
【大模型微调】2.微调方法详解与模型显存占用实测
【大模型微调】2.微调方法详解与模型显存占用实测
引言
前文在 Windows 环境下打通模型 SFT 微调流程后,本文进一步在 Linux 服务器上进行实验。
LLaMA-Factory 给了一则不同模型精度和训练方法所需显存的参考表。
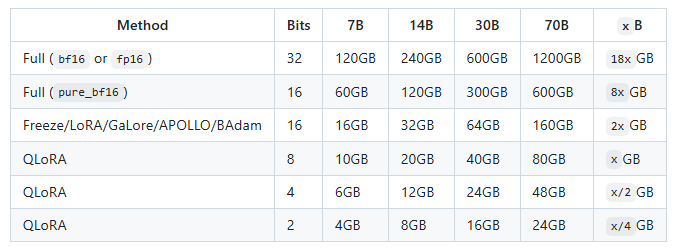
此表的显存是估计值,本文将在真实设备上,实际测试一下不同模型的显存占用情况。
训练方法总结
在实际测试前,有必要先梳理一下基本的训练方法,以避免在后续实验中不理解参数的具体含义。
这里的基本的训练方法参照 LLaMA-Factory 官方文档作为划分依据,不包含 LLaMA-Factory 支持以外的其它方法。
LLaMA-Factory 官方文档地址:https://github.com/hiyouga/LLaMA-Factory
训练方法按照训练阶段,可分为预训练(Pre-training)和后训练(Post-training)。
1. 预训练
预训练是指通过大型的通用数据集,让大语言模型来学习语言的表征/初始化模型权重/学习概率分布。
这是偏学术说法,说得通俗点,如果将训练大模型的过程比作教育孩子,预训练就是让他进小学学一些通识课,先学会怎么识字说话,这样后面报兴趣班,学专业课就更容易了。
预训练这个过程增强的是模型通用能力,对于普通人来说,无需再进行预训练,只需要把现有已经预训练完成的模型拿来做后训练就行了。
2. 后训练
后训练是指通过某些方法来使得模型在特定任务上也有足够好的表现。
具体有以下方式。
(1) 监督微调(Supervised Fine-Tuning)
这就是通常说的模型微调,通过小规模的标签数据集对模型进行微调训练。
(2) 基于人类反馈的强化学习(RLHF)
RLHF(Reinforcement Learning from Human Feedback) 是指通过人类反馈来进一步微调模型,使将模型行为与用户需求对齐(alignment),从而让模型能够更好更安全地遵循用户指令。
RLHF 包含以下两个步骤:
-
构建奖励模型(Reward model)
因为人类的真实反馈很难获取,所以可以训练一个奖励模型代替人类对语言模型的输出进行评价。为了训练这个奖励模型,需要让奖励模型获知人类偏好,这通常通过输入经过人类标注的偏好数据集来实现。在偏好数据集中,数据由三部分组成:输入、好的回答、坏的回答。 -
近端策略优化(PPO)
PPO(Proximal Policy Optimization)是一个比较经典的强化学习算法,语言模型接受 prompt 作为输入,其输出作为奖励模型的输入。奖励模型评价语言模型的输出,并将评价返回给语言模型。这一步的目的是让语言模型的输出能够尽可能地获得奖励模型的高评价,又不希望语言模型的变化过于“激进”。PPO并不是不可替代的算法,DeepSeek-R1的训练过程中就用了GRPO。
(3) 直接偏好优化(DPO)
RLHF需要同时保证语言模型与奖励模型都能良好工作,这并不容易。DPO(Direct Preference Optimization)这种方法丢弃奖励模型,直接构造了一个基于人类偏好对比的损失函数,大大简化了训练过程。
(4) 前景理论优化(KTO)
KTO(Kahneman-Taversky Optimization)是DPO的一种变体,通过引入了行为经济学中 Kahneman 和 Tversky 提出的“前景理论”思想,使用了一种新的损失函数使其只需二元的标记数据,对人类偏好的非对称性建模会更精细。
调优算法总结
LLaMA-Factory 包含多种调优算法:
(1) 全参微调(Full Parameter Fine-tuning)
全参微调指的是在训练过程中对于预训练模型的所有权重都进行更新,显存需求很大。
(2) 冻结微调(Freeze)
冻结微调指的是冻结部分模型参数,只对其它部分的模型参数进行微调,这样会减少显存要求。具体的冻结层可通过参数去设置。
(3) LoRA(Low-Rank Adaptation)
LoRA 是一种高效微调技术,它通过冻结预训练模型的参数并引入少量可训练的低秩矩阵,实现了在显著减少计算资源需求的同时保持模型性能的目标。
LoRA的核心思想是通过低秩分解来模拟参数更新矩阵。
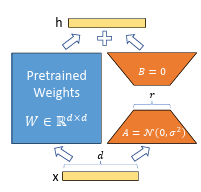
图源自LoRA论文:LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
以 attention 中的权重矩阵 为例,LoRA 将其替换为:
其中:矩阵 A 的维度为 ,矩阵 B 的维度为
因此,通过低秩分解中的秩,就可以实现训练参数量的降低。
举个例子,假设上面的 d 和 k 是 512。
那么直接训练 W 需要 512 x 512 = 262144个参数。
如果设定 r = 8,那么A矩阵和B矩阵总共只包含 512 x 8 + 8 x 512 = 8192个参数,参数量近是占原始的 3.1%。
如果不了解矩阵乘法,理解起来会有点抽象,举个形象的例子:
❝把原始权重看成是一个很大的玻璃门(比如 512×512),全参微调是把整个门拆下来重做。LoRA 的方式是:不动原来的门,只在门上贴一层很薄的贴膜(一个小矩阵),通过贴膜调整光线(输出结果)。
(4) LoRA+
在 LoRA 中,适配器矩阵 A 和 B 的学习率相同。在 LoRA+ 中,可以为适配器矩阵 A 和 B 单独添加不同的学习率。
(5) rsLoRA+
rsLoRA(Rank-Stabilized LoRA) 通过修改缩放因子使得模型训练更加稳定。
(6) DoRA+
DoRA (Weight-Decomposed Low-Rank Adaptation)将权重矩阵分解为大小与单位方向矩阵的乘积,并进一步微调二者(对方向矩阵则进一步使用 LoRA 分解),从而实现 LoRA 与全参数微调之间的平衡。
(7) PiSSA+
PiSSA(Principal Singular values and Singular vectors Adaptation)通过奇异值分解直接分解原权重矩阵进行初始化,使 LoRA 更快更好地收敛。
(8) Galore
GaLore(Gradient Low‑Rank Projection) 是一种针对大模型训练中的内存瓶颈提出的创新方法。与常见的 LoRA 不同,GaLore 不是对模型权重做低秩变换,而是对梯度本身进行低秩投影,允许训练时显著节省优化器所需的内存。
(9) BAdam
BAdam是一种内存高效的全参优化方法,将模型分解成多个互不重叠的块,每次仅对一个块执行 Adam 优化,其余块被冻结 ,从而减少内存需求。
配置参数解读
在前文中,通过 webui 来设定训练参数,实际上只是通过可视化交互的方式来修改具体配置文件的信息。
在服务器上,直接修改配置更加方便快捷。完整的配置参数可查阅官方文档,官方文档写的参数比较分散,这里按照配置文件的顺序进行解读。
在examples文件夹中,官方给了示例的配置文件,每个配置文件分以下几个部分:
model:
-
model_name_or_path:模型名称或本地路径
-
trust_remote_code:是否信任来自 Hub 上数据集/模型的代码执行
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
trust_remote_code: true
method:
-
stage:训练阶段, sft是监督微调,其它还有预训练pt,奖励模型rm等
-
do_train:true用于训练, false用于评估
-
finetuning_type:微调方式,full,freeze或lora
-
deepspeed:用于单机多卡或多机多卡的配置文件
### method
stage: sft
do_train: true
finetuning_type: full
deepspeed: examples/deepspeed/ds_z3_config.json
dataset:
-
dataset:用于训练的数据集名称
-
template:训练和推理时构造 prompt 的模板,具体模板信息可以在
src/llamafactory/data/template.py中看到 -
cutoff_len:输入的最大 token 数,超过该长度会被截断。
-
max_samples: 每个数据集的最大样本数
-
overwrite_cache: 是否覆盖缓存的训练和评估数据集
-
preprocessing_num_workers: 预处理时使用的进程数量
-
dataloader_num_workers: 用于数据加载的子进程数量
### dataset
dataset: identity,alpaca_en_demo
template: llama3
cutoff_len: 2048
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4
output:
-
output_dir:输出模型路径
-
logging_steps:日志输出步数间隔
-
save_steps:模型断点保存间隔
-
plot_loss: 是否保存训练过程中的损失曲线。
-
overwrite_output_dir: 是否允许覆盖输出目录
-
save_only_model: 仅保存模型权重
-
report_to: 保存训练记录的平台,可选TensorBoard、Wandb、MLflow
### output
output_dir: saves/llama3-8b/full/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none
train:
-
per_device_train_batch_size: 每个设备上训练的批次大小
-
gradient_accumulation_steps: 梯度积累步数
-
learning_rate: 学习率
-
num_train_epochs: 训练周期数
-
lr_scheduler_type: 学习率曲线
-
warmup_ratio: 学习率预热比例
-
bf16: 是否使用 bf16 格式
-
ddp_timeout: ddp超时时间
-
resume_from_checkpoint: 从中断点恢复训练
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 1.0e-5
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null
eval:
-
eval_dataset: 用于评估的数据集名称
-
val_size: 验证集相对所使用的训练数据集的大小,取值在(0,1)之间
-
per_device_eval_batch_size: 每个设备上评估时使用的批次大小
-
eval_strategy: 评估触发的策略, step是根据一定步骤进行评估
-
eval_steps: 指定每隔多少训练步骤执行一次评估
### eval
eval_dataset: alpaca_en_demo
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
实践测试
1. 测试准备
下面开始在服务器上进行实际测试,测试环境为 RTX4090 48GB * 8,操作系统为 ubuntu 24.04。
可直接通过examples里面的配置直接开始训练。
llamafactory-cli train examples/train_full/llama3_full_sft.yaml
实测发现,用配置文件还不如 webui 省力,因为配置文件的示例参数模板并不全,也无法直观看到每个参数的可选项,因此后面配置还是采用 webui。
llamafactory-cli webui
webui 中的 DeepSpeed Stage 这个值默认是关闭的,这会导致训练时把所有显存集中到单卡上,导致显存溢出。
DeepSpeed 是为大模型训练加速和显存优化开发的核心技术,分为多个阶段(stage 0~3),每一阶段解决不同的资源瓶颈。
|
Stage |
特性 |
节省资源 |
适合任务 |
|---|---|---|---|
| 0 |
不使用 ZeRO,仅普通的 DDP |
🚫 |
基础并行 |
| 1 |
优化器状态分片 |
✅ 优化器状态 |
微调 |
| 2 |
优化器状态 + 梯度分片 |
✅ 优化器 + 梯度 |
中等规模训练 |
| 3 |
优化器 + 梯度 + 模型参数都分片 |
✅ 所有 |
极大模型训练 |
webui中,DeepSpeed的可选项有 Stage 2 和 Stage 3,两者的区别如下:
|
特性 |
Stage 2 |
Stage 3 |
|---|---|---|
|
参数是否分片 |
❌(每卡全量) |
✅(跨卡分片) |
|
优化器状态是否分片 |
✅ |
✅ |
|
梯度是否分片 |
✅ |
✅ |
|
显存节省程度 |
中等(2~3 倍) |
最多(最多 10 倍) |
|
训练速度 |
快(接近 DDP) |
慢(参数通信较多) |
|
适合模型规模 |
<30B 模型 |
>30B 模型 |
|
配置复杂度 |
中等 |
高(需更多参数) |
|
通常是否配合 offload 使用 |
可选 |
常见(CPU or NVMe) |
因此,在后续测试时,手动设置DeepSpeed Stage设置为3。
DeepSpeed选项手动设置为3
此外,下面的测试精度均采用 bf16,这会在训练时默认开启混合精度训练,对于普通的线性层、卷积层采用bf16,对于loss计算等相关层采用fp32。
由于 Xorg 初始占用了一部分显存(约0.13GB),后面的显存统计中,涵盖该部分显存,实际训练显存占用需扣除该部分。
初始显存占用情况
1. DeepSeek-R1-1.5B 测试
下面先拿小参数的DeepSeek-R1-1.5B模型进行测试。
全参微调,显存占用约77.03GB。

全参微调显存占用情况
冻结微调(默认只微调最后两层),显存占用约38.92GB。
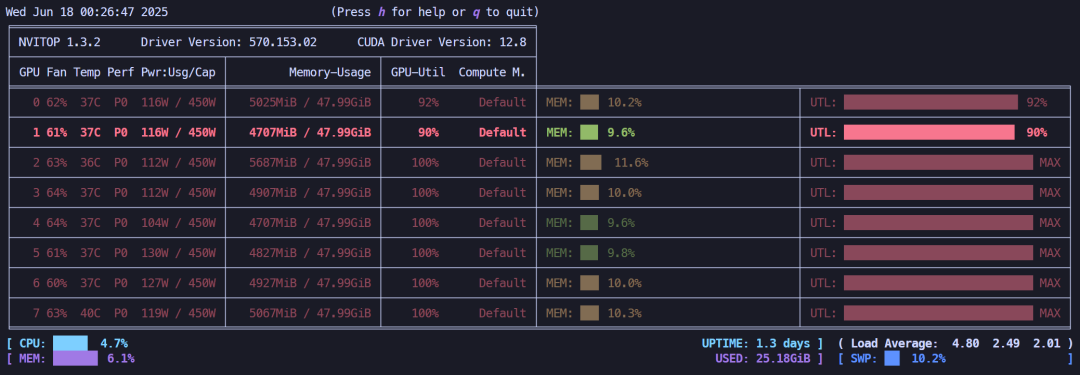
冻结微调显存占用情况
LoRA 4位微调,显存占用约32.97GB。
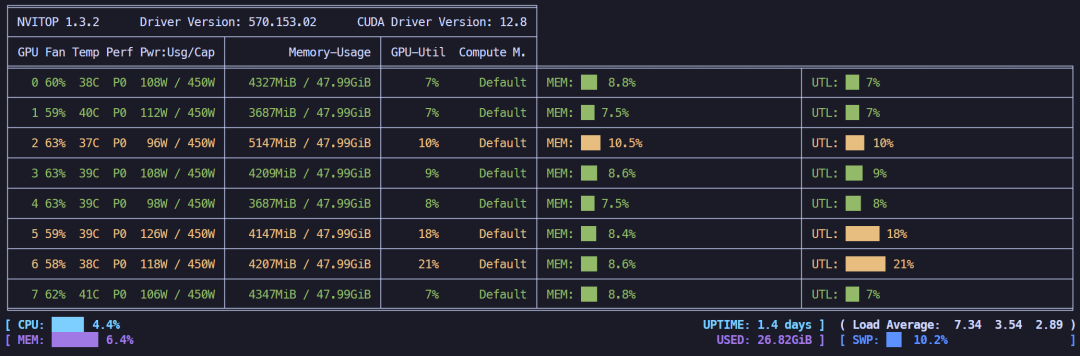
LoRA4位微调显存占用情况
下面再试一下开启 offload 策略,offload 是指在深度学习训练中,将部分模型参数或中间计算从 GPU 转移到 CPU(或 NVMe 磁盘) 的技术,主要用于节省 GPU 显存(memory),会导致训练速度变慢,属于时间换空间的策略。
LoRA 4位微调 + offload策略,显存占用约30.97GB,显存占用提升不明显。
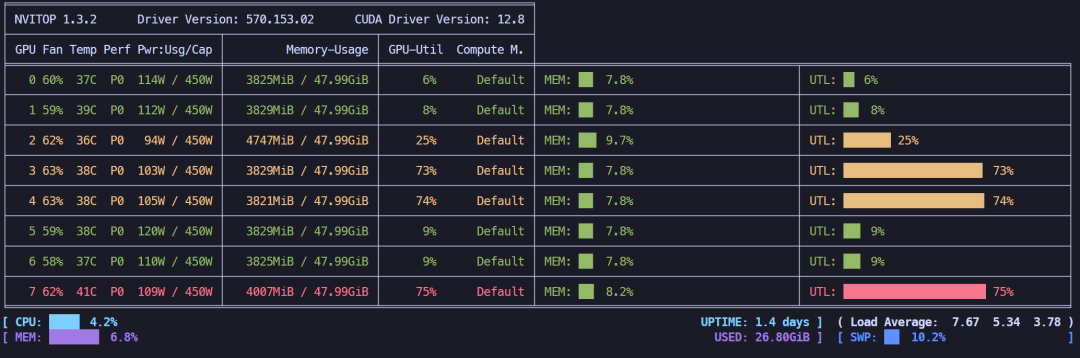
LoRA 4位微调 + offload策略,显存占用情况
下面可以再进一步节省显存,默认的批处理大小(batchsize为2),可以调整为1。
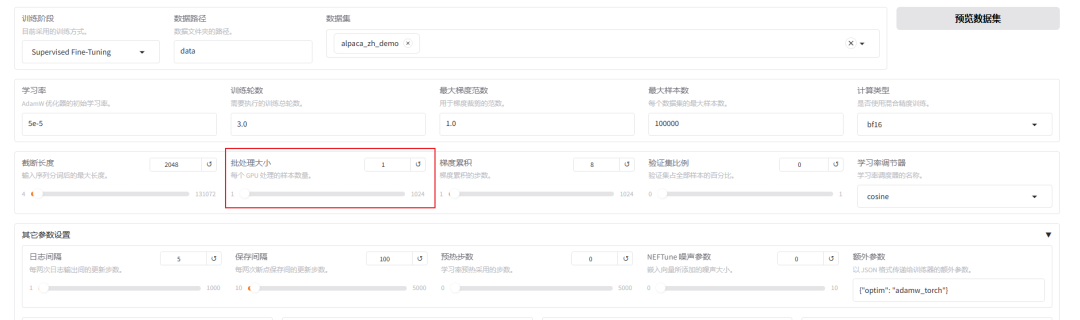
batchsize 2->1
LoRA 4位微调 + offload + batchsize 2->1,显存占用约29.77GB,节省得不多。
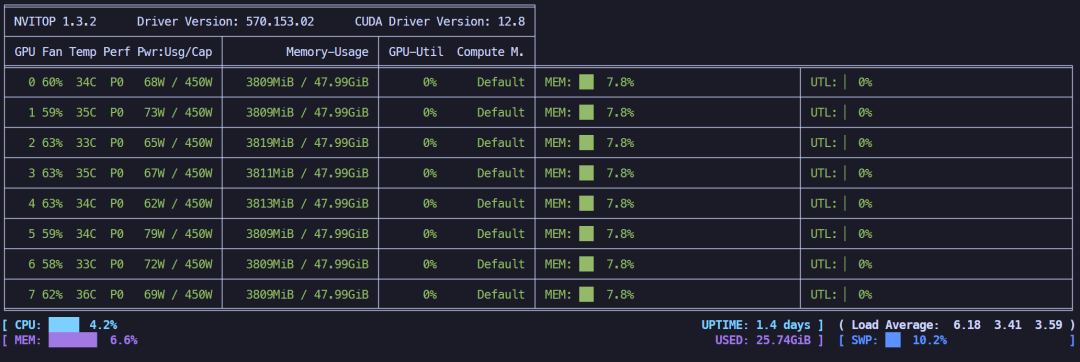
LoRA 4位微调 + offload + batchsize=1 显存占用情况
2. DeepSeek-R1-32B 测试
下面拿中规模的DeepSeek-R1-32B模型进行测试。
全参微调刚加载完模型,开始训练后就爆显存,基本上处于临界点。

全参微调刚加载完模型,显存占用情况
冻结微调,显存占用约133.75GB。
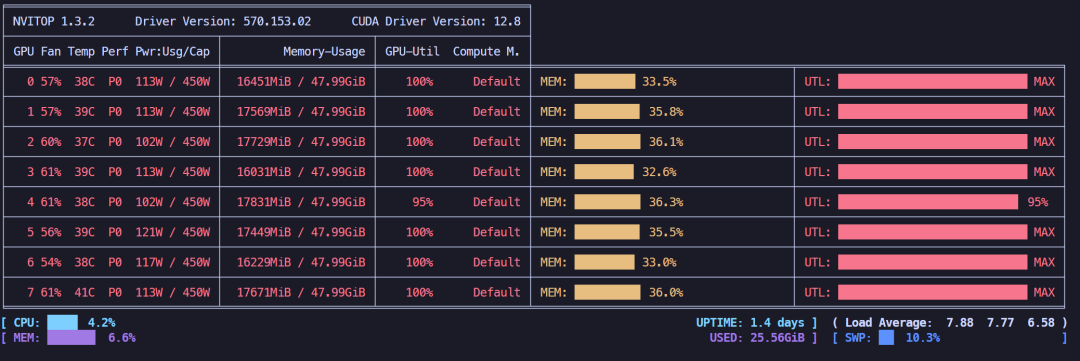
冻结微调显存占用情况
LoRA 4位微调,显存占用约75.42GB。

LoRA4位微调显存占用情况
LoRA 4位微调 + offload策略,显存占用约188.8GB,显存不减反增,可能存在模型重复存储的问题。
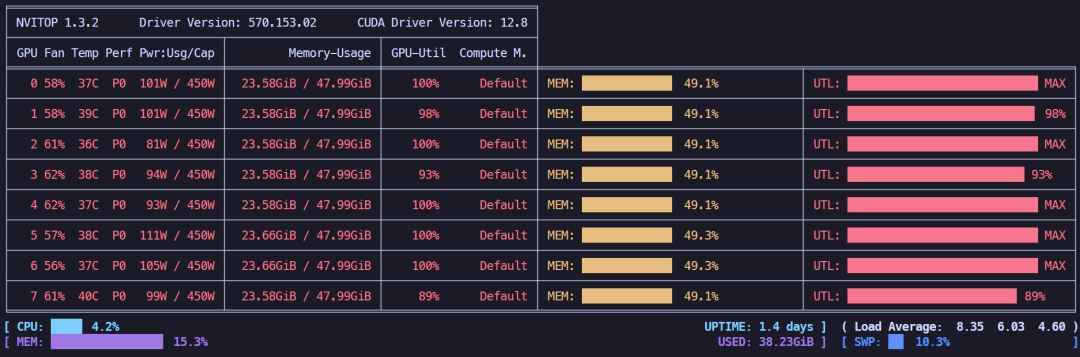
LoRA 4位微调 + offload策略,显存占用情况
3. Qwen-VL-7B 测试
下面再拿多模态模型 Qwen-VL-7B 进行测试,测试数据集选择 LLaMA-Factory 自带的多模态数据集 mllm_demo。
全参微调,显存占用约135GB。
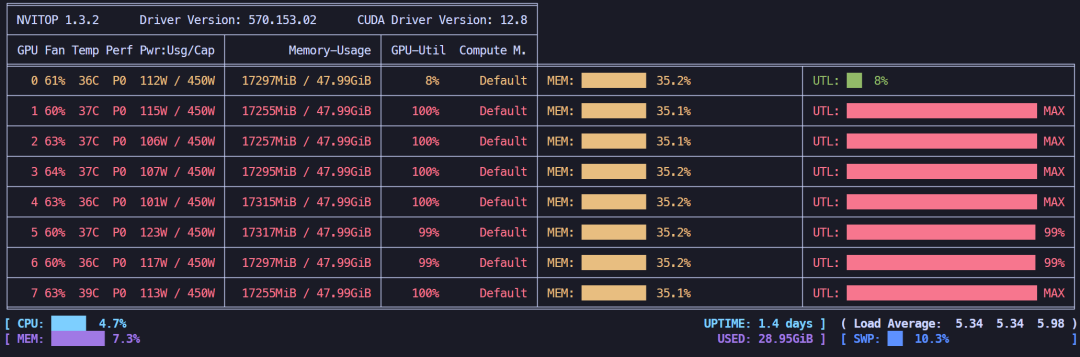
全参微调显存占用情况
冻结微调,显存占用约70.49GB。

冻结微调显存占用情况
LoRA 4位微调,显存占用约47.92GB。

LoRA4位微调显存占用情况
LoRA 4位微调 + offload策略,显存占用约82.14GB,显存不减反增,和上面存在相同的问题。
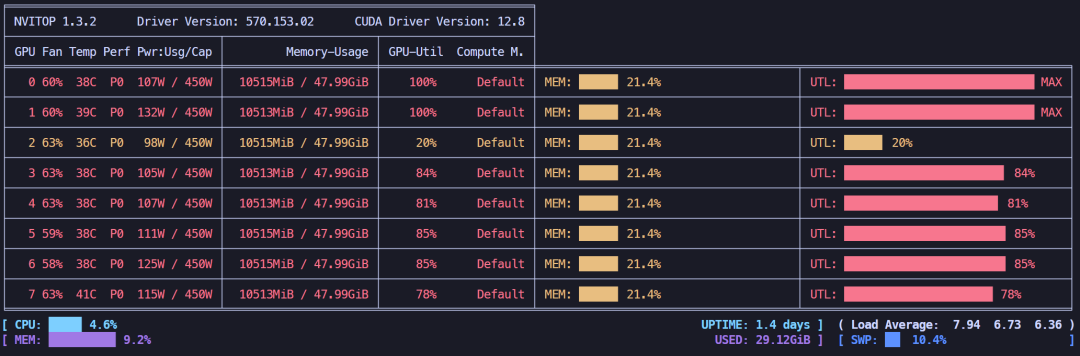
LoRA 4位微调 + offload策略,显存占用情况
总结
把上面的实验内容归纳一下,结果如下表所示,由于 offload 存在异常,不纳入统计范围。
|
模型 |
微调方式 |
显存占用 (GB) |
|---|---|---|
|
DeepSeek-R1-1.5B |
全参微调 |
77.03 |
|
DeepSeek-R1-1.5B |
冻结微调 |
38.92 |
|
DeepSeek-R1-1.5B |
LoRA 4bit微调 |
32.97 |
|
DeepSeek-R1-32B |
全参微调 |
-- |
|
DeepSeek-R1-32B |
冻结微调 |
133.75 |
|
DeepSeek-R1-32B |
LoRA 4bit微调 |
75.42 |
|
Qwen-VL-7B |
全参微调 |
135.00 |
|
Qwen-VL-7B |
冻结微调 |
70.49 |
|
Qwen-VL-7B |
LoRA 4bit微调 |
47.92 |
回到开篇提到的 LLaMA-Factory 给出的微调所需显存参考表,会发现此表严重低估了显存占用情况。
模型微调的显存占用很难直接通过简单的模型参数量换算去推断,因为和模型本身的结构有很大关系。
下一步将通过构建数据集的方式,进一步明确不同的微调方式,对结果有何影响。同时,LLaMA-Factory 提供的 QLora 微调方式,实际需要搭配 AWQ 等量化模型使用,后文也会进一步对此探究。
如何学习AI大模型 ?
“最先掌握AI的人,将会晚掌握AI的人有竞争优势,晚掌握AI的人比完全不会AI的人竞争优势更大”。 在这个技术日新月异的时代,不会新技能或者说落后就要挨打。
老蓝我作为一名在一线互联网企业(保密不方便透露)工作十余年,指导过不少同行后辈。帮助很多人得到了学习和成长。
我是非常希望可以把知识和技术分享给大家,但苦于传播途径有限,很多互联网行业的朋友无法获得正确的籽料得到学习的提升,所以也是整理了一份AI大模型籽料包括:AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、落地项目实战等 免费分享出来。
AI大模型学习路线图
100套AI大模型商业化落地方案
100集大模型视频教程
200本大模型PDF书籍
LLM面试题合集
AI产品经理资源合集

大模型学习路线
想要学习一门新技术,你最先应该开始看的就是学习路线图,而下方这张超详细的学习路线图,按照这个路线进行学习,学完成为一名大模型算法工程师,拿个20k、15薪那是轻轻松松!

视频教程
首先是建议零基础的小伙伴通过视频教程来学习,其中这里给大家分享一份与上面成长路线&学习计划相对应的视频教程。文末有整合包的领取方式

技术书籍籽料
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,这里也分享一份我学习期间整理的大模型入门书籍籽料。文末有整合包的领取方式

大模型实际应用报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。文末有整合包的领取方式

大模型落地应用案例PPT
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。文末有整合包的领取方式

大模型面试题&答案
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。文末有整合包的领取方式

领取方式
这份完整版的 AI大模型学习籽料我已经上传CSDN,需要的同学可以微⭐扫描下方CSDN官方认证二维码免费领取!
。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 8
8 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)