
FlashSpeech: 创新零样本语音合成系统
这篇由香港科技大学、微软、萨里大学等机构合作完成的论文,提出了一种名为FlashSpeech的创新零样本语音合成系统。该系统旨在解决当前大规模零样本语音合成方法生成速度慢、计算成本高的问题,实现高效、高品质的语音合成。
这篇由香港科技大学、微软、萨里大学等机构合作完成的论文,提出了一种名为FlashSpeech的创新零样本语音合成系统。该系统旨在解决当前大规模零样本语音合成方法生成速度慢、计算成本高的问题,实现高效、高品质的语音合成。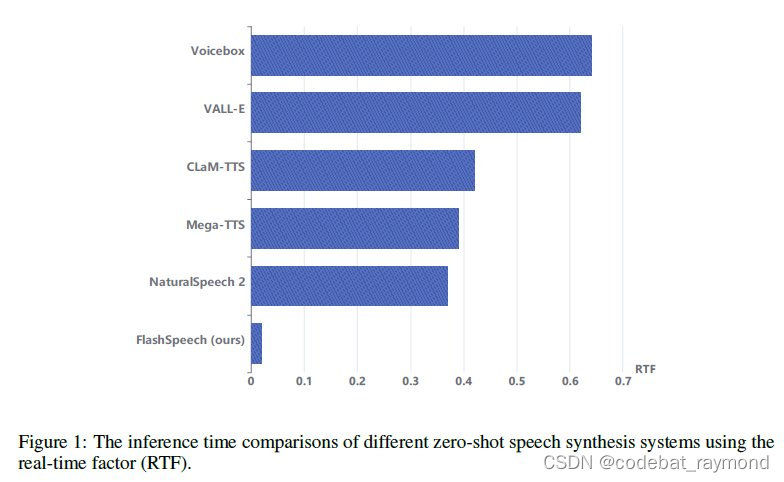
一、研究背景与动机:
随着深度学习技术的发展,零样本语音合成近年来取得显著进展。现有的方法主要基于语言模型(如VALL-E、ClaM-TTS)或扩散模型(如NaturalSpeech 2、Voicebox)实现。然而,这些方法在生成过程中需要大量的计算时间和资源,如VALL-E需要预测75个音频tokens来生成1秒钟的语音,NaturalSpeech 2则需要150个采样步骤。虽然一些工作(如Voicebox、ClaM-TTS)尝试通过最佳传输路径或优化音频编码器来加速生成过程,但推理速度仍不尽如人意。因此,如何在保证合成品质的同时大幅提升生成效率,成为亟待解决的关键问题。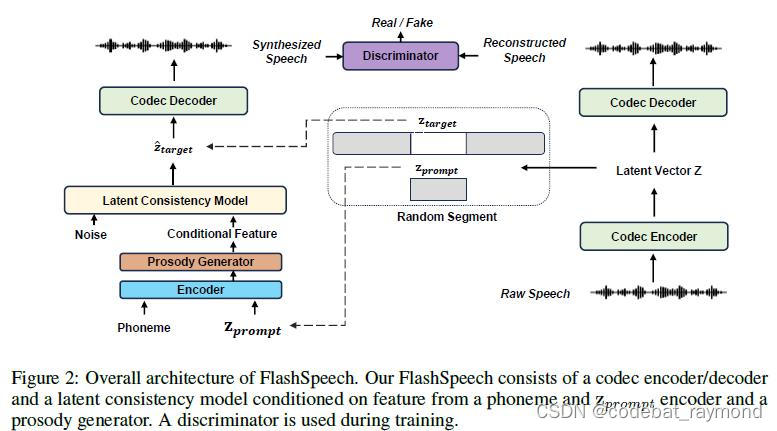
二、FlashSpeech系统架构:
FlashSpeech系统主要由以下模块组成:
1. 语音编解码器(codec):
使用Encodec模型将语音转换为潜在向量表示,并在合成后将生成的潜在向量转换回语音信号。
2. 潜在一致性模型(latent consistency model, LCM):
接收来自音素编码器、提示编码器和韵律生成器的条件特征,利用少量采样步骤生成目标语音的潜在向量。LCM通过对抗一致性训练从头开始学习,无需预训练的扩散模型作为教师。
3. 音素编码器和提示编码器:
分别将输入的音素序列和参考音频转换为隐藏特征表示,作为LCM的条件输入。
4. 韵律生成器:
基于隐藏特征预测语音的基频和时长。该模块包括韵律回归和韵律细化两部分,前者生成初始的确定性预测,后者利用一致性模型对韵律进行随机细化,以提高韵律的多样性。
5. 鉴别器:
在训练过程中,利用预训练的语音语言模型(如WavLM)作为鉴别器,引导LCM生成更真实的语音。同时,鉴别器以参考音频的特征为条件,以提高合成语音与参考音频的相似度。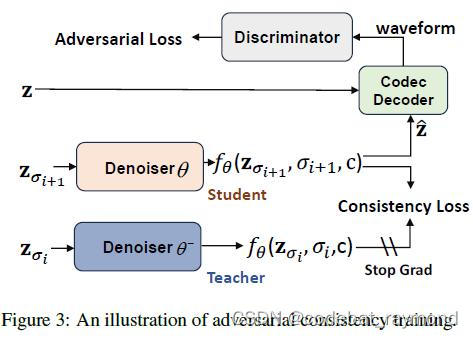
三、关键创新点:
1. 对抗一致性训练:FlashSpeech提出一种新颖的训练方法,利用预训练的语音语言模型作为鉴别器,无需训练额外的扩散模型作为教师,即可直接从头开始训练LCM。这不仅降低了训练成本,还使得生成品质不受教师模型性能的限制。在训练过程中,作者巧妙地结合了一致性损失和对抗损失,并引入自适应权重以平衡两种损失的梯度尺度,有效稳定了训练过程。
2. 韵律生成机制:FlashSpeech设计了一种新颖的韵律生成器,包括韵律回归和韵律细化两个模块。韵律回归生成初始的确定性预测,韵律细化则利用一致性模型对韵律进行随机细化,以提高韵律的多样性。此外,作者引入了一个控制因子α,用于平衡韵律的多样性和稳定性。实验表明,适当选择α可以在保持语音清晰度的同时,显著提高韵律的丰富性。
3. 高效的潜在一致性模型:FlashSpeech利用潜在一致性模型实现高效的语音生成。与先前基于语言模型或扩散模型的方法相比,LCM将生成过程的计算复杂度从O(N)或O(T)降低到O(1),仅需一两步采样即可生成高品质的语音。这种高效的生成机制使得FlashSpeech的推理速度比现有系统快约20倍。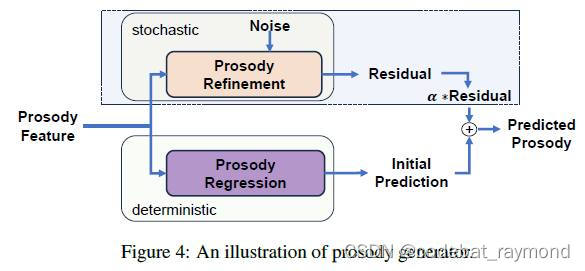
四、实验设置与结果:
1. 数据集:论文在包含44.5k小时语音的MLS(Multilingual LibriSpeech)英文子集上进行训练,该数据集涵盖了5490位说话人。在LibriSpeech的test-clean子集上进行了零样本语音合成的评估。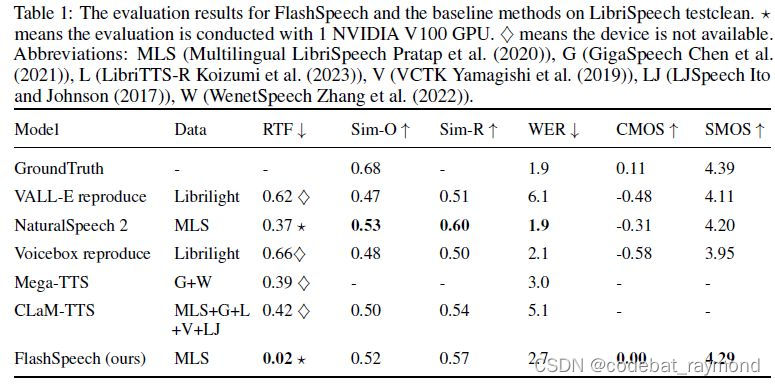
2. 评估指标:作者采用客观和主观指标全面评估FlashSpeech的性能,包括:
\- 实时因子(RTF):衡量生成1秒钟语音所需的时间。
\- 说话人相似度:使用Sim-O和Sim-R度量合成语音与原始/重建参考语音在说话人特征上的相似性。
\- 字错误率(WER):通过自动语音识别(ASR)模型转录合成语音,计算转录结果与原始文本的差异,以评估语音的清晰度和准确性。
\- 主观评分:包括音质的比较平均意见分(CMOS)、说话人相似度的主观评分(SMOS)等。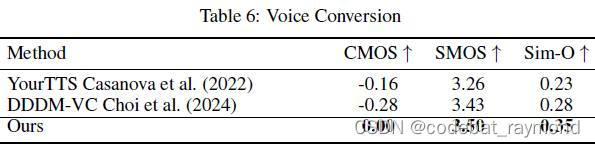
3. 实验结果:在LibriSpeech testclean上的评估表明,FlashSpeech在以下方面表现出色:
\- 生成品质:在CMOS和音质偏好测试中,FlashSpeech显著优于其他基准系统,生成的语音品质接近真实语音。
\- 说话人相似度:FlashSpeech在Sim-O、Sim-R和SMOS等指标上分别排名第一、第二和第三,证实了其在保持说话人特征方面的能力。尽管训练数据中包含的说话人数量少于其他方法,但FlashSpeech仍然取得了相当的效果。
\- 鲁棒性:FlashSpeech的字错误率(WER)为2.7,处于第一梯队,这得益于其非自回归的生成方式。
\- 生成速度:FlashSpeech的推理速度比现有方法快约20倍,在保证合成品质的同时大幅提升了生成效率。
除了在语音合成任务上的出色表现,论文还探讨了FlashSpeech在语音转换、语音编辑、多样化语音生成等应用中的有效性。实验结果表明,FlashSpeech在这些任务上同样展现了优越的性能。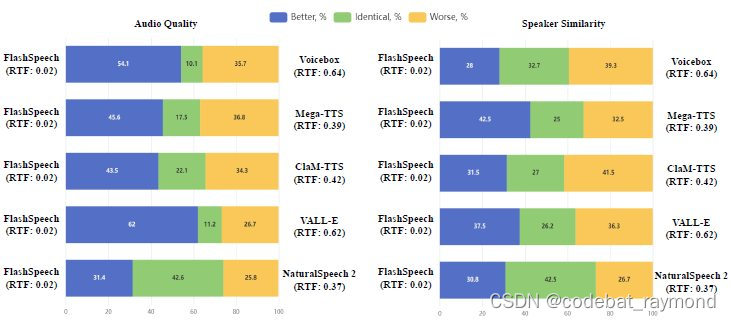
五、消融实验:
为了验证FlashSpeech各模块和训练策略的有效性,作者进行了一系列消融实验。
1. 鉴别器设计:实验比较了不同预训练模型(如wav2vec2-large、hubert-large、wavlm-large)作为鉴别器对LCM性能的影响。结果表明,使用WavLM作为鉴别器可以显著提高合成语音的自然度(UTMOS)和说话人相似度(Sim-O)。此外,以参考音频的特征为条件训练鉴别器,也有助于提升合成品质。
2. 采样步数:作者探究了LCM的采样步数对合成品质的影响。实验结果显示,增加采样步数从1步到2步可以略微提高UTMOS和Sim-O,但进一步增加到4步则会导致UTMOS下降,这可能是由于分数估计误差的累积。因此,论文最终选择2步作为LCM的预设采样设置。
3. 韵律控制因子:论文研究了韵律生成器中控制因子α对基频和时长预测的影响。实验表明,适当选择α(如0.2)可以在保持WER不变的情况下,降低基频和时长的JS散度,提高韵律的多样性。但过大的α(如1.0)虽然可以进一步降低JS散度,却会导致WER升高,说明韵律多样性和语音清晰度之间存在权衡。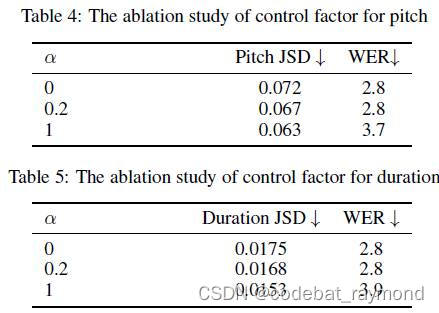
六、结论与展望:
FlashSpeech通过创新的对抗一致性训练、韵律生成机制和高效的潜在一致性模型,在保证合成品质的同时显著提升了生成效率,为大规模零样本语音合成提供了一种极具前景的解决方案。与现有方法相比,FlashSpeech在音质、说话人相似度、语音清晰度等方面表现出众,且生成速度快约20倍,展现出实际应用的巨大潜力。未来,研究团队计划进一步优化模型结构,扩充训练数据,以生成更丰富、自然的语音,并将该系统应用于虚拟助理、教育工具等领域。同时,作者也指出可以探索将FlashSpeech生成的合成数据用于语音识别等下游任务。
总之,FlashSpeech代表了语音合成技术的重要进展,为实现高效、高品质的大规模语音生成提供了新的思路和方法。这项工作有望成为未来大规模语音应用的关键支撑技术,推动人机语音交互体验的进一步提升。
https://arxiv.org/pdf/2404.14700

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)