
7种机器学习分类方法,Python实现,附资料
Logistic RegressionNaive BayesDecision TreeRandom ForestXGBoostKNNSVC
源码与论文资料领取链接:
领取链接 https://s.pdb2.com/pages/20231107/cNttH3oeFf2ifi6.html
https://s.pdb2.com/pages/20231107/cNttH3oeFf2ifi6.html
Logistic Regression
Logistic回归是一种用于处理二分类问题的线性模型。它使用sigmoid函数将线性模型的输出映射到0和1之间的概率值。该模型可以用来估计因变量为二元结果的概率。
m1 = 'Logistic Regression'
lr = LogisticRegression()
model = lr.fit(X_train, y_train)
lr_predict = lr.predict(X_test)
lr_conf_matrix = confusion_matrix(y_test, lr_predict)
lr_acc_score = accuracy_score(y_test, lr_predict)
print("confussion matrix")
print(lr_conf_matrix)
print("\n")
print("Accuracy of Logistic Regression:",lr_acc_score*100,'\n')
print(classification_report(y_test,lr_predict))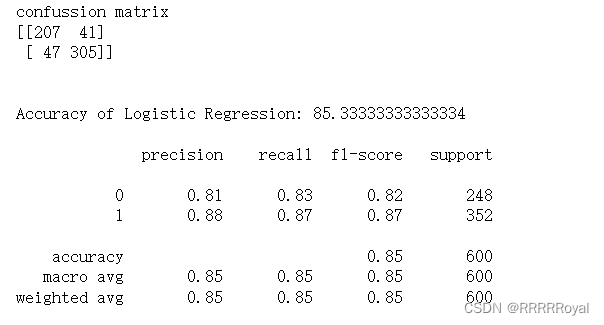
Naive Bayes
朴素贝叶斯是一种基于贝叶斯定理和特征条件独立性假设的简单且快速的分类算法。它通过计算每个类别的后验概率来进行分类,并假设特征之间是相互独立的。它在文本分类和垃圾邮件过滤等领域应用广泛。
m2 = 'Naive Bayes'
nb = GaussianNB()
nb.fit(X_train,y_train)
nbpred = nb.predict(X_test)
nb_conf_matrix = confusion_matrix(y_test, nbpred)
nb_acc_score = accuracy_score(y_test, nbpred)
print("confussion matrix")
print(nb_conf_matrix)
print("\n")
print("Accuracy of Naive Bayes model:",nb_acc_score*100,'\n')
print(classification_report(y_test,nbpred))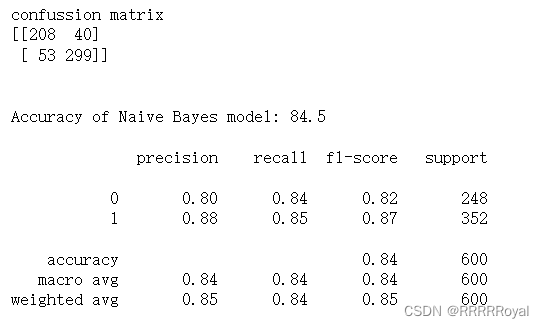
Decision Tree
决策树是一种基于树结构的分类和回归算法。它通过在特征空间中构建树来进行决策。每个内部节点表示一个特征或属性,每个叶节点表示一个类别或值。决策树易于理解和解释,可以处理离散和连续特征。
m6 = 'DecisionTreeClassifier'
dt = DecisionTreeClassifier(criterion = 'entropy',random_state=42,max_depth = 6)
dt.fit(X_train, y_train)
dt_predicted = dt.predict(X_test)
dt_conf_matrix = confusion_matrix(y_test, dt_predicted)
dt_acc_score = accuracy_score(y_test, dt_predicted)
print("confussion matrix")
print(dt_conf_matrix)
print("\n")
print("Accuracy of DecisionTreeClassifier:",dt_acc_score*100,'\n')
print(classification_report(y_test,dt_predicted))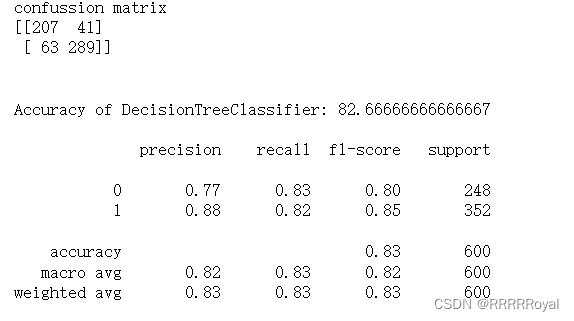
Random Forest
随机森林是一种集成学习方法,通过组合多个决策树来进行分类和回归。每个决策树都是独立训练的,并且最终结果是由投票或平均预测结果得出的。随机森林具有较高的准确性和鲁棒性,并且可以处理大量特征。
m3 = 'Random Forest Classfier'
rf = RandomForestClassifier(n_estimators=20, random_state=12,max_depth=5)
rf.fit(X_train,y_train)
rf_predicted = rf.predict(X_test)
rf_conf_matrix = confusion_matrix(y_test, rf_predicted)
rf_acc_score = accuracy_score(y_test, rf_predicted)
print("confussion matrix")
print(rf_conf_matrix)
print("\n")
print("Accuracy of Random Forest:",rf_acc_score*100,'\n')
print(classification_report(y_test,rf_predicted))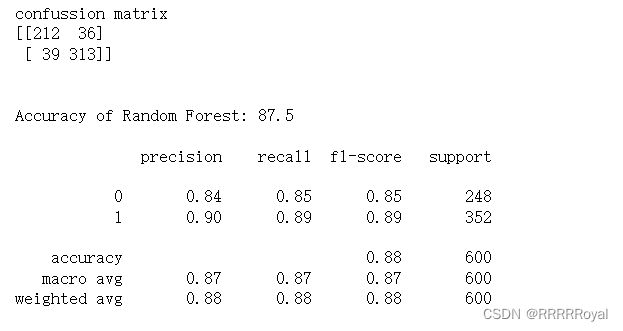
XGBoost
XGBoost是一个梯度提升框架,用于处理分类、回归和排序等机器学习问题。它通过迭代的方式,逐步优化模型的预测能力。XGBoost具有高效和可扩展的特性,并在许多Kaggle竞赛中表现出色。
from sklearn.model_selection import RandomizedSearchCV
import scipy
# 定义待搜索的超参数
params = {
'learning_rate': scipy.stats.uniform(0.01, 1),
'max_depth': scipy.stats.randint(3, 10),
'gamma': scipy.stats.uniform(0, 1),
'subsample': scipy.stats.uniform(0.5, 0.5),
'colsample_bytree': scipy.stats.uniform(0.5, 0.5),
'reg_lambda': scipy.stats.uniform(0, 2),
'booster': ['gbtree', 'dart'],
'colsample_bylevel': scipy.stats.uniform(0.5, 0.5),
'colsample_bynode': scipy.stats.uniform(0.5, 0.5)
}
# 实例化 XGBClassifier 模型
xgb = XGBClassifier(seed=27)
# 使用 RandomizedSearchCV 进行交叉验证
random_search = RandomizedSearchCV(estimator=xgb, param_distributions=params, cv=5, n_jobs=-1, n_iter=100)
random_search.fit(X_train, y_train)
# 输出最佳参数
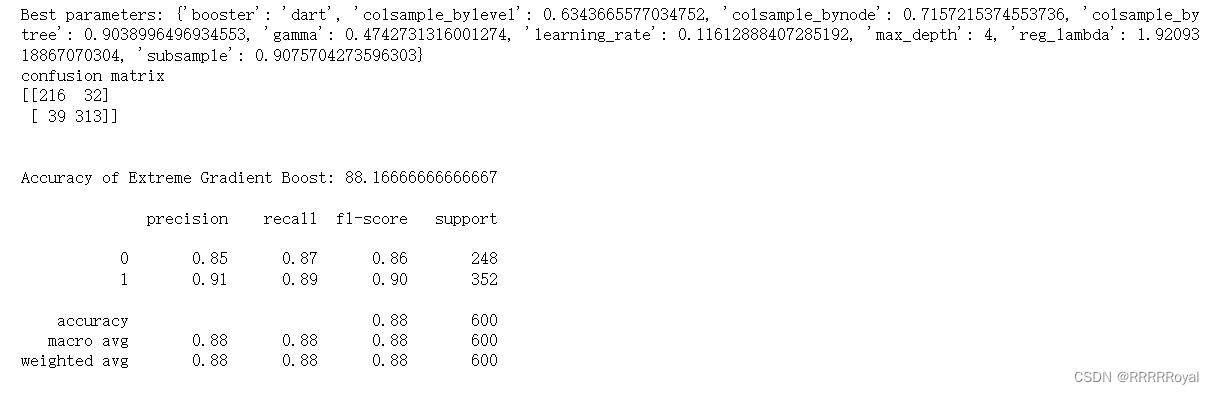
print("Best parameters:", random_search.best_params_)
# 使用最佳参数重新训练模型并预测测试集
best_xgb = random_search.best_estimator_
best_xgb.fit(X_train, y_train)
xgb_predicted = best_xgb.predict(X_test)
xgb_conf_matrix = confusion_matrix(y_test, xgb_predicted)
xgb_acc_score = accuracy_score(y_test, xgb_predicted)
print("confusion matrix")
print(xgb_conf_matrix)
print("\n")
print("Accuracy of Extreme Gradient Boost:", xgb_acc_score*100, '\n')
print(classification_report(y_test, xgb_predicted))
源码与论文资料领取链接:
领取链接https://s.pdb2.com/pages/20231107/cNttH3oeFf2ifi6.html
KNN
K最近邻是一种基于实例的分类算法。它将新样本分类为最接近它的K个邻居的多数类别。KNN算法没有显式的训练过程,而是通过记住训练数据集来进行分类。KNN算法可以应用于分类和回归问题。
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import ShuffleSplit
m5 = 'K-NeighborsClassifier'
knn = KNeighborsClassifier()
# 设置模型参数空间
param_dist = {
'n_neighbors': range(1, 30),
'weights': ['uniform', 'distance'],
'metric': ['euclidean', 'manhattan', 'minkowski']
}
# 定义随机搜索
rand_search = RandomizedSearchCV(knn,
param_distributions=param_dist,
n_iter=100,
cv=ShuffleSplit(n_splits=10),
scoring='accuracy',
random_state=42)
# 拟合模型并输出搜索最佳参数
rand_search.fit(X_train, y_train)
print("Best Parameters: ", rand_search.best_params_)
# 使用最佳参数的模型来进行预测
knn_predicted = rand_search.predict(X_test)
# 计算模型预测准确率,并输出混淆矩阵与分类报告
knn_acc_score = accuracy_score(y_test, knn_predicted)
knn_conf_matrix = confusion_matrix(y_test, knn_predicted)
print("confussion matrix")
print(knn_conf_matrix)
print("\n")
print("Accuracy of K-NeighborsClassifier:",knn_acc_score*100,'\n')
print(classification_report(y_test,knn_predicted))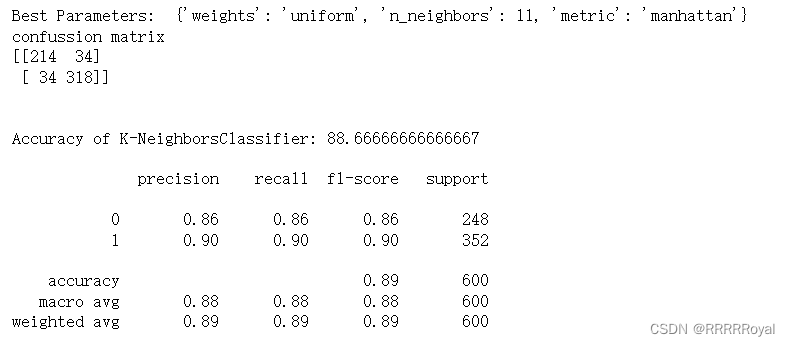
SVC
支持向量机是一种线性和非线性分类器。它通过在特征空间中找到一个最优超平面来进行分类,从而最大化样本之间的间隔。支持向量机可以处理高维数据,且对于特征不平衡的数据具有较好的效果。
from sklearn.model_selection import GridSearchCV
# 定义要调优的超参数候选值
param_grid = {'C': [0.1, 1, 10, 100], 'gamma': [0.1, 1, 10, 100]}
# 创建一个SVM分类器对象
svc = SVC(kernel='rbf', probability=True, random_state=42)
# 使用GridSearchCV进行交叉验证和超参数调整
grid_search = GridSearchCV(estimator=svc, param_grid=param_grid, cv=5)
# 在训练数据上拟合(训练和交叉验证)
grid_search.fit(X_train, y_train)
# 输出最佳参数和对应的准确度
print("Best Parameters: ", grid_search.best_params_)
print("Best Accuracy: ", grid_search.best_score_)
# 使用最佳参数构建最终模型
best_svc = grid_search.best_estimator_
best_svc.fit(X_train, y_train)
# 使用最终模型预测测试数据
svc_predicted = best_svc.predict(X_test)
# 生成混淆矩阵并计算准确度
svc_conf_matrix = confusion_matrix(y_test, svc_predicted)
svc_acc_score = accuracy_score(y_test, svc_predicted)
# 打印混淆矩阵和准确度
print("Confusion Matrix:")
print(svc_conf_matrix)
print("\n")
print("Accuracy of Support Vector Classifier:", svc_acc_score * 100, '\n')
# 输出测试集上的分类报告
print(classification_report(y_test, svc_predicted))
源码与论文资料领取链接:

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)