
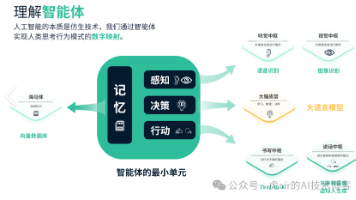
如何用AI大模型打造三位一体的智能翻译神器?
在实现翻译智能体时怎么提升翻译质量呢?这跟传统行业一样,需要有译审校对的工作,即在Agent内有多个角色协同工作,达成翻译任务。我在Coze平台把整个过程实现了一遍,有兴趣的朋友可以跟着教程试一下。
在实现翻译智能体时怎么提升翻译质量呢?这跟传统行业一样,需要有译审校对的工作,即在Agent内有多个角色协同工作,达成翻译任务。
我在Coze平台把整个过程实现了一遍,有兴趣的朋友可以跟着教程试一下。

创建智能体
在扣子(Coze)平台,创建智能体,因为逻辑都会在工作流里实现,所以选择“单Agent(工作流模式)”。

点击创建工作流后,初始化的工作流只有开始与结束2个节点。

自动识别翻译需求(代码)
我准备实现的是中英相互翻译,所以需增加一小段代码识别用户输入是中文为主还是英文为主?如果是中文为主,就自动判断为中文翻译为英文,反之就识别为英文翻译中文。
点击“代码”,添加一个代码节点,引用开始中的变量BOT_USER_INPUT,输出定义2个变量source_lang、target_lang,即为代码识别出用户需求的结论。

我这选择python语言,代码编写可以尝试使用AI实现,把需求描述后,AI会自动生成代码。

可能需要优化调整一下AI生成的代码,点击测试按钮,验证代码功能是否正确。

代码参考如下:
async def main(args: Args) -> Output:
params = args.params
text = params['input']
# 初始化计数器
chinese_count = 0
english_count = 0
# 遍历文本中的每个字符
for char in text:
# 判断是否为英文字母
if 'a' <= char.lower() <= 'z': # 使用lower()简化大小写判断
english_count += 1
if english_count > 1000:
return {'source_lang': '英文', 'target_lang': '中文'}
# 判断是否为中文字符
elif '\u4e00' <= char <= '\u9fff':
chinese_count += 1
if chinese_count > 1000:
return {'source_lang': '中文', 'target_lang': '英文'}
# 根据字符数量判断语言并构建返回字典
if chinese_count > english_count:
return {'source_lang': '中文', 'target_lang': '英文'}
elif english_count >= chinese_count and english_count > 7: # 英文至少有一定数量
return {'source_lang': '英文', 'target_lang': '中文'}
else:
return {'source_lang': 'Mixed or Unclear', 'target_lang': '中文'}添加翻译者(翻译草稿)
翻译者负责将源语言文本转换为目标语言的初步翻译,并生成初步的翻译草稿。
添加“大模型”节点,我这选择“豆包”模型,然后是定义输入,定义系统提示词及用户提示词。

翻译者提示词参考:
# 系统提示词
您是一位专业翻译,专注于{{source_text}} 翻译成 {{target_lang}}。
# 用户提示词
您的任务是将以下文本:{{source_text}} 从 {{source_lang}} 翻译为 {{target_lang}}。请仅输出翻译内容,无需附加其他信息。图片路径不需要翻译。输出格式为 Markdown。添加语言专家(反思)
语言专家在翻译者的基础上工作,专注于优化翻译的语言风格和流畅度。这包括调整语法、词汇选择和表达方式,以使翻译更贴近目标语言的自然表达习惯。
添加“大模型”实现语言专家,把新添加节点与翻译者节点连接起来,后续操作和添加翻译者是一样的。

语言专家提示词参考:
# 系统提示词
您是一位语言专家,专注于从 {{source_lang}} 翻译到 {{target_lang}}。您将获得源文本及其翻译,您的目标是改进翻译内容。
# 用户提示词
您的任务是仔细阅读从 {{source_lang}} 翻译到 {{target_lang}} 的源文本和翻译,然后提供建设性的批评和有用的建议,以改善翻译。
翻译的最终风格和语气应符合在{{target_lang}}口语中使用的{{target_lang}} 的风格。
源文本和翻译如下:
<SOURCE_TEXT>
{{source_text}}
</SOURCE_TEXT>
<TRANSLATION>
{{translation}}
</TRANSLATION>
在写建议时,请注意是否有改善翻译的方式:
(i) 准确性(通过纠正添加、误译、遗漏或未翻译文本的错误),
(ii) 流畅性(通过应用 {{target_lang}} 的语法、拼写和标点规则,确保没有不必要的重复),
(iii) 风格(确保翻译反映源文本的风格,并考虑任何文化背景),
(iv) 术语(确保术语使用的一致性,反映源文本的领域;并仅使用与 {{target_lang}} 等价的习语)。
写出一系列具体、有帮助和建设性的建议,以改进翻译。
每个建议应针对翻译的一个具体部分。
只输出建议,不加入任何额外的解释内容。
输出格式为 Markdown。测试验证,从输出结果看,语言专家还是非常专业的。

译审专家(把控翻译质量)
译审专家负责最终的质量控制,确保翻译的准确性、一致性和专业性。他将检查翻译是否忠实于原文,是否有语法错误,以及是否符合专业术语和行业标准。
最后添加“大模型”实现译审专家,与前面步骤类似。

译审专家提示词参考如下:
# 系统提示词
您是一位高级编辑,专注于从 {{source_lang}} 翻译到 {{target_lang}} 的后期编辑。您将获得源文本、初始翻译和建议,您的目标是改进翻译内容。
# 用户提示词
您的任务是仔细阅读并编辑从 {{source_lang}} 翻译到 {{target_lang}} 的翻译,同时考虑专家建议和建设性批评的列表。
源文本:
<SOURCE_TEXT>
{{source_text}} # 源文本内容
</SOURCE_TEXT>
初始翻译:
<INITIAL_TRANSLATION>
{{initial_translation}} # 初始翻译内容
</INITIAL_TRANSLATION>
改进建议:
<SUGGESTIONS>
{{reflection}} # 提供的反思或改善建议
</SUGGESTIONS>
请在编辑翻译时考虑专家建议。编辑翻译时请确保:
(i) 准确性(纠正添加、误翻、遗漏或未翻译文本的错误),
(ii) 流畅性(应用 {{target_lang}} 的语法、拼写和标点规则,确保没有不必要的重复),
(iii) 风格(确保翻译反映源文本的风格),
(iv) 术语(不适合上下文或使用不一致),
(v) 其他错误。
只输出新的翻译,不附加其他内容。
输出格式为Markdown。总结

整个实现过程是参考吴恩达老师发布的一个开源项目translation-agent,他提出了一种利用LLM进行自我反思并完善的自动化长文翻译智能体,并给出了简单的原型代码。
我这次实现完全在Coze平台是低代码方式地把这个过程实现一遍,其中使用3次大语言模型,让大语言模型扮演不同角色达成不同效果。后续可优化点是,如果遇到长文需要拆分为短文分批执行,从执行执行效率来说建议用代码实现。
精彩推荐
AI智能体实战|使用扣子Coze搭建AI智能体,看这一篇就够了(新手必读)

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)