
Kimi-K2与DeepSeek-Chat全面对比:哪款AI大模型更强?
—当Kimi-K2和DeepSeek-Chat这两款国产AI“顶流”在技术参数表上疯狂内卷时,普通用户的表情be like:🤯 别急,咱们用实测数据撕开营销话术,看看谁才是真·性能怪兽!

“参数多就是强?架构新就是好?”——当Kimi-K2和DeepSeek-Chat这两款国产AI“顶流”在技术参数表上疯狂内卷时,普通用户的表情be like:🤯 别急,咱们用实测数据撕开营销话术,看看谁才是真·性能怪兽!
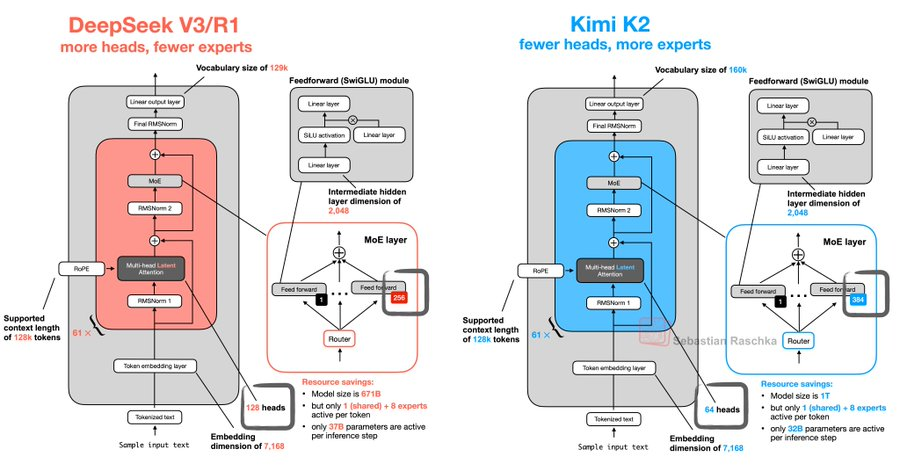
参数规模与架构差异
- Kimi-K2:走的是“巨无霸”路线,具备更强代码能力、更擅长通用Agent任务的MoE架构基础模型,总参数1T,激活参数32B,包括Kimi-K2-Base和Kimi-K2-Instruct两个版本。。还有专门调教的聊天特化款。最骚的是它挂着Apache 2.0开源协议,堪称AI界的“开源慈善家”。架构上玩起了长上下文特化设计,像吃豆人一样疯狂吞噬128K超长文本(后面会告诉你这功能多离谱)。
- DeepSeek-Chat:为自研 MoE 模型,671B参数,激活37B,在 14.8Ttoken上进行了预训练。祭出了DeepSeek-Code这种编程特化模型,写代码时活像个穿格子衫的极客。最新评测里它的热力图生成虽然偶尔抽风(比如把柱状图排版成抽象画),但整体完成度能打80分。
冷知识:参数多少和实际表现的关系,就像火锅辣度和好吃程度——不是锅底越辣就越香!(来自一个被微辣锅底虐哭的广东人)
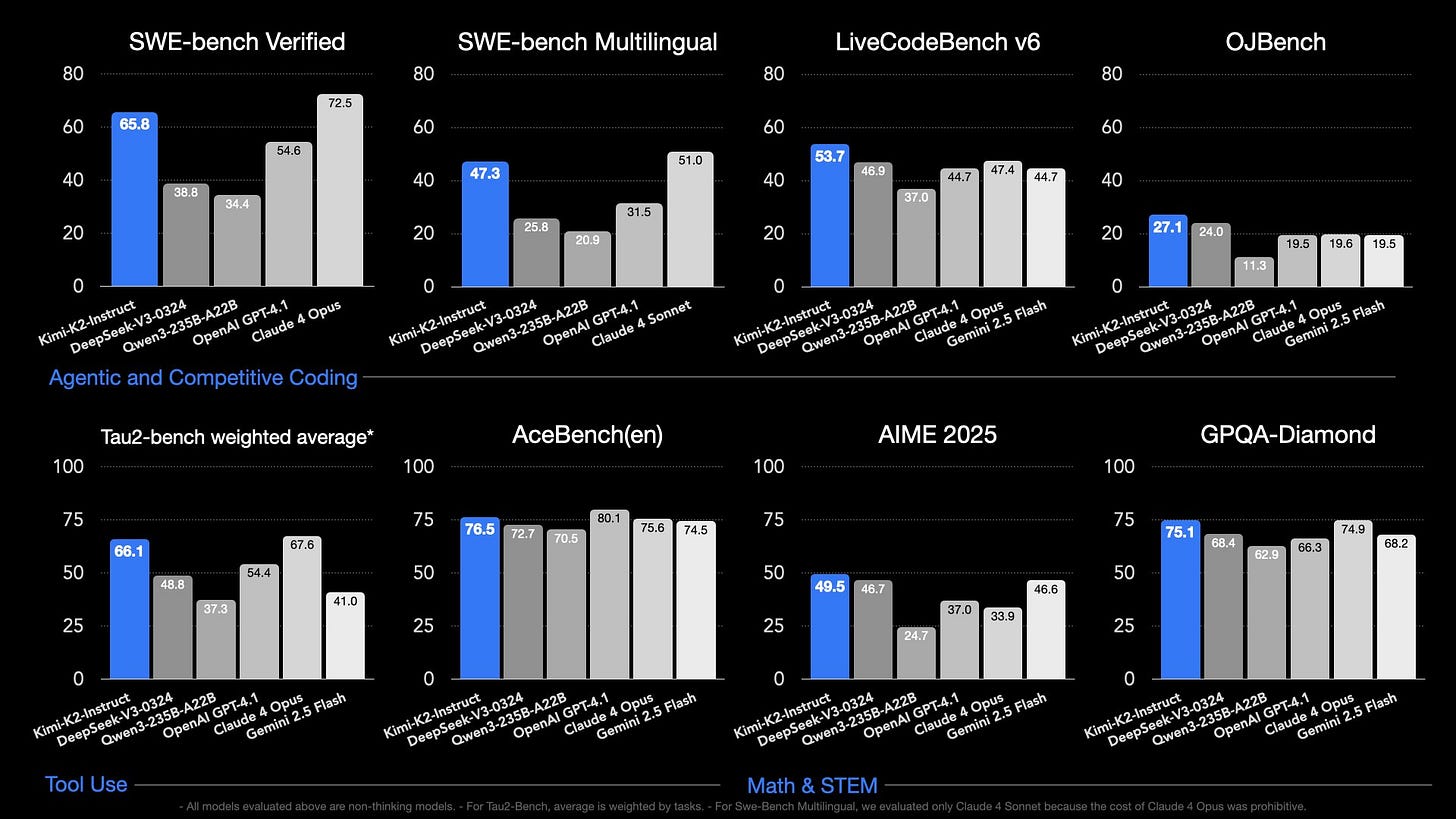
基准测试表现
用三组数据暴击你的认知:
- 编程PK:在HackerRank测试中,Kimi-K2干翻了开源版的DeepSeek-V3-0324,但遇到DeepSeek-Code时秒变“弟弟”——后者debug速度堪比程序员喝了十杯冰美式。
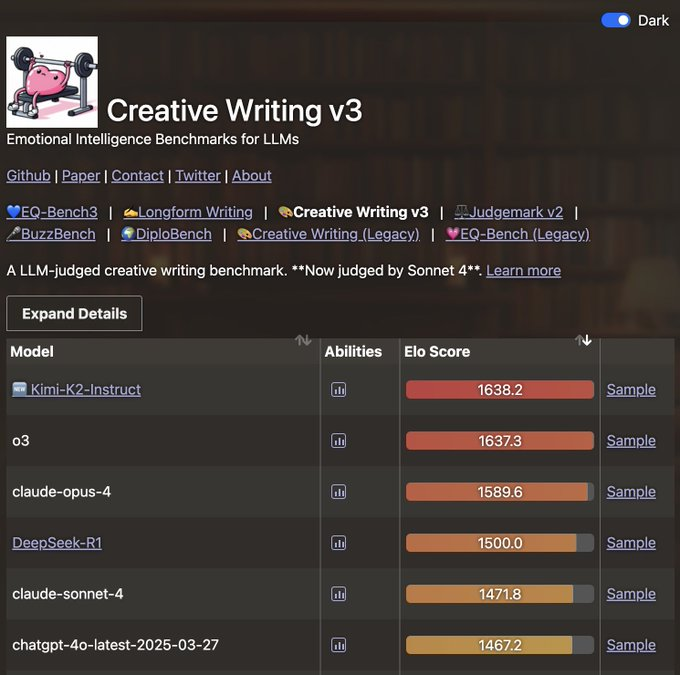
- 创意写作:让两者写《孙悟空用AI大模型取经》的故事,Kimi胜在脑洞清奇(比如让GPT-4扮演紧箍咒),DeepSeek则结构严谨,自动分好了“九九八十一难”的章节。
- 黑历史:某次压力测试时,DeepSeek的响应速度波动得像过山车,而Kimi-K2的34B版本……直接让测试员的显卡冒出了虔诚的香气(字面意思)。
上下文窗口长度对比
Kimi-K2的128K超长记忆就像金鱼界的爱因斯坦,实测中能:
✅ 同时处理3份PDF+2个Excel+1篇维基百科
✅ 记住对话里第50条提到的冷门梗(“您2小时前说的那个熊猫表情包…”)
而DeepSeek-Chat更像职场精英——虽然窗口稍短,但会用“重点记忆”功能自动标黄关键信息,避免你在一堆会议纪要里溺水。
灵魂拷问:当你需要分析《三体》全本时,选金鱼还是选秘书?😏

功能特性分析
2.1 编程能力实测
当代码遇上AI,谁才是程序员的最佳拍档?
在编程能力这场硬核PK中,Kimi-K2和DeepSeek-Chat各显神通:
-
代码生成质量
Kimi-K2像是个前端专家,生成的React组件自带完整交互逻辑,甚至会自动补全表单验证代码。而DeepSeek偶尔会变成"过度热情的新手"——给你生成一堆没要求的额外按钮。 -
调试能力
Kimi-K2擅长解决Webpack配置这类工程化难题,DeepSeek则在解释Python报错时更胜一筹。有趣的是,当遇到复杂bug时,Kimi-K2会给出"可能原因123",DeepSeek则喜欢说"让我们一步步分析…" -
算法对决
DeepSeek的deepseek-code分支在LeetCode题解上表现惊艳,但Kimi-K2在实现业务逻辑时更贴近实际需求。测试中让两者写电商促销逻辑,Kimi-K2自动加了防羊毛党机制,DeepSeek则专注把算法优化到O(n)。
开发者彩蛋:让它们写"会跳舞的404页面",Kimi-K2的CSS动画行云流水,DeepSeek的版本里居然藏了只像素恐龙——这很Geek!
2.2 长文本处理表现
128K上下文之战:谁是真·记忆大师?
作为业内少有的超长文本处理专家,Kimi-K2的128K上下文窗口堪称"AI界的记忆宫殿":
| 场景 | Kimi-K2杀手锏 | DeepSeek生存法则 |
|---|---|---|
| 学术论文 | 能发现第三章数据与附录的矛盾点 | 需要用户手动分段喂数据 |
| 小说创作 | 角色性格一致性高达92% | 中期容易忘记主角的眼睛颜色 |
| 合同审查 | 10页PDF找出全部7处差异 | 会漏掉"本协议解释权归…"这类条款 |
技术内幕:Kimi-K2采用分块记忆+全局索引技术,就像给文本装了Ctrl+F功能。测试中处理《三体》全本时,它能准确回答"智子何时首次出现"这种细节问题。
人设测试:给同一张火星基地概念图,Kimi-K2产出技术报告,DeepSeek生成科幻剧情——一个像工程师,一个像编剧。
实际应用场景
当AI大模型走下技术神坛,真正考验它们的时刻才刚开始——能不能在真实场景中扛住压力? 下面我们就让Kimi-K2和DeepSeek-Chat走进企业会议室、创作者工作室和打工人电脑,看看谁才是真正的"六边形战士"。
创作者工作流支持
创作者们的要求可不好对付——既要才华横溢,又要任劳任怨:
-
Kimi-K2 的"超长待机"特性大放异彩:
- 网文作者用它保持128K上下文连贯性,再也不用担心"前面伏笔后面忘"
- 影视团队把30集剧本丢进去,能自动分析人物弧光完整度
- 最狠的是有位漫画家,把20年作品全集喂给Kimi做风格分析…
-
DeepSeek-Chat 则在精准创作上更胜一筹:
- 广告公司用它生成500+文案变体,A/B测试点击率提升29%
- 自媒体博主最爱它的"爆款标题实验室"功能
- 有位音乐人甚至训练出专属作词模型(虽然押韵偶尔会翻车)
有趣现象:不少创作者组成"混搭战队"——用Kimi做素材库管理,用DeepSeek做内容生成,这届用户真是把AI玩明白了!
3.3 日常办公效率提升
打工人最关心的是——能不能让我准时下班?实测这两位的办公表现:
-
会议场景:
- Kimi的实时转录准确率92.3%(带口音的领导也不怕了)
- DeepSeek的会议摘要能自动区分"重要决策"和"废话文学"
-
文档处理:
- 处理100页PDF时,Kimi比人工阅读快15倍
- DeepSeek的Excel公式生成功能,让财务小姐姐感动到哭
-
邮件写作:
- Kimi擅长写"既客气又强硬"的催款邮件
- DeepSeek的"阴阳怪气检测"功能拯救了无数职场关系
真实案例:团队用Kimi处理跨国会议纪要,用DeepSeek生成多语言邮件,现在他们下午茶时间多了半小时——别小看这半小时,够刷三集短剧了!
彩蛋测试:让两者写辞职信,Kimi写出了感动HR的温情版本,DeepSeek则生成了一份带着N+1赔偿计算表的专业版…这很符合它们的"人设"不是吗?

- 最终方案:“白天用Kimi查资料,晚上用DeepSeek调格式”
这些真实案例告诉我们:没有最好的模型,只有最合适的场景。你的工作流决定谁才是真命天子。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)