
【机器学习】半监督学习
一、半监督学习(semi-supervised learning);二、生成式方法;三、半监督SVM(S3VM)
·
一、半监督学习(semi-supervised learning)
- 原因:”有标记数据少,未标记数据多“现象显著。
- 半监督学习:让学习器不依赖外界交互、自动利用未标记数据提高学习性能。
- 利用未标记样本的基本假设:相似样本拥有相似输出(聚类假设、流形假设)。
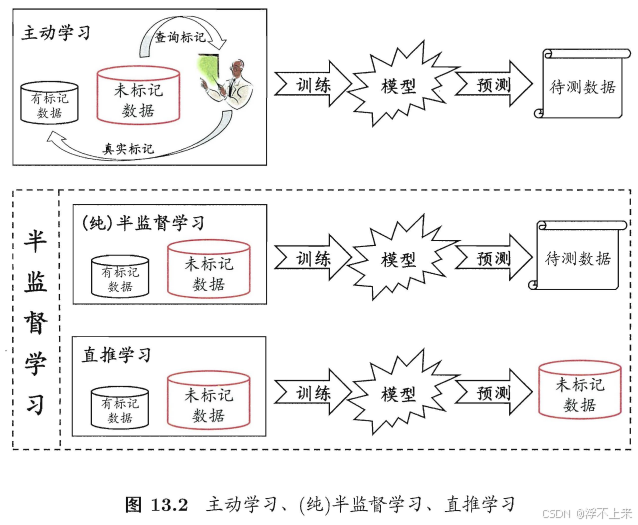
- 分类:纯半监督学习、直推学习(transductive learning)。
- 纯半监督学习:开放世界(联合对外)
- 直推学习:封闭世界(自产自销)
- 主动学习:有选择地查询少数标记来优化模型(无监督与监督学习中间档)
二、生成式方法
假设:数据由同一模型生成,未标记数据的标记看做隐变量,基于EM法求解,得到模型较优解再来预测。
- 基于高斯混合模型的生成式方法
三、半监督SVM(S3VM)
假设:低密度分隔(试图找到将有标记数据分开、且穿过数据低密度区域的划分超平面)
- TSVM
- 穷举:尝试将每个未标记样本作为正例和反例,在这些结果中寻求一个间隔最大化的超平面,未标记样本的最终标记指派就是其预测结果。
- 优化:穷举不现实,采用局部搜索迭代寻优。
- 算法:① 用标记数据集训练初始SVM,对未标记数据集指派标记;②大循环:逐渐增大未标记数据的重要性直至与已标记数据相当(初始指派不准确);③小循环:不断对调误判率最高的一对异类标记并重新求解参数。
- 再优化:小循环中调整每一对误判率较高的未标记样本,为大量计算开销的大规模优化问题。→ 基于图核函数梯度下降的LDS、基于标记均值估计的meanS3VM



技术共进,成长同行——讯飞AI开发者社区
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)