
自然语言处理基础-字符串处理、正则、结巴分词(关键词、停用词、词性分析)
nlp基础:字符串处理、正则表达式应用、结巴分词(中文分词、添加停用词、关键词提取、词性分析)
目录
一、字符串处理
1、空字符串处理
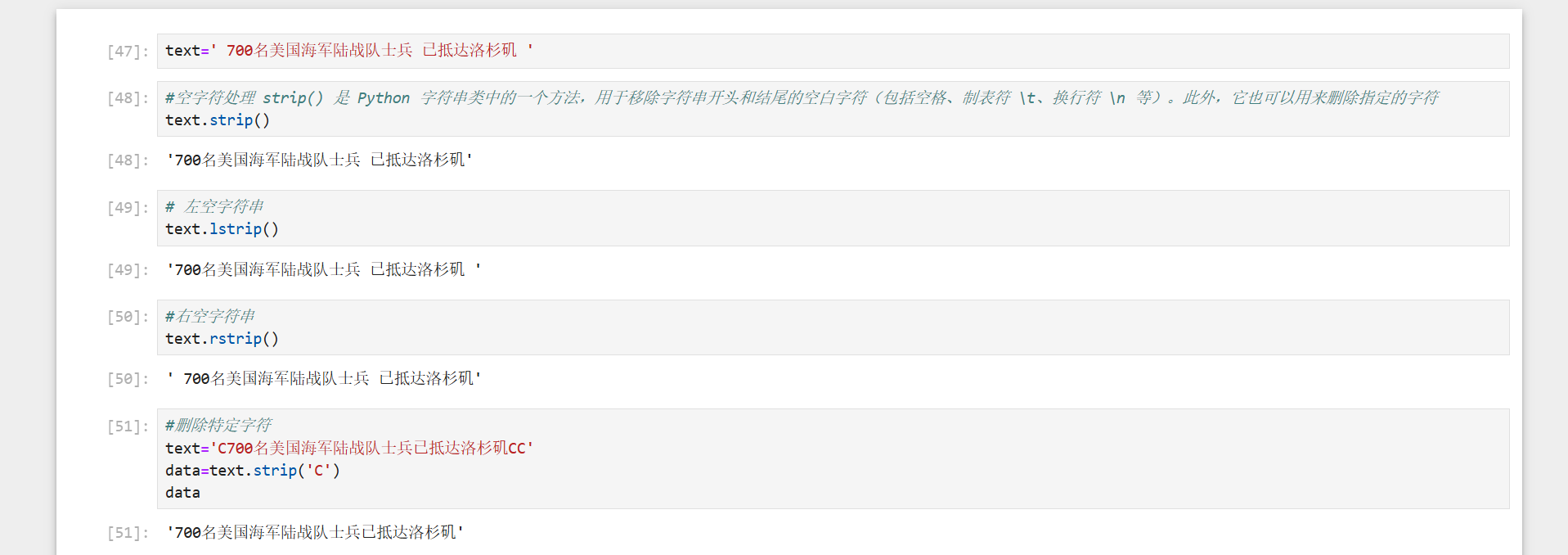
2、替换与查找
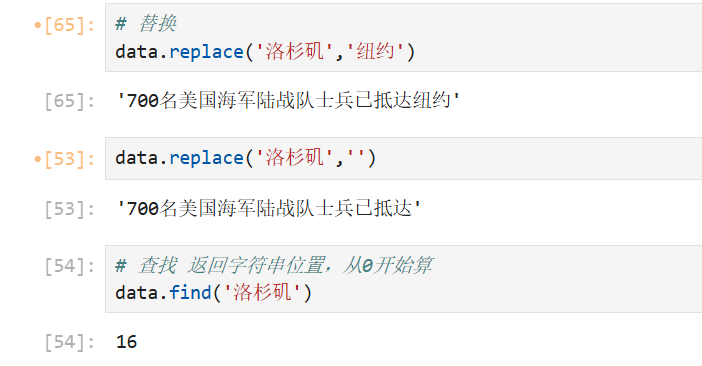
3、判断
基于内容的判断(字符类型检查)
| 方法 | 说明 | 示例 |
|---|---|---|
str.isalnum() |
是否仅包含字母或数字(至少一个字符) | "Ab12".isalnum() → True |
str.isalpha() |
是否仅包含字母(至少一个字符) | "中文abc".isalpha() → True |
str.isascii() |
是否所有字符都是 ASCII 字符(空字符串返回 True) |
"A!".isascii() → True |
str.isdecimal() |
是否仅包含十进制数字(如 0-9,全角数字) |
"123".isdecimal() → True |
str.isdigit() |
是否仅包含数字(包括特殊数字如 ²、➍) | "123".isdigit() → True |
str.isnumeric() |
是否仅包含数字字符(包括汉字数字、罗马数字等) | "五Ⅳ".isnumeric() → True |
str.islower() |
是否包含至少一个字母,且所有字母为小写 | "a1b".islower() → True |
str.isupper() |
是否包含至少一个字母,且所有字母为大写 | "A1B".isupper() → True |
str.isspace() |
是否仅包含空白字符(空格、\t、\n 等,至少一个字符) |
"\t \n".isspace() → True |

4、分割
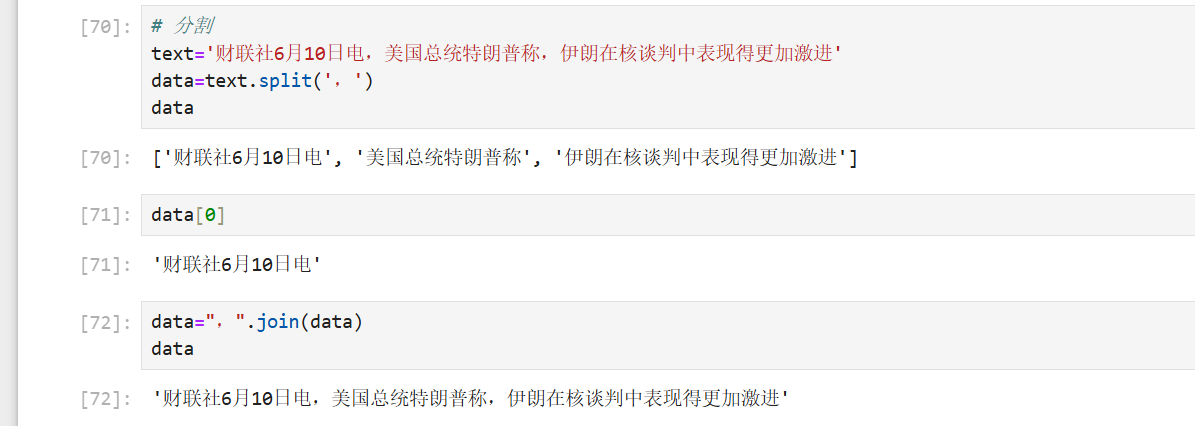
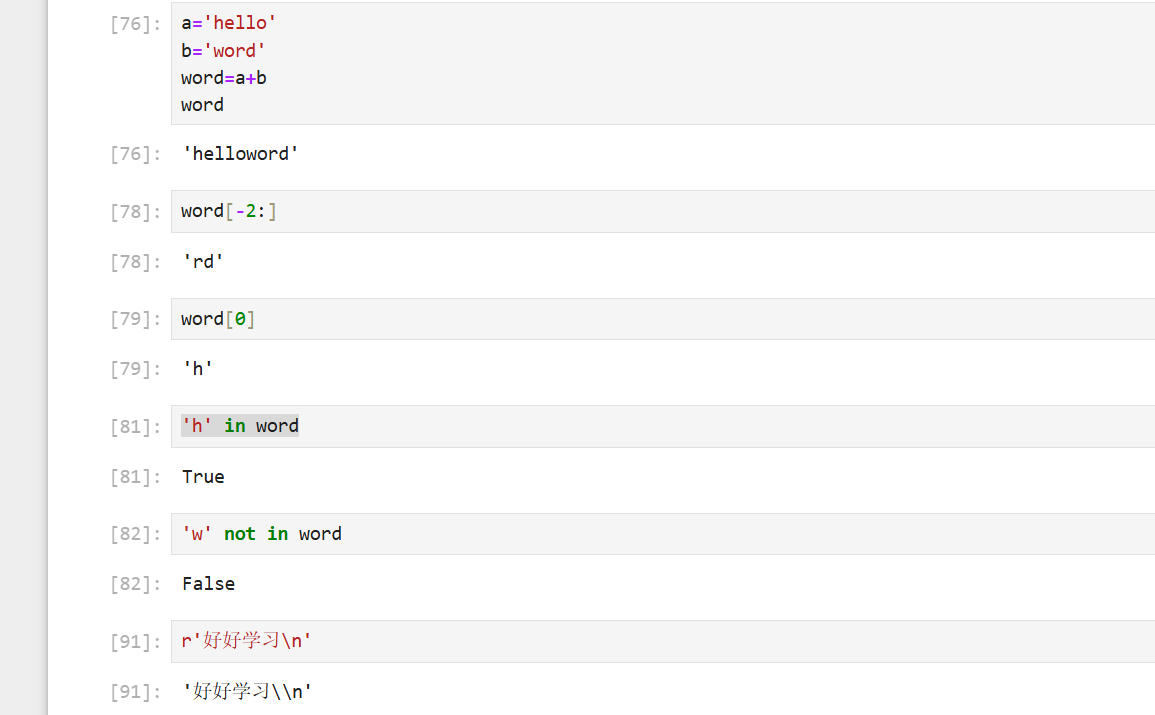
5、字符串连接
Python字符串运算符--来自菜鸟教程
下表实例变量 a 值为字符串 "Hello",b 变量值为 "Python":
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 |
>>>a + b 'HelloPython' |
| * | 重复输出字符串 |
>>>a * 2 'HelloHello' |
| [] | 通过索引获取字符串中字符 |
>>>a[1] 'e' |
| [ : ] | 截取字符串中的一部分 |
>>>a[1:4] 'ell' |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True |
>>>"H" in a True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True |
>>>"M" not in a True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 |
>>>print r'\n' \n >>> print R'\n' \n |
二、正则表达式
正则表达式模式--来自菜鸟教程
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 精确匹配 n 个前面表达式。例如, o{2} 不能匹配 "Bob" 中的 "o",但是能匹配 "food" 中的两个 o。 |
| re{ n,} | 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。"o{1,}" 等价于 "o+"。"o{0,}" 则等价于 "o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | 对正则表达式分组并记住匹配的文本 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \s | 匹配任意空白字符,等价于 [ \t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
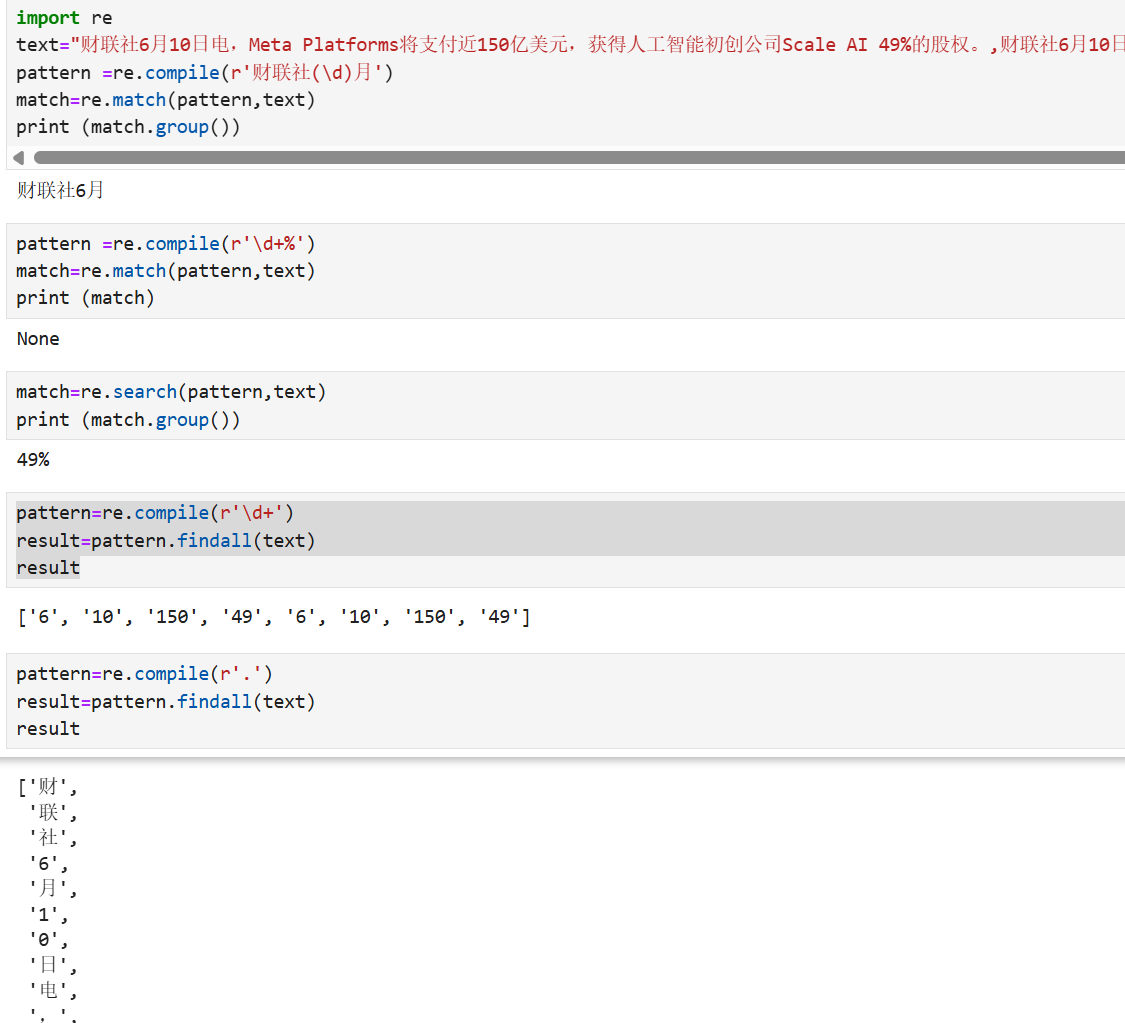
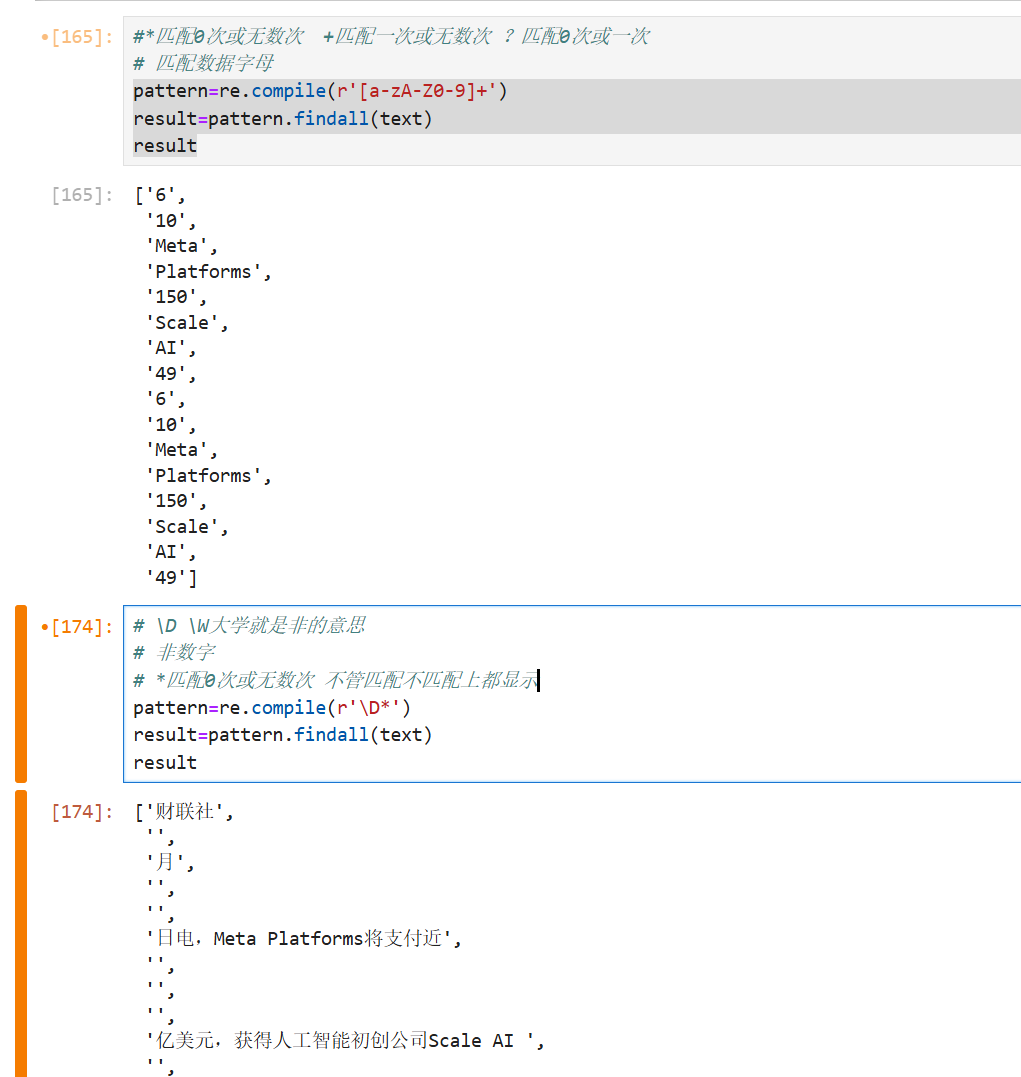
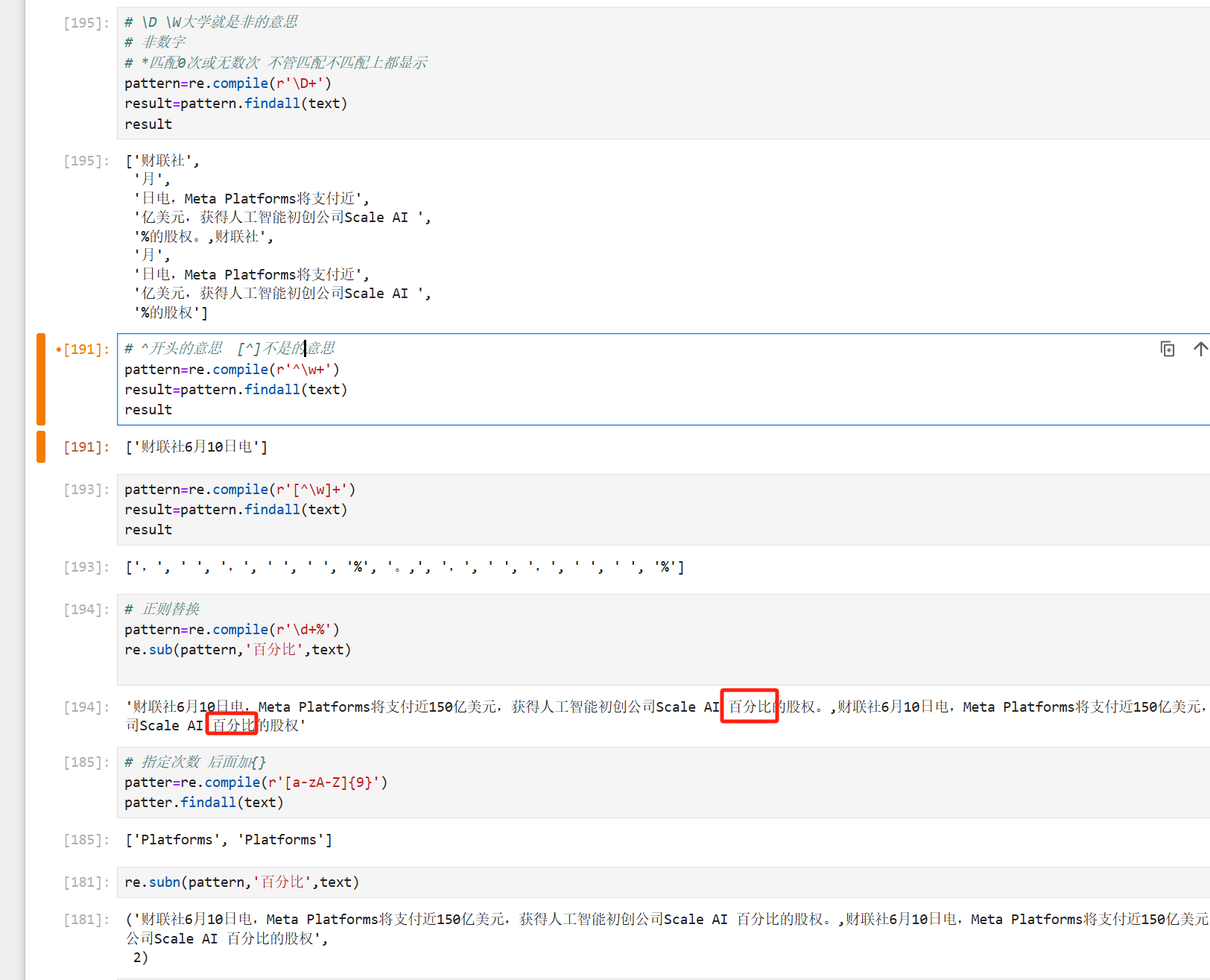
pattern: 匹配的正则表达式
re.compile 函数:用于编译正则表达式,生成一个正则表达式( Pattern )对象,可以给 match() 、 search() 以及 findall 等函数使用。
re.macth函数: 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话就返回 none。
re.search方法:扫描整个字符串并返回第一个成功的匹配
findall:在字符串中找到正则表达式所匹配的所有子串,并返回一个列表
三、结巴分词
jieba(结巴分词)是一个开源的中文分词工具,用于将中文文本切分成词语或词汇单位。
(没安装的,安装语句:pip install jieba)
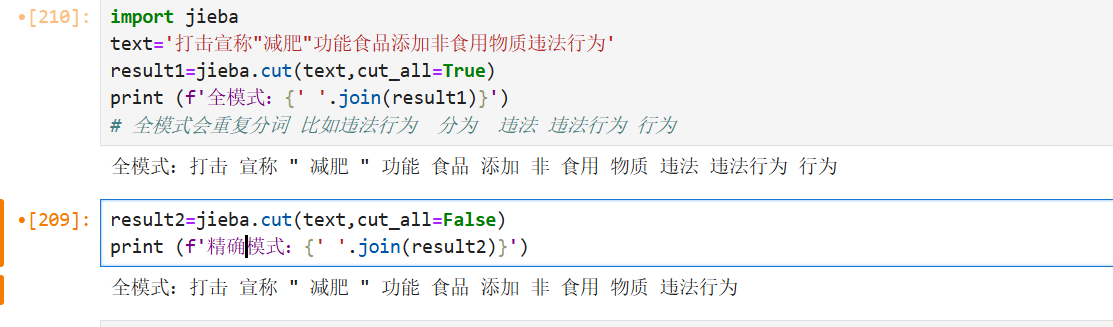
1、分词模式
2、添加词典
词典是为了后面分词更准确,如没有添加之前,央视新闻会分为央视和新闻两个词,但是添加后会分为央视新闻,所以为了分词更精确,我们要添加词典!
添加词典有两种方式
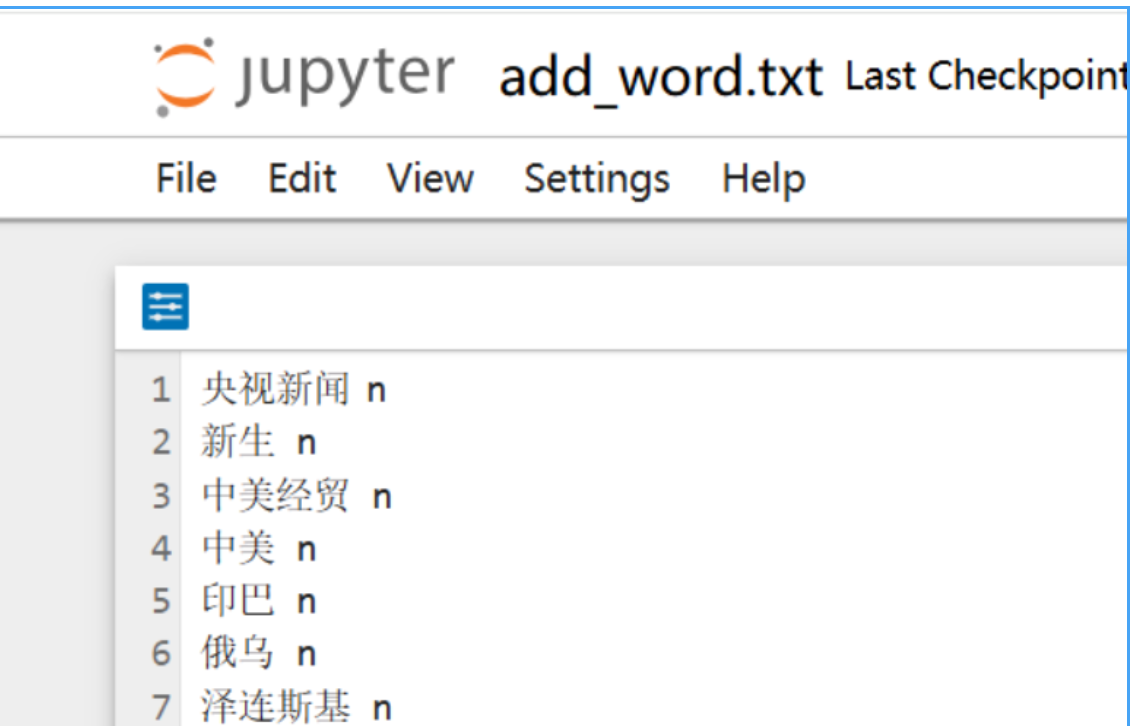
1>直接添加到txt文件(推荐用这个方法),如下所示
词典文件组成:词语+空格+词性(央视新闻 n),如下
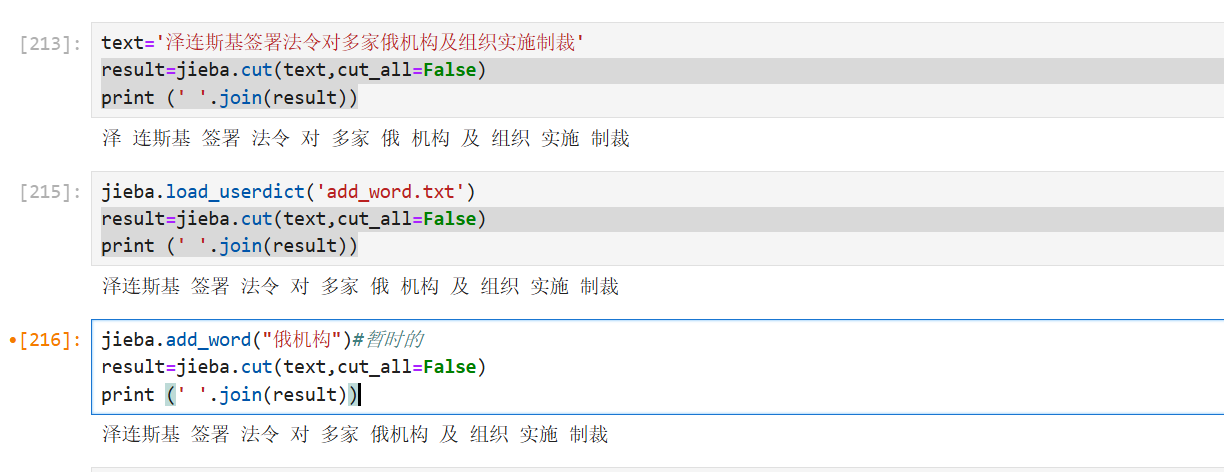
2>另一种是临时添加,如下
jieba.add_word("央视新闻")实例展示如下:
3、添加停用词
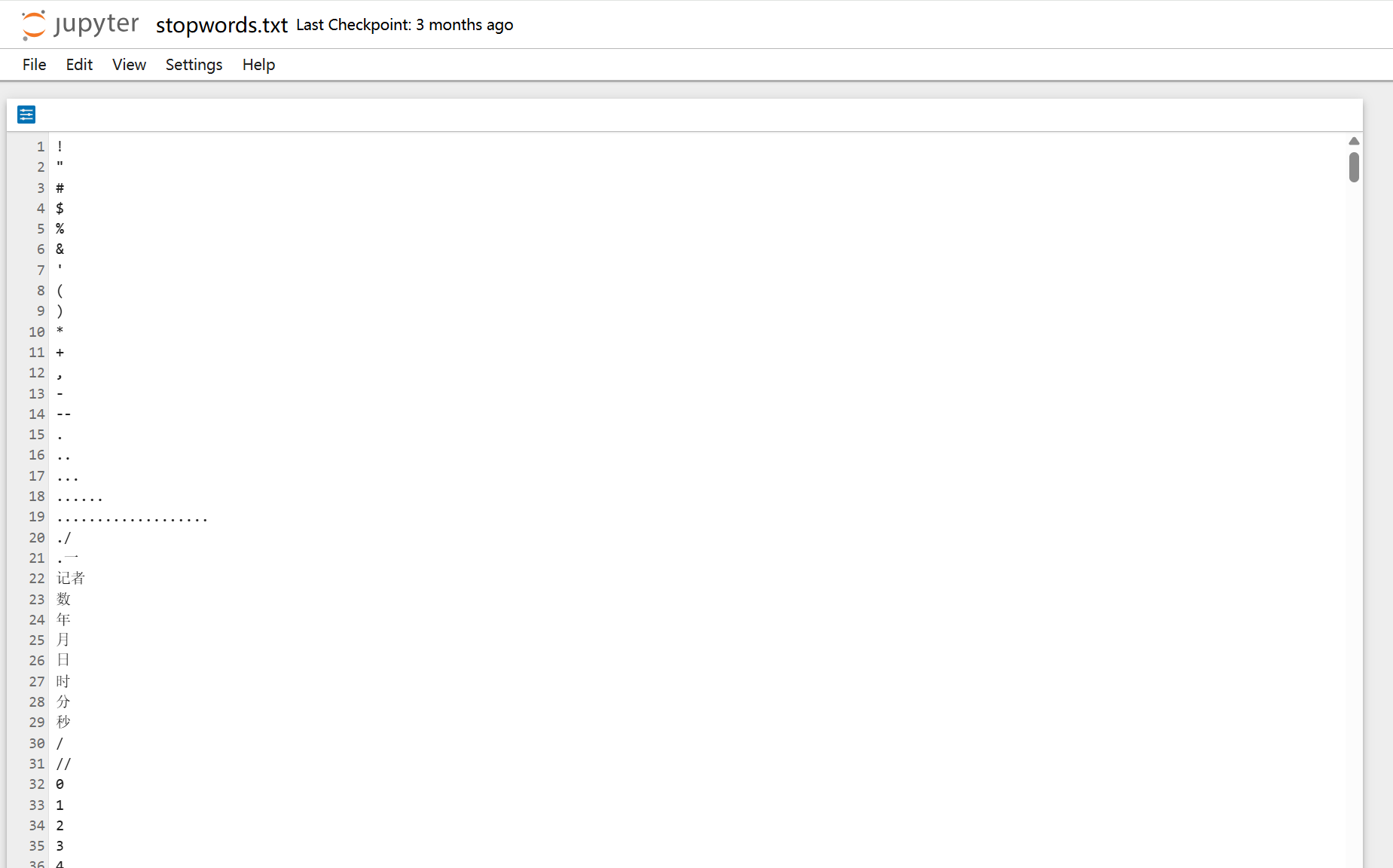
在分词以后有些词语对我们分析并没有用处,所以我们需要通过添加停用词对分词后的词语进行清洗
如下停用词是在网上找的,内容如下图(可以把没用的词语直接写入这个文件里面):
我们也可以临时添加停用词(stopwords.union),实例展示如下: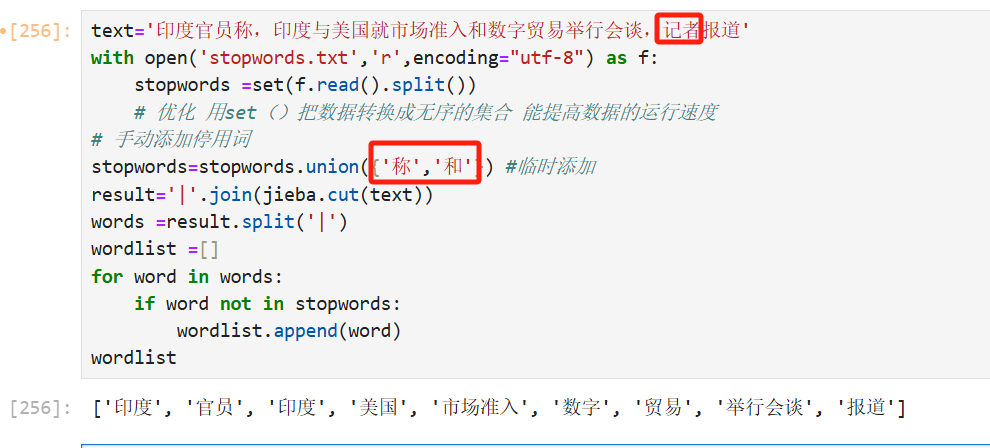
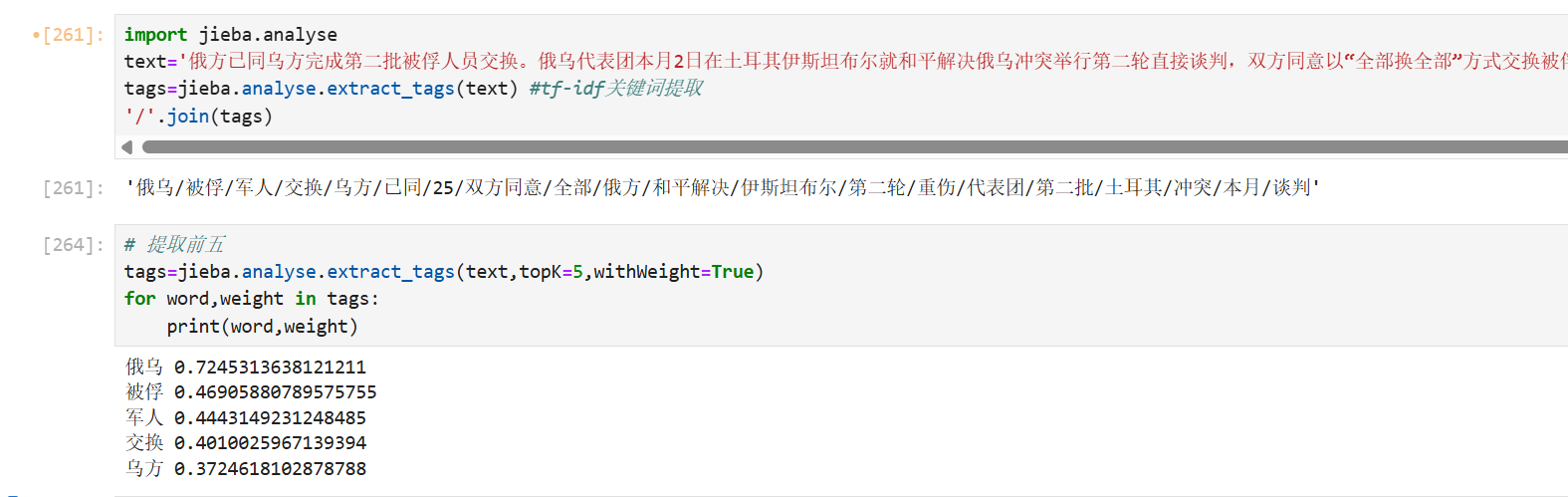
4、关键词提取
关键词用的tf-idf原理,tf-idf=词频*逆文档频率,通俗易懂的意思就是在本文出现频率多但是在别的文章出现频率少
tags = jieba.analyse.extract_tags(
sentence, # 待提取的文本(字符串)
topK=5, # 返回关键词数量(根据需求自己调整)
withWeight=False, # 是否返回权重(默认 False)
allowPOS=(), # 允许的词性(如 ['n', 'v'],默认不过滤)
withFlag=False # 是否返回词性(需 withWeight=True)
)
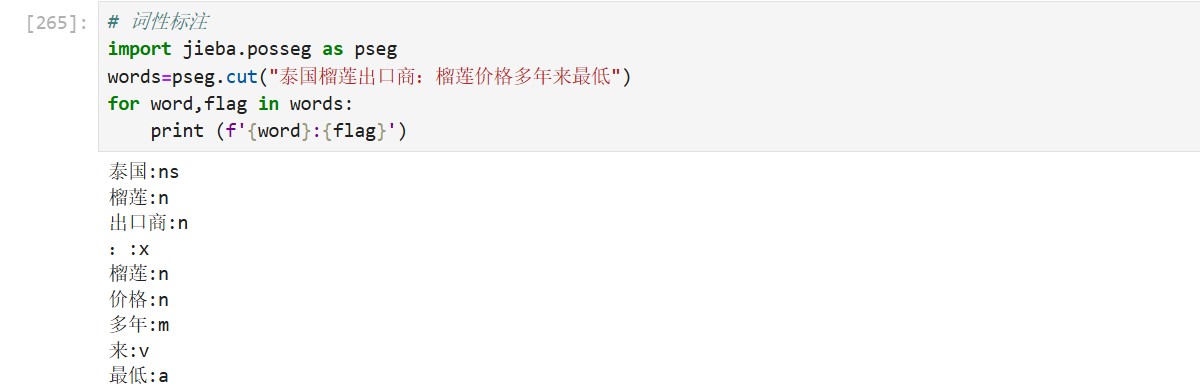
5、词性分析
有问题与意见请在评论区交流,谢谢!
【想要资源的后台私信可直接提供!】

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)