
Dots.ocr :有史以来最好的小型 OCR
这个东西吃扫描的文档当早餐:布局、内容、多语言文本、公式、表格,它可以毫无问题地解析所有这些。在他们的内部基准测试(100 种语言的 1493 个 PDF)中,与豆包或 MonkeyOCR 相比,它的错误率降低了近一半。多年来,OCR 是一个独立的领域,拥有笨重的工具和脆弱的管道。成为专用的检测模型。因为如果你在 OCR 领域工作了足够长的时间,你就会知道华而不实的声明并不意味着没有好数字的蹲点。
如果您在 2025 年仍然在处理笨重的 OCR 管道,请停止。Dots.ocr 刚刚发布,它正是那种“悄无声息”的模型,让你仔细检查参数计数。
是的,它是 1.7B。不,感觉不像。
这个东西吃扫描的文档当早餐:布局、内容、多语言文本、公式、表格,它可以毫无问题地解析所有这些。它在一个统一的视觉语言模型中做到这一点。没有奇怪的多阶段预处理。你给它一个提示。它弄清楚了其余的。
让我们谈谈是什么让这个模型如此愚蠢地好。
不仅仅是另一个 OCR 模型

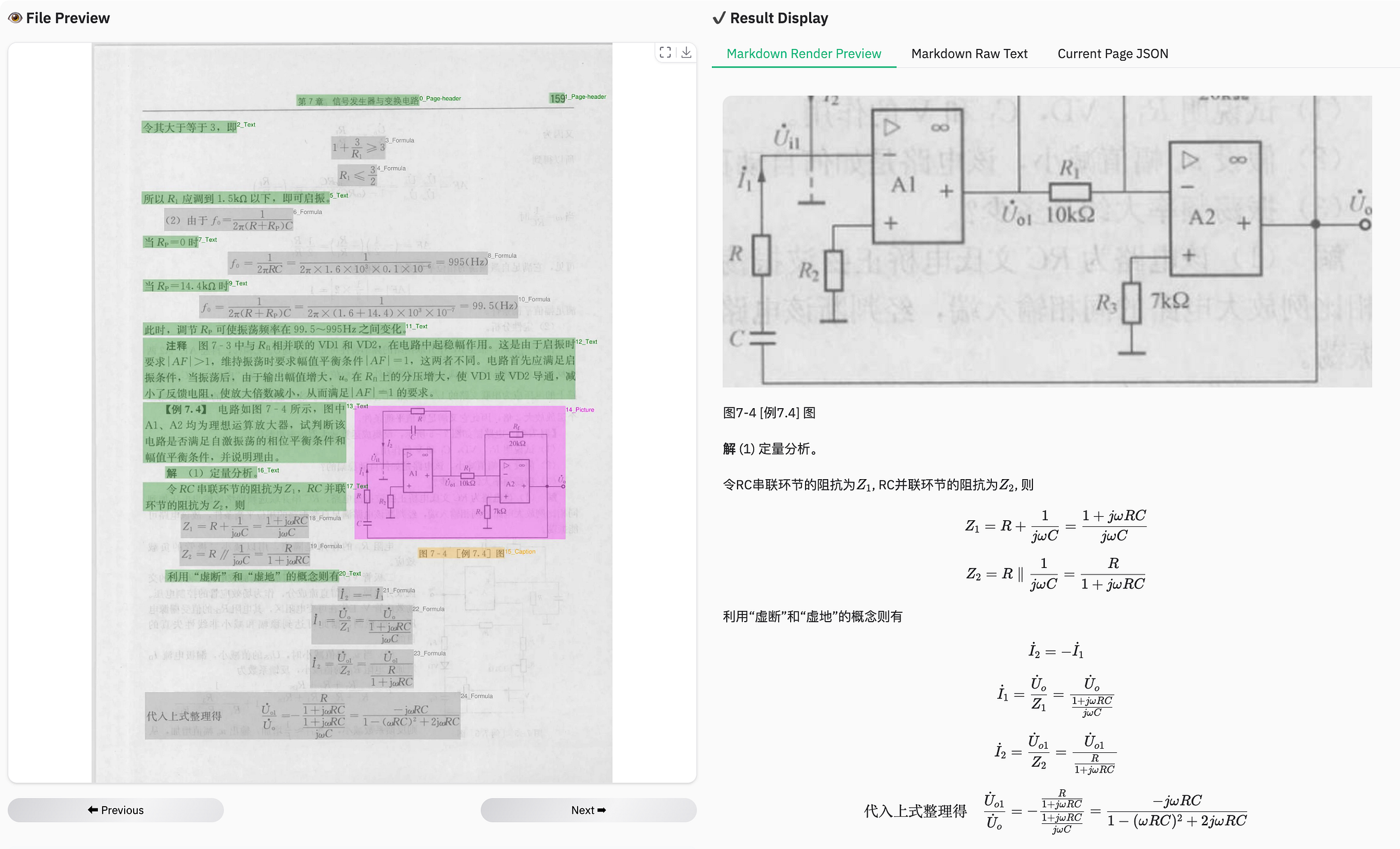
dots.ocr 是一个视觉语言模型,可以说流利的文档。
其他模型将 YOLO 风格的检测器与语言模型一起使用,而 dots.ocr 仅使用一个 VLM 来处理布局检测、文本解析、阅读顺序,甚至公式。无需在型号之间切换。没有特征错位。只是一个干净的、基于提示的界面,用于在任务之间切换。
- 您想要布局检测吗? 更改提示。
- 您想要纯文本 OCR?更改提示。
- 想要通过边界框接地区域?也有提示。
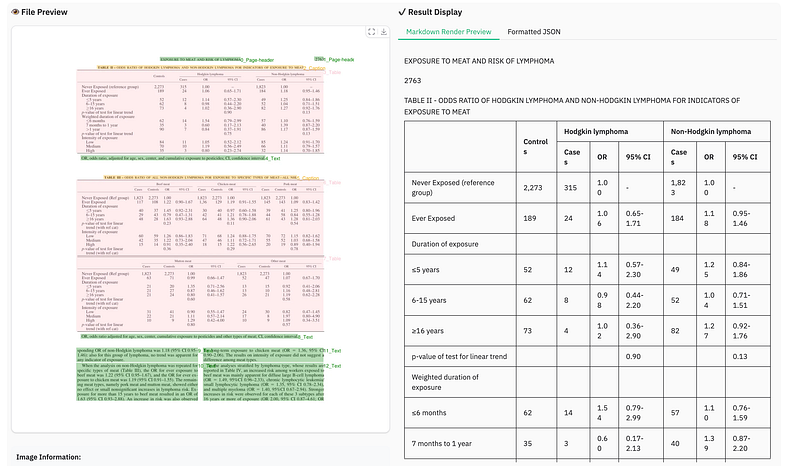
这使得部署、调试和扩展变得异常容易。您不需要维护三个不同的模型并希望它们在表的坐标上达成一致。Dots.ocr 第一次就做对了。

性能
让我们谈谈基准。因为如果你在 OCR 领域工作了足够长的时间,你就会知道华而不实的声明并不意味着没有好数字的蹲点。
OmniDocBench 系统
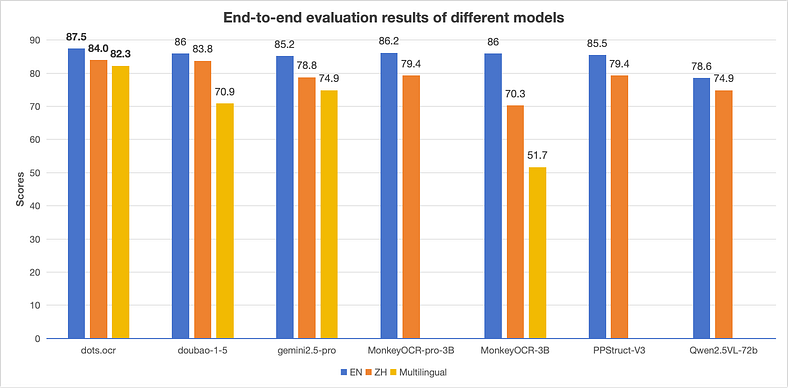
在文档解析的黄金标准基准上,dots.ocr 完全拥有它的类别。它在以下方面获得了最高分:
- 文本识别:EN:0.032,ZH:0.066(更低 = 更好)
- 公式检测:与 Gemini72-Pro 等 2.5B 机型相当
- 表格理解:88.6 / 89.0 TableTEDS (EN/ZH)
- 阅读顺序:它基本上做到了这一点,得分低于 GPT-4o、Mistral,甚至 MonkeyOCR-Pro-3B
从这个角度来看,这款 1.7B 型号的性能是其尺寸的 20 倍。
多语言解析 (dots.ocr-bench)
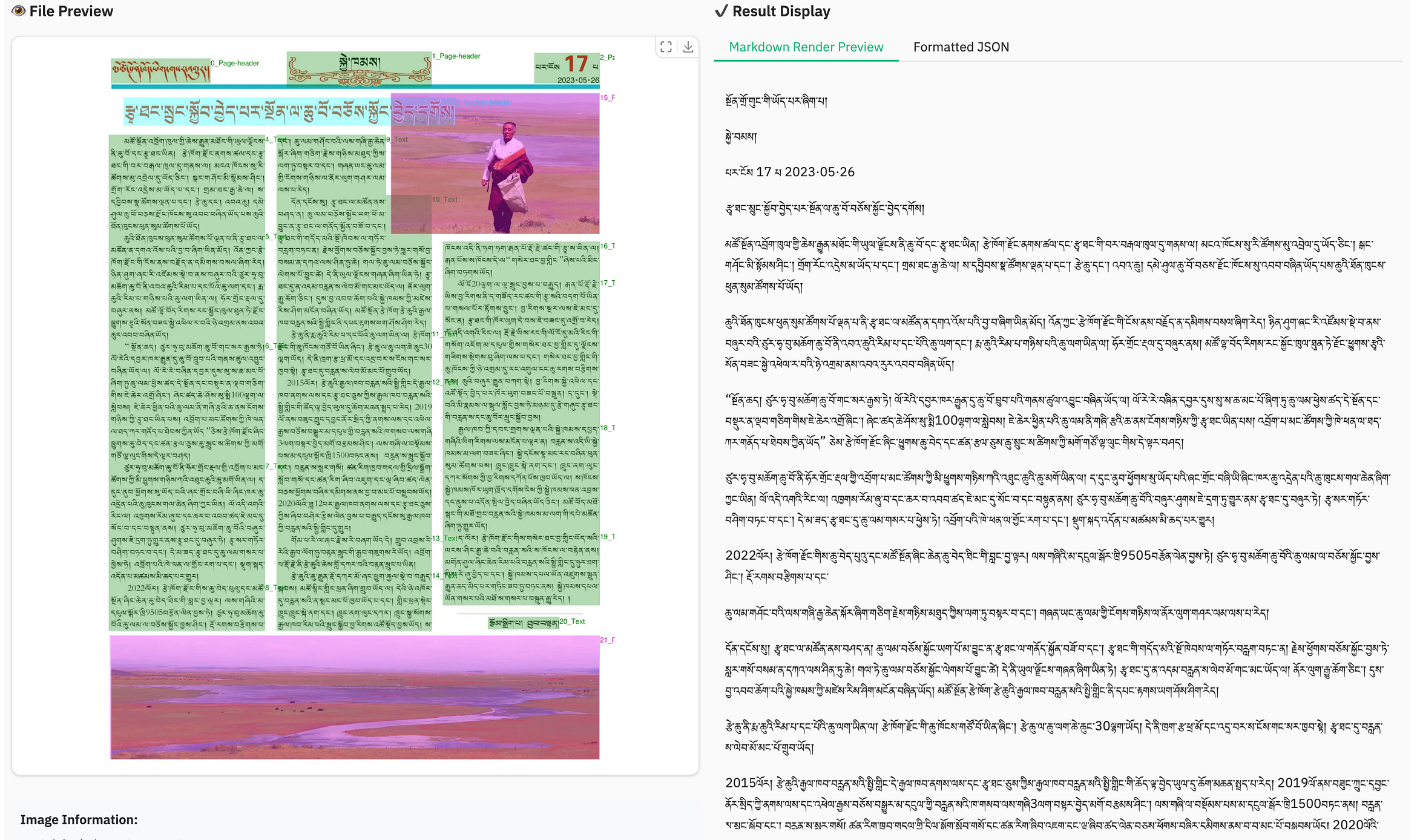
dots.ocr 不仅在低资源语言中生存下来,而且蓬勃发展。在他们的内部基准测试(100 种语言的 1493 个 PDF)中,与豆包或 MonkeyOCR 相比,它的错误率降低了近一半。
为什么这很重要?因为大多数 OCR 系统在你向他们扔藏语或卡纳达语之类的东西的那一刻就会崩溃。dots.ocr 只是耸耸肩并继续解析。
版面检测:YOLO 谁?
DocLayout-YOLO 应该是“足够好”的基线。但 dots.ocr 用它擦地板:
- F1@IoU .50:总分 0.93 与 YOLO 的 0.80
- 单独用于配方检测:0.832 vs 0.620
它可以做到这一点,而无需成为专用的检测模型。只需用 提示它,它就会成为一个。这就是诀窍:VLM 曾经是万事通,一无所长。dots.ocr 感觉就像一位大师。prompt_layout_only_en
深切:OLMOCR-bench
如果您曾经处理过嘈杂的 PDF、旧扫描件、数学内容丰富的日记、奇怪的标题,您就会知道这些是模型死亡的地方。
- MonkeyOCR-pro-3B 总体得分为 75.8。
- dots.ocr 的?79.1. 即使在嵌入 LaTeX 和来自地狱的脚注的多列垃圾扫描中,它也不会退缩。
甚至还有针对特定文档类型的细分:
教科书、试卷、财务报告、报纸......dots.ocr 全面领先或排名第二。考虑到它在 BF3 精度的 ~16B 参数上运行,这太疯狂了。
部署出奇地干净
您可以通过 Huggingface API 部署它。这些文档实际上是可用的,但这里引起了我的注意:vLLM
- 没有 TensorRT 戏剧。无需保姆 CUDA。
- 基于提示的任务切换意味着您不需要为每种文档类型使用自定义推理脚本。
- 如果你懒惰,可以支持 Docker(我是)。
它甚至还有一个有效的 Gradio 演示。
它还不完美
如果我不指出缺陷,这就不是一篇诚实的帖子:
- 高密度图像可能会绊倒它。如果您的图像是 11289600 像素或更多,请缩减采样或将 DPI 提高到 200。
- 特殊字符喜欢或导致输出中出现奇怪的重复错误。在这些情况下,您需要尝试其他提示。
...___ - 没有图片解析。这仍然是一个差距。如果您的文档嵌入了信息图表,那么您就不走运了。
- 批量作业的吞吐量有限。它尚未针对大规模 PDF 摄取进行优化。
但考虑到这是第一个版本,这些都是小的权衡。它仍然比市场上的大多数产品更强大。
为什么这个模型实际上很重要
dots.ocr 感觉就像一个证明点,不仅用于文档解析,而且用于正确完成视觉语言建模。多年来,OCR 是一个独立的领域,拥有笨重的工具和脆弱的管道。现在?这只是另一个提示。
这不再是关于 OCR 的。这是关于将整个工具链折叠成一个实际有效的灵活 VLM。
如果您正在构建任何涉及扫描表格、多语言文档、学术论文甚至凌乱发票的东西,请测试一下。它免费,速度快,而且好得危险。
该模型是开源的,可以在下面访问
结束语
我通常不会给 OCR 工具写情书。但 dots.ocr 感觉就像那种让其他工具在一夜之间变得无关紧要的模型。在它臃肿、商业化或被十层企业许可掩埋之前尝试一下。
如果您正在围绕文档智能构建一个项目,请跳过 YOLO、UNets 和手工制作的表格启发式方法。只需使用这个。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)