
机器学习 day38(有放回抽样、随机森林算法、XGBoost)
有放回抽样有放回抽样和无放回抽样的区别:有放回可以确保每轮抽取的结果不一定相同,无放回则每轮抽取的结果都相同在猫狗的例子中,我们使用”有放回抽样“来抽取10个样本,并组合为一个与原始数据集不同的新数据集,虽然新数据集中可能有重复的样本,也不一定包含原始数据集的所有样本。随机森林算法装袋决策树算法(Bagged decision tree)是适用于决策树集合的一种算法,生成决策树集合的过程如下:对于
·
有放回抽样
- 有放回抽样和无放回抽样的区别:有放回可以确保每轮抽取的结果不一定相同,无放回则每轮抽取的结果都相同
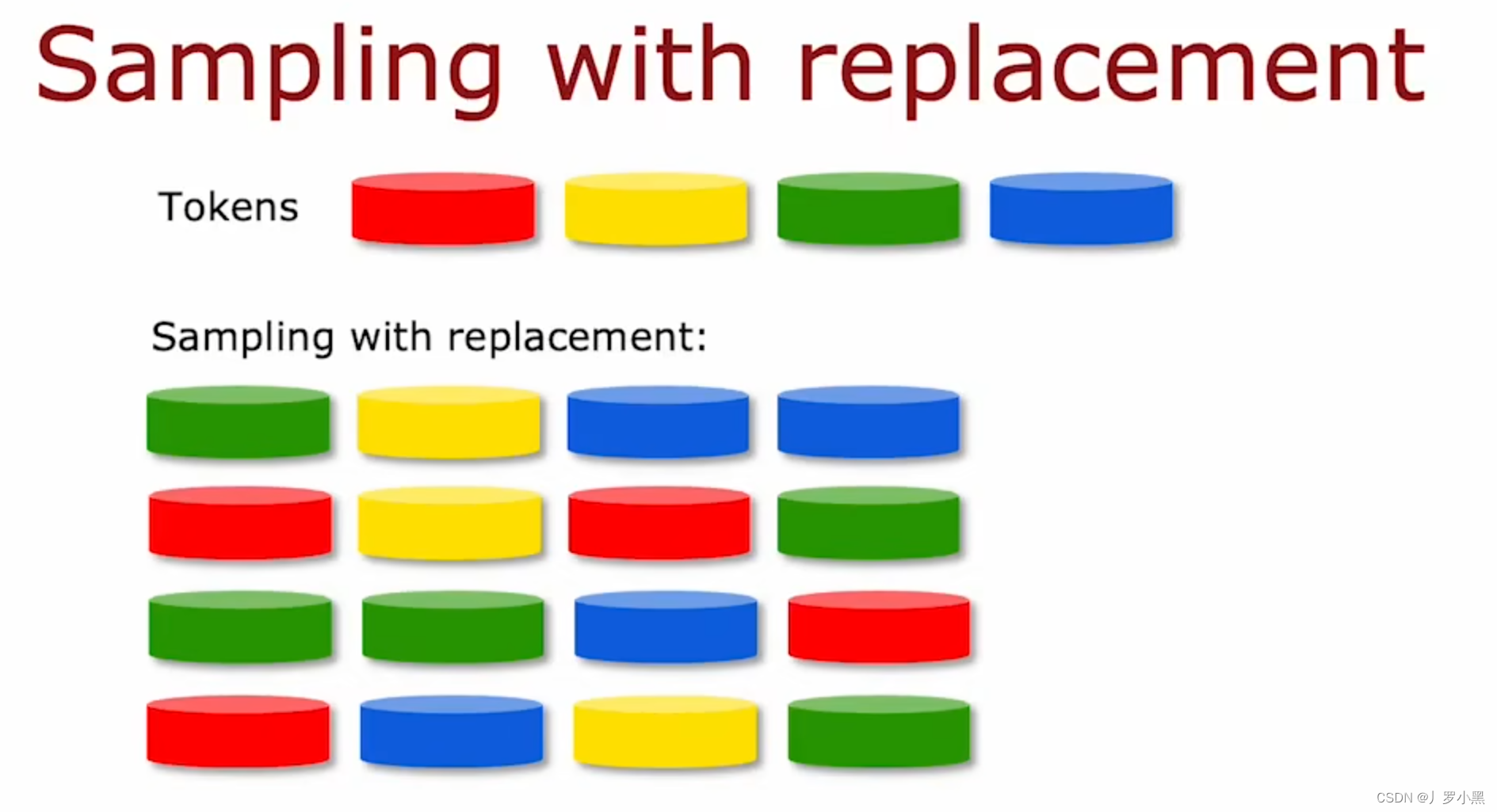
- 在猫狗的例子中,我们使用”有放回抽样“来抽取10个样本,并组合为一个与原始数据集不同的新数据集,虽然新数据集中可能有重复的样本,也不一定包含原始数据集的所有样本。
随机森林算法

- 装袋决策树算法(Bagged decision tree)是适用于决策树集合的一种算法,生成决策树集合的过程如下:
- 对于一个大小为M的原始数据集,进行以下操作:
- 使用“有放回抽样”,生成一个大小为M的新数据集, 在新数据集上训练决策树
- 完成一次后,重复这个操作,直到重复B次(B不需要特别大,因为收益会递减,100左右是比较合适的值)
- 对于一个大小为M的原始数据集,进行以下操作:
- 装袋决策树算法指的是:我们将训练示例放入虚拟袋中,并进行有放回的抽样

- 装袋决策树算法会导致:根节点处的拆分基本相同,且根节点附近的子节点也很相似,所以最后生成的决策树有大部分相似。为了让每个节点处能选择的特征不同,从而生成更多不同的决策树,提出了鲁棒性更强的随机森林算法。
- 随机森林算法:在每个拆分节点处,我们的最优子节点的选择不是从所有的特征中选,而是先随机一个小于n的数k,再在包含k个特征的子集中选择最优子节点(当n很大时,通常取k=根号n)
- 为什么随机森林算法比单个决策树的算法的鲁棒性更强:因为随机森林已经用很多进行了细小修改的数据集来训练算法,并进行平均,所以即便训练集发生一些小变化,也不会对最终输出有很大影响
XGBoost

- Boost tree的思路是:用第一个已经训练好的决策树来预测原始数据集,并在之后的新决策树建立的过程中,重点关注预测失败的样本
- 注意:训练第一个决策树的数据集 —> 对原始数据集进行平均概率的有放回抽样;预测第一个决策树的数据集 —> 原始数据集;训练第二个决策树的数据集 —> 对原始数据集进行重点关注预测失败的有放回抽样

- 由于重点关注预测失败算法的数学细节比较复杂(选择不同样本之间的概率),现在常用的是XGBoost,有以下优点:开源、快速高效、良好的默认拆分标准和停止拆分标准、内置正则化防止过拟合、广泛应用于比赛网站
- XGBoost为不同的训练示例分配了不同的方法,所以不需要采用有放回抽样来生成随机训练集,但就重点关注预测失败这一行为来看,和Boost tree还是很类似

- 由于XGBoost的实现细节比较复杂,所以通常直接导库使用,具体代码:分类和回归两种

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)