
第五章.干货干货!!!Langchain4j开发智能体-Chain式调用多个大模型
在实际开发中我们通常需要协调多个大模型一起完成工作,如果使用过类似coze的工作流就能明白,很多时候一个任务是由多个环节构成的。对于大模型而言,每次用户提问它不应该去访问所有的tools,这样做很危险,会消耗大量的token,而且会带来一些意想不到的问题。正确的方式应该是根据不同的提问类型调用不同的tools做出相应的处理,如下图:本篇文章我们通过Lanchain4j实现根据用户的不同提问类型,调
前言
在实际开发中我们通常需要协调多个大模型一起完成工作,如果使用过类似coze的工作流就能明白,很多时候一个任务是由多个环节构成的。对于大模型而言,每次用户提问它不应该去访问所有的tools,这样做很危险,会消耗大量的token,而且会带来一些意想不到的问题。 正确的方式应该是根据不同的提问类型调用不同的tools做出相应的处理,如下图: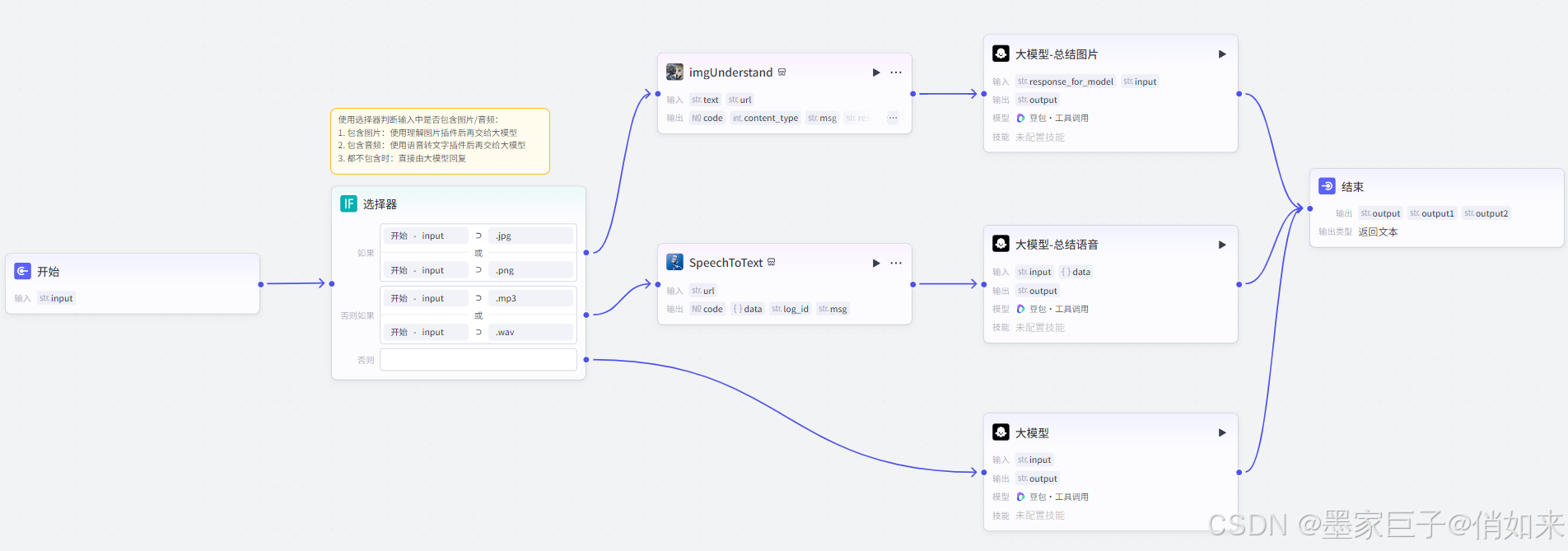
本篇文章我们通过Lanchain4j实现根据用户的不同提问类型,调用不同的tools完成响应的逻辑处理
准备工作
首先我们需要定义一个枚举,该枚举对应了不同的tools ,我们以查询天气,查询商品为例,定义如下两个枚举
@Getter
public enum TaskType {
SEARCH_WEATHER("查询天气"),
SEARCH_GOODS("查询商品");
private final String name;
TaskType(String name) {
this.name = name;
}
}
然后我们定义2个AI助手,分别是用来查询天气,以及查询商品的,,同时我们还需要一个用于识别用户提问根据提问类型返回为枚举的方法如下:
public interface OllamaAssistant {
/**
* 任务类型识别
* @param message :消息
*/
@SystemMessage("请识别一下内容 {{message}} 是什么任务类型")
TaskType taskType(@UserMessage @V("message") String message);
/**
* 流式输出 - 记忆能力 - search 工具调用
* @param message :消息
* @param memoryId :消息记忆用作隔离的ID
*/
@SystemMessage("你是一名AI购物助手,根据用户的提问帮助用户搜索相关的商品信息")
String search(@UserMessage String message, @MemoryId String memoryId);
/**
* 流式输出 - 记忆能力 - tools 工具调用
* @param message :消息
* @param memoryId :消息记忆用作隔离的ID
*/
@SystemMessage("你是一名天气查询助手,仔细分析用户的提问内容,根据内容中的城市名,调用tools搜索天气")
String weather(@UserMessage String message, @MemoryId String memoryId);
...
}
接下来是配置 OllamaAssistant ,和之前的文章中没有什么变化,这里再贴一下代码
@Configuration
public class LLMConfig {
/**
* ollama大模型 - ai -service
* 记忆功能
*/
@Bean
public OllamaAssistant ollamaAssistant(QwenChatModel chatModel, WebSearchEngine webSearchEngine){
//对话记忆功能实现
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder().chatMemoryStore(new PersistentChatMemoryStore()).maxMessages(10).build();
//RAG检索
return AiServices.builder(OllamaAssistant.class)
//流式对话
.chatLanguageModel(chatModel)
//记忆功能
.chatMemoryProvider((memoryId -> chatMemory))
//调用自定义工具 , web搜索工具
.tools(new WeatherTool(),new WebSearchTool(webSearchEngine))
.build();
}
对话测试
接下来我们编写对话逻辑,拿到用户提问先使用大模型识别 taskType,根据不同的 taskType 调用不同的tools,逻辑代码如下
/**
* 多个AI调用,AI chain
*/
@RequestMapping(value="/chat/chain", produces = TEXT_EVENT_STREAM_VALUE)
public Flux<String> aiChain(@RequestParam("message") String message, @RequestParam("memoryId")String memoryId) {
TaskType taskType = ollamaAssistant.taskType(message);
log.info("taskType = {}",taskType);
return switch (taskType){
case SEARCH_WEATHER -> ollamaAssistant.weather(message,memoryId);
case SEARCH_GOODS -> ollamaAssistant.search(message,memoryId);
};
}
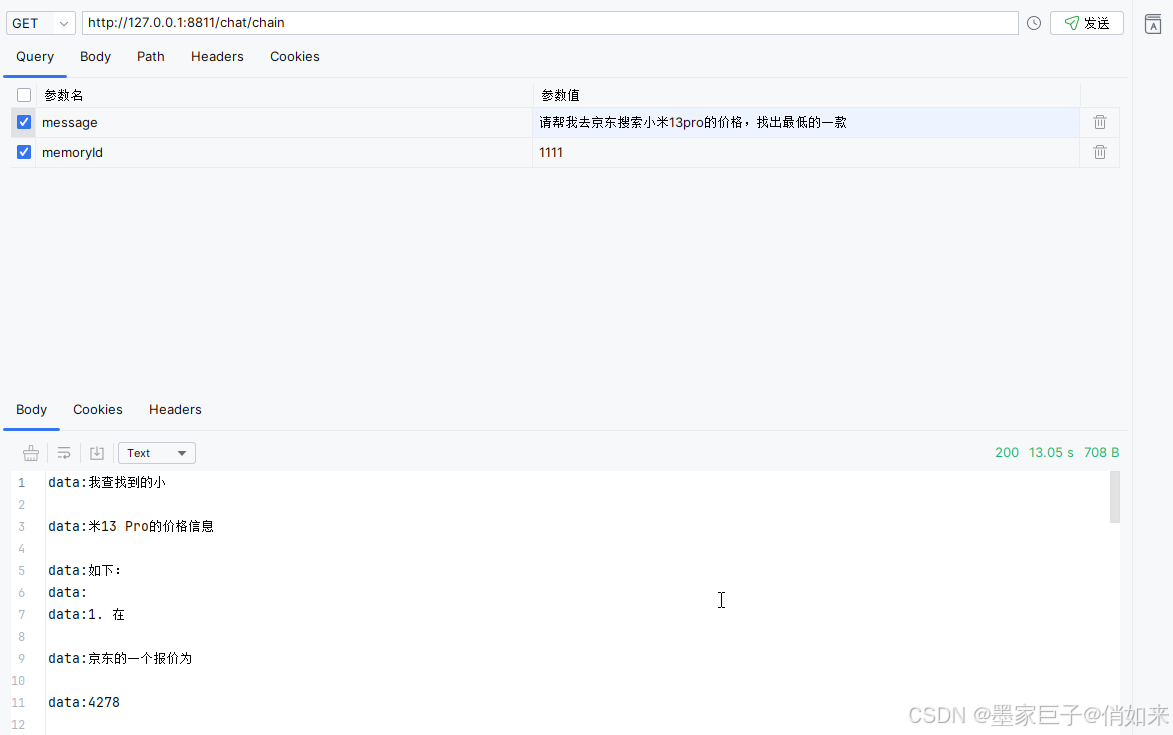
最后启动项目进行测试,分别向大模型输入不同的提问:成都今天天气怎么样 , 请帮我去
京东搜索小米13pro手机的价格。可以看到控制台的答应结果,拿到的枚举分别是 SEARCH_WEATHER,以及 SEARCH_GOODS ,从而实现了根据用户不同的提问内容,路由到不同的tools调用。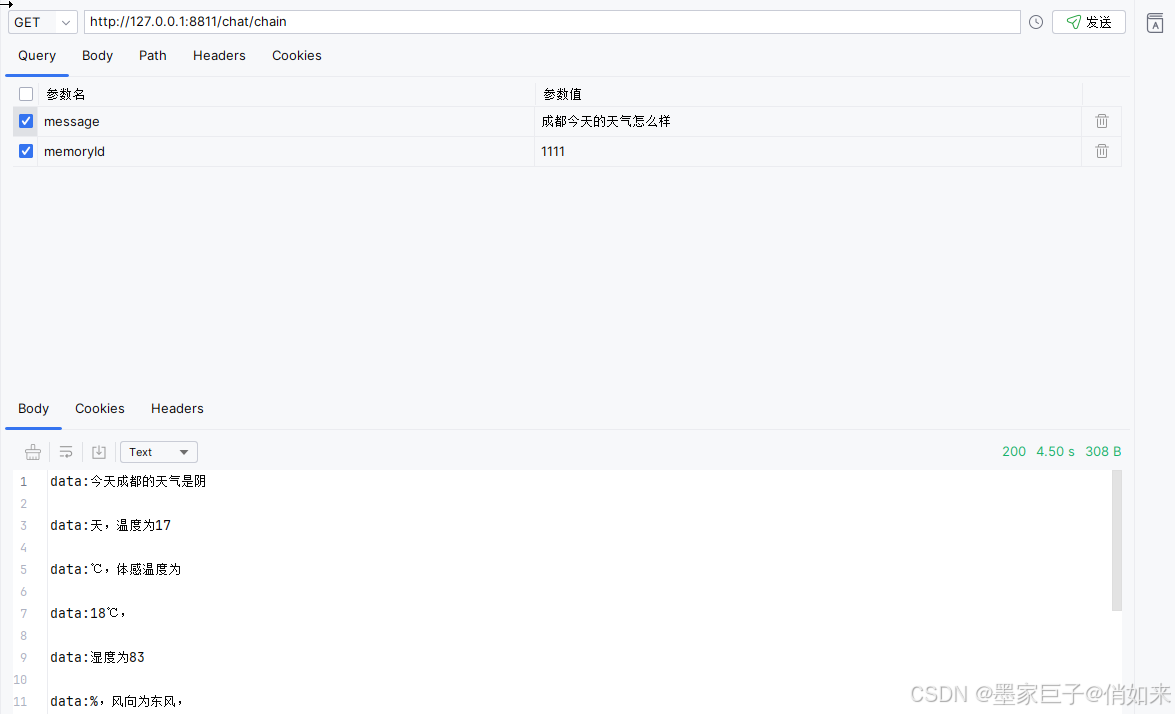
总结
文章到这里就结束了,本文主要是讲解了如何使用大模型对用户的内容进行分类,根据不同的类型调用不同的tools,做出不同的业务处理,整个功能实现感觉是蛮简单的,但是这个样一个小小的案例其实提供给我们无限的可能。文章结束喜欢请三联!!!

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 12
12 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)