
深度解析【大模型】 RAG 检索增强生成技术
Retrieve():检索模块,从知识库中获取相关文档集合\(D=\{d_1, d_2, ..., d_k\}\)Gen():生成模块,结合 Query 和文档集合\(D\)生成最终回答RAG 技术的落地不是简单的模块拼接,而是需要结合领域特性进行深度调优。从检索策略到生成控制,每个环节的微小改进都可能带来显著的效果提升。建议开发者从具体业务场景出发,先构建最小可行产品(MVP),通过用户反馈持续
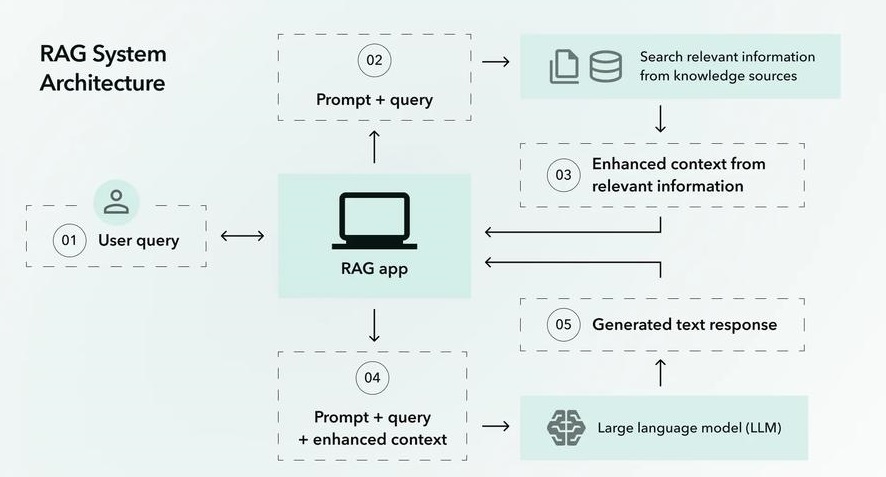
在大模型落地过程中,RAG 检索增强生成已成为解决知识时效性、领域专业性和事实准确性的核心技术。
一、RAG 技术核心原理:三模块协同工作机制
1. RAG 技术公式化定义
\(Response = Gen(Retrieve(Query, KnowledgeBase), Query)\)
- Retrieve():检索模块,从知识库中获取相关文档集合\(D=\{d_1, d_2, ..., d_k\}\)
- Gen():生成模块,结合 Query 和文档集合\(D\)生成最终回答
2. 解决大模型三大痛点
|
痛点类型 |
传统大模型问题 |
RAG 解决方案 |
|
知识过时 |
数据截止到 2023 年 |
对接实时数据库 / API(如股票行情、政策文件) |
|
领域盲区 |
缺乏医疗 / 法律术语理解 |
构建领域专属知识库(如 ICD-11 疾病库、公司法条库) |
|
事实错误 |
生成无依据内容 |
强制基于检索文档生成,输出包含证据引用 |
二、检索模块:从基础到进阶的实现指南
1. 基础检索技术选型
(1)关键词检索(适合明确 query 场景)
- 工具选择:Elasticsearch(支持复杂查询语法)、Lucene(轻量化)
- 最佳实践:
|
# Elasticsearch关键词检索示例 from elasticsearch import Elasticsearch es = Elasticsearch("http://localhost:9200") query = { "query": { "match": { "content": "如何申请专利" } } } res = es.search(index="legal_knowledge", body=query) |
(2)向量检索(核心解决语义匹配)
- 向量化模型选择:
-
- 通用:Sentence-BERT(all-MiniLM-L6-v2,兼顾速度与精度)
-
- 领域专用:BioBERT(医疗)、LexGLUE(法律)
- 向量数据库对比:
|
数据库 |
优势场景 |
数据规模 |
延迟 |
典型应用 |
|
FAISS |
本地部署 |
<100 万 |
低 |
中小规模知识库 |
|
Milvus |
分布式 |
100 万 - 10 亿 |
中 |
企业级应用 |
|
Pinecone |
全托管 |
动态扩容 |
低 |
云端 SaaS 服务 |
- 向量检索代码实现(Milvus 版):
|
from pymilvus import MilvusClient client = MilvusClient(uri="https://api.pinecone.io", api_key="xxx") # 插入文档向量 client.upsert( index_name="legal_index", vectors=[doc_embedding], metadatas=[{"source": "专利法第2条", "page": 15}] ) # 查询 results = client.query( index_name="legal_index", query_embeddings=query_embedding, top_k=5 ) |
2. 检索优化技术
(1)Query 改写(提升召回率)
- 方法:使用大模型生成 query 的同义表达
|
# 通过GPT-4进行query改写 prompt = f"将以下用户问题改写为3个语义相同的查询:{user_query}" responses = openai.ChatCompletion.create( model="gpt-4", messages=[{"role": "user", "content": prompt}] ) expanded_queries = [choice.message['content'] for choice in responses.choices] |
(2)重排序(提升准确率)
- 模型选择:使用交叉编码器(如 BERT-based 的 Sentence-BERT 重排序模型)
|
from sentence_transformers import CrossEncoder re_ranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2') scores = re_ranker.predict([(query, doc) for doc in retrieved_docs]) # 按分数排序 ranked_docs = [doc for _, doc in sorted(zip(scores, retrieved_docs), reverse=True)] |
三、增强模块:知识预处理与融合的关键技术
1. 文档分块策略(影响检索精度的核心)
(1)分块方法对比
|
方法 |
优势 |
适用场景 |
实现注意 |
|
固定窗口 |
简单高效 |
新闻、博客 |
窗口大小建议 500-1000 字 |
|
语义分块 |
保持知识完整性 |
法律合同、技术手册 |
基于标点 / 标题检测(spaCy 库) |
|
动态分块 |
内容自适应 |
混合类型文档 |
结合文本密度算法(如 TF-IDF 阈值) |
(2)分块工具推荐
- spaCy:用于检测句子边界和段落结构
- LangChain Text Splitter:支持多种分块策略(RecursiveCharacterTextSplitter 优先保留句子完整性)
2. 知识融合技术
(1)证据链构建(跨文档知识整合)
- 方法:通过文档元数据(如 "法律 - 公司法 - 第 3 章")建立层级关联,使用图数据库(Neo4j)存储知识网络
(2)冲突消解(多源数据处理)
- 规则引擎:定义数据优先级(如企业内部文档 > 行业标准 > 通用知识)
|
# 冲突消解规则示例 def resolve_conflict(docs): internal_docs = [doc for doc in docs if doc.metadata['source'] == 'internal'] if internal_docs: return internal_docs[0] # 优先使用内部文档 else: return docs[0] |
四、生成模块:从 Prompt 设计到模型调用的最佳实践
1. Prompt 工程三要素
(1)示例注入(Few-Shot 学习)
|
[系统指令]:你是企业客服,回答需引用知识库章节 [示例]: Q:退货流程是什么? A:根据《售后服务手册》第2章第3条,退货需先在APP提交申请,审核通过后寄回商品... [用户问题]:电池保修期限是多久? |
(2)结构化输出控制
- 使用 JSON Schema 约束:
|
{ "type": "object", "properties": { "answer": {"type": "string"}, "source": {"type": "string", "description": "知识库章节引用"} }, "required": ["answer", "source"] } |
(3)温度参数控制
- 低温度(0.1-0.3):生成确定答案(如客服、医疗诊断)
- 中温度(0.5-0.7):生成创意内容(如文案创作、报告大纲)
2. 大模型调用策略
(1)单阶段调用(简单场景)
|
# 将检索结果拼入prompt prompt = f"用户问题:{query}\n参考文档:{docs_content}\n请根据以上信息回答:" response = model.generate(prompt) |
(2)级联调用(复杂场景)
- 首先生成回答大纲
- 按大纲分段生成具体内容
- 最后进行内容整合
|
# 级联调用示例(法律文书生成) outline = model.generate(f"根据{docs}生成离婚协议大纲") for section in outline: content = model.generate(f"撰写{section}部分,要求引用《民法典》条款") |
五、工程落地:从 0 到 1 搭建 RAG 系统
1. 实施流程图
|
graph TD A[数据准备] --> B[文档预处理] B --> C[知识库构建(向量数据库)] C --> D[检索模块开发] D --> E[生成模块适配] E --> F[端到端测试] F --> G{是否达标?} G --是--> H[部署上线] G --否--> I[优化迭代] |
2. 关键环节技术点
(1)数据准备
- 格式支持:PDF(PyPDF2 解析)、Word(python-docx)、网页(BeautifulSoup 爬取)
- 数据清洗:去除重复内容、敏感信息脱敏(医疗数据需符合 HIPAA)
(2)模型适配
- 轻量化微调:使用 LoRA 技术(仅训练 0.1% 参数),降低计算成本
|
# Hugging Face LoRA微调示例 from peft import get_peft_model, LoraConfig peft_config = LoraConfig( r=8, lora_alpha=32, target_modules=["q_proj", "v_proj"], lora_dropout=0.1 ) model = get_peft_model(base_model, peft_config) |
(3)监控体系
- 核心指标:
-
- 检索召回率(Recall@5)≥90%
-
- 生成准确率(人工标注)≥95%
-
- 响应时间(P95)≤500ms
六、实战优化:常见问题解决方案
1. 长文本分块信息割裂问题
- 解决方案:使用滑动窗口分块(重叠率 20%),或引入上下文感知分块(如基于语义相似度判断块边界)
2. 检索结果与生成内容不一致
- 调试步骤:
-
- 检查检索文档是否包含正确信息
-
- 分析 Prompt 是否引导模型忽略关键内容
-
- 增加生成时的证据引用强制要求(如 "根据文档第 X 页...")
3. 成本优化技巧
- 分级检索:简单问题先用关键词检索,失败再触发向量检索
- 结果缓存:使用 Redis 缓存高频问题的检索结果(TTL 设置 24 小时)
- 模型量化:将 FP16 模型转换为 INT8(推理速度提升 3 倍,精度损失 < 5%)
七、行业最佳实践:三大典型场景配置
1. 企业智能客服(日均 10 万次调用)
- 知识库:产品手册(500+PDF)+ 历史对话(10 万条 CSV)
- 检索层:Elasticsearch(关键词)+Milvus(向量),Query 改写使用轻量 T5 模型
- 生成层:GPT-3.5 Turbo,温度 0.2,强制输出 "回答 + 知识库链接"
2. 医疗辅助问诊(高合规要求)
- 技术配置:
-
- 编码器:PubMedBERT(医疗领域专用)
-
- 分块:按病历段落(保持主诉 - 现病史 - 检查结果完整性)
-
- 生成控制:输出必须包含 ICD-10 编码和《临床指南》引用
3. 金融研报生成(实时数据驱动)
- 数据链路:
-
- 实时数据:通过 API 获取股票行情(分钟级更新)
-
- 历史数据:向量数据库存储 10 万 + 研报(按 "公司 - 行业 - 时间" 打标签)
-
- 生成流程:先检索最新财务数据,再调用模型生成 "指标分析 + 风险提示"
八、工具链推荐与生态整合
1. 一站式开发框架
- LangChain:提供 RAG 组件化开发工具(文档加载、分块、检索、生成串联)
- Haystack:支持复杂 RAG 流程(多阶段检索、证据链构建)
2. 向量数据库对比表
|
工具 |
开源 |
分布式 |
中文支持 |
生态整合 |
适合场景 |
|
FAISS |
是 |
部分 |
一般 |
TensorFlow/PyTorch |
本地轻量 |
|
Milvus |
是 |
支持 |
良好 |
LangChain/Haystack |
企业级 |
|
Pinecone |
否 |
全托管 |
良好 |
OpenAI/Anthropic |
云端快速部署 |
结语
RAG 技术的落地不是简单的模块拼接,而是需要结合领域特性进行深度调优。从检索策略到生成控制,每个环节的微小改进都可能带来显著的效果提升。建议开发者从具体业务场景出发,先构建最小可行产品(MVP),通过用户反馈持续迭代优化知识库和模型参数。随着向量数据库和高效微调技术的不断进步,RAG 将成为大模型从 "通用智能" 走向 "行业专家" 的核心引擎。
(全文完)

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 26
26 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)