
能理解1万帧长视频的大模型!
长视频理解大模型!
前言
模型在面对长视频理解领域存在着困难,因为其往往有很多帧,远远超出了目前大模型的处理范围,已经存在的一些方法比如简单的帧采样策略或者特征融合方法会分别造成关键帧信息遗漏或者语义完整性受损。
今天要给大家介绍的这篇工作则是动态的分配计算配额,增强那些关键信息且差异大的的信息,注意这里说的不仅仅是关键,而且是差异大的(比如单从query角度看两个都是关键帧,但是很相似,那只保留一个就行啦),进一步压缩了冗余。所以其最终能实现在单卡A100上处理1万帧的效果。
论文也给出了和业界其他模型的比较(内存方面),可以看到其所提出的方法能给处理更长的视频
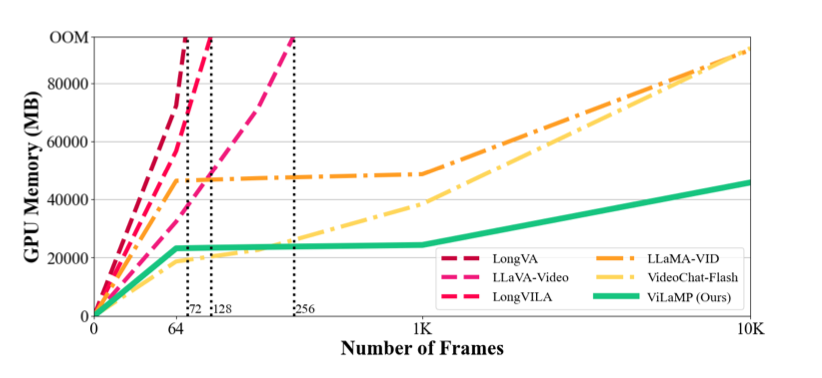
当然在各大benchmark榜单上效果也是sota
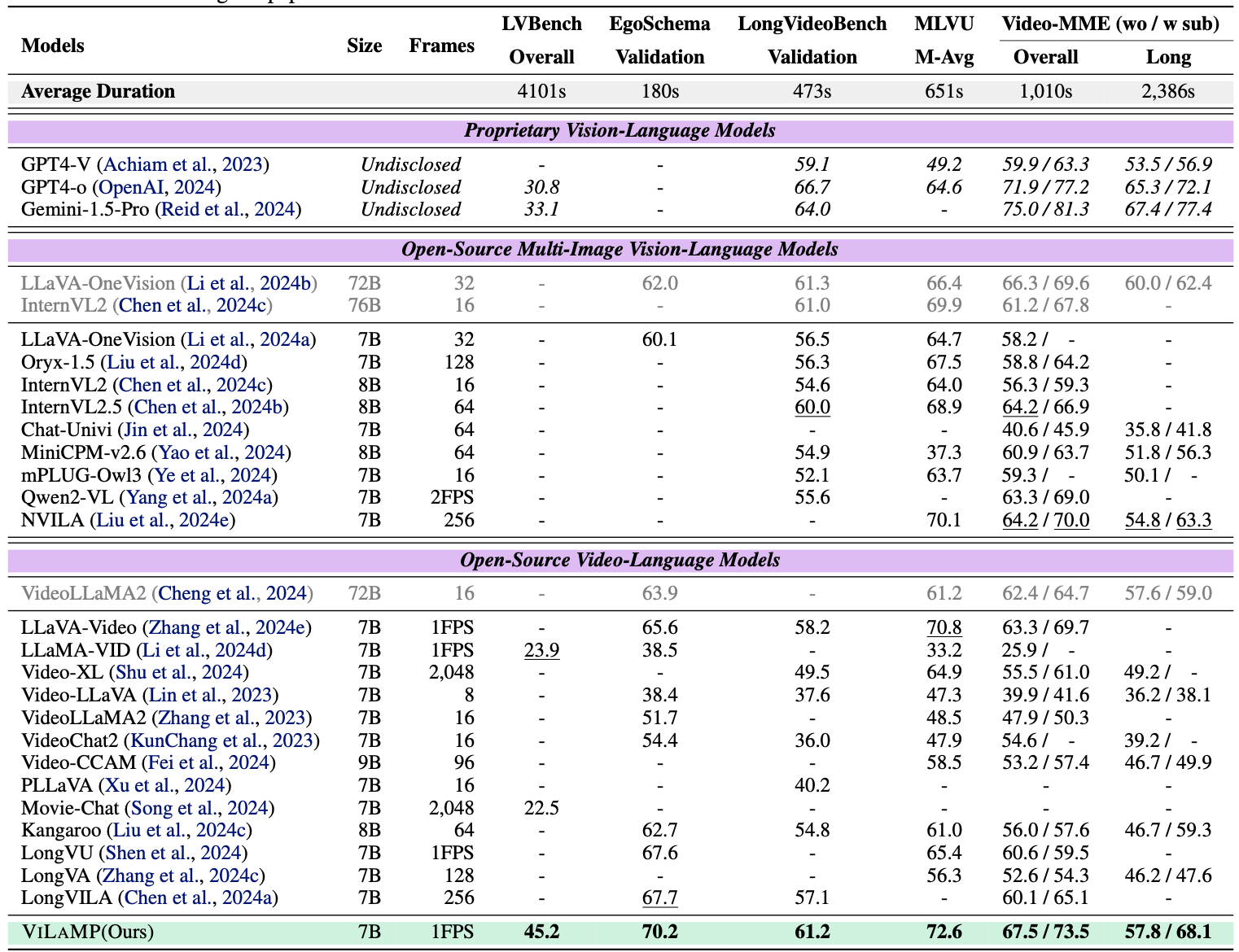
下面我们一起看看其具体是怎么实现的吧。
论文链接:https://arxiv.org/pdf/2504.02438
githun:https://github.com/steven-ccq/ViLAMP
方法
具体来说其分为Differential Keyframe Selection和Differential Feature Merging两个模块。前者模块负责“挑选”关键帧,后者就是特征融合即每一帧具体怎么表征。看起来思路和之前一样,但是不同的是其挑选和融合的手段都实现了动态。
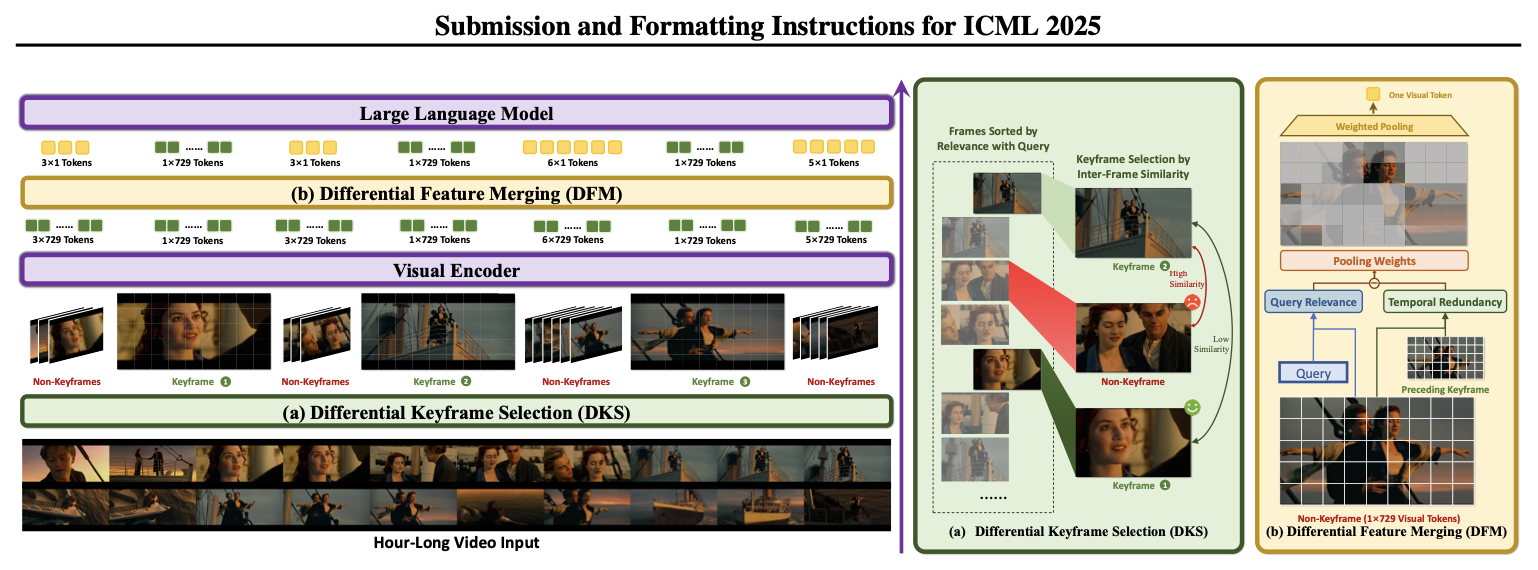
其整体都用了差分的思路
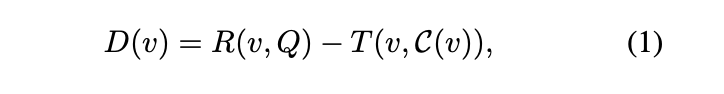
R ( v , Q ) R(v,Q) R(v,Q)代表的是和问题query的相似度,分数越高代表越相关。 T ( v , C ( v ) ) T(v,C(v)) T(v,C(v))代表的是当前v和其上下文的冗余性。可以看到 D ( v ) D(v) D(v)越高代表着和当前query相似度越高且更独特。换句话说其和query相似度高但是和之前的上下文冗余性高,那 D ( v ) D(v) D(v)分数也不会高。再举个特别直白的例子:假设第4、8帧和query的相似度很高,但是第8帧和第4帧相似度也很高,那就是说第4和第8帧虽然都是关键帧,但是二者存在冗余,只保留一个就行。
同样在表征每一帧内部patch的时候,也可以采用这种思路。
那具体是怎么落地实现的呢?我们来具体看看~
(1)Differential Keyframe Selection
假设给定当前帧序列 V = ⟨ f 1 , f 2 , ⋅ ⋅ ⋅ , f N ⟩ V=⟨f_{1}, f_{2}, · · · , f_{N}⟩ V=⟨f1,f2,⋅⋅⋅,fN⟩和问题 Q Q Q,那我们可以通过clip即 E f ( . ) E_{f}(.) Ef(.)来对每一帧和 Q Q Q分别进行表征,具体来说就是得到一个 d d d纬的向量。
接着就可以通过余弦相似度来计算每一帧和 Q Q Q的相似度分数 R f ( f n , Q ) R_{f}(f_{n},Q) Rf(fn,Q),对应的是上面的 R ( v , Q ) R(v,Q) R(v,Q)
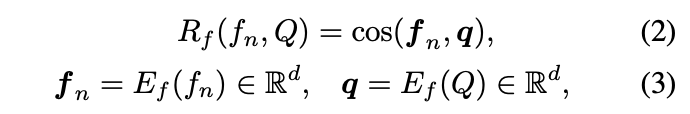
那我们再来看看 T ( v , C ( v ) ) T(v,C(v)) T(v,C(v))是怎么实现的
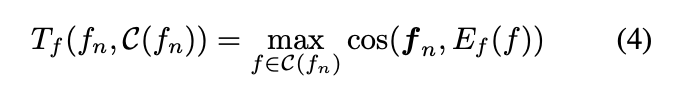
这里就是取和上下文最大相似度那个值作为冗余度。
基于上面两大指标就可以挑选出那些高相关且具有独特性强的关键帧。整个算法流程如下:

其中最终我们想挑选K个关键帧。
可以看到第1行就是在算每一帧和query的相似度 R f ( f n , Q ) R_{f}(f_{n},Q) Rf(fn,Q)并降序排序。
然后第3、4、5行就是从最高相似度->最低相似度帧开始逐个遍历,当发现其和已被选好的关键帧池的相似度低于某一预设值 τ τ τ就把它认为是一个新的关键帧,加入到关键帧池。从这里可以看到要同时满足和Q相似度高且不冗余的帧才会被加入到关键帧池。
(2)Differential Feature Merging
在经过(1)后其实就是选出了哪些是关键帧,哪些是非关键帧。接下来就是要开始分别表征了,一个直观的思路就是将关键帧的信息全部保留(因为重要),将非关键帧可以进行压缩(减少内存)。
假设非关键帧序列是 f n = ⟨ p n 1 , p n 2 , ⋅ ⋅ ⋅ , p n M ⟩ f_{n}=⟨p_{n}^{1},p_{n}^{2},· · ·,p_{n}^{M}⟩ fn=⟨pn1,pn2,⋅⋅⋅,pnM⟩。以及对应的离自己最近的关键帧 f n = ⟨ p k 1 , p k 2 , ⋅ ⋅ ⋅ , p k M ⟩ f_{n}=⟨p_{k}^{1},p_{k}^{2},· · ·,p_{k}^{M}⟩ fn=⟨pk1,pk2,⋅⋅⋅,pkM⟩。具体来说使用VLM来对patch进行编码 E p ( ⋅ ) E_{p}(·) Ep(⋅)。思路还是采用上述的相似度-冗余性进行
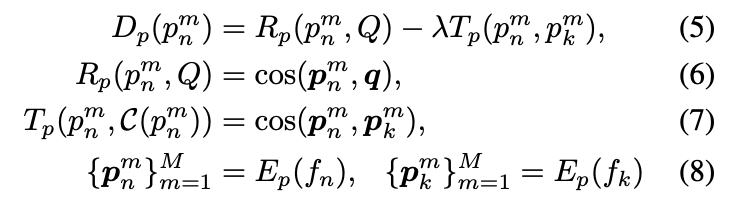
R p ( p n m , Q ) R_{p}(p_{n}^{m},Q) Rp(pnm,Q)就是 p n p_{n} pn这一非关键帧的第 m m m个patch和query的相似度。 T p ( p n m , p k m ) T_{p}(p_{n}^{m}, p_{k}^{m}) Tp(pnm,pkm)就是计算非关键帧 p n p_{n} pn的第 m m m个patch的冗余性,具体来说就是计算其和自己对应的最近关键帧 p k p_{k} pk的第 m m m个patch的相似度(注意是对应的第 m m m个patch),相似度高就代表冗余高。通过上面两个差分就可以得到最终的分数$D_{p}(p_{n}^{m}) $,其代表着当前非关键帧的某一个patch的重要度,越高代表着越重要。
基于 D p ( p n m ) D_{p}(p_{n}^{m}) Dp(pnm)这个量化值就可以动态压缩非关键帧了,具体如下
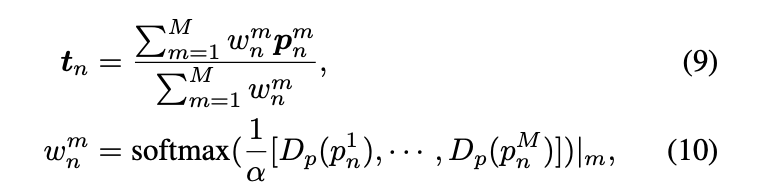
可以看到对当前非关键帧 p n p_{n} pn进行压缩是先计算每一个patch对应的 D p ( p n m ) D_{p}(p_{n}^{m}) Dp(pnm)。然后统一进行softmax得到某一个patch的归一化分数 w n m w_{n}^{m} wnm。然后基于这个分数进行动态加权平均得到一个最终的表征。
现在我们来理一下这里的压缩,假设一帧有729个patch(或者叫729个token)。对于关键帧这些都是要保留的即最终的维度[1,729,d]。而非关键帧是[1,1,d]。可以看到是把729 patch动态动态加权压缩成一个patch,这样就大大减少了最终的token数。
(3)Multimodal Learning
通过上面我们得到了关键帧的表征(所有patch都保留)、非关键帧(所有patch都被动态压缩成一个patch)。因为每一个patch最终都会被映射成一个单独token送到LLM大模型,所以patch总数就是最终的token总数。
本篇讲的压缩其实就将非关键帧的所有token压缩成一个token。其他方面并没有压缩。
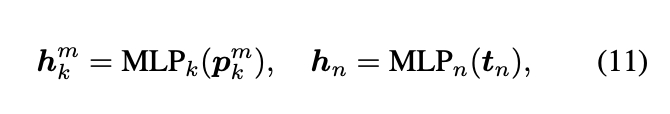
p k m p_{k}^{m} pkm就是关键帧的所有保留的token表征, t n t_{n} tn就是非关键帧被压缩成一个token的表征
在得到关键帧和非关键帧的表征后分别通过一个MLP层进行映射成token送到大模型。假设一共N帧,每帧有M个patch,有K个关键帧。那么总token数是MN,通过对非关键帧的压缩,那总token数就变成了MK +(N −K)其中K≪N(关键帧就那么几帧)
总结
总的来说先通过Differential Keyframe Selection来区分出关键帧和非关键帧。然后就是开始表征每一帧了,关键帧不做任何特殊变化,在非关键帧用Differential Feature Merging来动态压缩表征(压缩token)。
我们可以看到主要一个idea就是考虑冗余性,在计算冗余性方面这里可以探索更多的方法。
关注

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 25
25 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)