print(b1_new,b2_new)
self.W0 = np.array([self.W0])
print("_________________________")
print(self.W0)
print(self.X)
print(self.b)
print("_________________________")
z = (self.W0*self.X).sum(axis=1)+self.b
self.Y_pre = []
"""原本计划是要大于支持向量边界时,也就是大于1,才能分类为1,小于-1才能分类为-1,但实际还是有些点位于<-1,1>之间,导致无法完全实现点全在两侧边界分类的效果,因此直接用中间的分类函数进行分"""
for i in z:
if i>=0:
self.Y_pre.append(1)
elif i<0:
self.Y_pre.append(-1)
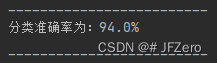
print(f"分类准确率为:{round(sum(self.Y_pre==self.Y)/self.Y.shape[0]*100,2)}%")
test = SMO(X,Y)
test.run()
二、 软间隔-对偶问题及smo算法推导
之前要求的对偶问题:MAXλL(λ)=∑λi−∑i=1n∑j=1nλiλjxixjyiyj2MAX_λL(λ)=∑λ_i-\frac{∑_{i=1}^n∑_{j=1}^nλ_iλ_jx_ix_jy_iy_j}{2}MAXλL(λ)=∑λi−2∑i=1n∑j=1nλiλjxixjyiyj
是基于线性可分的情况下【即硬间隔】,一旦数据并不是严格线性可分的情况下,SVM就会失效
我猜测,极有可能无法应用SMO算法,计算出正确的λ
因此,每条数据都引入一个松弛变量的ξiξ_iξi
然后每条数据的约束条件就变为 yi(Wxi+b)≥1−ξiy_i(Wx_i+b)≥1-ξ_iyi(Wxi+b)≥1−ξi,且ξ≥0
但引入松弛变量,就要在目标函数上,增加惩罚项
原目标函数min:f=w22min:f=\frac{w^2}{2}min:f=2w2
增加惩罚项后为min:f=w22+C∑ξimin:f=\frac{w^2}{2}+C∑ξ_imin:f=2w2+C∑ξi
这里的C是我们自己设置的惩罚项权重常数
其实我也很困惑:这个惩罚项到底对于目标函数的实现,有什么作用呢?
按我的初步想法是,将惩罚项放入原函数中,w22+C∑ξi\frac{w^2}{2}+C∑ξ_i2w2+C∑ξi 表示,要让w22和C∑ξi\frac{w^2}{2}和C∑ξ_i2w2和C∑ξi在相互影响相互制约的情况下,尽可能使f(x)达到极小值
那么min:f=w22+C∑ξimin:f=\frac{w^2}{2}+C∑ξ_imin:f=2w2+C∑ξi中,如果C比较大,那么松弛变量对目标函数f的影响就会比较大,因此会在训练过程中,偏向于让ξ达到最小,而w就没那么重要了
反之,如果C比较小,则松弛变量ξ对目标函数f的影响就比较小,因此训练过程中会倾向于让w达到最小,松弛变量反而就相对没那么重要。
通常在sklearn中,这个C默认取值为1,但训练出来的结果未必令人满意的,因此要看情况设置C【这部分回头再说】
现在的求解目标为:
- 目标函数为min:f=w22+C∑ξimin:f=\frac{w^2}{2}+C∑ξ_imin:f=2w2+C∑ξi
- 约束条件为:
- g(w,b,ξ)=1−ξi−yi(Wxi+b)≤0g(w,b,ξ) = 1-ξ_i-y_i(Wx_i+b)≤0g(w,b,ξ)=1−ξi−yi(Wxi+b)≤0 ,这是约束条件1
- ξ≥0ξ≥0ξ≥0,这是约束条件2,转为−ξ≤0-ξ≤0−ξ≤0
根据拉格朗日乘数法,建立函数L:
第一个约束条件,用λ表示对应的拉格朗日乘子
第二个约束条件,用β表示对应的拉格朗日乘子
minL(w,b,ξ,λ,β)=w22+CΣξi+Σλi[1−ξi−yi(Wxi+b)]−Σβiξimin L(w,b,ξ,λ,β)=\frac{w^2}{2}+CΣξ_i+Σλ_i[1-ξ_i-y_i(Wx_i+b)]-Σβ_iξ_iminL(w,b,ξ,λ,β)=2w2+CΣξi+Σλi[1−ξi−yi(Wxi+b)]−Σβiξi
KKT条件是:
- λi[1−ξi−yi(Wxi+b)]=0λ_i[1-ξ_i-y_i(Wx_i+b)]=0λi[1−ξi−yi(Wxi+b)]=0
- λi>0时,1−ξi−yi(Wxi+b)=0λ_i>0时, 1-ξ_i-y_i(Wx_i+b)=0λi>0时,1−ξi−yi(Wxi+b)=0
- λi=0时,1−ξi−yi(Wxi+b)≤0λ_i=0时, 1-ξ_i-y_i(Wx_i+b)≤0λi=0时,1−ξi−yi(Wxi+b)≤0
- βiξi=0β_iξ_i=0βiξi=0
- βi>0时,ξi=0β_i>0时,ξ_i=0βi>0时,ξi=0
- βi=0时,ξi≥0β_i=0时,ξ_i≥0βi=0时,ξi≥0
将拉格朗日函数,变为对偶问题:
minL(w,b,ξ,λ,β)=w22+CΣξi+Σλi[1−ξi−yi(Wxi+b)]−Σβiξimin L(w,b,ξ,λ,β)=\frac{w^2}{2}+CΣξ_i+Σλ_i[1-ξ_i-y_i(Wx_i+b)]-Σβ_iξ_iminL(w,b,ξ,λ,β)=2w2+CΣξi+Σλi[1−ξi−yi(Wxi+b)]−Σβiξi
由于求极值过程中,是要先w,b,ξ求其极小值,因此可以同之前硬间隔那样推导出对偶函数为
Maxλ,βMinw,b,ξL(w,b,ξ,λ,β)=w22+CΣξi+Σλi[1−ξi−yi(Wxi+b)]−ΣβiξiMax_{λ,β}Min_{w,b,ξ} L(w,b,ξ,λ,β)=\frac{w^2}{2}+CΣξ_i+Σλ_i[1-ξ_i-y_i(Wx_i+b)]-Σβ_iξ_iMaxλ,βMinw,b,ξL(w,b,ξ,λ,β)=2w2+CΣξi+Σλi[1−ξi−yi(Wxi+b)]−Σβiξi
先对w,b,以及每一个ξ_i分别求偏导,得到以下三个条件
- w=Σλixiyiw = Σλ_ix_iy_iw=Σλixiyi ———①
- Σλiyi=0Σλ_iy_i=0Σλiyi=0 ———②
- C−λi−βi=0C-λ_i-β_i = 0C−λi−βi=0 ———③
将C−Σλi−Σβi=0C-Σλ_i-Σβ_i = 0C−Σλi−Σβi=0转为Σβi=C−ΣλiΣβ_i =C-Σλ_iΣβi=C−Σλi,并结合①,代入对偶函数,整理得到
Max(λ)=Σλi−12ΣΣλiλjyiyjxixjMax(λ) =Σλ_i-\frac{1}{2}ΣΣλ_iλ_jy_iy_jx_ix_jMax(λ)=Σλi−21ΣΣλiλjyiyjxixj,这会发现,与之前硬间隔的对偶函数是一样的
松弛变量ξ及对应的拉格朗日乘子β,对目标求解并无直接影响。
但KKT条件是对SMO迭代时,有条件上的额外限制
KKT条件是:
- λi[1−ξi−yi(Wxi+b)]=0λ_i[1-ξ_i-y_i(Wx_i+b)]=0λi[1−ξi−yi(Wxi+b)]=0
- λi>0时,1−ξi−yi(Wxi+b)=0λ_i>0时, 1-ξ_i-y_i(Wx_i+b)=0λi>0时,1−ξi−yi(Wxi+b)=0
- λi=0时,1−ξi−yi(Wxi+b)≤0λ_i=0时, 1-ξ_i-y_i(Wx_i+b)≤0λi=0时,1−ξi−yi(Wxi+b)≤0
- 总之:λi≥0λ_i≥0λi≥0————①
- βiξi=0β_iξ_i=0βiξi=0
- βi=C−λi>0时,ξi=0β_i=C-λ_i>0时,ξ_i=0βi=C−λi>0时,ξi=0
- βi=C−λi=0时,ξi≥0β_i=C-λ_i=0时,ξ_i≥0βi=C−λi=0时,ξi≥0
- 总之:βi=C−λi≥0β_i=C-λ_i≥0βi=C−λi≥0——————②
- 由①②综合得:C≥λi≥0C≥λ_i≥0C≥λi≥0
对偶补充条件是:
- w=Σλixiyiw = Σλ_ix_iy_iw=Σλixiyi
- Σλiyi=0Σλ_iy_i=0Σλiyi=0
- C−λi−βi=0C-λ_i-β_i = 0C−λi−βi=0
在SMO迭代时的5个步骤里,在第①③④⑤上都有各自对应的调整
①未知参数赋初值:C、λ、w、b
- C: 可先设置为1
- λ:λ_i全赋值为0,这样即可保证Σλiyi=0Σλ_iyi=0Σλiyi=0
- ξ:ξi由C−λi得到ξ_i由C-λ_i得到ξi由C−λi得到
- W:W=∑λixi∗yi,因此W也全为0W=∑λ_ix_i*y_i,因此W也全为0W=∑λixi∗yi,因此W也全为0
- b:b没有条件限制要求,可以直接赋值为0
②选择2个迭代λ(用λ_1,λ_2分别代表选中的2个λ)
-
λ1的选择方式:选择最偏离KKT条件的λ
-
首先是违反KKT条件,
- λi[1−ξi−yi(Wxi+b)]=0λ_i[1-ξ_i-y_i(Wx_i+b)]=0λi[1−ξi−yi(Wxi+b)]=0
- λi>0时,1−ξi−yi(Wxi+b)=0λ_i>0时, 1-ξ_i-y_i(Wx_i+b)=0λi>0时,1−ξi−yi(Wxi+b)=0
- λi=0时,1−ξi−yi(Wxi+b)≤0λ_i=0时, 1-ξ_i-y_i(Wx_i+b)≤0λi=0时,1−ξi−yi(Wxi+b)≤0
-
其次违反程度通过max:1−ξ−y(wx+b)max:1-ξ-y(wx+b)max:1−ξ−y(wx+b)值来衡量,即选择max:1−ξ−y(wx+b)max:1-ξ-y(wx+b)max:1−ξ−y(wx+b)下的λiλ_iλi
但建议还是将违反KKT条件的程度,降序排列得到一个违反KKT条件的1−ξ−y(wx+b)1-ξ-y(wx+b)1−ξ−y(wx+b)降序列表 -
这样,如果1−ξ−y(wx+b)1-ξ-y(wx+b)1−ξ−y(wx+b)的最大值对应的λ1不满足迭代条件时,还可以退而求其次,选1−ξ−y(wx+b)1-ξ-y(wx+b)1−ξ−y(wx+b)第二大对应的λ1
-
【判断1】若选不到λ1,说明所有λ都满足KKT条件,可停止SMO算法
-
-
λ2的选择方式:选择能使λ2改变最大的λ
- 公式推导出的λ2new=λ2old+yi∗(E1−E2)K11+K22−2K12λ2_{new}=λ2_{old}+\frac{y_i*(E1-E2)}{K11+K22-2K12}λ2new=λ2old+K11+K22−2K12yi∗(E1−E2) ,当∣E1−E2∣大|E1-E2|大∣E1−E2∣大说明这两条对应的数据差距比较大【后续再公式推导】
- 【判断1】若当前|E1-E2|最大的λ2不满足条件要求,则重选λ,即退而求其次选|E1-E2|第二大对应的λ2
- 【判断2】若选不到λ2,则重新选λ1,再选λ2
- 重选λ1,是指选下一个偏离KKT条件的λ,而不是最偏离了【降序选择λ1】
最终整理出λ2=λ2old+y2∗(E1−E2)x1.x1+x2.x2−2x1.x2λ2 = λ_{2old}+\frac{y2*(E1-E2)}{x1.x1+x2.x2-2x1.x2}λ2=λ2old+x1.x1+x2.x2−2x1.x2y2∗(E1−E2)
③求解迭代后的λ,并判断是否满足迭代条件
条件1:λ≥0,即求解出的λ1、λ2都要满足C≥λ≥0C≥λ≥0C≥λ≥0的条件
通过上一步可得到λ2=λ2old+y2∗(E1−E2)x1.x1+x2.x2−2x1.x2λ2 = λ_{2old}+\frac{y2*(E1-E2)}{x1.x1+x2.x2-2x1.x2}λ2=λ2old+x1.x1+x2.x2−2x1.x2y2∗(E1−E2)
因此可先判断0≤λ2≤C0≤λ2≤C0≤λ2≤C ————①
接着判断λ1,由C≥λ1=−λ2y1y2−Ay1≥0C≥λ_1 = -λ_2y_1y_2-Ay_1≥0C≥λ1=−λ2y1y2−Ay1≥0可得
- 当y1y2=1时:C≥−λ2−Ay1≥0当y1y2 = 1时:C≥ -λ_2-Ay_1≥0当y1y2=1时:C≥−λ2−Ay1≥0
- C+Ay1≤λ2≤−Ay1C+Ay_1≤λ_2≤-Ay_1C+Ay1≤λ2≤−Ay1 结合上式①得λ2最终的取值范围:
- max(0,C+Ay1)≤λ2≤min(C,−Ay1)max(0,C+Ay_1)≤λ_2≤min(C,-Ay_1)max(0,C+Ay1)≤λ2≤min(C,−Ay1)
- 简化为L≤λ2≤HL≤λ_2≤HL≤λ2≤H
- 当y1y2=−1时:C+Ay1≥λ2≥Ay1当y1y2 = -1时:C+Ay_1≥λ2≥Ay_1当y1y2=−1时:C+Ay1≥λ2≥Ay1 ——————②
- 结合上式①得λ2最终的取值范围:
- max(0,Ay1)≤λ2≤min(C,C+Ay1)max(0,Ay_1)≤λ_2≤min(C,C+Ay_1)max(0,Ay1)≤λ2≤min(C,C+Ay1)
- 简化为L≤λ2≤HL≤λ_2≤HL≤λ2≤H
- 如果满足L≤λ2≤HL≤λ_2≤HL≤λ2≤H,则继续往下
- 如果不满足条件,则直接剪枝后,再继续往下
- 当λ2>H时,使λ2=H
- 当λ2<L时,使λ2=L
④计算当前的Wnew,bnewW_{new},b_{new}Wnew,bnew
计算出满足λ≥0的λ1和λ2后,可代入求解最新的WnewW_{new}Wnew
Wold=λ1oldy1x1+λ2oldy2x2+∑i=3nλiyixiW_{old} = λ_{1old}y_1x_1+λ_{2old}y_2x_2+∑^n_{i=3}λ_iy_ix_iWold=λ1oldy1x1+λ2oldy2x2+∑i=3nλiyixi
Wnew=λ1y1x1+λ2y2x2+∑i=3nλiyixiW_{new} = λ_{1}y_1x_1+λ_{2}y_2x_2+∑^n_{i=3}λ_iy_ix_iWnew=λ1y1x1+λ2y2x2+∑i=3nλiyixi
则Wnew=Wold+(λ1−λ1old)y1x1+(λ2−λ2old)y2x2W_{new} = W_{old}+(λ_{1}-λ_{1old})y_1x_1+(λ_{2}-λ_{2old})y_2x_2Wnew=Wold+(λ1−λ1old)y1x1+(λ2−λ2old)y2x2
可见,每次W的更新,都只与选择的两个λ有关
bnewb_{new}bnew,表示两条边界上的b1和b2的中间值
怎么判断是不是边界呢?
其实也就是当λ>0的时候,因此λ>0,则g(w,b)=0,这在之前的拉格朗日乘数法中已证明为支持向量,即边界
因此,则当λ1、λ2均大于0且小于C时,根据 g(w,b)=1−ξi−yi(Wnewxi+b)=0g(w,b) = 1-ξ_i-y_i(W_{new}x_i+b) = 0g(w,b)=1−ξi−yi(Wnewxi+b)=0
要求松弛变量ξiξ_iξi同时为0,则βi>0β_i>0βi>0,即C−λi>0C-λ_i>0C−λi>0
综合得 当 0<λ<C时,该数据为支持向量上的边界点,则可以求出b
求出
b1new=y1−Wnewx1b_{1new}= y_1-W_{new}x_1b1new=y1−Wnewx1
b2new=y2−Wnewx2b_{2new}= y_2-W_{new}x_2b2new=y2−Wnewx2
则bnew=b1new+b2new2b_{new} = \frac{b_{1new}+b_{2new}}{2}bnew=2b1new+b2new
⑤若全部满足KKT条件,或达到迭代次数,则停止SMO算法
增加软间隔后的分类速度其实很快,而且准确率相对高一点点儿
代码改动量不大,主要只需要改动的是计算出新的λ时,要进行判断和剪枝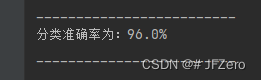
import numpy as np
import pandas as pd
import random
import matplotlib.pyplot as plt
import time
# 获取所需数据:
datas = pd.read_excel('./datas6.xlsx')
important_features = ['推荐分值','专业度','推荐类型']
# datas = pd.read_excel('./datas5.xlsx')
# important_features = ['推荐分值','推荐类型']
datas_1 = datas[important_features].head(100)
Y = datas_1['推荐类型']
X = datas_1.drop('推荐类型',axis=1)
X_features = X.columns
Y_features = '推荐类型'
rows,columns = datas_1.shape
Y=Y.where(Y!="高推荐",other=1) # 高推荐设置为1
Y=Y.where(Y!="低推荐",other=-1) # 低推荐设置为-1
class SMO():
def __init__(self,X,Y):
self.X = X
self.Y = Y
self.C = 1
self.m = X.shape[1]
self.n = Y.shape[0]
self.lamb = np.zeros(self.n)
self.β = self.C-self.lamb
self.b = 0
self.W0 = np.zeros(self.m)
self.times = 5
self.Finish = False
self.break_kkt = {}
self.break_kkt_list = []
self.E = None
def count_break_KKT(self):
del self.break_kkt
self.break_kkt = {}
self.g = 1-self.Y*((self.W0*self.X).sum(axis=1)+self.b)
# time.sleep(3)
for index,g_value in self.g.items():
a = self.lamb[index]
if a < 0:
raise Exception(f"lamb1_new为{self.lamb1_new},还是小于0")
elif a == 0 and g_value>0:
self.break_kkt[index] = abs(g_value)
elif a > 0 and g_value!=0:
self.break_kkt[index] = abs(g_value)
def run(self):
select_lamb1 = False
while not self.Finish and self.times>0:
if len(self.break_kkt_list) == 0:
self.count_break_KKT()
self.break_kkt_list = sorted(self.break_kkt.items(), key=lambda d: d[1], reverse=True)
if len(self.break_kkt_list) == 0:
print("已全部满足KKT")
break
# print(f"当前违反KKT条件的:{self.break_kkt_list}")
# time.sleep(3)
index1 = self.break_kkt_list.pop(0)[0]
x1 = self.X.iloc[index1]
y1 = self.Y[index1]
lamb1_old = self.lamb[index1]
self.E = (self.W0 * self.X).sum(axis=1) + self.b - self.Y
e1 = self.E[index1]
self.E1E2_all = e1-self.E
self.E1E2_abs = (e1-self.E).abs()
self.E1E2_sort = sorted(self.E1E2_abs.items(), key=lambda d: d[1], reverse=True)
# print(f"当前的E1E2排序:{self.E1E2_sort}")
# time.sleep(3)
self.times -= 1
for j in self.E1E2_sort:
index2 = j[0]
x2 = self.X.iloc[index2]
y2 = self.Y[index2]
lamb2_old = self.lamb[index2]
e1_e2 = self.E1E2_all[index2]
# print(f"选中的第{index1}和第{index2}的E差值为{e1_e2},参数:{self.lamb[index1], self.lamb[index2]}")
# time.sleep(3)
if e1_e2 == 0:
# print(f"由于两者的E差值为0,因此不进行迭代")
select_lamb1 = True
break
temp = sum(x1*x1+x2*x2-2*x1*x2)
A = -lamb1_old*y1-lamb2_old*y2
if temp==0:
continue
lamb2_new = lamb2_old + e1_e2*y2/temp
if y1*y2 == 1:
L = max(0,-self.C-A*y1,)
H = min(self.C,-A*y1)
if lamb2_new<L:
lamb2_new = L
elif lamb2_new>H:
lamb2_new = H
elif lamb2_new<H and lamb2_new>L:
pass
else:
print("怎么H还比L小呢")
self.Finish = True
break
elif y1*y2 == -1:
L = max(0,A*y1)
H = min(self.C,self.C+A*y1)
if lamb2_new<L:
lamb2_new = L
elif lamb2_new>H:
lamb2_new = H
elif lamb2_new<H and lamb2_new>L:
pass
else:
print("怎么H还比L小呢")
self.Finish = True
break
lamb1_new = -lamb2_new*y1*y2-A*y1
time.sleep(3)
self.W0 = self.W0+(lamb1_new-lamb1_old)*y1*x1+(lamb2_new-lamb2_old)*y2*x2
self.W0 = np.array(self.W0)
if 0<lamb1_new and lamb1_new<self.C:
b1_new = y1-sum(self.W0*x1)
if 0 < lamb2_new and lamb2_new < self.C:
b2_new = y2-sum(self.W0*x2)
self.b = np.array((b1_new+b2_new)/2)
self.lamb[index1]=lamb1_new
self.lamb[index2]=lamb2_new
self.β[index1]=self.C-lamb1_new
self.β[index2]=self.C-lamb2_new
print(f"新的lamb:{self.lamb},\nW0为{self.W0},b为{self.b}")
select_lamb1 = True
break
else:
print(f"可选的E2中:{self.E1E2_sort},没有满足条件的lamb2")
if select_lamb1:
select_lamb1 = False
self.count_break_KKT()
self.break_kkt_list = sorted(self.break_kkt.items(), key=lambda d: d[1], reverse=True)
if len(self.break_kkt_list)==0:
self.Finish = True
print("已全部服从KKT条件")
sum_lamb_y = sum(self.lamb*self.Y)
print(f"汇总后的值是否为零:{sum_lamb_y}")
print(self.lamb)
break
lambs = sorted([(index1,value1) for index1,value1 in enumerate(self.lamb)],key=lambda x:x[1],reverse=True)
index1 = lambs.pop(0)[0]
for index2,value2 in enumerate(lambs):
if self.Y[index1]!=self.Y[index2] and value2!=0:
print("++++++++++++++++++++++++++++++++++++")
x1 = self.X.iloc[index1]
x2 = self.X.iloc[index2]
print(self.W0*x1)
print((self.W0*x1).sum(axis=0))
b1_new = np.array(self.Y[index1]-(self.W0*x1).sum(axis=0))
b2_new = np.array(self.Y[index2]-(self.W0*x2).sum(axis=0))
b_new = (b1_new+b2_new)/2
self.b = b_new
print("++++++++++++++++++++++++++++++++++++")
break
print(b1_new,b2_new)
self.W0 = np.array([self.W0])
print("_________________________")
print(self.W0)
print(self.X)
print(self.b)
print("_________________________")
z = (self.W0*self.X).sum(axis=1)+self.b
self.Y_pre = []
for i in z:
if i>=0:
self.Y_pre.append(1)
elif i<0:
self.Y_pre.append(-1)
else:
print("居然还有点位于支持向量中间的点,big problem")
print(f"分类准确率为:{round(sum(self.Y_pre==self.Y)/self.Y.shape[0]*100,2)}%")
print("_________________________")
z = (self.W0*self.X).sum(axis=1)+self.b
# z1 = (self.W0 * self.X).sum(axis=1) + b1_new
# z2 = (self.W0 * self.X).sum(axis=1) + b2_new
map_color = {-1: 'r', 1: 'g'}
color = list(map(lambda x: map_color[x], self.Y))
plt.scatter(np.array(z), np.array(self.Y),c=color)
plt.show()
test = SMO(X,Y)
test.run()

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 5
5 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)