
【【大模型推理】SCORPIO: Serving the Right Requests at the Right Time for Heterogeneous SLOs in LLM(第四部)】
基于信用的批处理机制通过TRP动态分配资源,将严格SLO请求的优先级显式编码到信用积累速率中,同时利用信用扣除机制实现细粒度的批次控制。这一方法在保证服务质量的同时,最大化了系统吞吐量。
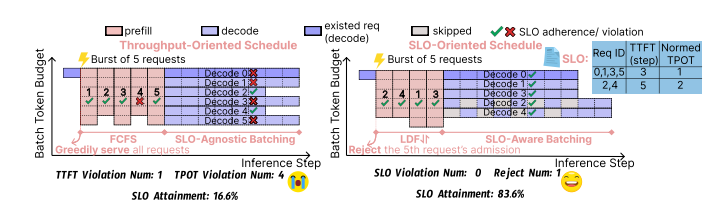
图1:吞吐量导向型与服务等级目标(SLO)导向型调度方法的对比。吞吐量导向型调度器在接纳和处理请求时采取贪婪策略,不考虑单个请求的SLO要求。在预填充阶段,请求4违反了其SLO约束条件(实际耗时4个步骤>允许的3个步骤)。SLO导向型调度器通过优先处理截止时间最近的请求策略避免此类违规。在解码阶段,我们假设归一化解码步骤时间为0.25×批处理规模(BatchSize)。吞吐量导向型调度器在每个步骤均批量处理全部请求(批处理规模=6),导致请求0、1、3、5违反其TPOT约束条件(每个步骤消耗时间为1.5单位)。相比之下,SLO导向型调度器会拒绝无法实现的请求(如请求5),并实施自适应细粒度批处理策略(批处理规模=4)。该策略允许具有较宽松TPOT SLO的请求(请求2和4)跳过某些迭代,从而确保所有被接纳请求均能满足其TPOT约束条件。
3.4 异构TPOT保护模块
关键见解。如图1所示,现有方法无差别接纳所有新到达的请求并在每个步骤中平等处理。这种方法导致两个主要问题:1)当严格TPOT SLO的请求与宽松TPOT SLO的请求竞争时,前者会违反其SLO约束;2)当系统负载超过处理能力时,贪婪服务所有请求会产生级联效应,导致所有请求均无法满足SLO。针对第一个问题,我们设计了一种新型批处理机制,根据请求的TPOT SLO提供差异化的批处理机会(即基于信用的批处理机制)。宽松TPOT SLO的请求获得较少的信用(机会)进行批处理,从而跳过部分执行迭代,为严格TPOT SLO的请求预留更多资源。针对第二个问题,受云计算中负载控制技术启发[20,21],我们引入了一种考虑TPOT SLO异质性的新型准入控制机制:一方面,预估会导致TPOT违规的请求将被拒绝;另一方面,由于宽松TPOT SLO的请求是间歇性服务的,因此在计算批处理规模(即虚拟批处理规模)进行TPOT估算时,可将其视为部分请求(§3.2)。这两种机制共同提供了TPOT保障,如算法1所示。
基于信用的批处理机制(Credit-based Batching)如前所述,为不同TPOT SLO的请求在每次迭代中提供不同的信用(机会)进行批处理。决定请求获得多少信用时,我们首先引入一个称为TPOT相对比例性(TRP)的概念:
定义1(TPOT相对比例性(TRP)):令STP(r)STP(r)STP(r)表示请求r的TPOT SLO。给定当前处理迭代t和运行中请求集合R(t)R(t)R(t),请求r∈R(t)r∈R(t)r∈R(t)的TPOT相对比例性(TRP)定义为:
TRP(r)=minr′∈R(t)STP(r′)/STP(r)TRP(r) = min_{r'∈R(t)} STP(r') / STP(r)TRP(r)=minr′∈R(t)STP(r′)/STP(r)
TRP量化了请求r相较于已接纳请求中最严格TPOT SLO的紧迫程度。需注意TRP会自适应响应工作负载变化。因此,每个请求按其TRP速率获得信用。当累计信用(≥1.0)时,请求可在下一批处理中被纳入批次。此时信用扣除1.0,代表消耗了一个处理机会。形式上,在每次批处理步骤t中,执行以下操作:
• 信用获取:对每个请求r∈R(t),按其TRP速率更新信用:
Cr(t)←Cr(t)+TRP(r)C_r(t) ← C_r(t) + TRP(r)Cr(t)←Cr(t)+TRP(r)
其中C_r(t)为步骤t时请求r的信用(初始值为0)
• 批次选择:将累计信用≥阈值的请求纳入批次:
B(t)=r∈R(t)∣Cr(t)≥1.0B(t) = {r ∈ R(t) | C_r(t) ≥ 1.0}B(t)=r∈R(t)∣Cr(t)≥1.0
• 信用扣除:对B(t)中每个请求r,信用减1.0:
若r∈B(t),则Cr(t)←Cr(t)−1.0C_r(t) ← C_r(t) − 1.0Cr(t)←Cr(t)−1.0
该机制确保经过多轮迭代后,请求r被批处理的频率将收敛至其TRP速率。
基于VBS的准入控制(VBS-based Admission Control)当新请求r到达时,为保障TPOT SLO,直观做法是仅在接纳后不会导致自身或其他运行中请求违反TPOT SLO时才接纳。然而,由于基于信用的批处理机制会使部分请求跳过执行迭代(如前所述),直接使用运行中请求数量作为批处理规模会高估实际系统负载。由于请求r若被接纳,将在每次迭代中获得TRP(r)TRP(r)TRP(r)的机会参与批处理,可视为一个虚拟的TRP(r)TRP(r)TRP(r)请求。令R′(t)=R(t)∪rR'(t)=R(t)∪{r}R′(t)=R(t)∪r,则系统实际负载可投影为所有请求TRP之和,即虚拟批处理规模(VBS):
VBS(R′)=∑r∈R′TRP(r)VBS(R') = ∑_{r∈R'} TRP(r)VBS(R′)=∑r∈R′TRP(r) (8)
若新增请求在步骤t时不会导致预估TPOT超过运行中请求集R’的最小TPOT SLO,则将其接纳至运行队列:
EstimatedTPOT(VBS(R′),Lavg(R′))≤minr′∈R(t)STP(r′)EstimatedTPOT(VBS(R'), L_avg(R')) ≤ min_{r'∈R(t)} STP(r')EstimatedTPOT(VBS(R′),Lavg(R′))≤minr′∈R(t)STP(r′)
该机制保证了被接纳的请求均能遵守其TPOT SLO。

基于信用的批处理机制(Credit-based Batching)详解
核心思想
基于信用的批处理机制通过动态分配“信用”来平衡不同请求的TPOT(Time Per Output Token)SLO(服务等级目标),确保严格SLO的请求优先处理,同时允许宽松SLO的请求间歇性跳过执行,从而优化整体吞吐量并避免SLO违规。
关键概念
-
TPOT相对比例性(TRP)
TRP量化请求的紧迫程度,公式为:
TRP(r)=minr′∈R(t)STP(r′)STP(r) \text{TRP}(r) = \frac{\min_{r' \in R(t)} \text{STP}(r')}{\text{STP}(r)} TRP(r)=STP(r)minr′∈R(t)STP(r′)- STP®:请求$ r $的TPOT SLO(目标TPOT)。
- 最小TPOT:当前运行请求中最严格的TPOT SLO。
- TRP范围:0 < TRP ≤ 1。
- TRP=1:请求具有最严格SLO,需最高优先级处理。
- TRP→0:请求SLO较宽松,处理频率更低。
-
信用积累与扣除规则
- 信用获取:每个迭代周期中,请求按其TRP值积累信用(例如,TRP=0.5 → 每次迭代加0.5)。
- 批次选择:信用≥1.0的请求被纳入下一批处理。
- 信用扣除:被处理的请求信用减1.0(代表消耗一次机会)。
机制流程示例
场景设定
- 请求集合:3个请求(R1, R2, R3),TPOT SLO分别为2、4、6。
- 最小TPOT:当前运行请求中最小STP为2。
- TRP计算:
- R1: TRP = 2/2 = 1.0
- R2: TRP = 2/4 = 0.5
- R3: TRP = 2/6 ≈ 0.333
迭代过程模拟
| 迭代 | 请求 | 信用变化(TRP) | 累计信用 | 处理? | 扣除后信用 |
|---|---|---|---|---|---|
| t=1 | R1 | +1.0 → 1.0 | 是 | 0.0 | |
| R2 | +0.5 → 0.5 | 否 | - | ||
| R3 | +0.333 → 0.333 | 否 | - | ||
| t=2 | R1 | +1.0 → 1.0 | 是 | 0.0 | |
| R2 | +0.5 → 0.5+0.5=1.0 | 是 | 0.0 | ||
| R3 | +0.333 → 0.333+0.333=0.666 | 否 | - | ||
| t=3 | R1 | +1.0 → 1.0 | 是 | 0.0 | |
| R2 | +0.5 → 0.5 | 否 | - | ||
| R3 | +0.333 → 0.666+0.333=1.0 | 是 | 0.0 |
结果分析
- R1(严格SLO):每迭代必被处理(TRP=1.0 → 每次加1.0,立即触发处理)。
- R2(中等SLO):每2次迭代被处理一次(TRP=0.5 → 每次加0.5,2次累计达1.0)。
- R3(宽松SLO):每3次迭代被处理一次(TRP≈0.333 → 每次加0.333,3次累计达1.0)。
优势与效果
- 严格SLO保障
- 高TRP请求(如R1)获得高频处理,确保其TPOT目标(如2步内完成解码)。
- 资源动态分配
- 宽松SLO请求(如R3)主动让出资源,避免与严格SLO请求竞争。
- 吞吐量优化
- 通过限制批次大小(如VBS=4而非6),减少因过载导致的全局SLO违规。
实际应用场景
-
大模型推理服务:
- 用户A(实时聊天):TPOT SLO=1步(TRP=1)。
- 用户B(批量生成):TPOT SLO=4步(TRP=0.25)。
- 结果:用户A每步必被处理,用户B每4步处理一次,确保实时响应不被延迟。
-
云计算负载控制:
- 拒绝无法满足TRP阈值的新请求(如R3若TRP=0.1,信用积累过慢),防止系统过载。
数学收敛性
经过多轮迭代后,请求的处理频率将趋近于其TRP值:
limt→∞处理次数r(t)t=TRP(r) \lim_{t \to \infty} \frac{\text{处理次数}_r(t)}{t} = \text{TRP}(r) t→∞limt处理次数r(t)=TRP(r)
例如,TRP=0.5的请求最终每2步处理1次,TRP=0.333的请求每3步处理1次。
总结
基于信用的批处理机制通过TRP动态分配资源,将严格SLO请求的优先级显式编码到信用积累速率中,同时利用信用扣除机制实现细粒度的批次控制。这一方法在保证服务质量的同时,最大化了系统吞吐量。
TPOT保障机制详解
TPOT(Time Per Output Token)保障机制通过 基于信用的批处理(Credit-based Batching) 和 基于虚拟批处理规模的准入控制(VBS-based Admission Control) 相结合,确保所有被接纳的请求满足其TPOT SLO(服务等级目标),同时最大化系统吞吐量。以下是其核心设计与工作流程的详细解析:
核心设计目标
- 避免SLO违规:严格保障请求的TPOT目标(如低延迟生成)。
- 动态资源分配:根据请求的SLO紧迫性差异化分配资源。
- 防止系统过载:拒绝可能导致全局SLO失效的请求,避免级联失败。
关键组件与流程
1. 准入控制(Admission Control)
目的:在请求进入系统前评估其对整体负载的影响,确保接纳后所有请求仍能遵守TPOT SLO。
核心逻辑:
- 输入:等待队列中的新请求 $ w $,当前运行队列 $ R $。
- 虚拟批处理规模(VBS):
VBS(R′)=∑r∈R′TRP(r) \text{VBS}(R') = \sum_{r \in R'} \text{TRP}(r) VBS(R′)=r∈R′∑TRP(r)
其中 $ R’ = R \cup {w} $,TRP(TPOT相对比例性)量化请求的紧迫性(定义见下文)。 - TPOT预估:
使用模型 $ M $ 和序列长度预测器 $ P $,计算当前负载下的预估TPOT:
EstimatedTPOT(VBS(R′),Lavg(R′)) \text{EstimatedTPOT}(\text{VBS}(R'), L_{\text{avg}}(R')) EstimatedTPOT(VBS(R′),Lavg(R′))
其中 $ L_{\text{avg}} $ 为请求的平均序列长度。 - 接纳条件:
若预估TPOT ≤ 当前运行请求集 $ R’ $ 的最小TPOT SLO(即 $ \min_{r \in R’} \text{STP}® $),则接纳请求 $ w $。
示例:
- 请求 $ w $ 的STP(TPOT SLO)为3步,当前运行请求的最小STP为2步。若接纳后预估TPOT为2.5步,则 $ 2.5 \leq 2 $ 不成立,拒绝 $ w $。
2. 基于信用的批处理(Credit-based Batching)
目的:动态分配执行机会,优先保障严格SLO的请求,允许宽松SLO请求跳过部分迭代。
核心逻辑:
-
TRP(TPOT相对比例性)定义:
TRP(r)=minr′∈R(t)STP(r′)STP(r) \text{TRP}(r) = \frac{\min_{r' \in R(t)} \text{STP}(r')}{\text{STP}(r)} TRP(r)=STP(r)minr′∈R(t)STP(r′)- TRP范围:$ 0 < \text{TRP} \leq 1 $。
- TRP=1:请求具有最严格SLO,需最高优先级处理。
- TRP→0:请求SLO宽松,处理频率低。
-
信用积累与扣除规则:
- 信用获取:每个迭代周期中,请求按其TRP值积累信用(例如,TRP=0.5 → 每次迭代加0.5)。
- 批次选择:信用≥1.0的请求被纳入下一批处理。
- 信用扣除:被处理的请求信用减1.0(代表消耗一次机会)。
数学收敛性:
经过多轮迭代后,请求的处理频率将趋近于其TRP值:
limt→∞处理次数r(t)t=TRP(r) \lim_{t \to \infty} \frac{\text{处理次数}_r(t)}{t} = \text{TRP}(r) t→∞limt处理次数r(t)=TRP(r)
例如,TRP=0.5的请求每2步处理1次,TRP=0.333的请求每3步处理1次。
示例:
- 请求集合:R1(STP=2)、R2(STP=4)、R3(STP=6)。
- TRP计算:
- R1: TRP = 2/2 = 1.0
- R2: TRP = 2/4 = 0.5
- R3: TRP = 2/6 ≈ 0.333
- 信用积累与处理:
- R1每步必被处理(TRP=1.0 → 每次加1.0)。
- R2每2步处理一次(TRP=0.5 → 每次加0.5,2次累计达1.0)。
- R3每3步处理一次(TRP≈0.333 → 3次累计达1.0)。
整体流程(Algorithm 1)
- 主循环:持续运行以处理动态请求流。
- 初始化批处理集合:每轮迭代开始时清空批处理集合 $ B $。
- 准入控制阶段:
- 尝试将等待队列 $ W $ 中的请求 $ w $ 接入运行队列 $ R $。
- 计算新队列 $ R’ $ 的虚拟批处理规模(VBS)和平均序列长度($ L_{\text{avg}} $)。
- 预估TPOT是否满足所有请求的最小TPOT SLO。若满足,接纳 $ w $。
- 信用批处理阶段:
- 所有运行中请求按其TRP速率积累信用。
- 信用≥1.0的请求被纳入批次 $ B $,并扣除1.0信用。
- 结束循环:重复上述步骤,持续优化资源分配。
优势与效果
- 严格SLO保障:高TRP请求(严格SLO)获得高频处理,确保其TPOT目标。
- 资源动态分配:宽松SLO请求主动让出资源,避免与严格SLO请求竞争。
- 吞吐量优化:通过限制批次大小(如VBS=4而非6),减少因过载导致的全局SLO违规。
- 抗过载能力:拒绝潜在违规请求(如TRP过低的新请求),防止系统崩溃。
实际应用场景
-
大模型推理服务:
- 用户A(实时聊天):TPOT SLO=1步(TRP=1)。
- 用户B(批量生成):TPOT SLO=4步(TRP=0.25)。
- 结果:用户A每步必被处理,用户B每4步处理一次,确保实时响应不被延迟。
-
云计算负载控制:
- 拒绝无法满足TRP阈值的新请求(如TRP=0.1,信用积累过慢),防止系统过载。
总结
TPOT保障机制通过 TRP动态分配资源 和 VBS精准评估负载,将严格SLO请求的优先级显式编码到信用积累速率中,同时利用信用扣除机制实现细粒度的批次控制。这一方法在保证服务质量的同时,最大化了系统吞吐量,适用于大模型推理、实时服务等场景。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 17
17 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)