
多模态大模型LLaVA的介绍、部署、推理及Lora微调
本文主要详细介绍了LLaVA模型的架构,并做了不同版本的对比。同时针对LLaVA-v1.6-Mistral-7B,做了模型的部署、推理以及Lora微调工作。最后,总结了此过程中可能遇到的常见错误,分析并给出了解决办法。
前言
LLaVA 是一个由威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学的研究人员开发的开源的、端到端训练的大型多模态模型,结合了视觉编码器和语言模型,用于通用的视觉和语言理解。该模型可以执行多种任务,包括图像描述、图像查询、图像生成和视觉问答等。
一、模型介绍
1.1 架构
LLaVA主要由视觉编码器、语言模型和连接器组成,如下图:
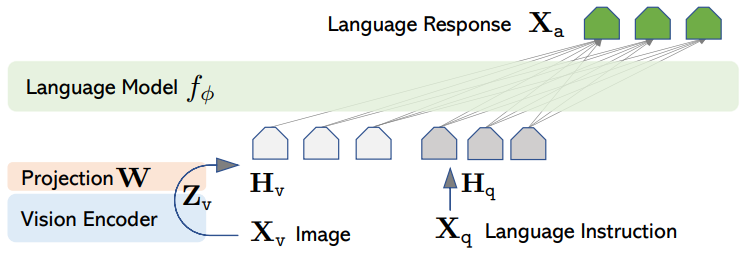
1.1.1 视觉编码器
通常使用预训练好的 CLIP 的 ViT-L/14 模型(比如clip-vit-large-patch14-336)。它的作用是将输入的图像编码成一系列有意义的视觉特征(视觉 token)。这一步负责“看懂”图片。
1.1.2 大语言模型
作为核心的“大脑”,负责语言理解和生成、推理。LLaVA 主要基于 Vicuna 构建(Vicuna 本身是基于 LLaMA 微调的对话模型),后续版本也支持其他 LLM 如 LLaMA、Mistral 等。LLaVA-1.5 开始,LLM 部分也扮演了“视觉推理”的角色。
1.1.3 连接器
这是 LLaVA 的关键创新之一。它负责将视觉编码器输出的高维视觉特征“翻译”成 LLM 能够理解的语言模型空间中的特征向量(类似于文本 token)。早期的连接器是一个简单的线性层(全连接层)(如v1版本),后来也探索了MLP(如v1.5和v1.6版本)、Gated Cross-attention等更复杂的结构 。连接器需要从头开始训练,以弥合视觉和语言模态之间的鸿沟。
大致的工作流程如下图:
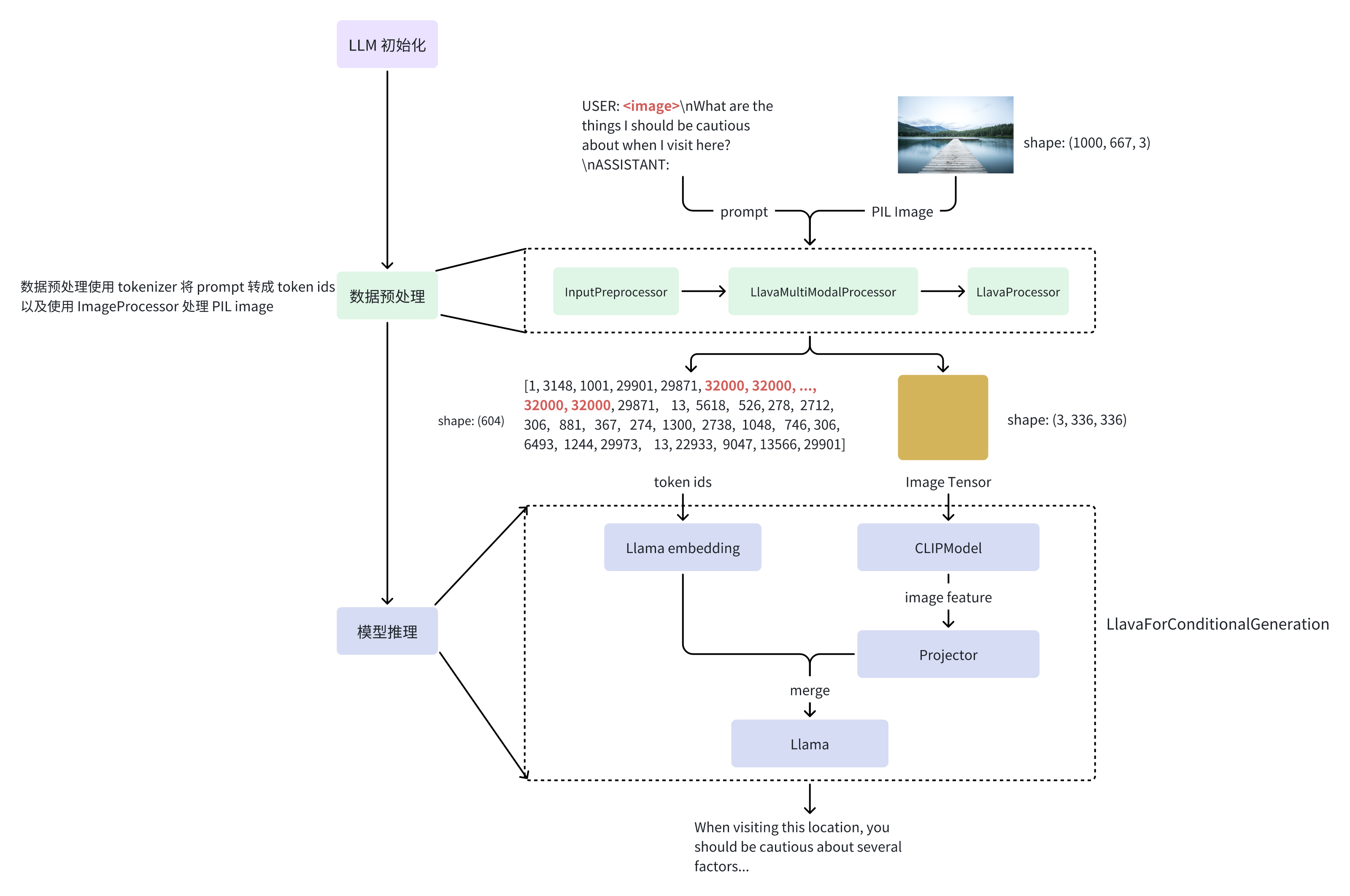
1.2 版本
| 模型版本 | 输入图片分辨率 | 视觉编码器 | 大语言模型 | 连接器 | 关键改进 |
|---|---|---|---|---|---|
| LLaVA | 224×224 | CLIP-ViT-L/14(224px训练) | Vicuna-7B | 单层全连接层(FC) | 初代多模态对齐框架 |
| LLaVA-v1.5 | 336×336 | CLIP-ViT-L-336px(336px微调) |
Vicuna-1.5-7B Vicuna-1.5-13B |
2层MLP(增强特征投影) | 更高分辨率输入、数据多样性增强 |
| LLaVA-v1.6 | 336×336 | CLIP-ViT-L-336px(336px微调) |
Vicuna-1.5-7B Vicuna-1.5-13B Mistral-7B Nous-Hermes-2-Yi-34B |
2层MLP(优化参数,提升跨模态对齐) | 动态分辨率支持、多样化LLM适配、专用场景数据扩展(OCR、图表、文档理解) |
二、 模型部署
本文以LLaVA-v1.6-Mistral-7B为例,开展模型的部署、推理及微调工作。
2.1 部署
2.1.1 LLaVA代码下载
首先,从github官网下载LLaVA代码(由于论文作者的源代码没有关于v1.6的微调代码,因此我们下载arielnlee大佬写好的项目):
方法一:
git clone https://github.com/arielnlee/LLaVA-1.6-ft.git
cd LLaVA-1.6-ft方法二:
直接进入github官网,将代码下载到本地:
https://github.com/arielnlee/LLaVA-1.6-ft.git
2.1.2 配置环境
在Linux系统(以Ubuntu 22.04为例)中,逐条运行以下命令,创建虚拟环境,并安装依赖包:
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip # enable PEP 660 support
pip install -e .此时系统有可能安装的是cpu版本的pytorch。如果确认是cpu版本,执行以下命令,可以安装对应的gpu版本(建议cuda版本安装为12.1):
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia #安装pytorch,此命令会安装部分cuda
conda install -c "nvidia/label/cuda-12.1.0" cuda-toolkit #安装剩余cuda组件如果需要训练模型,则还需安装以下依赖包:
pip install -e ".[train]"
pip install flash-attn --no-build-isolation最后,执行以下命令,确保所下载的LLaVA为最新版本:
git pull2.2 推理
在开始推理之前,需要下载两部分预训练权重:
(1)从hugging Face官网下载LLaVA-v1.6-Mistral-7B的预训练权重:https://huggingface.co/liuhaotian/llava-v1.6-mistral-7b/tree/main
(2)从hugging Face官网下载视觉编码器clip-vit-large-patch14-336的权重,并修改LLaVA-v1.6-Mistral-7B预训练权重文件夹中的config.json文件中的“mm_vision_tower”为clip-vit-large-patch14-336权重文件夹的路径:https://huggingface.co/openai/clip-vit-large-patch14-336/tree/main
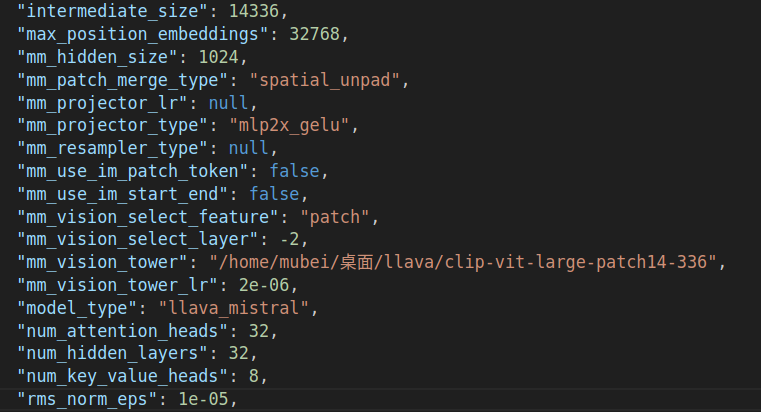
下面正式开始模型的推理。可以运行模型自带的eval脚本,也可以自己编码。下面以我编写的eval脚本为例,说明推理的大致流程:
import torch
from llava.model import LlavaMistralForCausalLM
from llava.mm_utils import tokenizer_image_token
from llava.mm_utils import process_images
from llava.constants import DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX
from llava.conversation import conv_templates, SeparatorStyle
from transformers import AutoTokenizer
from PIL import Image
DEFAULT_IMAGE_PATCH_TOKEN = "<im_patch>"
DEFAULT_IM_START_TOKEN = "<im_start>"
DEFAULT_IM_END_TOKEN = "<im_end>"
tokenizer = None
model = None
image_processor = None
#下载模型
def load_model(load_8bit=False, device_map="auto", device="cuda", use_flash_attn=False):
global tokenizer, model, image_processor
kwargs = {"device_map": device_map}
if device != "cuda":
kwargs['device_map'] = {"": device}
if load_8bit:
kwargs['load_in_8bit'] = True
else:
kwargs['torch_dtype'] = torch.float16
if use_flash_attn:
kwargs['attn_implementation'] = 'flash_attention_2'
# 预训练权重的路径
base_model_path = "/home/mubei/桌面/llava/llava-v1.6-mistral-7b-hf2" #保存下载的LLaVA-v1.6-Mistral-7B预训练权重的文件夹
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
# 加载模型
model = LlavaMistralForCausalLM.from_pretrained(
base_model_path,
low_cpu_mem_usage=True,
**kwargs
)
# 加载image_processor
image_processor = None
mm_use_im_start_end = getattr(model.config, "mm_use_im_start_end", False)
mm_use_im_patch_token = getattr(model.config, "mm_use_im_patch_token", True)
if mm_use_im_patch_token:
tokenizer.add_tokens([DEFAULT_IMAGE_PATCH_TOKEN], special_tokens=True)
if mm_use_im_start_end:
tokenizer.add_tokens([DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True)
model.resize_token_embeddings(len(tokenizer))
vision_tower = model.get_vision_tower()
if not vision_tower.is_loaded:
vision_tower.load_model(device_map=device_map)
if device_map != 'auto':
vision_tower.to(device=device_map, dtype=torch.float16)
image_processor = vision_tower.image_processor
return model, tokenizer, image_processor
def main():
# 下载模型
model, tokenizer, image_processor = load_model(load_8bit=False)
# 设置图像和提示
image = Image.open("/home/mubei/桌面/llava/LLaVA-1.6-ft-main/mllm_demo_data/3.jpg").convert('RGB')
prompt = "请描述这张图片"
# 创建对话模板
conv = conv_templates["mistral_direct"].copy()
# 处理提示:添加图像标记
prompt = DEFAULT_IMAGE_TOKEN + "\n" + prompt
# 将提示添加到对话
conv.append_message(conv.roles[0], prompt)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
# 处理图像
image_tensor = process_images([image], image_processor, model.config).to(model.device, dtype=torch.float16)
# 对文本进行分词
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt").unsqueeze(0).cuda()
# 生成attention_mask并设置pad_token_id
attention_mask = input_ids.ne(tokenizer.pad_token_id).int().cuda()
# 准备停止标记
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
# 模型推理
with torch.inference_mode():
output_ids = model.generate(
input_ids,
attention_mask=attention_mask,
images=image_tensor,
image_sizes=[image.size],
do_sample = 0,
temperature=1e-5,
top_p=None,
num_beams=1,
max_new_tokens=512,
use_cache=None,
pad_token_id=tokenizer.pad_token_id
)
#解码输出
outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:]).strip()
outputs = outputs.split(stop_str)[0]
print(f"输入: {prompt}")
print(f"输出: {outputs}")
if __name__ == '__main__':
main()运行以上代码,可以得到以下输出:


可以看出,模型的描述基本属实,展示了LLaVA-v1.6-Mistral-7B优异的视觉问答能力。
2.3 Lora微调
2.3.1 数据集准备
LLaVA-v1.6-Mistral-7B模型训练所需的数据格式如下所示:
{
"conversations": [
{"from": "human", "value": "<image>\nWhat is in this image?"},
{"from": "gpt", "value": "The image shows..."}
]
"images": ["image.jpg"]
}
可以看出,“conversations”包含"from"和"value"字段,“images”则包含具体的图片。因此,我们将LLaVA官方提供的mllm_demo.json数据集改写成此种格式。具体数据集如下:
[
{
"conversations": [
{
"value": "<image>Who are they?",
"from": "human"
},
{
"value": "They're Kane and Gretzka from Bayern Munich.",
"from": "gpt"
},
{
"value": "What are they doing?<image>",
"from": "human"
},
{
"value": "They are celebrating on the soccer field.",
"from": "gpt"
}
],
"images": [
"1.jpg",
"1.jpg"
]
},
{
"conversations": [
{
"value": "<image>Who is he?",
"from": "human"
},
{
"value": "He's Thomas Muller from Bayern Munich.",
"from": "gpt"
},
{
"value": "Why is he on the ground?",
"from": "human"
},
{
"value": "Because he's sliding on his knees to celebrate.",
"from": "gpt"
}
],
"images": [
"2.jpg"
]
},
{
"conversations": [
{
"value": "<image>Please describe this image",
"from": "human"
},
{
"value": "Chinese astronaut Gui Haichao is giving a speech.",
"from": "gpt"
},
{
"value": "What has he accomplished?",
"from": "human"
},
{
"value": "He was appointed to be a payload specialist on Shenzhou 16 mission in June 2022, thus becoming the first Chinese civilian of Group 3 in space on 30 May 2023. He is responsible for the on-orbit operation of space science experimental payloads.",
"from": "gpt"
}
],
"images": [
"3.jpg"
]
},
{
"conversations": [
{
"value": "<image>他们是谁?",
"from": "human"
},
{
"value": "他们是拜仁慕尼黑的凯恩和格雷茨卡。",
"from": "gpt"
},
{
"value": "他们在做什么?<image>",
"from": "human"
},
{
"value": "他们在足球场上庆祝。",
"from": "gpt"
}
],
"images": [
"1.jpg",
"1.jpg"
]
},
{
"conversations": [
{
"value": "<image>他是谁?",
"from": "human"
},
{
"value": "他是来自拜仁慕尼黑的托马斯·穆勒。",
"from": "gpt"
},
{
"value": "他为什么在地上?",
"from": "human"
},
{
"value": "因为他正在双膝跪地滑行庆祝。",
"from": "gpt"
}
],
"images": [
"2.jpg"
]
},
{
"conversations": [
{
"value": "<image>请描述这张图片",
"from": "human"
},
{
"value": "中国宇航员桂海潮正在讲话。",
"from": "gpt"
},
{
"value": "他取得过哪些成就?",
"from": "human"
},
{
"value": "他于2022年6月被任命为神舟十六号任务的有效载荷专家,从而成为2023年5月30日进入太空的首位平民宇航员。他负责在轨操作空间科学实验有效载荷。",
"from": "gpt"
}
],
"images": [
"3.jpg"
]
}
]2.3.2 微调
在微调之前,我们需要打开finetune_lora_llava_mistral.sh文件,修改LLaVA-v1.6-Mistral-7B预训练权重的路径、视觉编码器预训练权重的路径、数据集路径及其对应的图片文件夹路径。如下:
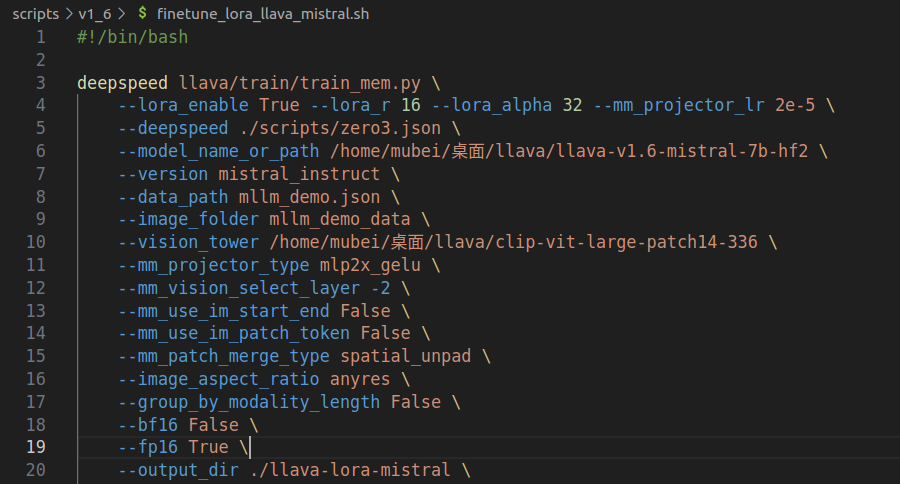
由于arielnlee大佬已添加并完善LLaVA-v1.6-Mistral-7B的Lora微调代码,因此我们可以直接调用。在终端直接运行以下命令,即可开始Lora的微调:
bash scripts/v1_6/finetune_lora_llava_mistral.sh以下是微调过程的输出:
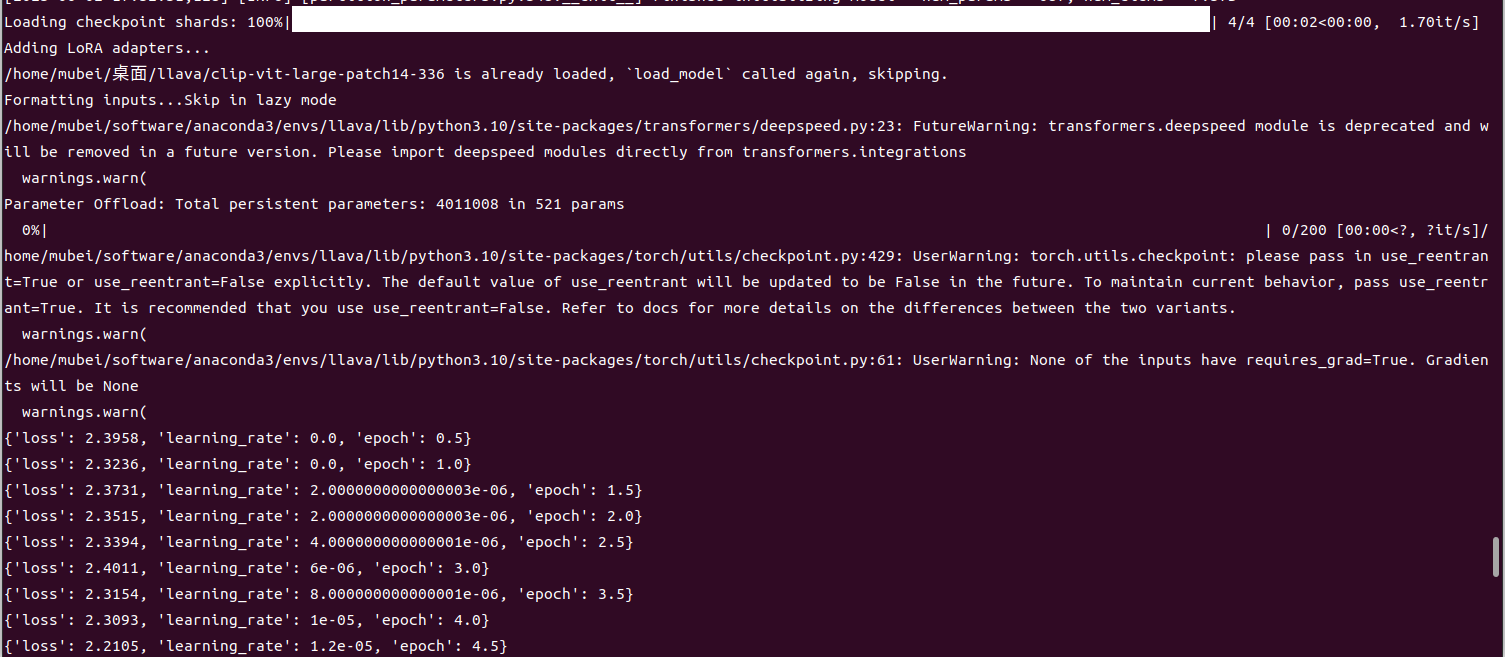
2.4 权重合并
在微调结束后,我们需要将训练之后得到的权重和原始的预训练权重合并,以得到最终的、可用于推理测试的权重。
使用以下代码,可以得到合并后的权重:
# 加载原始模型
base_model = LlavaMistralForCausalLM.from_pretrained(
base_model_path,
low_cpu_mem_usage=True,
**kwargs
)
# 加载 LoRA 适配器
model = PeftModel.from_pretrained(
base_model,
finetuned_model_path,
adapter_name="default",
config=lora_config,
is_trainable=False
)
# 合并模型
model = model.merge_and_unload()因此,我们将以上代码添加到推理阶段,做Lora微调后的推理测试:
import torch
from llava.model import LlavaMistralForCausalLM
from llava.mm_utils import tokenizer_image_token
from llava.mm_utils import process_images
from llava.constants import DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX
from llava.conversation import conv_templates, SeparatorStyle
from transformers import AutoTokenizer
from PIL import Image
DEFAULT_IMAGE_PATCH_TOKEN = "<im_patch>"
DEFAULT_IM_START_TOKEN = "<im_start>"
DEFAULT_IM_END_TOKEN = "<im_end>"
tokenizer = None
model = None
image_processor = None
#下载模型
def load_model(load_8bit=False, device_map="auto", device="cuda", use_flash_attn=False):
global tokenizer, model, image_processor
kwargs = {"device_map": device_map}
if device != "cuda":
kwargs['device_map'] = {"": device}
if load_8bit:
kwargs['load_in_8bit'] = True
else:
kwargs['torch_dtype'] = torch.float16
if use_flash_attn:
kwargs['attn_implementation'] = 'flash_attention_2'
# 预训练权重的路径
base_model_path = "/home/mubei/桌面/llava/llava-v1.6-mistral-7b-hf2"
# 微调后生成的权重的路径
finetuned_model_path = "/home/mubei/桌面/llava/llava-v1.6-mistral-7b-hf2/lora/train_2025-05-31-20-11-53/checkpoint-100"
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
# 加载原始模型
base_model = LlavaMistralForCausalLM.from_pretrained(
base_model_path,
low_cpu_mem_usage=True,
**kwargs
)
# 加载 LoRA 适配器
model = PeftModel.from_pretrained(
base_model,
finetuned_model_path,
adapter_name="default",
config=lora_config,
is_trainable=False
)
# 合并模型
model = model.merge_and_unload()
# 加载image_processor
image_processor = None
mm_use_im_start_end = getattr(model.config, "mm_use_im_start_end", False)
mm_use_im_patch_token = getattr(model.config, "mm_use_im_patch_token", True)
if mm_use_im_patch_token:
tokenizer.add_tokens([DEFAULT_IMAGE_PATCH_TOKEN], special_tokens=True)
if mm_use_im_start_end:
tokenizer.add_tokens([DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True)
model.resize_token_embeddings(len(tokenizer))
vision_tower = model.get_vision_tower()
if not vision_tower.is_loaded:
vision_tower.load_model(device_map=device_map)
if device_map != 'auto':
vision_tower.to(device=device_map, dtype=torch.float16)
image_processor = vision_tower.image_processor
return model, tokenizer, image_processor
def main():
# 下载模型
model, tokenizer, image_processor = load_model(load_8bit=False)
# 设置图像和提示
image = Image.open("/home/mubei/桌面/llava/LLaVA-1.6-ft-main/mllm_demo_data/3.jpg").convert('RGB')
prompt = "请描述这张图片"
# 创建对话模板
conv = conv_templates["mistral_direct"].copy()
# 处理提示:添加图像标记
prompt = DEFAULT_IMAGE_TOKEN + "\n" + prompt
# 将提示添加到对话
conv.append_message(conv.roles[0], prompt)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
# 处理图像
image_tensor = process_images([image], image_processor, model.config).to(model.device, dtype=torch.float16)
# 对文本进行分词
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt").unsqueeze(0).cuda()
# 生成attention_mask并设置pad_token_id
attention_mask = input_ids.ne(tokenizer.pad_token_id).int().cuda()
# 准备停止标记
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
# 模型推理
with torch.inference_mode():
output_ids = model.generate(
input_ids,
attention_mask=attention_mask,
images=image_tensor,
image_sizes=[image.size],
do_sample = 0,
temperature=1e-5,
top_p=None,
num_beams=1,
max_new_tokens=512,
use_cache=None,
pad_token_id=tokenizer.pad_token_id
)
#解码输出
outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:]).strip()
outputs = outputs.split(stop_str)[0]
print(f"输入: {prompt}")
print(f"输出: {outputs}")
if __name__ == '__main__':
main()三、常见报错
3.1 环境依赖包下载错误
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 35, in <module>
File "/tmp/pip-install-fx3x4wsk/flash-attn_7983b6cadac94c4da9daa94f9301803d/setup.py", line 171, in <module>
_, bare_metal_version = get_cuda_bare_metal_version(CUDA_HOME)
File "/tmp/pip-install-fx3x4wsk/flash-attn_7983b6cadac94c4da9daa94f9301803d/setup.py", line 89, in get_cuda_bare_metal_version
raw_output = subprocess.check_output([cuda_dir + "/bin/nvcc", "-V"], universal_newlines=True)
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/subprocess.py", line 421, in check_output
return run(*popenargs, stdout=PIPE, timeout=timeout, check=True,
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/subprocess.py", line 503, in run
with Popen(*popenargs, **kwargs) as process:
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/subprocess.py", line 971, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/subprocess.py", line 1863, in _execute_child
raise child_exception_type(errno_num, err_msg, err_filename)
FileNotFoundError: [Errno 2] No such file or directory: '/home/mubei/software/anaconda3/envs/llava/bin/nvcc'
torch.__version__ = 2.1.2
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.以上错误是由于flash-attn的版本不匹配原因引起的,需要指定flash-attn的版本进行安装:
pip install flash-attn==2.7.3 --no-build-isolation3.2 模型导入错误
Traceback (most recent call last):
File "/home/mubei/桌面/llava/LLaVA-main/example.py", line 6, in <module>
from llava.model import LlavaMistralForCausalLM
File "/home/mubei/桌面/llava/LLaVA-main/llava/__init__.py", line 1, in <module>
from .model import LlavaLlamaForCausalLM
ImportError: cannot import name 'LlavaLlamaForCausalLM' from 'llava.model' (/home/mubei/桌面/llava/LLaVA-main/llava/model/__init__.py)以上错误出现的原因千奇百怪,我遇到的原因是deepspeed版本太低,运行以下命令,升级deepspeed,即可解决此错误:
pip install peepspeed==0.16.93.3 微调错误
(1)numpy版本不匹配
Traceback (most recent call last):
File "/home/mubei/桌面/llava/LLaVA-main/example.py", line 256, in <module>
main()
File "/home/mubei/桌面/llava/LLaVA-main/example.py", line 219, in main
image_tensor = process_images([image], image_processor, model.config).to(model.device, dtype=torch.float16)
File "/home/mubei/桌面/llava/LLaVA-main/llava/mm_utils.py", line 176, in process_images
image = process_anyres_image(image, image_processor, model_cfg.image_grid_pinpoints)
File "/home/mubei/桌面/llava/LLaVA-main/llava/mm_utils.py", line 143, in process_anyres_image
image_patches = [processor.preprocess(image_patch, return_tensors='pt')['pixel_values'][0]
File "/home/mubei/桌面/llava/LLaVA-main/llava/mm_utils.py", line 143, in <listcomp>
image_patches = [processor.preprocess(image_patch, return_tensors='pt')['pixel_values'][0]
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/transformers/models/clip/image_processing_clip.py", line 326, in preprocess
return BatchFeature(data=data, tensor_type=return_tensors)
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/transformers/feature_extraction_utils.py", line 78, in __init__
self.convert_to_tensors(tensor_type=tensor_type)
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/transformers/feature_extraction_utils.py", line 188, in convert_to_tensors
raise ValueError(
ValueError: Unable to create tensor, you should probably activate padding with 'padding=True' to have batched tensors with the same length.以上错误我的原因是numpy版本不匹配(但运行代码时系统并没有提示)。需指定numpy的版本进行安装:
pip install numpy==1.24.4(2)scipy版本不匹配
Traceback (most recent call last):
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1364, in _get_module
return importlib.import_module("." + module_name, self.__name__)
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/transformers/trainer.py", line 59, in <module>
from .data.data_collator import DataCollator, DataCollatorWithPadding, default_data_collator
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/transformers/data/__init__.py", line 26, in <module>
from .metrics import glue_compute_metrics, xnli_compute_metrics
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/transformers/data/metrics/__init__.py", line 19, in <module>
from scipy.stats import pearsonr, spearmanr
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/scipy/stats/__init__.py", line 624, in <module>
from ._stats_py import *
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/scipy/stats/_stats_py.py", line 39, in <module>
from scipy.spatial import distance_matrix
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/scipy/spatial/__init__.py", line 116, in <module>
from ._geometric_slerp import geometric_slerp
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/scipy/spatial/_geometric_slerp.py", line 7, in <module>
from scipy.spatial.distance import euclidean
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/scipy/spatial/distance.py", line 121, in <module>
from ..special import rel_entr
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/scipy/special/__init__.py", line 826, in <module>
from . import _basic
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/scipy/special/_basic.py", line 22, in <module>
from ._multiufuncs import (assoc_legendre_p_all,
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/scipy/special/_multiufuncs.py", line 142, in <module>
sph_legendre_p = MultiUFunc(
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/scipy/special/_multiufuncs.py", line 41, in __init__
raise ValueError("All ufuncs must have type `numpy.ufunc`."
ValueError: All ufuncs must have type `numpy.ufunc`. Received (<ufunc 'sph_legendre_p'>, <ufunc 'sph_legendre_p'>, <ufunc 'sph_legendre_p'>)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/mubei/桌面/llava/LLaVA-1.6-ft-main/llava/train/train_mem.py", line 1, in <module>
from llava.train.train import train
File "/home/mubei/桌面/llava/LLaVA-main/llava/train/train.py", line 32, in <module>
from llava.train.llava_trainer import LLaVATrainer
File "/home/mubei/桌面/llava/LLaVA-main/llava/train/llava_trainer.py", line 7, in <module>
from transformers import Trainer
File "<frozen importlib._bootstrap>", line 1075, in _handle_fromlist
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1354, in __getattr__
module = self._get_module(self._class_to_module[name])
File "/home/mubei/software/anaconda3/envs/llava/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1366, in _get_module
raise RuntimeError(
RuntimeError: Failed to import transformers.trainer because of the following error (look up to see its traceback):
All ufuncs must have type `numpy.ufunc`. Received (<ufunc 'sph_legendre_p'>, <ufunc 'sph_legendre_p'>, <ufunc 'sph_legendre_p'>)以上错误是由于scipy版本和numpy不匹配导致的。运行以下命令,安装能相互匹配的scipy版本:
pip install scipy==1.9.0四、总结
本文主要详细介绍了LLaVA模型的架构,并做了不同版本的对比。同时针对LLaVA-v1.6-Mistral-7B,做了模型的部署、推理以及Lora微调工作。最后,总结了此过程中可能遇到的常见错误,分析并给出了解决办法。

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)