
SpringAI+DeepSeek大模型应用开发——1 认识AI
先大概介绍了一下AI,包括人工智能的发展和大模型的原理。
1 认识AI
1.1 人工智能发展
-
AI,人工智能(Artificial Intelligence),使机器能够像人类一样思考、学习和解决问题的技术;
-
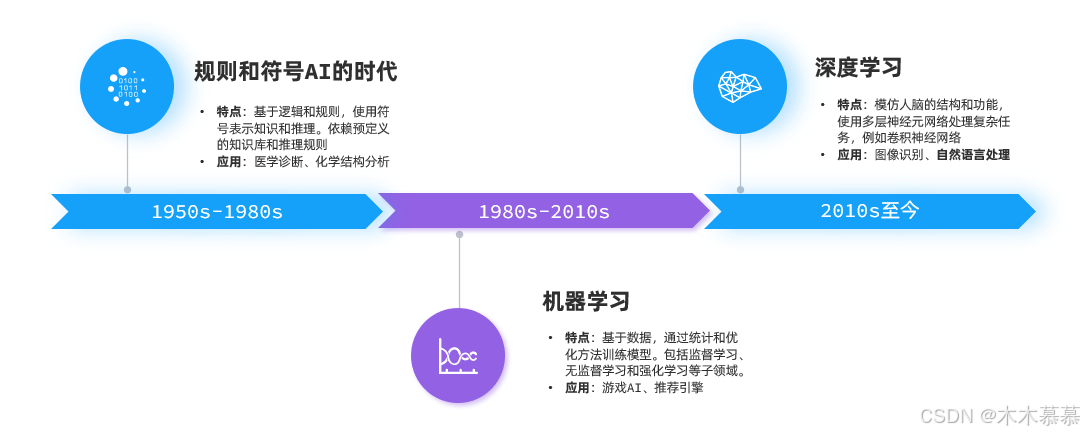
AI发展至今大概可以分为三个阶段:
-
其中,深度学习领域的自然语言处理(Natural Language Processing, NLP)有一个关键技术叫做Transformer,这是一种由多层感知机组成的神经网络模型,是现如今AI高速发展的最主要原因;
-
我们所熟知的大模型(Large Language Models, LLM),例如GPT、DeepSeek底层都是采用Transformer神经网络模型;
-
以GPT模型为例,其三个字母的缩写分别是Generative、Pre-trained、Transformer:

1.2 大模型原理
-
其实,最早Transformer是由Google在2017年提出的一种神经网络模型,一开始的作用是把它作为机器翻译的核心:
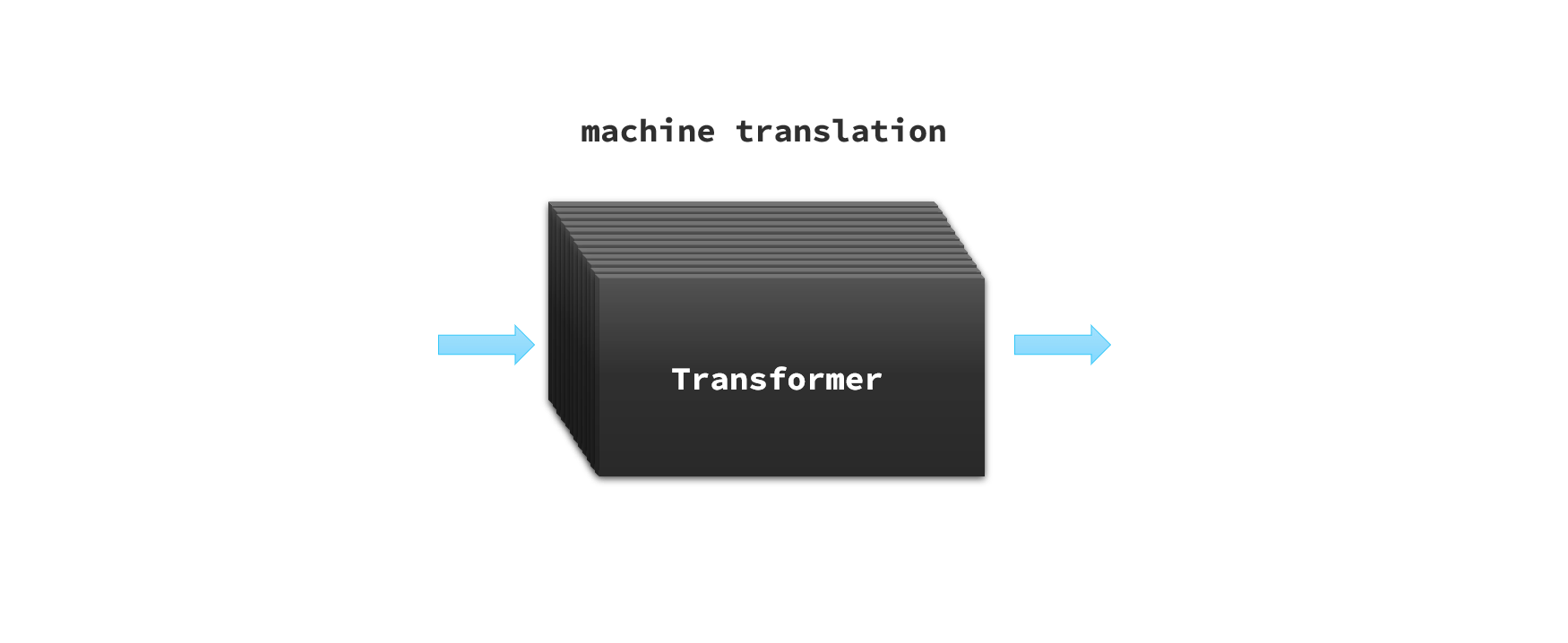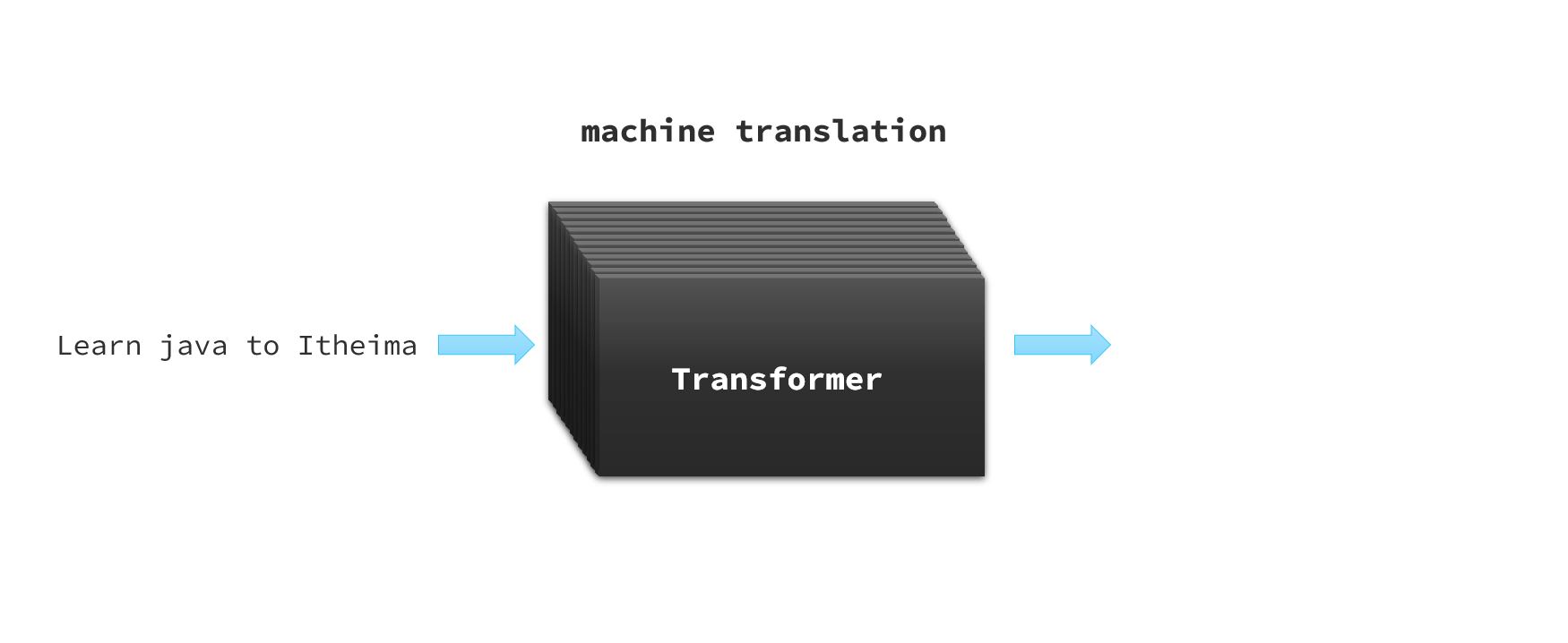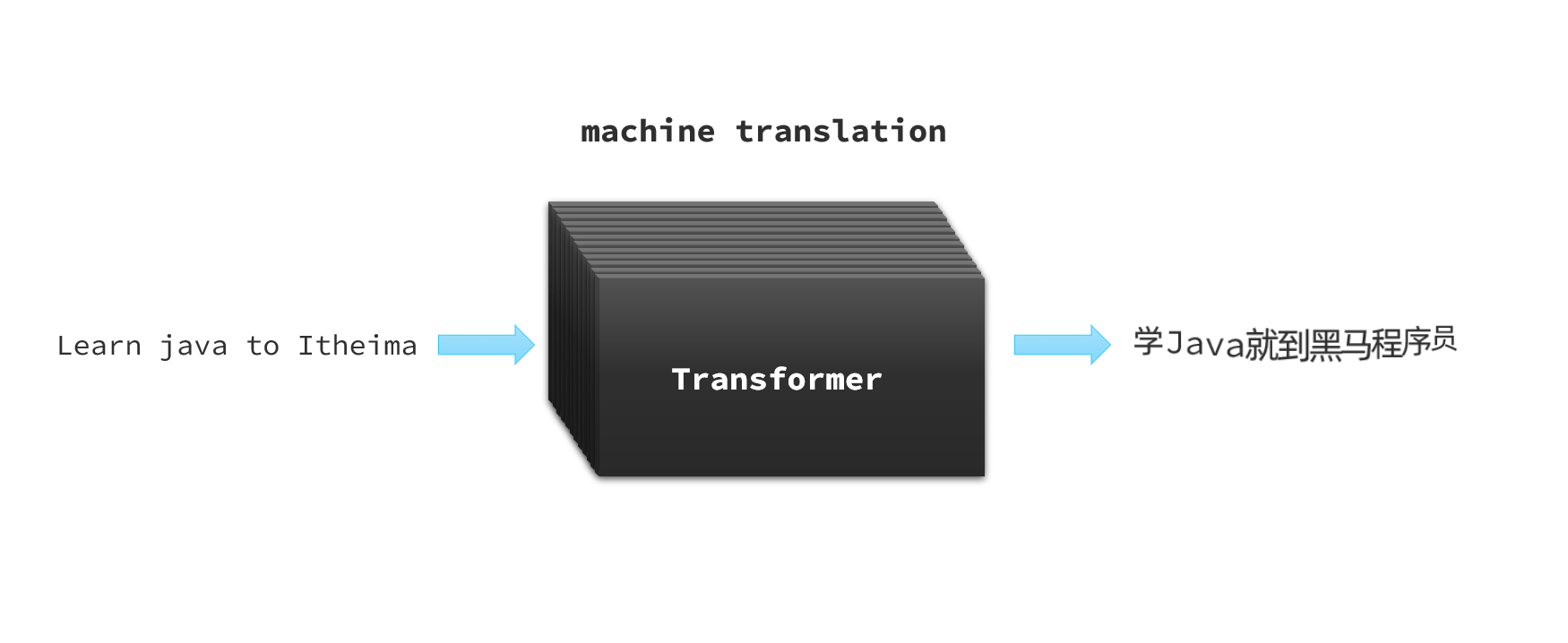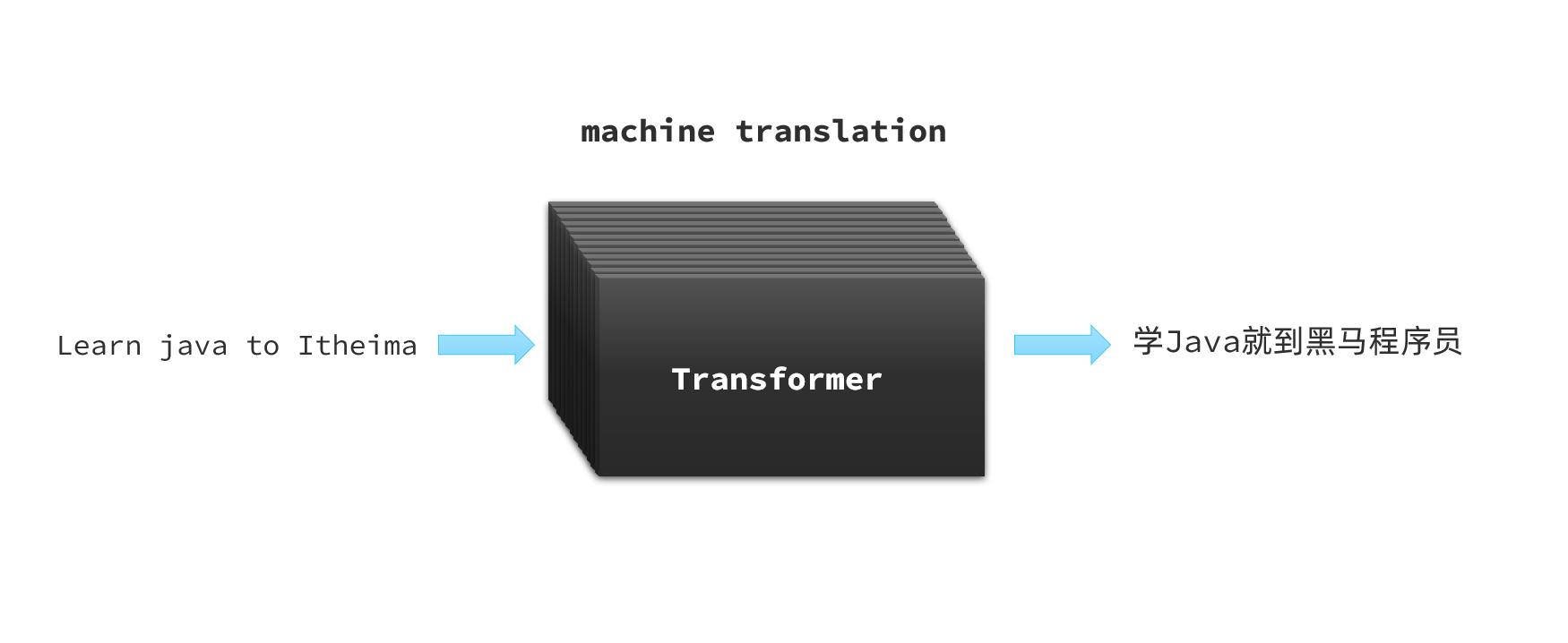
-
Transformer中提出的注意力机制使得神经网络在处理信息时可以根据上下内容调整对数据的理解,变得更加智能化。这不仅仅是说人类的文字,包括图片、音频数据都可以交给Transformer来处理。于是,越来越多的模型开始基于Transformer实现了各种神奇的功能;
-
例如,有的模型可以根据音频生成文本,或者根据文本生成音频:

-
还有的模型则可以根据文字生成图片,比如Dall-E、MidJourney:
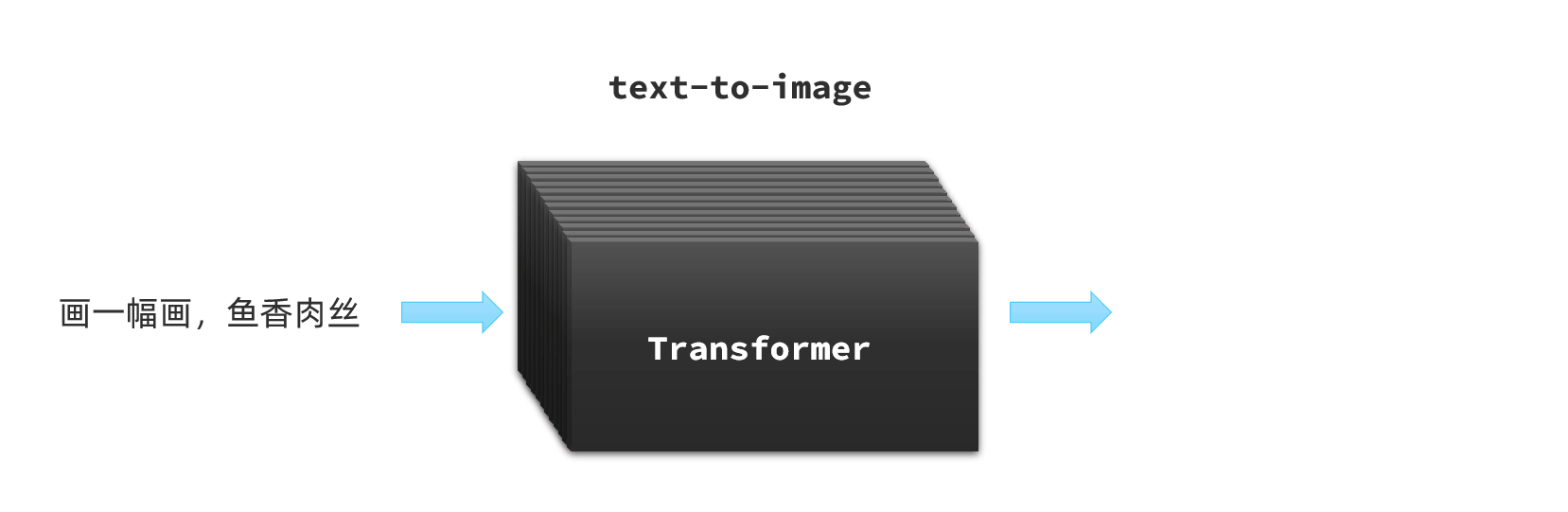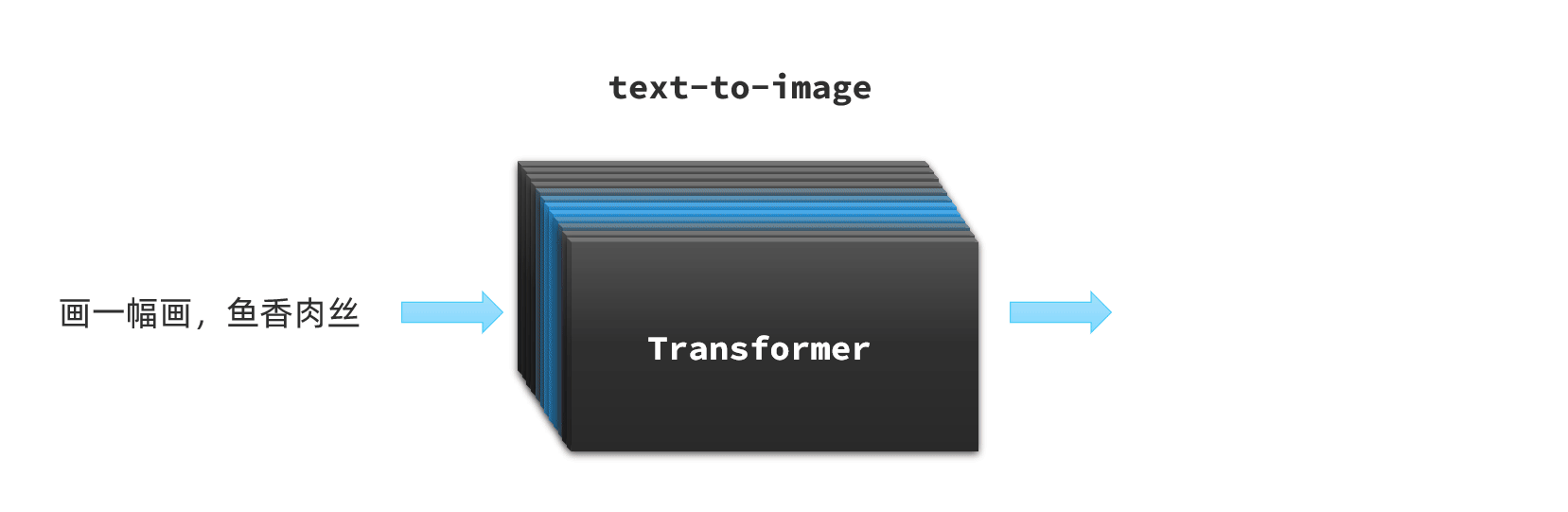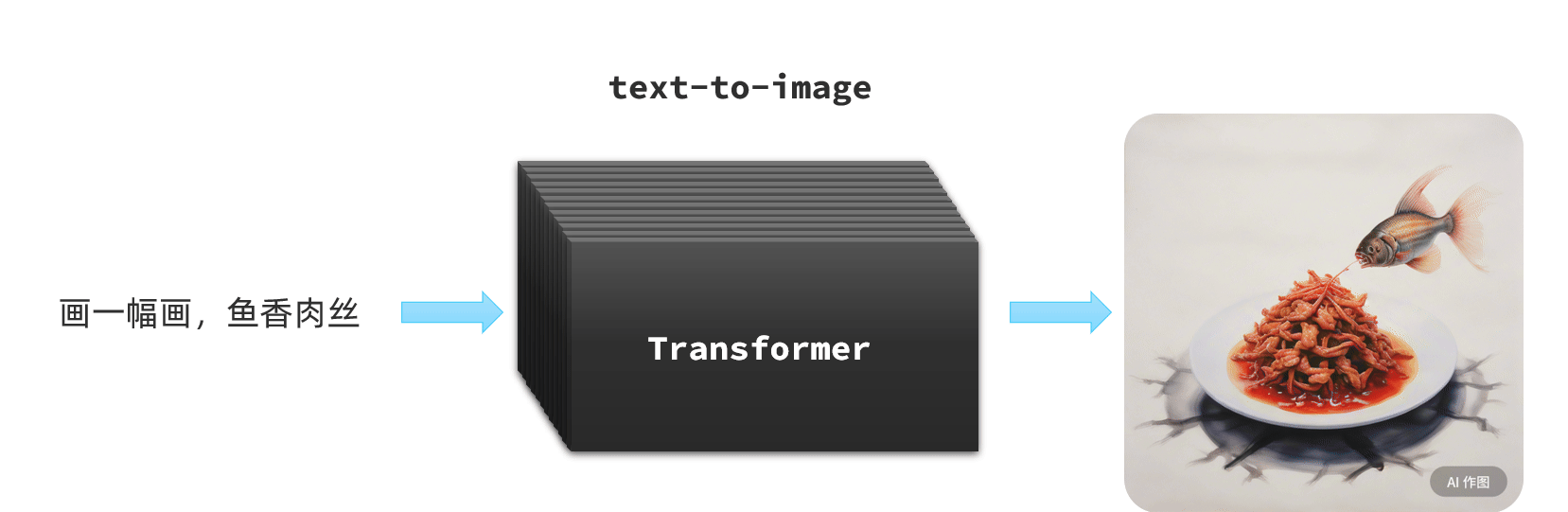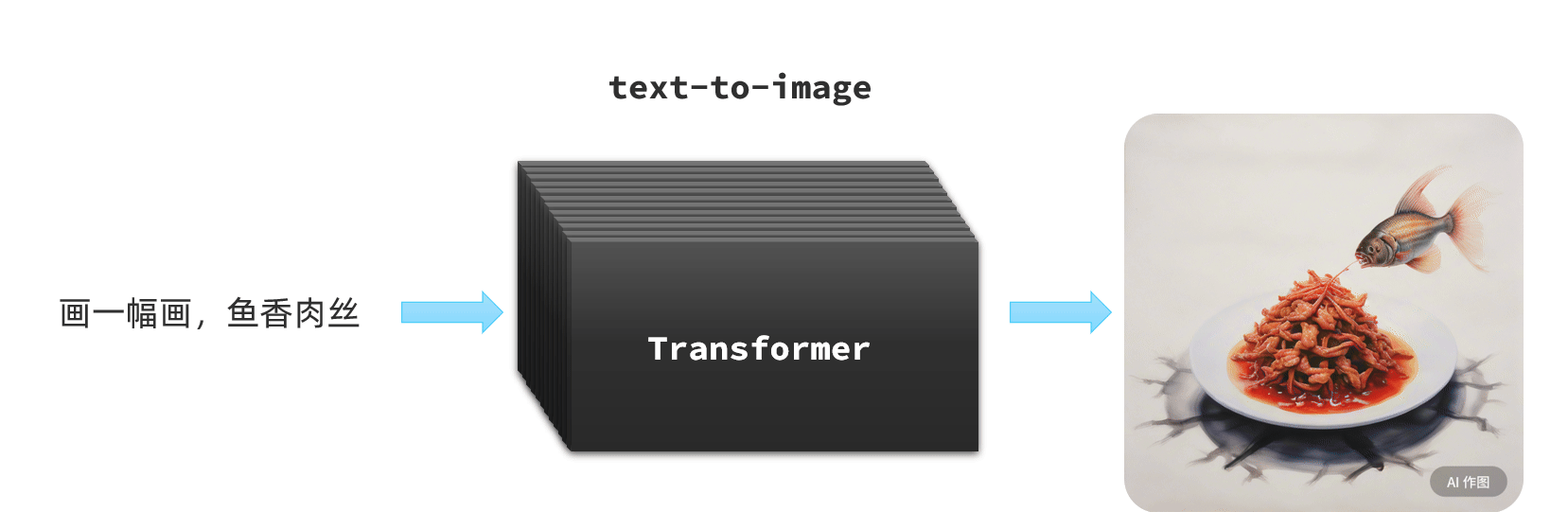
-
-
不过,我们今天要聊的大语言模型(Large Language Models, 以下简称LLM)是对Transformer的另一种用法:推理预测;
-
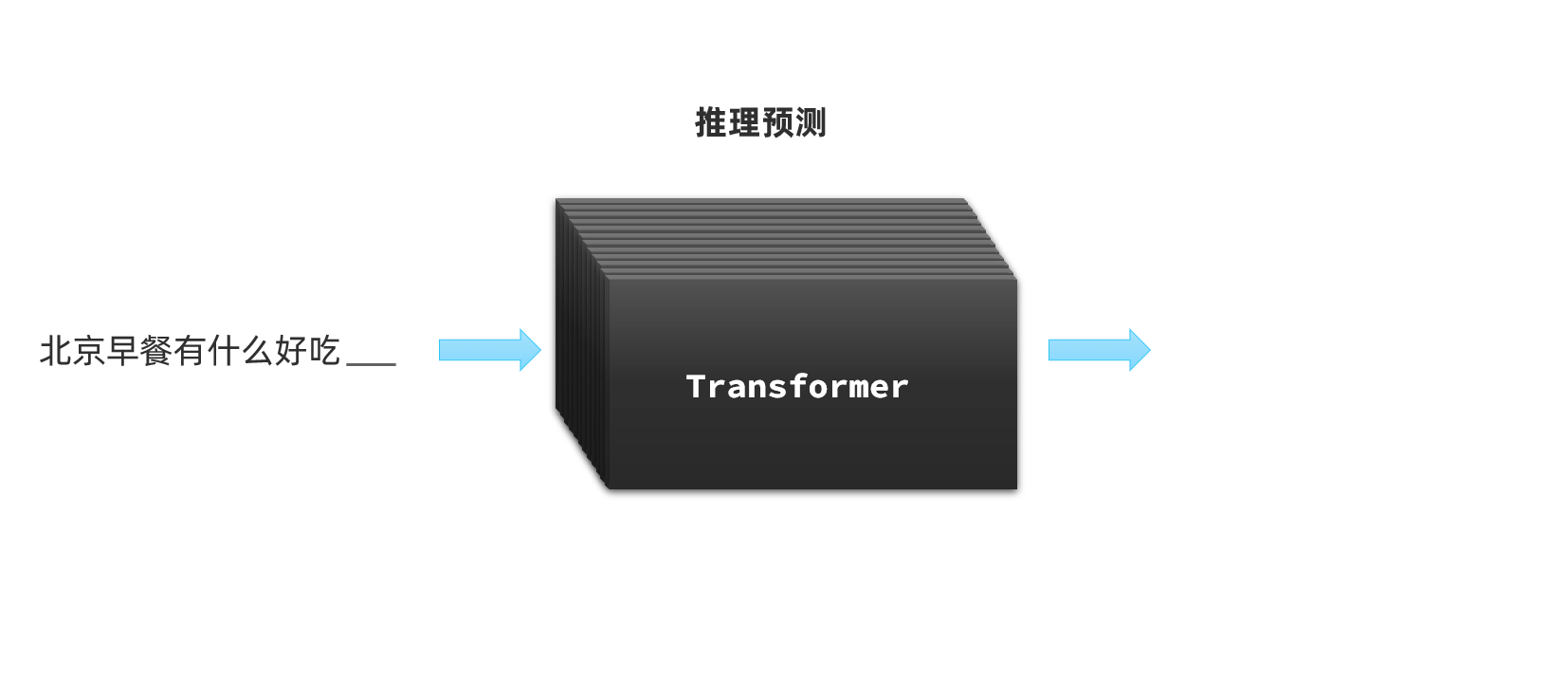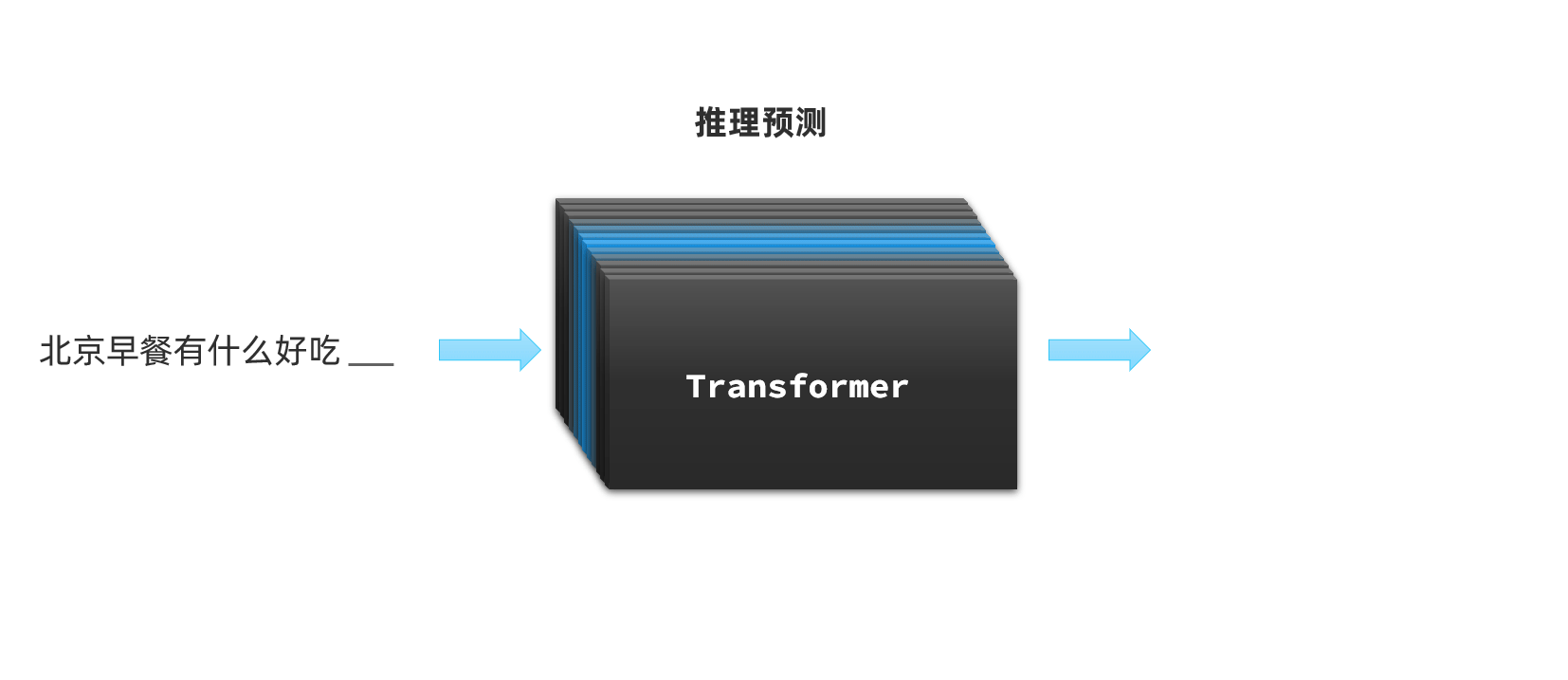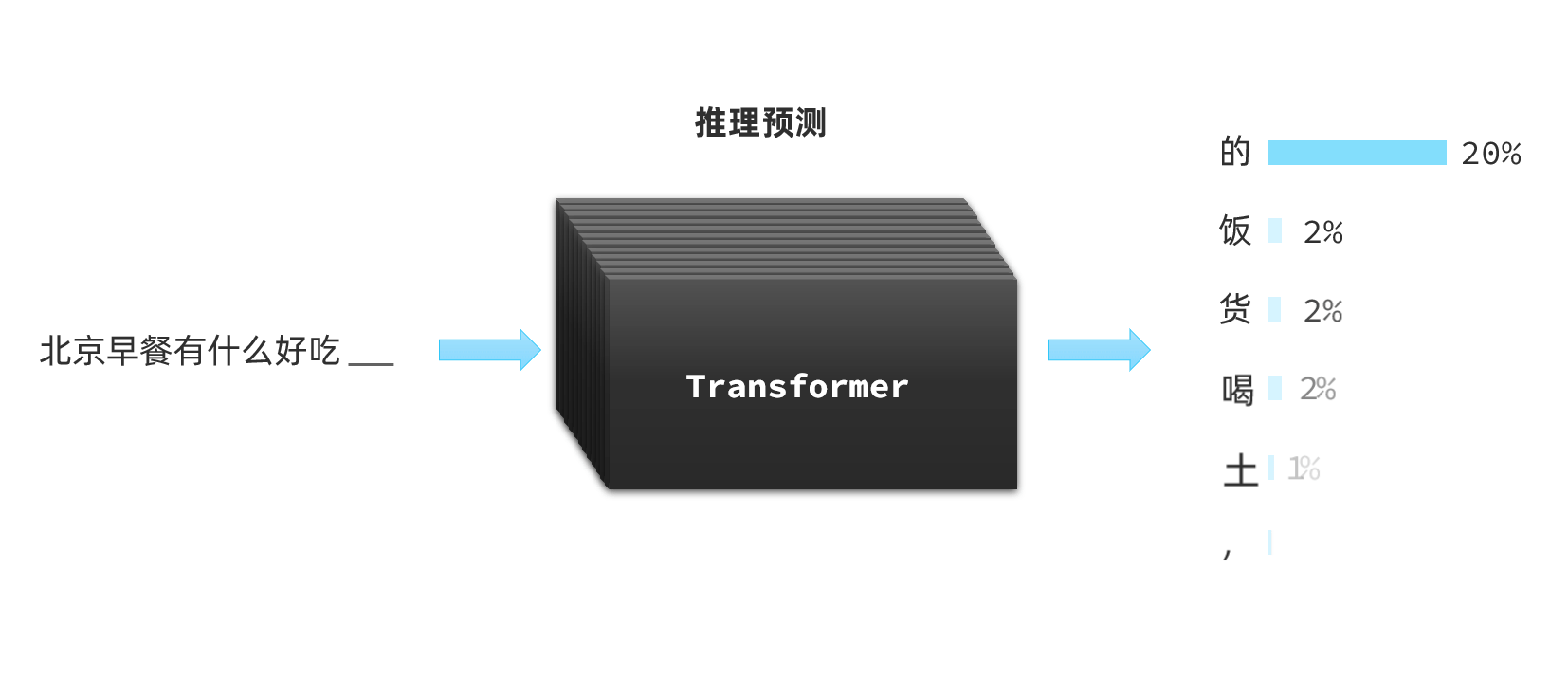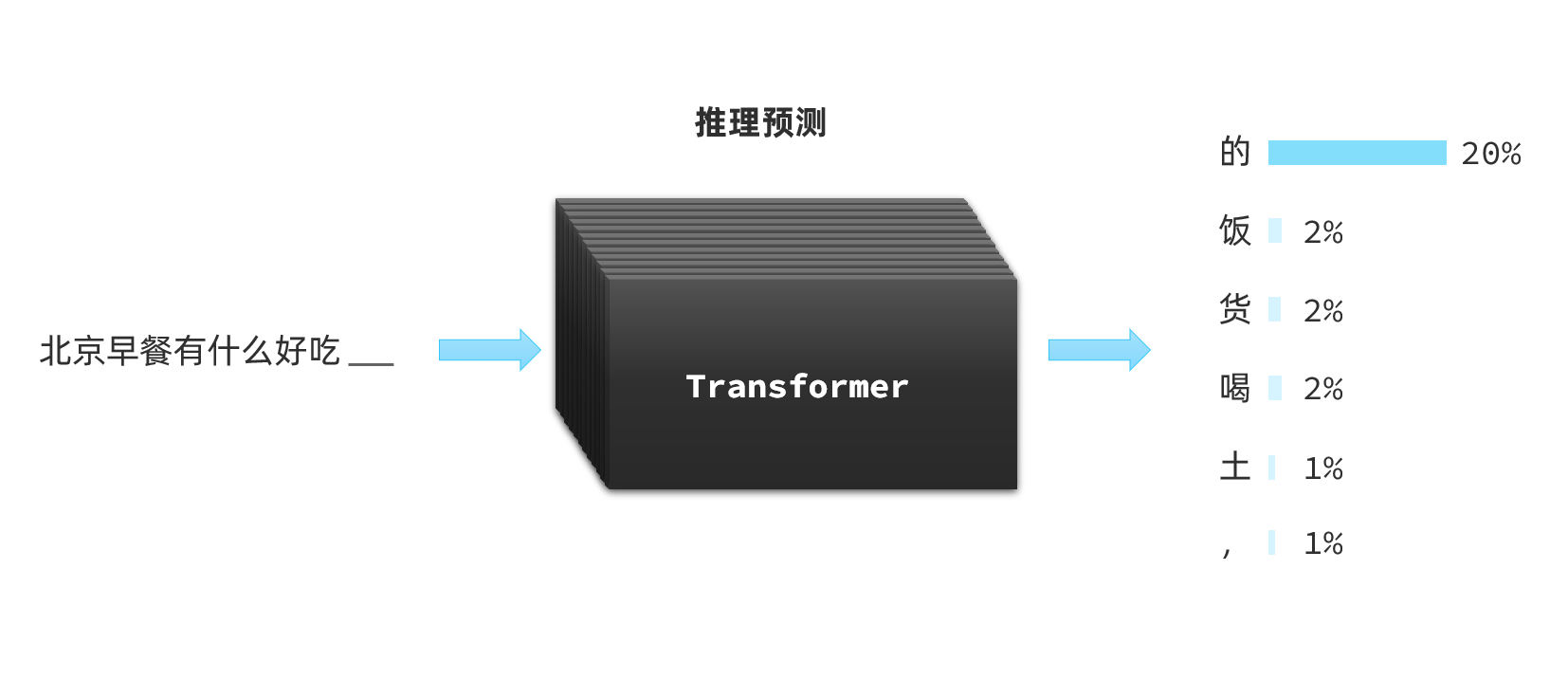
LLM在训练Transformer时会尝试输入一些文本、音频、图片等信息,然后让Transformer推理接下来跟着的应该是什么内容。推理的结果会以概率分布的形式出现:
-
问:仅仅是推测接下来的内容,怎么能让ChatGPT在对话中生成大段的有关联的文字内容呢?
-
其实LLM采用的就是笨办法,答案就是:持续生成;
-
根据前文推测出接下来的一个词语后,把这个词语加入前文,再次交给大模型处理,推测下一个字,然后不断重复前面的过程,就可以生成大段的内容了:

-
这就是为什么我们跟AI聊天的时候,它生成的内容总是一个字一个字的输出的原因了;
-
以上就是LLM的核心技术,Transformer的原理了;
-
-
如果想要进一步搞清楚Transformer机制,可以参考以下两个视频:

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 30
30 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)