
深度学习之图像分类(七)--ResNet网络结构
深度学习之图像分类(七)ResNet 网络与 Batch Normalization目录深度学习之图像分类(七)ResNet 网络与 Batch Normalization1. 前言2. Residual3. 网络配置4. 代码本节学习ResNet网络结构,以及迁移学习入门,学习视频源于 Bilibili。1. 前言ResNet 是在 2015 年由微软实验室提出来的,斩获当年 ImageNet
深度学习之图像分类(七)ResNet 网络结构
本节学习ResNet网络结构,以及迁移学习入门,学习视频源于 Bilibili,感谢霹雳吧啦Wz,建议大家去看视频学习哦。

1. 前言
ResNet 是在 2015 年由微软实验室提出来的,斩获当年 ImageNet 竞赛中分类任务第一名,目标检测任务第一名,获得 COCO 数据集中目标检测第一名,图像分割第一名。总结而言就是 NB!更 NB 的是,这是中国人提出来的!原始论文为:Deep Residual Learning for Image Recognition。
网络越深,咱们能获取的信息越多,而且特征也越丰富。按理说,网络越来越深,至少能达到浅网络的性能,为什么呢?因为后面全部学习恒等映射就可以了呀。网络加深,不是想加就加的;恒等映射,不是说学就能学的。
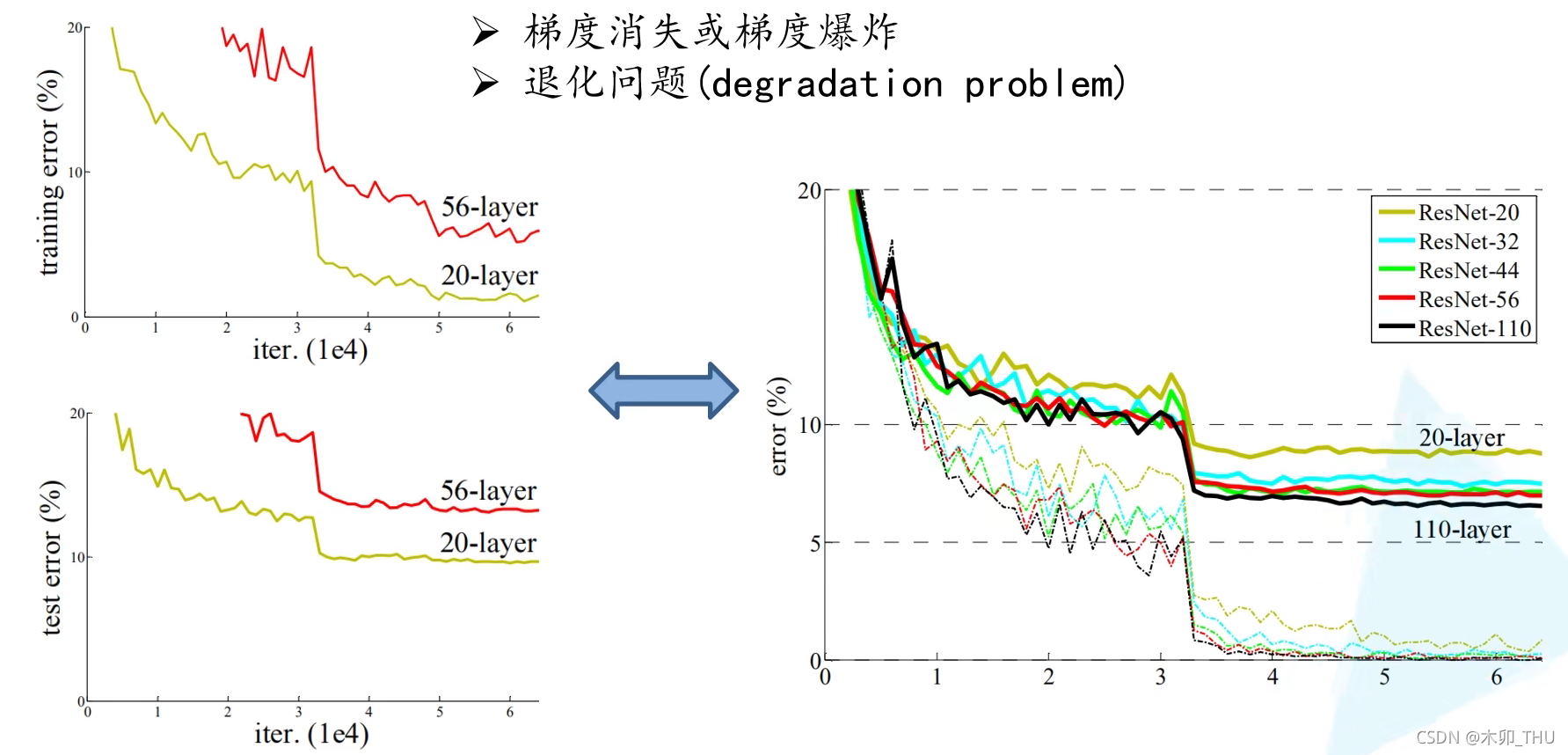
但是根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。**这是由于网络的加深会造成梯度爆炸和梯度消失的问题。**目前针对这种现象已经有了解决的方法:通常是通过对数据进行标准化处理,权重初始化,以及 Batch Normalization 来处理的,这种方法可以保证网络在反向传播中采用随机梯度下降(SGD),从而让网络达到收敛。但是,这个方法仅对几十层的网络有用,当网络再往深处走的时候,这种方法就无用武之地了。并且退化问题(degradation problem,层数深的效果没有浅的好,下图左边部分 )严重。下图中实线是验证集,虚线是训练集。右图中 ResNet 层数越深,错误率越低,确实解决了退化问题。
网络亮点在于:
- 超级深的网络结构(突破了 1000 层)
- 提出 Residual 模块(搭建深网络的基础,学恒等不如学习0变换)
- 使用 Batch Normalization 加速训练,丢弃了 Dropout
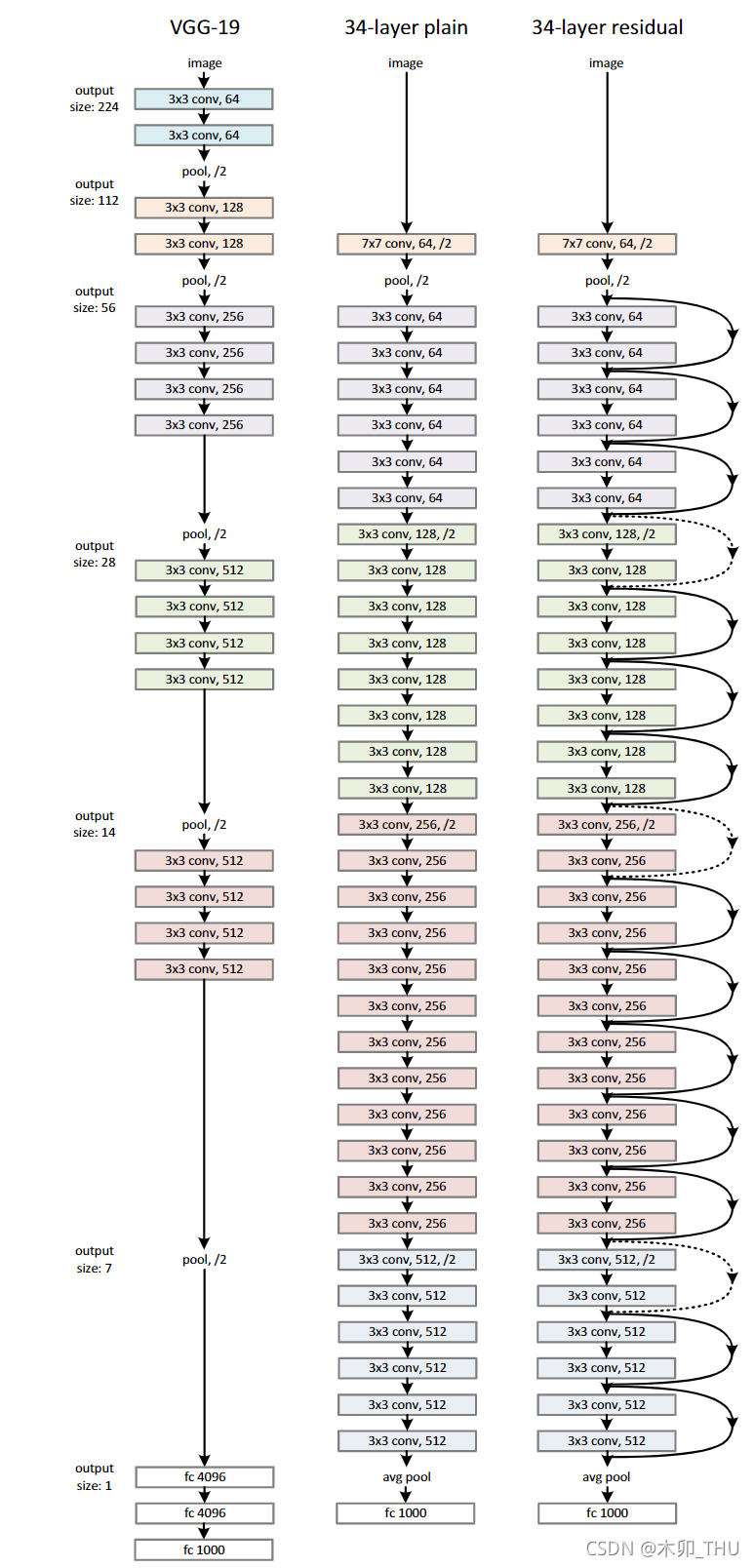
ResNet34 网络结构如下所示(conv_3, conv_4, conv_5 的第一个残差结构,虚线的残差结构需要注意):
2. Residual
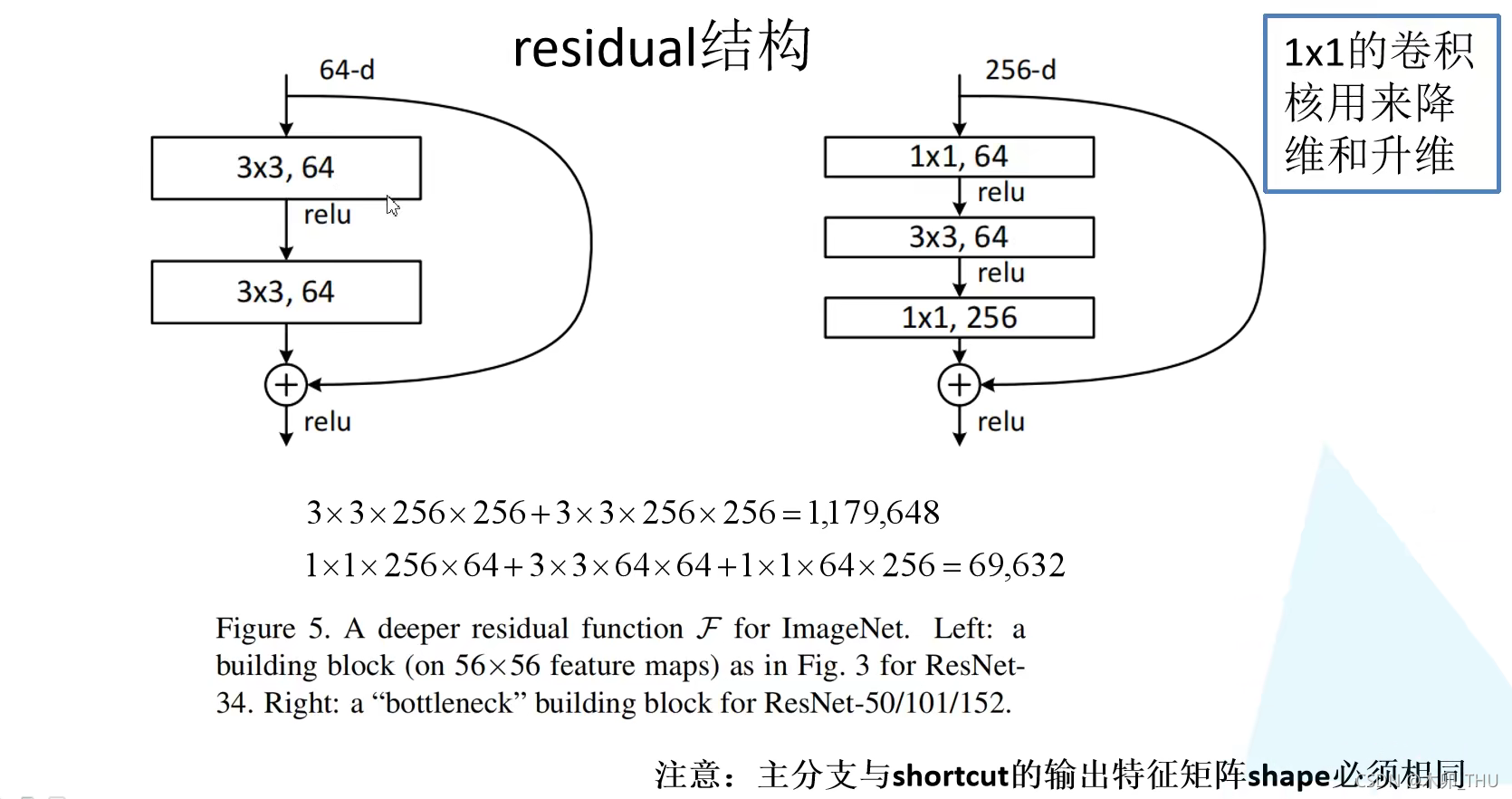
Residual 可以把它理解为一个子网络,这个子网络经过堆叠可以构成一个很深的网络。下图给出了两种残差结构。左边的主要针对网络层数较少的网络;右边主要针对网络层数较多的网络。左边结构中,主线是将输入特征矩阵经过两个 3 × 3 3 \times 3 3×3 的卷积层,右边有一个弧线直接从输入连接到输出,与卷积后的特征矩阵按元素相加得到最终特征矩阵结果。右边的结构的主分支则是在输入与输出都加上了 1 × 1 1 \times 1 1×1 的卷积层,用来实现降维和升维。右边的参数节省了 94%。
注意:加了之后再经过 ReLU 激活函数。
注意:主分支与 shortcut 分支的输出特征矩阵的 shape 必须一致才能进行元素加法。回顾,GoogleNet 是在深度方向进行拼接。
a [ l + 2 ] = R e l u ( W [ l + 2 ] ( R e l u ( W [ l + 1 ] a [ l ] + b [ l + 1 ] ) ) + b [ l + 2 ] + a [ l ] ) a^{[l+2]} = Relu(W^{[l+2]}(Relu(W^{[l+1]}a^{[l]} + b^{[l+1]})) + b^{[l+2]} + a^{[l]}) a[l+2]=Relu(W[l+2](Relu(W[l+1]a[l]+b[l+1]))+b[l+2]+a[l])
其中 b b b 为卷积层偏置 bias。
如何理解 Residual 呢?
假设我们要求解的映射为: H ( x ) H(x) H(x)。现在咱们将这个问题转换为求解网络的残差映射函数,也就是 F ( x ) F(x) F(x),其中 F ( x ) = H ( x ) − x F(x) = H(x)-x F(x)=H(x)−x。残差即观测值与估计值之间的差。这里 H ( x ) H(x) H(x) 就是观测值, x x x 就是估计值(也就是上一层Residual 输出的特征映射)。我们一般称 x x x 为 Identity Function(恒等变换),它是一个跳跃连接;称 F ( x ) F(x) F(x) 为 Residual Function。
那么我们要求解的问题变成了 H ( x ) = F ( x ) + x H(x) = F(x)+x H(x)=F(x)+x。有小伙伴可能会疑惑,我们干嘛非要经过 F ( x ) F(x) F(x) 之后在求解 H ( x ) H(x) H(x) 啊!整这么麻烦干嘛,直接搞不好吗,神经网络那么强(三层全连接可以拟合任何函数)!我们来分析分析:如果是采用一般的卷积神经网络的话,原先我们要求解的是 H ( x ) = F ( x ) H(x) = F(x) H(x)=F(x) 这个值对不?那么,我们现在假设,在我的网络达到某一个深度的时候,咱们的网络已经达到最优状态了,也就是说,此时的错误率是最低的时候,再往下加深网络的化就会出现退化问题(错误率上升的问题)。我们现在要更新下一层网络的权值就会变得很麻烦,权值得是一个让下一层网络同样也是最优状态才行,对吧?我们假设输入输出特征尺寸不变,那么下一层最优的状态就是学习一个恒等映射,不改变输入特征是最好的,这样后续的计算会保持,错误了就和浅一层一样了。但是这是很难的,试想一下,给你个 3 × 3 3 \times 3 3×3 卷积,数学上推导出来恒等映射的卷积核参数有一个,那就是中间为 1,其余为 0。但是它不是想学就能学出来的,特别是初始化权重离得远时。
但是采用残差网络就能很好的解决这个问题。还是假设当前网络的深度能够使得错误率最低,如果继续增加咱们的 ResNet,为了保证下一层的网络状态仍然是最优状态,咱们只需要把令 F ( x ) = 0 F(x)=0 F(x)=0 就好啦!因为 x x x 是当前输出的最优解,为了让它成为下一层的最优解也就是希望咱们的输出 H ( x ) = x H(x)=x H(x)=x 的话,是不是只要让 F ( x ) = 0 F(x)=0 F(x)=0 就行了?这个太方便了,只要卷积核参数都足够小,乘法加法之后就是 0 呀。当然上面提到的只是理想情况,咱们在真实测试的时候 x x x 肯定是很难达到最优的,但是总会有那么一个时刻它能够无限接近最优解。采用 Residual 的话,也只用小小的更新 F ( x ) F(x) F(x) 部分的权重值就行啦!不用像一般的卷积层一样大动干戈!
注意:如果残差映射( F ( x ) F(x) F(x))的结果的维度与跳跃连接( x x x)的维度不同,那咱们是没有办法对它们两个进行相加操作的,必须对 x x x进行升维操作,让他俩的维度相同时才能计算。升维的方法有两种:
- 全 0 填充
- 采用 1 × 1 1 \times 1 1×1 卷积
3. 网络配置
下图给出了不同 ResNet 的配置图。
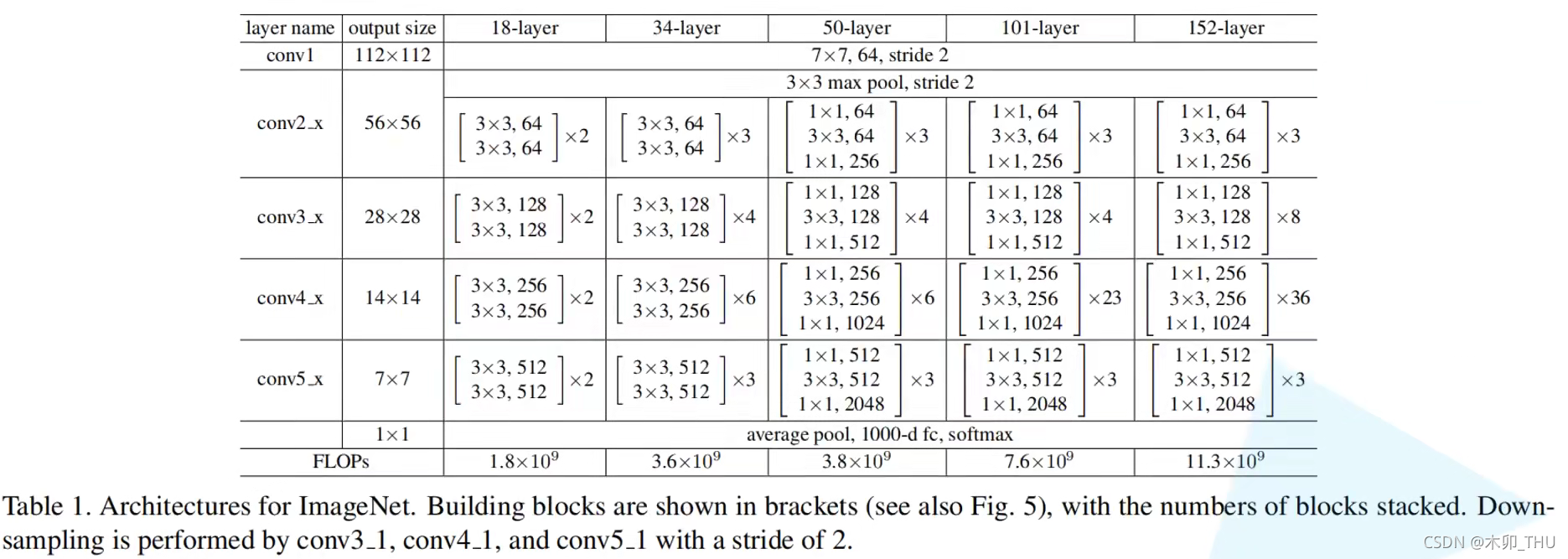
对于需要进行下采样的残差结构(conv_3, conv_4, conv_5 的第一个残差结构),论文使用如下形式(原论文有多个形式,我们这里说的是最后作者选择的形式),主线部分 3 × 3 3 \times 3 3×3 的卷积层使用 stride = 2,实现下采样;虚线部分的 1 × 1 1 \times 1 1×1 卷积且 stride = 2:
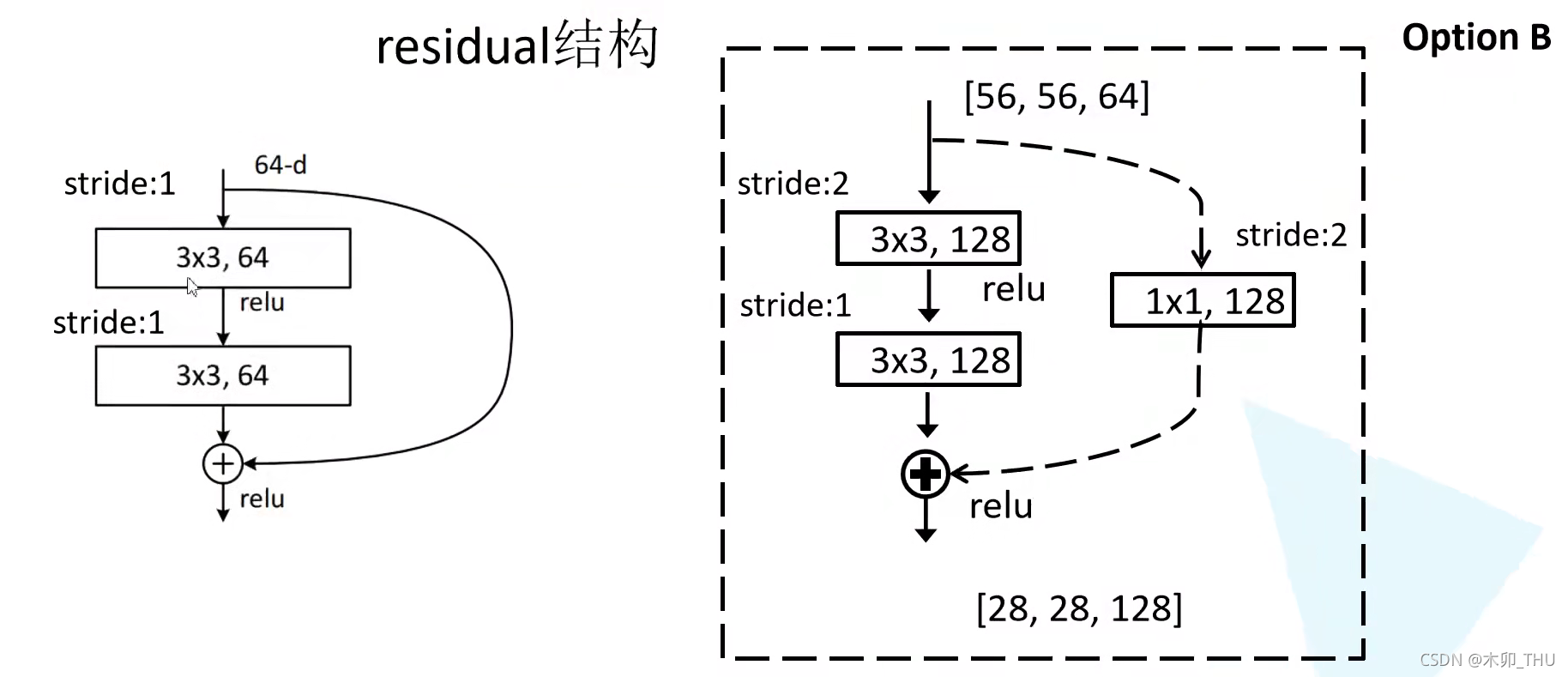
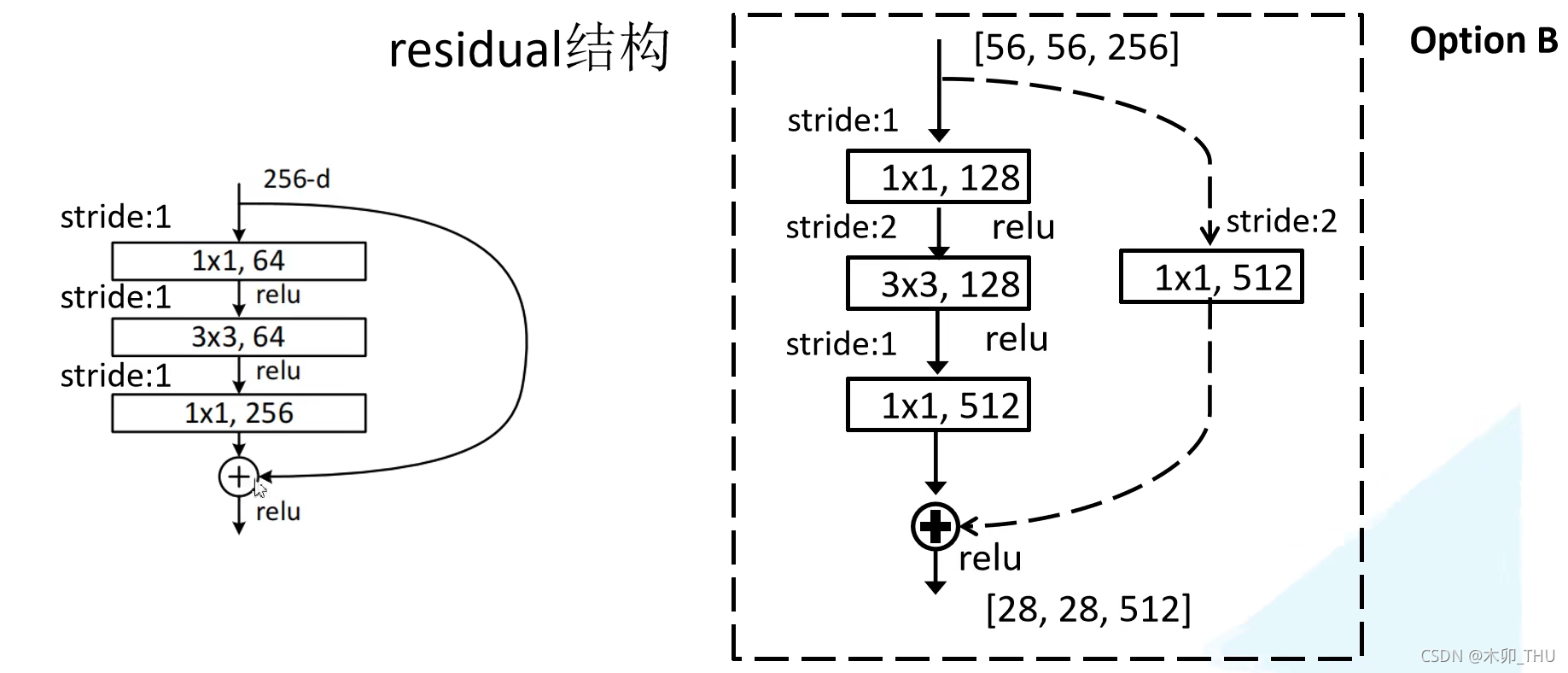
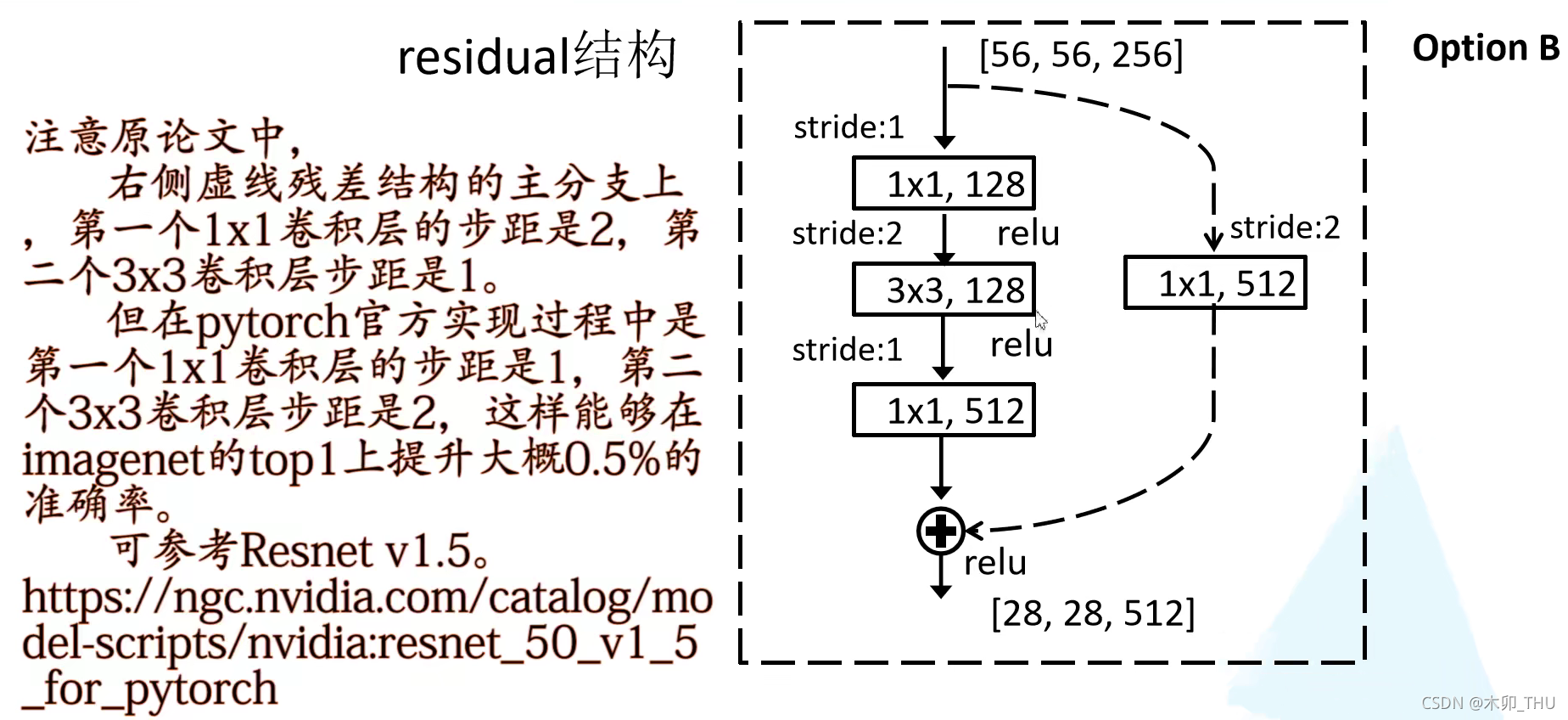
值得注意的是,pytorch 官方实现和原始论文有些许不同:
注意一些细节:对于 conv_2 一开始,在 Resnet18 和 ResNet34 得到的就是期望的 [56, 56, 64] 的输入;但是对于 ResNet50,ResNet101 和 ResNet152 而言,通过最大池化后得到的输出 shape 是 [56, 56, 64] ,而实线残差结构所需要的输入 shape 是 [56, 56, 256] ,所以 conv_2 对应的第一个也是虚线残差层,仅旁路只调整特征矩阵的深度,高和宽都不变。
通常我们都使用 ImageNet 的预训练参数(迁移学习),能够快速训练出一个理想的模型,尽管在小数据集下也能训练一个好的模型。注意使用别人预训练模型参数时,要注意别人的预处理方式,例如 ImageNet 的常见正则化为:
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
迁移学习大白文理解如下所示,假设网络训练完成之后,网络第一个卷积层可能学到了角点信息,第二个卷积层可能学会了分析纹理,再到后来的卷积层学到了如何识别部件。全连接层基于这些信息学会如何分类目标类别。通常浅层的卷积操作是通用的,所以可以直接使用用于初始化。
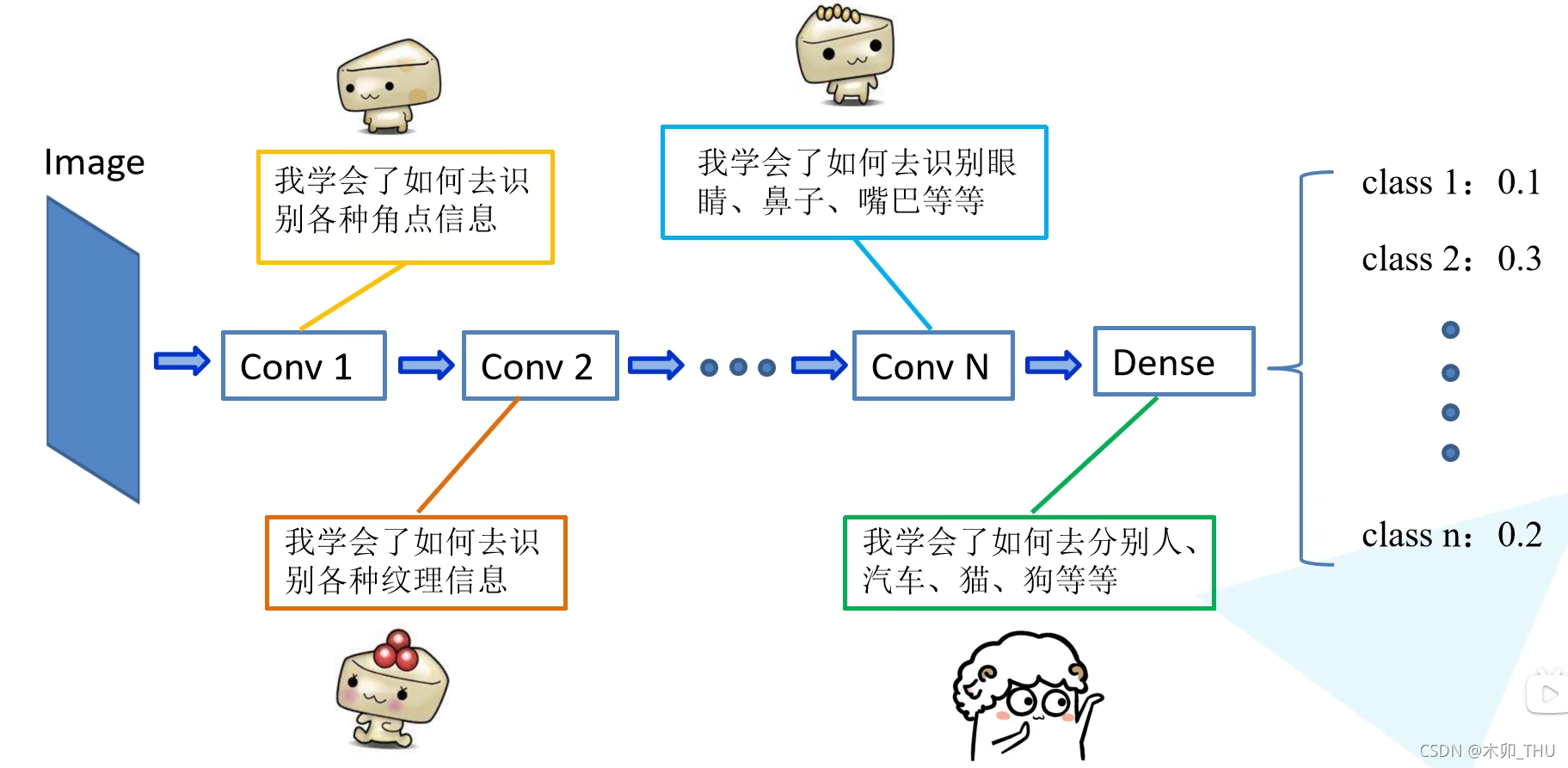
常见的迁移学习方式包括:
- 载入权重后训练所有参数
- 载入权重后只训练最后几层参数
- 在数权重后在原有网络基础上再加一层全连接,仅训练最后一个全连接层
4. 代码
ResNet 实现代码如下所示:
import torch.nn as nn
import torch
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnext50_32x4d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
# load ImageNet pretrain parameter
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
my_output_channel = 5
# load pretrain weights
# download url: https://download.pytorch.org/models/resnet34-333f7ec4.pth
model_weight_path = "./resnet34-pre.pth"
assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)
# option1
net = resnet34()
net.load_state_dict(torch.load(model_weight_path, map_location=device))
# change fc layer structure
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, my_output_channel)
# option2
# net = resnet34(num_classes=my_output_channel)
# pre_weights = torch.load(model_weight_path, map_location=device)
# del_key = []
# for key, _ in pre_weights.items():
# if "fc" in key:
# del_key.append(key)
#
# for key in del_key:
# del pre_weights[key]
#
# missing_keys, unexpected_keys = net.load_state_dict(pre_weights, strict=False)
# print("[missing_keys]:", *missing_keys, sep="\n")
# print("[unexpected_keys]:", *unexpected_keys, sep="\n")

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 7
7 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)