
美国玩大模型那帮人:好几万卡集群+超级节点
(一)AI芯片挑战者入场?尽管A100已经是英伟达上几代的老产品了。而在国内知名互联网公司内部,很多人仍然排队等用。最近,谭老师我有个经历,某个大模型训练论坛刚结束,想到前排加演讲嘉宾微信。这时候,不知道是因为走得太慢,还是过道太窄,突然背后被人推了一把,那人抢先我一步与嘉宾交流。好家伙,这人是对科技,抱有多大的热情呢?仔细一听,嚯,推销GPU集群业务。当下,GPU的确是“黄金商机”,是该拿出如火

(一)AI芯片挑战者入场?
尽管A100已经是英伟达上几代的老产品了。
而在国内知名互联网公司内部,
很多人仍然排队等用。
最近,谭老师我有个经历,
某个大模型训练论坛刚结束,想到前排加演讲嘉宾微信。
这时候,不知道是因为走得太慢,还是过道太窄,
突然背后被人推了一把,那人抢先我一步与嘉宾交流。
好家伙,这人是对科技,抱有多大的热情呢?
仔细一听,嚯,推销GPU集群业务。
当下,GPU的确是“黄金商机”,
是该拿出如火的热情,谁挡道就把谁推开。
AI芯片的头号玩家当然是英伟达。
好消息是,伴随着老牌芯片厂商依次入场,变化的曙光似乎来了。
2023年12月,AMD拿出自家AI芯片MI300X 。
AMD硬件相当强大,被视为英伟达最有利的挑战者,
虽然,AMD在软件定制化优化方面还有很长的路要走。
2024年4月10日,英特尔入场了,
带来了AI芯片Gaudi 3。
你说突然袭击也好,正常出牌也罢。
两个重量级路标事件出现了。
这意味着:以前是其他厂商都不行,完全上不了牌桌。
现在是,挑战者完成了从0到1的过程,难能可贵。
略显遗憾的是,国产芯片厂商势单力薄。
不要灰心,仍有希望。
时光没有穿梭机,
英伟达上几代产品 A100 在设计之时,
也不可能考虑到大语言模型的种种需求。
这一代的需求,这一代应对。

(二)英伟达超级节点:一直往上堆
一位在美国大会上亲眼看到超级节点
GB200 NVL72
的读者告诉我,
他深受震撼。
这个大家伙可以说是近期最让部分硬件爱好者尖叫的产品了。
对于英伟达的玩法,我的总结是:
不要Scale out,而要Scale up。
这个押头韵的句子,很洋(装)气(B)。
于是,配上谭老师我的土味翻译:
不要往外堆(Scale out)
而是往上堆(Scale up)
重点来了,如何区别两种堆法?
“往外堆”在互联网大厂内部由来已久,
很有年头,
“往上堆”是英伟达玩AI一路摸索出来的。
曾几何时,
“往外堆”是互联网大厂最熟悉的打法。
我搞一堆普通的机器,
以超大规模并行的方式做大集群,
这种方式在“搜索推荐广告”计算领域,
行之有效,
有效的原因在于,
那时候计算密度没有那么高。
互联网公司搜推广是主流业务,
而搜推广计算中,真正密集计算量的部分少。
生成式AI大模型一手擎天,
可是,这属于稠密计算,
英伟达的“往上堆”,需要看下技术细节,
于是我和某国产AI芯片初创公司产品总监Winnie聊了聊,
作为历经Arm和阿里平头哥的芯片老兵,
我每次和她聊,收获都爆棚。
B200是把两个芯片拼在一起,
这两个芯片都是GPU。
GB200是三个芯片并在一起。
之所以用“拼”和“并”两个不同的词,
是因为技术上有差别,
封装工艺不同。
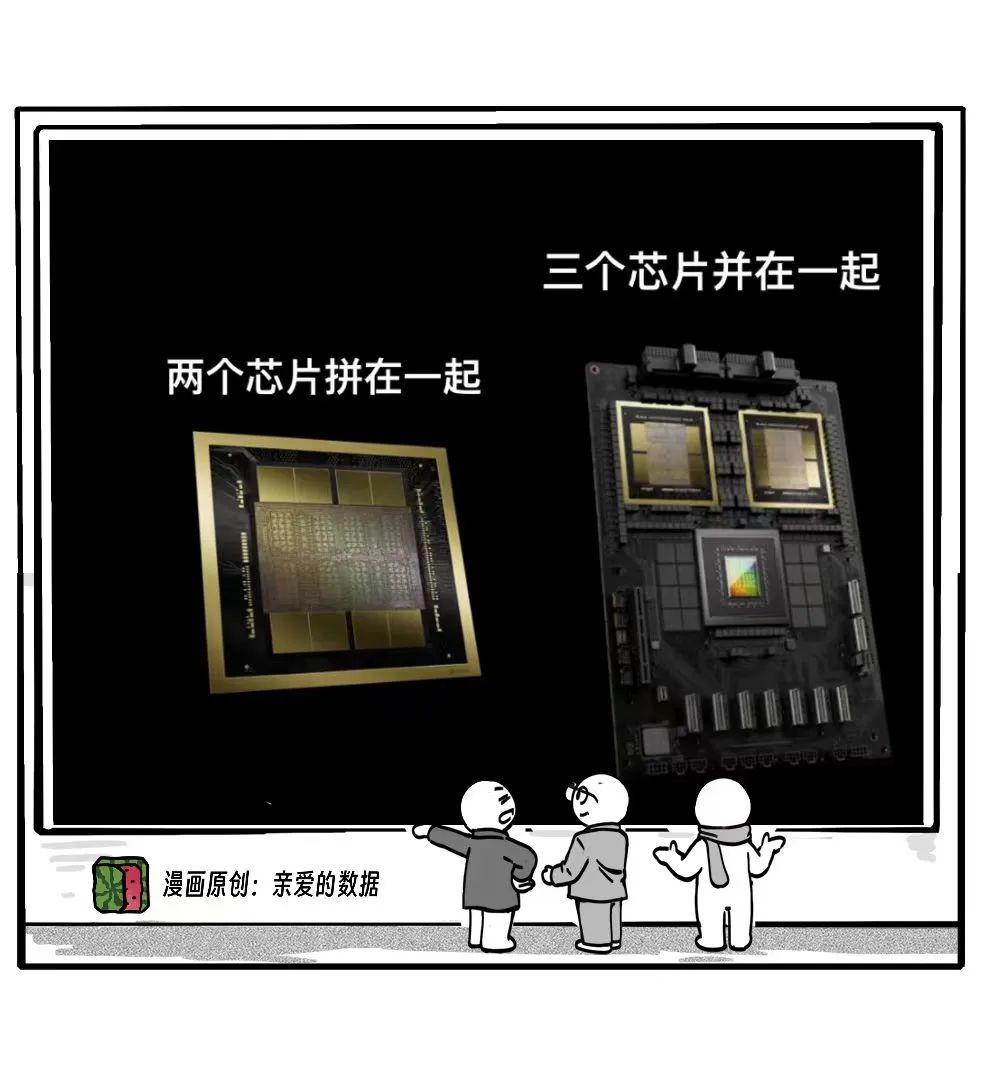
这三个芯片分别是,两个GPU,一个CPU;
CPU是英伟达自产的,名叫Grace。
这个G,就是GB200的第一个字母。
GB200是典型的,根据“往上堆”的思路设计的产品。
GB200 NVL72更是这个思路,
把72颗B200芯片全部连接起来。
关键是虽说有72个,但是工作起来像一个。
这真是汪峰的歌唱的,
这是飞一样的感觉。
用自己芯片的内存,和用另一个芯片的内存,
用的时候,没有感觉到跨芯片了。
官方有这样一句话:
rack-scale 72-GPU NVLink domain, that can act as a single
massive GPU
超级节点工作起来像一个巨大的GPU,
这个就是GB200 NVL72的灵魂。
怎么做到的?
当GB200系统里三个芯片全都是英伟达的芯片,
芯片之间用英伟达特有网络就更方便了。
芯片间通信在极致的拉高(Chip to Chip)。
再通过多个芯片互联构建一个更大规模的系统。
再用那种英伟达特有的网络把GPU互联,
从芯片到多芯片系统,从一台服务器到多服务器节点(Node)。
因为只要你往外堆,出了一定范围,就免不了外部通信。
既然“往上堆”,那就只要内部通信,不要外部通信。
当走“内部通信”,你虽然有72个GB200芯片,但是彼此之间的网络超快,
这样就能感觉不到内存之间的 “距离”。
甚至好几百个GPU也能以这种方式相联。
既然官方产品是NVL36和NVL72。
那么这种扩大规模的互联,
就是用“外部通信”链接,取36的倍数。
也就是说,以最小单元是36,翻倍互联。
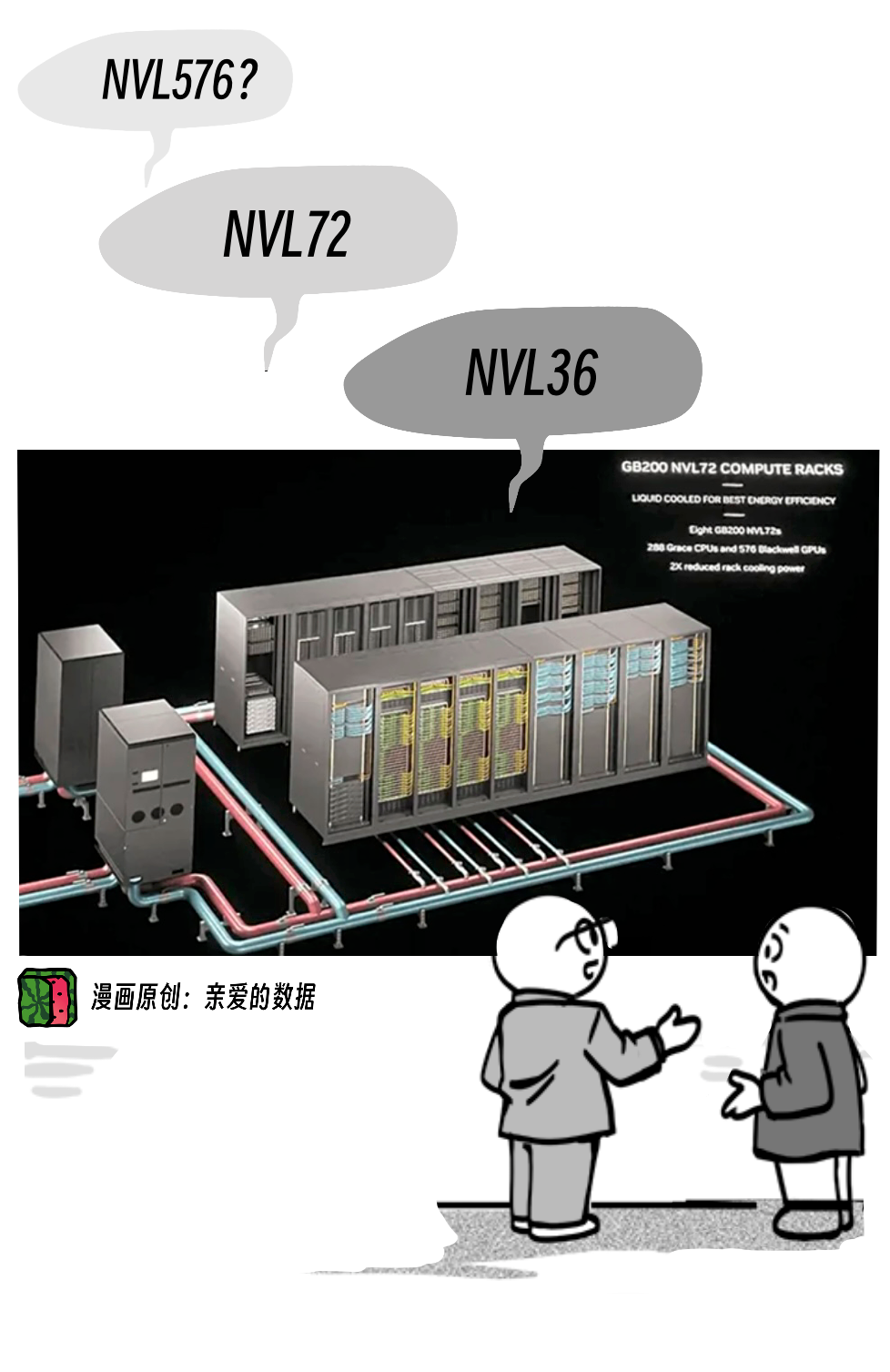
比如,照片中更有NVL576,
就是72 乘8(个机柜)。
576卡集群就要液冷方案了,
不过机柜间的链接已经算是“外部通信”了。
(英伟达公司官方没有NVL576,数字是从图片中数出来的。)
所以,打法非常明确,尽量走内网,而非外网。
一位原阿里云技术专家告诉我,
这是“通信局部性更强了”。
当超过这个局部区域的话,再跟外部相连的时候,
就只能走那种较慢的网络了,英伟达特有的网络用不了。
这样,那就降速。
在这种往上堆的过程中,精巧设计就来了。
就是三层级架构(Hierarchy),
用来管理通信和数据移动。
两种通信前面已经仔细介绍了,
第一,节点内通信,
第二,节点外通信。
第三,内存池(Memory pool)。
写到这里我也不由的感慨一句,2年前,
就有阿里云AIS(基础设施服务部)的朋友告诉我,
一定要留意GPU池化技术。
可惜,他后来跳槽到了字节跳动。
道理是,GPU虽然多,但它们会形成一个统一的,巨大的内存池。
这个池子为所有GPU提供了一个共享的内存空间。
看看这些设计,可真是变强的法宝。
这个内存池,讲的是一个统一内存编址的事儿。
你可以认为,内存是一个统一的地址。
统一内存编址允许所有处理器访问相同的内存空间。

这对上层软件的影响如何体现呢?
原阿里云计算平台事业部研究员,现任云器科技 CTO 关涛告诉我:
“一个数据库放在一个内存池,数据的取用都很方便。
当一个内存池放不下,分开多个,就带来了一堆分布式的难题。
不仅查询,排序的难度增加。
而且上层应用的开发都会非常吃力。”
数据库如此,大模型亦如此。
这些模型有着巨大的“中间计算结果”。
并且这些数据可能在多个GPU上。
那种8张GPU卡的AI服务器在训练模型的时候,
模型稍大些就放不下了。
服务器内存不足,
训练过程可能会遇到错误或失败。
所以,GPU内存小,大的模型训不了。
这时候,内存设计的越大越好。
放得下,就不用把模型拆开,分开放了。
可以看到:
一方面,英伟达把超级节点做得通信局部性更强了,
算力密度更高了。
AWS公司果断选择了NVL72来支持公有云计算服务。
美国那帮人把好几万GPU互联,
形成非常大的集群,
或者再拿超级节点来组集群。
这些可能是单节点计算能力不够的时下,最好的解决方案了。
没有什么更神奇的了。
换句话说, 难题摆在这里,没有神药。
那时下美国头部厂商的GPU集群有多大呢?
确切数字在文章开头表格里。
答案是:好几万卡。
(三)好几万卡集群

要知道,去年十月,
谭老师我还在写千卡技术多么酷炫。
如今,美国玩大模型的那帮人眼瞅着把玩好几万卡集群。
发展也太快了。
国内也有头部玩家在飙万卡集群,
虽然国内头部互联网厂商都拿的出万卡,但也不是只有大模型这一件事。
有的厂商,有双万卡。
英伟达万卡,华为昇腾910B也有万卡。
美团公司的大模型训练,则是万卡起步,原因是王慧文的光年之外被收购后,把卡都留给美团了。
公开信息中,字节跳动在学术论文中谈到用于训练大语言模型的生产系统MegaScale的情况,讲的是一件万卡级别进行千亿级别模型训练的事情。
另外,科大讯飞也大概率是万卡集群,
基础模型的迭代速度很快,没有足够大的集群,
不可能做到。
这类集群,成本以亿计算,不仅非常昂贵,
而且配套软件系统的架构也极其复杂,
优化对性能至关重要。
于是,难题摆在这里,
要有好的芯片,
但AI芯片并非孤立存在,
还要有好的AI基础软件团队来做优化。
硬件和软件协同奏响乐章。
既然如此重要,AI芯片和AI基础软件理应在AI浪潮中率先受益。
最后,国产AI芯片赶紧搞,
在线催,赶着用,挺急的。
(完)

《我看见了风暴:人工智能基建革命》,
作者:谭婧

更多阅读
长文系列
4. 假如你家大模型还是个二傻子,就不用像llya那样操心AI安全
6. 对话百度孙珂:想玩好AI Agent,大模型的“外挂”生意怎么做?
7. 再造一个英伟达?黄仁勋如何看待生物学与AI大模型的未来?
8. 科大讯飞刘聪:假如对大模型算法没把握,错一个东西,三个月就过去了
9.美国AI芯片公司“赢”大模型?Samba-CoE v0.2超过多个业界知名对手
漫画系列

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)