
LLaMA-Factory训练自己的大模型
LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。
·
LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。
今天咱们来试着走下整个流程。
1、首先下载代码
git clone https://github.com/hiyouga/LLaMA-Factory.git2、安装环境
conda create -n llama python==3.10conda activate llamapip install -e ".[torch,metrics]"
安装竟然非常顺利,没有报错。
3、export 下huggingface镜像,后面要从上面下载模型
export HF_ENDPOINT=https://hf-mirror.com4、启动webui界面,通过web端去训练模型
export USE_MODELSCOPE_HUB=1 && llamafactory-cli webui5、启动效果如下

默认端口7860,可以在同一网络打开平台地址。
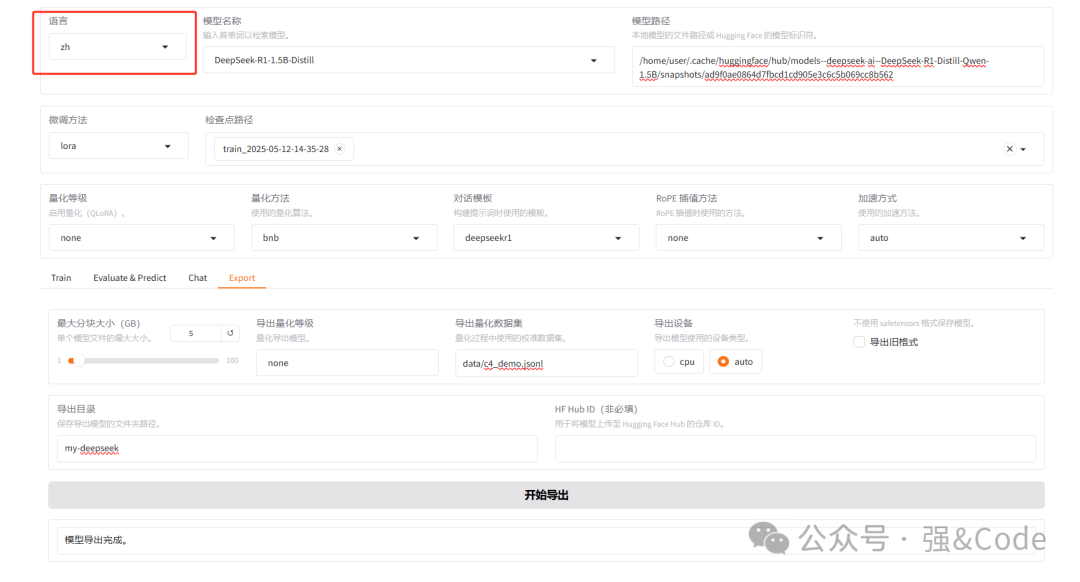
选择语言,界面可切换语言。
6、系统搭建好了,咱们试着用一个模型训练下。我选择的deepseek-r1 1.5b的。
系统默认会下载你选择的模型。模型下载好后,在模型路径填写模型地址。
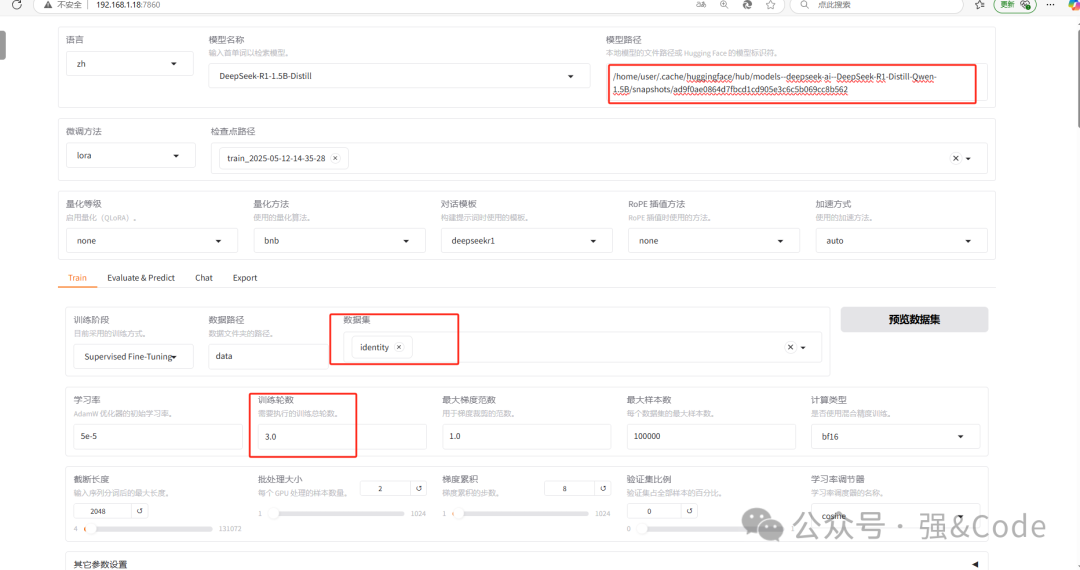
选择系统提供默认的数据集,选择训练轮数,点击开始就开始训练了。
7、过程很顺利,训练很快完成了。
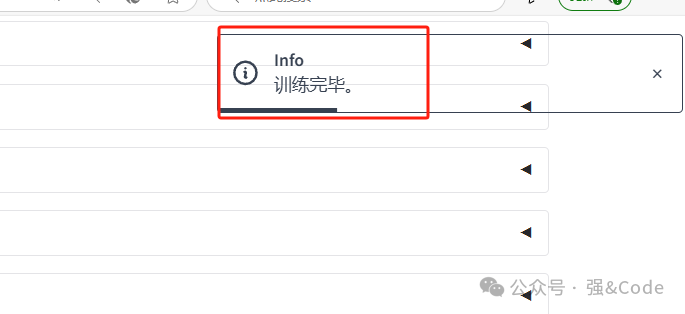
8、可以在线测试下。选择chat,点击加载模型就可以在线测试了。
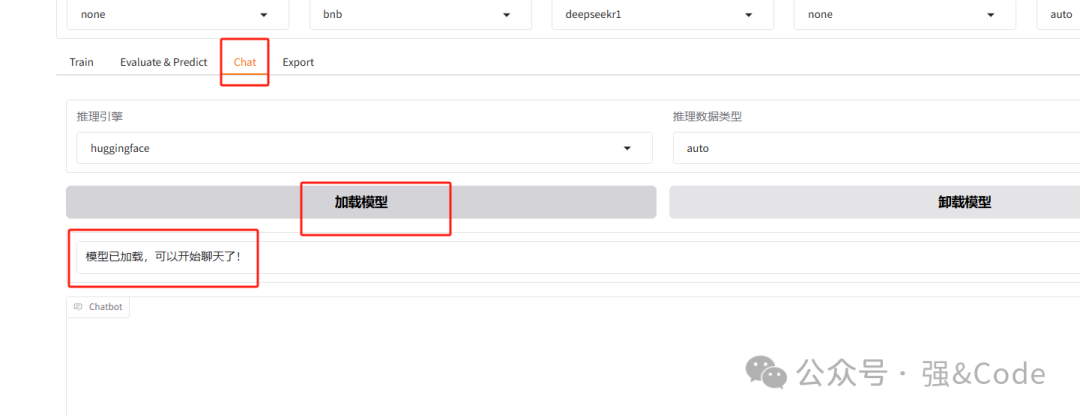
9、如果想对外使用怎么弄呢?咱们可以使用ollama。首先安装ollama
curl -fsSL https://ollama.com/install.sh | sh10、安装好后咱们把训练好的模型导出,填写下导出目录。
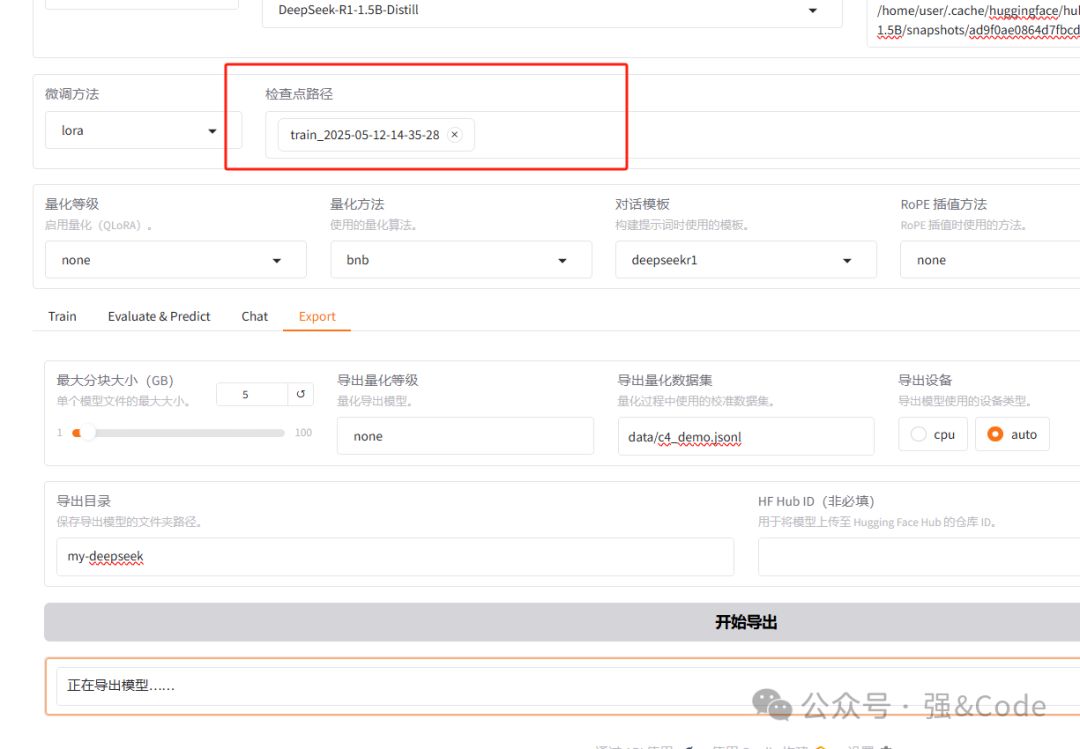
11、使用ollama创建下。
ollama create my-deepseek -f ~/shuziren/LLaMA-Factory/my-deepseek/Modelfile12、使用ollama试着跑下
ollama run my-deepseek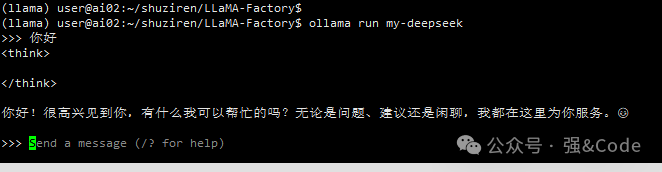
OK,完美运行。
这就是我本地试着训练大模型的步骤方法,大家在使用的过程中有什么问题或者有什么想复现的平台的话欢迎公众号留言,大家一起讨论学习。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)