
生成对抗网络(GANs)中的损失函数公式 判别器最优解D^*(x)的推导
这张图片展示的是生成对抗网络(GANs)中的损失函数公式,特别是针对判别器(Discriminator)和生成器(Generator)的优化目标。通过上述公式,我们了解了GAN中判别器和生成器之间的博弈过程,以及如何通过优化损失函数来训练这两个模型,以达到生成高质量样本的目的。这个公式展示了判别器的目标是最大化其对真实样本的识别能力和对生成样本的拒绝能力。:分别代表判别器正确识别真实样本和错误识别
https://www.bilibili.com/video/BV1YyHSekEE2
这张图片展示的是生成对抗网络(GANs)中的损失函数公式,特别是针对判别器(Discriminator)和生成器(Generator)的优化目标。让我们用Markdown格式逐步解析这些公式:
GAN的基本优化目标
markdown
深色版本
minGmaxDV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))] \min_G \max_D V(D, G) = \mathbb{E}_{\boldsymbol{x} \sim p_{data}(\boldsymbol{x})}[\log D(\boldsymbol{x})] + \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log(1 - D(G(\boldsymbol{z})))] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
minGmaxD\min_G \max_DminGmaxD 表示:这是一个最小最大博弈问题,其中生成器 G 和判别器 D 在相互竞争中进行优化。
Ex∼pdata(x)\mathbb{E}_{\boldsymbol{x} \sim p_{data}(\boldsymbol{x})}Ex∼pdata(x):表示对真实数据分布 pdata(x)p_{data}(\boldsymbol{x})pdata(x) 的期望值计算。
Ez∼pz(z)\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}Ez∼pz(z):表示对噪声分布 pz(z)p_{\boldsymbol{z}}(\boldsymbol{z})pz(z) 的期望值计算。
D(x)D(\boldsymbol{x})D(x):判别器输出的真实样本的概率。
G(z)G(\boldsymbol{z})G(z):生成器根据噪声 z\boldsymbol{z}z 生成的样本。
logD(x)\log D(\boldsymbol{x})logD(x) 和 log(1−D(G(z)))\log(1 - D(G(\boldsymbol{z})))log(1−D(G(z))):分别代表判别器正确识别真实样本和错误识别生成样本的对数概率。
判别器的损失函数
markdown
深色版本
lossd=−(1N∑i=1Nyilog(pi)+(1−yi)log(1−pi)) loss_d = -\left(\frac{1}{N}\sum_{i=1}^{N}y_i\log(p_i) + (1-y_i)\log(1-p_i)\right) lossd=−(N1i=1∑Nyilog(pi)+(1−yi)log(1−pi))
这是一个二分类交叉熵损失函数,用于衡量判别器在区分真实和生成样本时的性能。
yiy_iyi 是标签(1表示真实样本,0表示生成样本),pip_ipi 是判别器预测的概率。
判别器损失函数的具体形式
markdown
深色版本
lossd=−(1N∑i=1Nyilog(D(imagei))+(1−yi)log(1−D(imagei))) loss_d = -\left(\frac{1}{N}\sum_{i=1}^{N}y_i\log(D(image_i)) + (1-y_i)\log(1-D(image_i))\right) lossd=−(N1i=1∑Nyilog(D(imagei))+(1−yi)log(1−D(imagei)))
这里将 pip_ipi 替换为 D(imagei)D(image_i)D(imagei),即判别器对图像 imageiimage_iimagei 的输出概率。
判别器损失函数的进一步分解
markdown
深色版本
minlossd=−(1Nreal∑ilog(D(xi))+1Nfake∑ilog(1−D(G(zi)))) \min loss_d = -\left(\frac{1}{N_{real}}\sum_i\log(D(x_i)) + \frac{1}{N_{fake}}\sum_i\log(1-D(G(z_i)))\right) minlossd=−(Nreal1i∑log(D(xi))+Nfake1i∑log(1−D(G(zi))))
这个公式明确地将损失分为两部分:一部分是对于真实样本 xix_ixi 的损失,另一部分是对于生成样本 G(zi)G(z_i)G(zi) 的损失。
最大化判别器的目标
markdown
深色版本
max1Nreal∑ilog(D(xi))+1Nfake∑ilog(1−D(G(zi))) \max \frac{1}{N_{real}}\sum_i\log(D(x_i)) + \frac{1}{N_{fake}}\sum_i\log(1-D(G(z_i))) maxNreal1i∑log(D(xi))+Nfake1i∑log(1−D(G(zi)))
这个公式展示了判别器的目标是最大化其对真实样本的识别能力和对生成样本的拒绝能力。
通过上述公式,我们了解了GAN中判别器和生成器之间的博弈过程,以及如何通过优化损失函数来训练这两个模型,以达到生成高质量样本的目的。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 定义生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(True),
nn.Linear(256, 256),
nn.ReLU(True),
nn.Linear(256, 784),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
# 定义判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(True),
nn.Linear(256, 256),
nn.ReLU(True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
# 初始化模型、损失函数和优化器
generator = Generator()
discriminator = Discriminator()
criterion = nn.BCELoss() # Binary Cross Entropy Loss
optimizer_g = optim.Adam(generator.parameters(), lr=0.0002)
optimizer_d = optim.Adam(discriminator.parameters(), lr=0.0002)
# 加载MNIST数据集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
train_loader = torch.utils.data.DataLoader(datasets.MNIST('data', train=True, download=True, transform=transform),
batch_size=64, shuffle=True)
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):
for i, (imgs, _) in enumerate(train_loader):
# 准备数据
valid = torch.ones(imgs.size(0), 1)
fake = torch.zeros(imgs.size(0), 1)
real_imgs = imgs.view(imgs.size(0), -1)
# 训练判别器
optimizer_d.zero_grad()
z = torch.randn(imgs.size(0), 100)
gen_imgs = generator(z)
loss_real = criterion(discriminator(real_imgs), valid)
loss_fake = criterion(discriminator(gen_imgs.detach()), fake)
loss_d = (loss_real + loss_fake) / 2
loss_d.backward()
optimizer_d.step()
# 训练生成器
optimizer_g.zero_grad()
loss_g = criterion(discriminator(gen_imgs), valid)
loss_g.backward()
optimizer_g.step()
print(f"Epoch [{epoch}/{num_epochs}] Loss D: {loss_d.item()}, loss G: {loss_g.item()}")
print('训练完成')
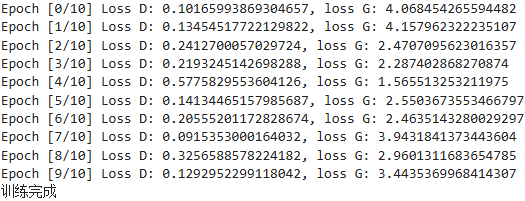
判别器损失(Loss D)
趋势:判别器损失在训练过程中表现出较大的波动性。初期较低(<0.2),中期升高(最高达到0.5776),然后又回落。
解释:这表明模型在学习过程中经历了不同的阶段,其中生成器在某些时期能够较好地欺骗判别器,导致判别器的损失增加。
生成器损失(Loss G)
趋势:生成器损失从最初的较高水平逐渐下降到最低点(1.5655),然后有所回升并在后续的epoch中保持在一个相对较高的水平(约2.5至4之间)。
解释:这种模式可能意味着生成器的学习速率与判别器相比不够平衡,或者存在过拟合现象。特别是在第4个epoch之后,生成器损失的上升可能表示生成器遇到了瓶颈或难以进一步优化。
🔍 结论与建议
稳定性问题:由于损失值的大幅波动,可能需要调整超参数来稳定训练过程。比如:
调整学习率。
应用梯度惩罚或其他正则化技术以增强训练稳定性。
网络架构或数据集问题:如果损失值持续不稳定,考虑检查数据集是否足够多样化,以及网络架构是否有改进空间。
早期停止策略:可以实施早期停止策略来防止过拟合,并确保模型在验证集上的性能不会恶化。
可视化:定期保存并查看生成样本,可以帮助理解模型的实际表现和进步情况。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, utils
import matplotlib.pyplot as plt
# 检查是否可用 CUDA
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# -----------------------------
# 模型定义
# -----------------------------
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(True),
nn.Linear(256, 256),
nn.ReLU(True),
nn.Linear(256, 784),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(True),
nn.Linear(256, 256),
nn.ReLU(True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
# -----------------------------
# 初始化模型和优化器
# -----------------------------
generator = Generator().to(device)
discriminator = Discriminator().to(device)
criterion = nn.BCELoss()
optimizer_g = optim.Adam(generator.parameters(), lr=0.0002)
optimizer_d = optim.Adam(discriminator.parameters(), lr=0.0002)
# -----------------------------
# 数据加载
# -----------------------------
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True, transform=transform),
batch_size=64,
shuffle=True
)
# -----------------------------
# 可视化函数
# -----------------------------
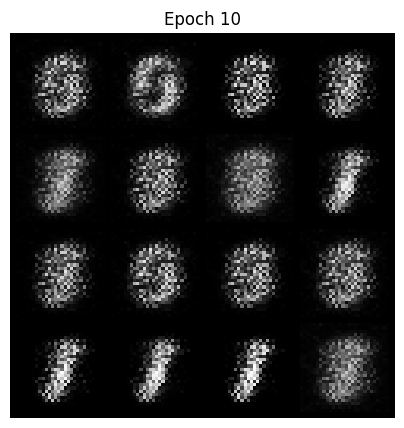
def show_images(images, epoch):
images = images.view(-1, 1, 28, 28)
grid = utils.make_grid(images, nrow=4, normalize=True)
plt.figure(figsize=(5, 5))
plt.title(f"Epoch {epoch}")
plt.imshow(grid.permute(1, 2, 0).cpu())
plt.axis("off")
plt.show()
# 固定噪声,用于每轮观察生成效果变化
fixed_noise = torch.randn(16, 100, device=device)
# -----------------------------
# 训练循环
# -----------------------------
num_epochs = 20
for epoch in range(num_epochs):
for i, (imgs, _) in enumerate(train_loader):
imgs = imgs.to(device)
real_labels = torch.ones(imgs.size(0), 1).to(device)
fake_labels = torch.zeros(imgs.size(0), 1).to(device)
# ---------------------
# 训练判别器
# ---------------------
optimizer_d.zero_grad()
real_imgs = imgs.view(imgs.size(0), -1)
d_real_loss = criterion(discriminator(real_imgs), real_labels)
z = torch.randn(imgs.size(0), 100).to(device)
gen_imgs = generator(z).detach()
d_fake_loss = criterion(discriminator(gen_imgs), fake_labels)
loss_d = (d_real_loss + d_fake_loss) / 2
loss_d.backward()
optimizer_d.step()
# ---------------------
# 训练生成器
# ---------------------
optimizer_g.zero_grad()
gen_imgs = generator(z)
loss_g = criterion(discriminator(gen_imgs), real_labels)
loss_g.backward()
optimizer_g.step()
print(f"Epoch [{epoch}/{num_epochs}] Loss D: {loss_d.item():.4f}, Loss G: {loss_g.item():.4f}")
# 每个epoch结束后可视化生成结果
with torch.no_grad():
generated = generator(fixed_noise).cpu()
show_images(generated, epoch)
print("训练完成")
加入可视化


https://www.kaggle.com/code/alihhhjj/notebook8be232dcc8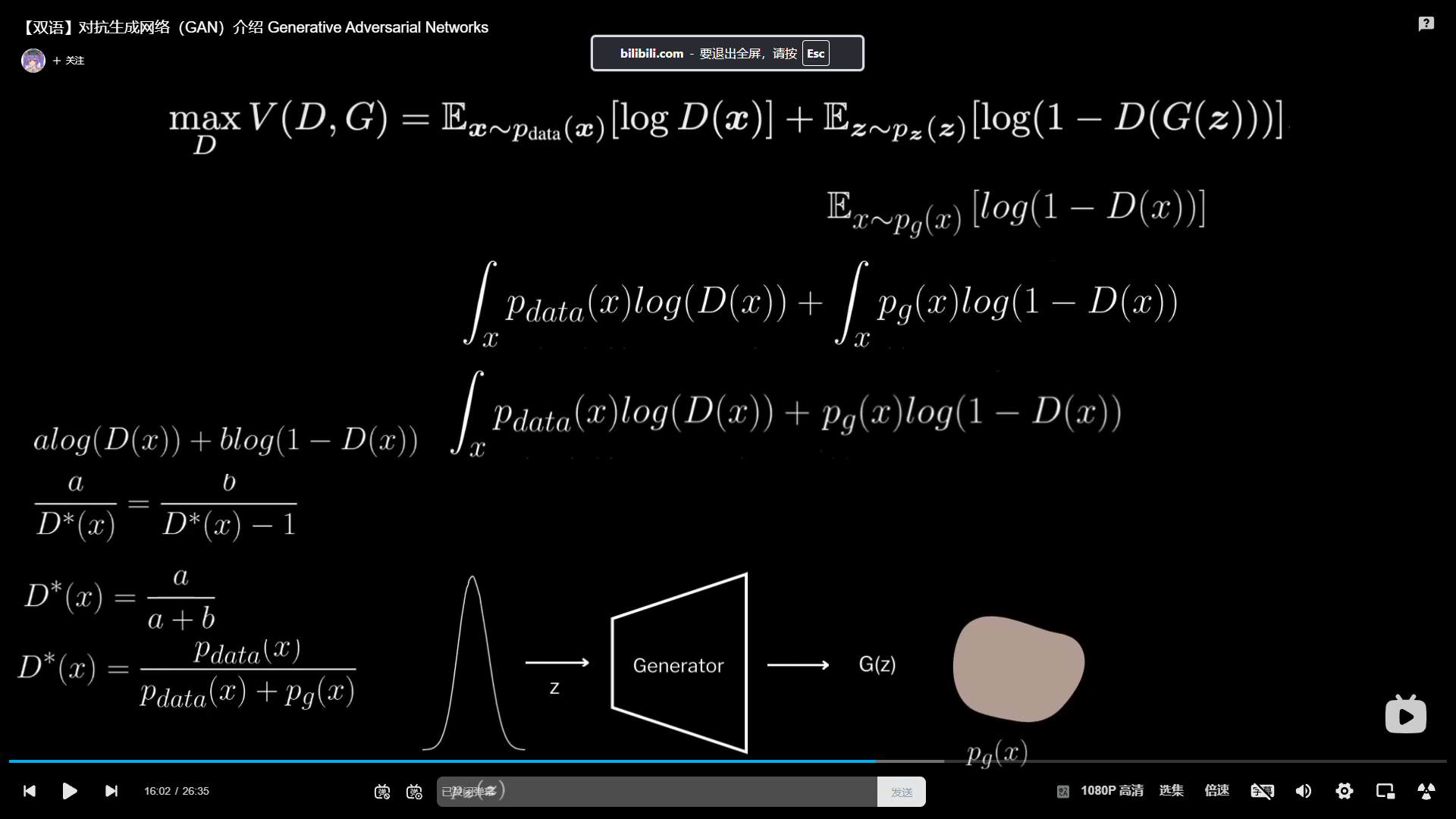
判别器最优解 $ D^*(x) $ 的推导
在生成对抗网络(GAN)中,判别器的目标是最大化以下目标函数:
V(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))] V(D, G) = \mathbb{E}_{\boldsymbol{x} \sim p_{data}(\boldsymbol{x})}[\log D(\boldsymbol{x})] + \mathbb{E}_{\boldsymbol{z} \sim p_z(\boldsymbol{z})}[\log(1 - D(G(\boldsymbol{z})))] V(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
固定生成器 $ G $,我们希望找到使 $ V(D, G) $ 最大化的最优判别器 $ D^*(x) $。
一、简化目标函数
考虑对某个固定的输入样本 $ x $,我们可以将目标函数简化为一个关于 $ D(x) $ 的函数:
L(D(x))=alogD(x)+blog(1−D(x)) L(D(x)) = a \log D(x) + b \log (1 - D(x)) L(D(x))=alogD(x)+blog(1−D(x))
其中:
- $ a = p_{data}(x) $:真实数据分布中 $ x $ 的概率密度;
- $ b = p_g(x) $:生成器生成的数据分布中 $ x $ 的概率密度。
二、求极值:令导数为零
对 $ D(x) $ 求导并令其等于 0:
dLdD(x)=aD(x)−b1−D(x)=0 \frac{dL}{dD(x)} = \frac{a}{D(x)} - \frac{b}{1 - D(x)} = 0 dD(x)dL=D(x)a−1−D(x)b=0
整理得:
aD(x)=b1−D(x) \frac{a}{D(x)} = \frac{b}{1 - D(x)} D(x)a=1−D(x)b
这就是你看到的等式形式:
aD∗(x)=b1−D∗(x) \frac{a}{D^*(x)} = \frac{b}{1 - D^*(x)} D∗(x)a=1−D∗(x)b
三、解方程求出 $ D^*(x) $
交叉相乘:
a(1−D∗(x))=bD∗(x) a(1 - D^*(x)) = b D^*(x) a(1−D∗(x))=bD∗(x)
展开并整理:
a=aD∗(x)+bD∗(x)⇒a=D∗(x)(a+b) a = a D^*(x) + b D^*(x) \Rightarrow a = D^*(x)(a + b) a=aD∗(x)+bD∗(x)⇒a=D∗(x)(a+b)
解得:
D∗(x)=aa+b D^*(x) = \frac{a}{a + b} D∗(x)=a+ba
代入 $ a = p_{data}(x), b = p_g(x) $,得到最终结果:
D∗(x)=pdata(x)pdata(x)+pg(x) D^*(x) = \frac{p_{data}(x)}{p_{data}(x) + p_g(x)} D∗(x)=pdata(x)+pg(x)pdata(x)
四、意义
这表示在给定输入样本 $ x $ 的情况下,最优判别器 $ D^*(x) $ 输出的是该样本来自真实数据分布而非生成分布的概率。






技术共进,成长同行——讯飞AI开发者社区
更多推荐



 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)