
SpringAI+DeepSeek大模型应用开发——7 RAG:知识库 ChatPDF
利用RAG实现了一个仿ChatPDF的功能,用户把个人的PDF文件作为知识库上传,让AI基于PDF内容来回答问题。文章讲解了RAG原理(向量模型、向量库等),PDF的上传下载和向量化、配置ChatClient、实现对话接口、测试。最后还做了点小拓展,即持久化向量库VectorStore。
7 RAG(知识库 ChatPDF)
-
由于训练大模型非常耗时,再加上训练语料本身比较滞后,所以大模型存在知识限制问题:
- 知识数据比较落后,往往是几个月之前的;
- 不包含太过专业领域或者企业私有的数据;
-
为了解决这些问题,就需要用到RAG了。
7.1 RAG原理
- 要解决大模型的知识限制问题,其实并不复杂;
- 解决的思路就是给大模型外挂一个知识库,可以是专业领域知识,也可以是企业私有的数据;
- 不过,知识库不能简单的直接拼接在提示词中;
- 因为通常知识库数据量都是非常大的,而大模型的上下文是有大小限制的,早期的GPT上下文不能超过2000token,现在也不到200k token,因此知识库不能直接写在提示词中;
- 怎么办?
- 思路很简单,庞大的知识库中与用户问题相关的其实并不多;
- 所以,只要想办法从庞大的知识库中找到与用户问题相关的一小部分,组装成提示词,发送给大模型就可以了;
- 那么问题来了,该如何从知识库中找到与用户问题相关的内容呢?
- 全文检索?但是在这里是不合适的,因为全文检索是文字匹配,而这里要求的是内容上的相似度;
- 而要从内容相似度来判断,这就不得不提到向量模型的知识了。
7.1.1 向量模型
-
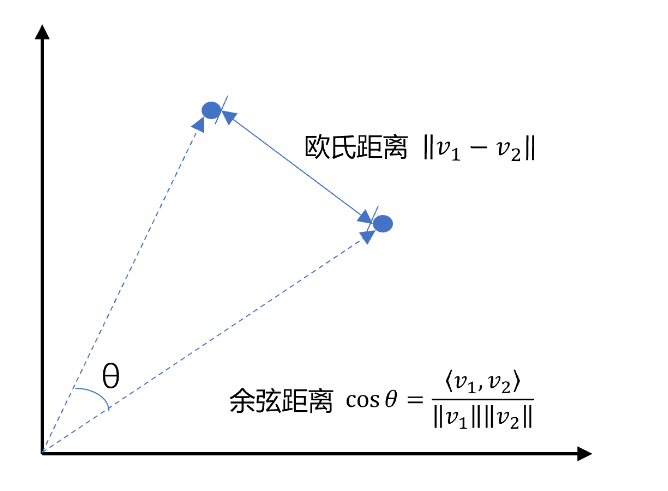
向量是空间中有方向和长度的量,空间可以是二维,也可以是多维;
-
向量既然是在空间中,那么两个向量之间就一定能计算距离;
-
以二维向量为例,向量之间的距离有两种计算方法:
-
通常,两个向量之间欧式距离越近,就认为两个向量的相似度越高(余弦距离相反,越大相似度越高);
-
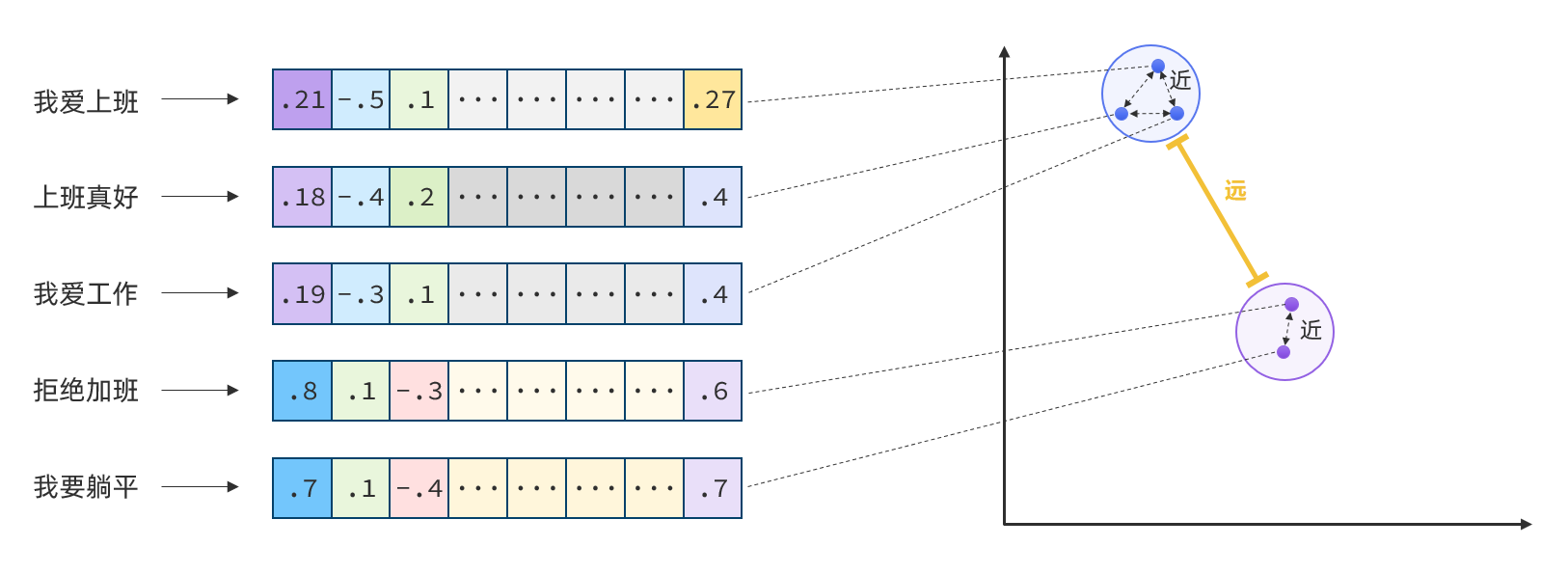
所以,如果能把文本转为向量,就可以通过向量距离来判断文本的相似度了;
-
现在有不少的专门的向量模型,就可以实现将文本向量化。一个好的向量模型,就是要尽可能让文本含义相似的向量,在空间中距离更近:
-
阿里云百炼平台就提供了这样的模型,用于将文本向量化:
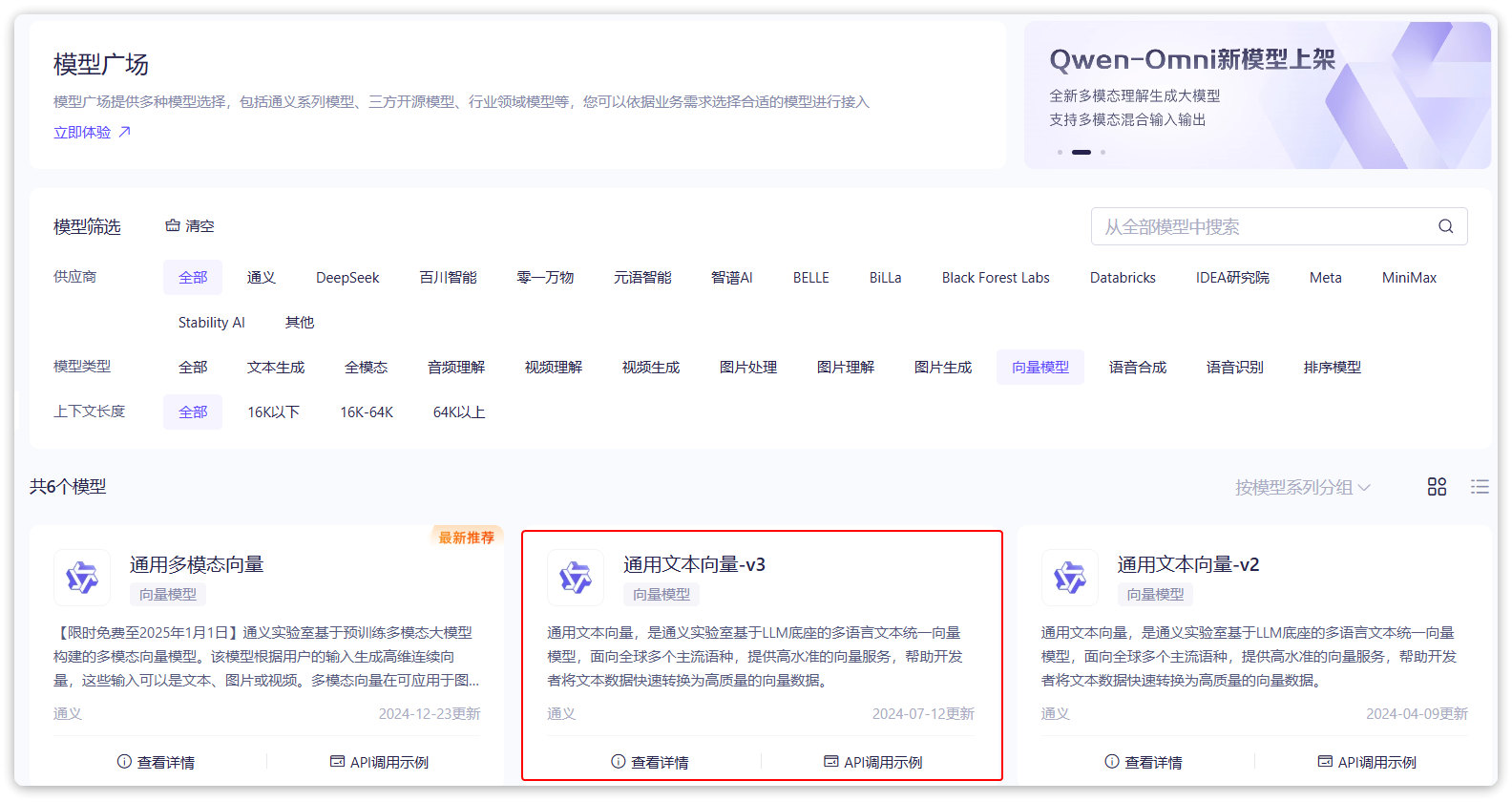
- 这里选择
通用文本向量-v3,这个模型兼容OpenAI,所以我们依然采用OpenAI的配置;
- 这里选择
-
修改
application.yaml,添加向量模型配置:spring: application: name: chart-robot ai: ollama: # Ollama服务地址 base-url: http://localhost:11434 chat: # 模型名称,可更改 model: deepseek-r1:14b options: # 模型温度,值越大,输出结果越随机 temperature: 0.8 openai: base-url: https://dashscope.aliyuncs.com/compatible-mode api-key: ${OPENAI_API_KEY} chat: options: # 可选择的模型列表 https://help.aliyun.com/zh/model-studio/getting-started/models model: qwen-max-latest embedding: options: model: text-embedding-v3 dimensions: 1024
7.1.2 向量模型测试
-
前面说过,文本向量化以后,可以通过向量之间的距离来判断文本相似度;
-
接下来,就来测试下阿里百炼提供的向量大模型;
-
在项目中写一个工具类,用以计算向量之间的欧氏距离和**余弦距离。**新建一个
com.shisan.ai.util包,在其中新建一个VectorDistanceUtils类:package com.shisan.ai.util; public class VectorDistanceUtils { // 防止实例化 private VectorDistanceUtils() {} // 浮点数计算精度阈值 private static final double EPSILON = 1e-12; /** * 计算欧氏距离 * @param vectorA 向量A(非空且与B等长) * @param vectorB 向量B(非空且与A等长) * @return 欧氏距离 * @throws IllegalArgumentException 参数不合法时抛出 */ public static double euclideanDistance(float[] vectorA, float[] vectorB) { validateVectors(vectorA, vectorB); double sum = 0.0; for (int i = 0; i < vectorA.length; i++) { double diff = vectorA[i] - vectorB[i]; sum += diff * diff; } return Math.sqrt(sum); } /** * 计算余弦距离 * @param vectorA 向量A(非空且与B等长) * @param vectorB 向量B(非空且与A等长) * @return 余弦距离,范围[0, 2] * @throws IllegalArgumentException 参数不合法或零向量时抛出 */ public static double cosineDistance(float[] vectorA, float[] vectorB) { validateVectors(vectorA, vectorB); double dotProduct = 0.0; double normA = 0.0; double normB = 0.0; for (int i = 0; i < vectorA.length; i++) { dotProduct += vectorA[i] * vectorB[i]; normA += vectorA[i] * vectorA[i]; normB += vectorB[i] * vectorB[i]; } normA = Math.sqrt(normA); normB = Math.sqrt(normB); // 处理零向量情况 if (normA < EPSILON || normB < EPSILON) { throw new IllegalArgumentException("Vectors cannot be zero vectors"); } // 处理浮点误差,确保结果在[-1,1]范围内 double similarity = dotProduct / (normA * normB); similarity = Math.max(Math.min(similarity, 1.0), -1.0); return similarity; } // 参数校验统一方法 private static void validateVectors(float[] a, float[] b) { if (a == null || b == null) { throw new IllegalArgumentException("Vectors cannot be null"); } if (a.length != b.length) { throw new IllegalArgumentException("Vectors must have same dimension"); } if (a.length == 0) { throw new IllegalArgumentException("Vectors cannot be empty"); } } }- 由于SpringBoot的自动装配能力,刚才配置的向量模型可以直接使用;
-
编写测试类:
package com.shisan.ai; import org.junit.jupiter.api.Test; import org.springframework.boot.test.context.SpringBootTest; import com.shisan.ai.util.VectorDistanceUtils; import org.springframework.ai.openai.OpenAiEmbeddingModel; import org.springframework.beans.factory.annotation.Autowired; import java.util.Arrays; import java.util.List; @SpringBootTest class ChatRobotApplicationTests { // 自动注入向量模型 @Autowired private OpenAiEmbeddingModel embeddingModel; @Test public void testEmbedding() { // 1.测试数据 // 1.1.用来查询的文本,国际冲突 String query = "global conflicts"; // 1.2.用来做比较的文本 String[] texts = new String[]{ "哈马斯称加沙下阶段停火谈判仍在进行 以方尚未做出承诺", "土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判", "日本航空基地水井中检测出有机氟化物超标", "国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营", "我国首次在空间站开展舱外辐射生物学暴露实验", }; // 2.向量化 // 2.1.先将查询文本向量化 float[] queryVector = embeddingModel.embed(query); // 2.2.再将比较文本向量化,放到一个数组 List<float[]> textVectors = embeddingModel.embed(Arrays.asList(texts)); // 3.比较欧氏距离 // 3.1.把查询文本自己与自己比较,肯定是相似度最高的 System.out.println(VectorDistanceUtils.euclideanDistance(queryVector, queryVector)); // 3.2.把查询文本与其它文本比较 for (float[] textVector : textVectors) { System.out.println(VectorDistanceUtils.euclideanDistance(queryVector, textVector)); } System.out.println("------------------"); // 4.比较余弦距离 // 4.1.把查询文本自己与自己比较,肯定是相似度最高的 System.out.println(VectorDistanceUtils.cosineDistance(queryVector, queryVector)); // 4.2.把查询文本与其它文本比较 for (float[] textVector : textVectors) { System.out.println(VectorDistanceUtils.cosineDistance(queryVector, textVector)); } } } -
注意: 运行单元测试通用需要配置
OPENAI_API_KEY的环境变量;-
右键点击单元测试左侧运行按钮:
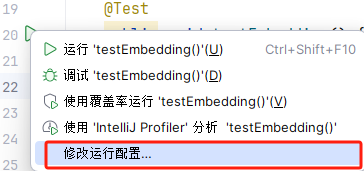
-
配置环境变量:
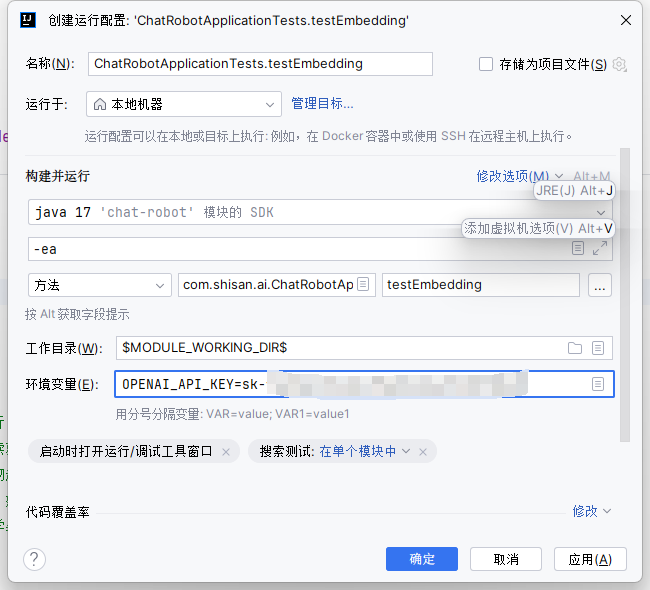
-
-
运行结果:
0.0 1.0722205301828829 1.0844350869313875 1.1185223356097924 1.1693257901084286 1.1499045763089124 ------------------ 0.9999999999999998 0.4251716163869882 0.41200032867283726 0.37445397231274447 0.3163386320532005 0.3388597327534832 -
可以看到,向量相似度确实符合我们的预期。有了比较文本相似度的办法,知识库的问题就可以解决了;
-
前面说了,知识库数据量很大,无法全部写入提示词,而且庞大的知识库中与用户问题相关的其实并不多;
- 所以,我们需要想办法从庞大的知识库中找到与用户问题相关的一小部分,组装成提示词,发送给大模型就可以了;
-
现在,利用向量大模型就可以帮助我们比较文本相似度。但是新的问题来了:向量模型是生成向量的,如此庞大的知识库,谁来从中比较和检索数据呢?
- 这就需要用到向量数据库了。
7.1.3 向量数据库
-
向量数据库的主要作用有两个:
- 存储向量数据;
- 基于相似度检索数据;
-
SpringAI支持很多向量数据库,并且都进行了封装,可以用统一的API去访问:
- Azure Vector Search - The Azure vector store.
- Apache Cassandra - The Apache Cassandra vector store.
- Chroma Vector Store - The Chroma vector store.
- Elasticsearch Vector Store - The Elasticsearch vector store.
- GemFire Vector Store - The GemFire vector store.
- MariaDB Vector Store - The MariaDB vector store.
- Milvus Vector Store - The Milvus vector store.
- MongoDB Atlas Vector Store - The MongoDB Atlas vector store.
- Neo4j Vector Store - The Neo4j vector store.
- OpenSearch Vector Store - The OpenSearch vector store.
- Oracle Vector Store - The Oracle Database vector store.
- PgVector Store - The PostgreSQL/PGVector vector store.
- Pinecone Vector Store - PineCone vector store.
- Qdrant Vector Store - Qdrant vector store.
- Redis Vector Store - The Redis vector store.
- SAP Hana Vector Store - The SAP HANA vector store.
- Typesense Vector Store - The Typesense vector store.
- Weaviate Vector Store - The Weaviate vector store.
- SimpleVectorStore - A simple implementation of persistent vector storage, good for educational purposes.
-
这些库都实现了统一的接口:
VectorStore,因此操作方式一模一样,只要学会任意一个,其它就都不是问题; -
注意:除了最后一个库,其它所有向量数据库都是需要安装部署的,而且每个企业用的向量库都不一样。
7.1.3.1 SimpleVectorStore
-
最后一个
SimpleVectorStore向量库是基于内存实现,是一个专门用来测试、教学用的库,非常适合此处案例的使用; -
修改
CommonConfiguration,添加一个VectorStore的Bean:@Bean public VectorStore vectorStore(OpenAiEmbeddingModel embeddingModel) { return SimpleVectorStore.builder(embeddingModel).build(); }
7.1.3.2 VectorStore接口
-
接下来就可以使用
VectorStore接口中的各种功能了,可以参考SpringAI官方文档:Vector Databases :: Spring AI Reference; -
这是
VectorStore接口中声明的方法:public interface VectorStore extends DocumentWriter { default String getName() { return this.getClass().getSimpleName(); } // 保存文档到向量库 void add(List<Document> documents); // 根据文档id删除文档 void delete(List<String> idList); void delete(Filter.Expression filterExpression); default void delete(String filterExpression) { ... }; // 根据条件检索文档 List<Document> similaritySearch(String query); // 根据条件检索文档 List<Document> similaritySearch(SearchRequest request); default <T> Optional<T> getNativeClient() { return Optional.empty(); } } -
注意,
VectorStore操作向量化的基本单位是Document,在使用时需要将自己的知识库分割转换为一个个的Document,然后写入VectorStore; -
那么问题来了,该如何把各种不同的知识库文件转为Document呢?
7.1.4 文件读取和转换
-
由于知识库太大,所以要将知识库拆分成文档片段,然后再做向量化。而且SpringAI中向量库接收的是
Document类型的文档,也就是说,我们处理文档还要转成Document格式; -
不过,文档读取、拆分、转换的动作并不需要我们亲自完成。在SpringAI中提供了各种文档读取的工具,可以参考官网:ETL Pipeline :: Spring AI Reference;
-
比如PDF文档读取和拆分,SpringAI提供了两种默认的拆分原则:
PagePdfDocumentReader:按页拆分,推荐使用;ParagraphPdfDocumentReader:按pdf的目录拆分,不推荐,因为很多PDF不规范,没有章节标签;
-
此处选择使用
PagePdfDocumentReader。首先,在pom.xml中引入依赖:<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-pdf-document-reader</artifactId> </dependency>- 然后就可以利用工具把PDF文件读取并处理成Document了;
-
编写一个单元测试(别忘了配置API_KEY):
// 自动注入向量库 @Autowired private VectorStore vectorStore; @Test public void testVectorStore(){ Resource resource = new FileSystemResource("中二知识笔记.pdf"); // 1.创建PDF的读取器 PagePdfDocumentReader reader = new PagePdfDocumentReader( resource, // 文件源 PdfDocumentReaderConfig.builder() .withPageExtractedTextFormatter(ExtractedTextFormatter.defaults()) .withPagesPerDocument(1) // 每1页PDF作为一个Document .build() ); // 2.读取PDF文档,拆分为Document List<Document> documents = reader.read(); // 3.写入向量库 vectorStore.add(documents); // 4.搜索 SearchRequest request = SearchRequest.builder() .query("论语中教育的目的是什么") .topK(1) .similarityThreshold(0.6) .filterExpression("file_name == '中二知识笔记.pdf'") .build(); List<Document> docs = vectorStore.similaritySearch(request); if (docs == null) { System.out.println("没有搜索到任何内容"); return; } for (Document doc : docs) { System.out.println(doc.getId()); System.out.println(doc.getScore()); System.out.println(doc.getText()); } } -
注意:启动测试之前,要将
中二知识笔记.pdf文件放到工程目录结构下;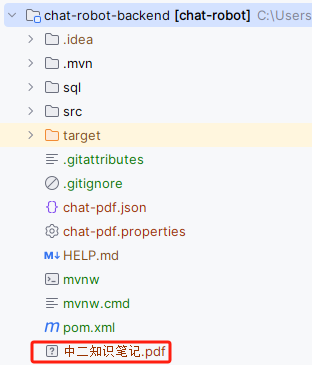
7.1.5 RAG原理总结
-
目前已经有了以下这些工具:
- PDFReader:读取文档并拆分为片段;
- 向量大模型:将文本片段向量化;
- 向量数据库:存储向量,检索向量;
-
接下来梳理一下要解决的问题和解决思路:
-
要解决大模型的知识限制问题,需要外挂知识库;
-
受到大模型上下文限制,知识库不能简单的直接拼接在提示词中;
-
此时需要从庞大的外挂知识库中找到与用户问题相关的一小部分,再组装成提示词;
-
这些可以利用文档读取器、向量大模型、向量数据库来解决;
-
RAG要做的事情就是将知识库分割,然后利用向量模型做向量化,存入向量数据库,然后查询的时候去检索;
-
第一阶段(存储知识库):
- 将知识库内容切片,分为一个个片段;
- 将每个片段利用向量模型向量化;
- 将所有向量化后的片段写入向量数据库;
-
第二阶段(检索知识库):
- 每当用户询问AI时,将用户问题向量化;
- 拿着问题向量去向量数据库检索最相关的片段;
-
第三阶段(对话大模型):
- 将检索到的片段、用户的问题一起拼接为提示词;
- 发送提示词给大模型,得到响应。
-
7.1.6 目标
-
接下来就来实现一个非常火爆的个人知识库AI应用——ChatPDF,原网站如下:
-
这个网站其实就是把个人的PDF文件作为知识库,让AI基于PDF内容来回答问题,对于大学生、研究人员、专业人士来说,非常方便。
7.2 PDF上传下载、向量化
-
既然是ChatPDF,也就是说所有知识库都是PDF形式的,由用户提交给服务器。所以,需要先实现一个上传PDF的接口,在接口中实现下列功能:
- 校验文件格式是否为PDF;
- 保存文件信息;
- 保存文件(可以是oss或本地保存);
- 保存会话ID和文件路径的映射关系(方便查询会话历史的时候再次读取文件);
- 文档拆分和向量化(文档太大,需要拆分为一个个片段,分别向量化);
-
另外,将来用户查询会话历史,还需要返回pdf文件给前端用于预览,所以需要实现一个下载PDF接口,包含下面功能:
- 读取文件;
- 返回文件给前端。
7.2.1 PDF文件管理
-
由于将来要实现PDF下载功能,就需要记住每一个chatId对应的PDF文件名称;
-
所以,定义一个类,记录chatId与pdf文件的映射关系,同时实现基本的文件保存功能。在
com.itheima.shisan.repository中定义FileRepository接口:package com.shisan.ai.repository; import org.springframework.core.io.Resource; public interface FileRepository { /** * 保存文件,还要记录chatId与文件的映射关系 * @param chatId 会话id * @param resource 文件 * @return 上传成功,返回true; 否则返回false */ boolean save(String chatId, Resource resource); /** * 根据chatId获取文件 * @param chatId 会话id * @return 找到的文件 */ Resource getFile(String chatId); } -
再写一个实现类:
package com.shisan.ai.repository; import jakarta.annotation.PostConstruct; import jakarta.annotation.PreDestroy; import lombok.RequiredArgsConstructor; import lombok.extern.slf4j.Slf4j; import org.springframework.ai.vectorstore.SimpleVectorStore; import org.springframework.ai.vectorstore.VectorStore; import org.springframework.core.io.FileSystemResource; import org.springframework.core.io.Resource; import org.springframework.stereotype.Component; import java.io.*; import java.nio.charset.StandardCharsets; import java.nio.file.Files; import java.time.LocalDateTime; import java.util.Objects; import java.util.Properties; @Slf4j @Component @RequiredArgsConstructor public class LocalPdfFileRepository implements FileRepository { private final VectorStore vectorStore; // 会话id 与 文件名的对应关系,方便查询会话历史时重新加载文件 private final Properties chatFiles = new Properties(); @Override public boolean save(String chatId, Resource resource) { // 2.保存到本地磁盘 String filename = resource.getFilename(); File target = new File(Objects.requireNonNull(filename)); if (!target.exists()) { try { Files.copy(resource.getInputStream(), target.toPath()); } catch (IOException e) { log.error("Failed to save PDF resource.", e); return false; } } // 3.保存映射关系 chatFiles.put(chatId, filename); return true; } @Override public Resource getFile(String chatId) { return new FileSystemResource(chatFiles.getProperty(chatId)); } @PostConstruct private void init() { FileSystemResource pdfResource = new FileSystemResource("chat-pdf.properties"); if (pdfResource.exists()) { try { chatFiles.load(new BufferedReader(new InputStreamReader(pdfResource.getInputStream(), StandardCharsets.UTF_8))); } catch (IOException e) { throw new RuntimeException(e); } } FileSystemResource vectorResource = new FileSystemResource("chat-pdf.json"); if (vectorResource.exists()) { SimpleVectorStore simpleVectorStore = (SimpleVectorStore) vectorStore; simpleVectorStore.load(vectorResource); } } @PreDestroy private void persistent() { try { chatFiles.store(new FileWriter("chat-pdf.properties"), LocalDateTime.now().toString()); SimpleVectorStore simpleVectorStore = (SimpleVectorStore) vectorStore; simpleVectorStore.save(new File("chat-pdf.json")); } catch (IOException e) { throw new RuntimeException(e); } } } -
注意:
- 由于此处选择了基于内存的SimpleVectorStore,重启就会丢失向量数据。所以这里依然是将pdf文件与chatId的对应关系、VectorStore都持久化到了磁盘;
- 实际开发中,如果选择了RedisVectorStore,或者CassandraVectorStore,则无需自己持久化。但是chatId和PDF文件之间的对应关系,还是需要自己维护的。
7.2.2 上传文件相应结果
-
由于前端文件上传给后端后,后端需要返回响应结果,在
com.itheima.ai.entity.vo中定义一个Result类:package com.shisan.ai.entity.vo; import lombok.Data; import lombok.NoArgsConstructor; @Data @NoArgsConstructor public class Result { private Integer ok; private String msg; private Result(Integer ok, String msg) { this.ok = ok; this.msg = msg; } public static Result ok() { return new Result(1, "ok"); } public static Result fail(String msg) { return new Result(0, msg); } }
7.2.3 文件上传、下载
-
在
com.shisan.ai.controller中创建一个PdfController:package com.shisan.ai.controller; import com.shisan.ai.entity.vo.Result; import com.shisan.ai.repository.FileRepository; import lombok.RequiredArgsConstructor; import lombok.extern.slf4j.Slf4j; import org.springframework.ai.document.Document; import org.springframework.ai.reader.ExtractedTextFormatter; import org.springframework.ai.reader.pdf.PagePdfDocumentReader; import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig; import org.springframework.ai.vectorstore.VectorStore; import org.springframework.core.io.Resource; import org.springframework.http.MediaType; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.*; import org.springframework.web.multipart.MultipartFile; import java.io.IOException; import java.net.URLEncoder; import java.nio.charset.StandardCharsets; import java.util.List; import java.util.Objects; @Slf4j @RequiredArgsConstructor @RestController @RequestMapping("/ai/pdf") public class PdfController { private final FileRepository fileRepository; private final VectorStore vectorStore; /** * 文件上传 */ @RequestMapping("/upload/{chatId}") public Result uploadPdf(@PathVariable String chatId, @RequestParam("file") MultipartFile file) { try { // 1. 校验文件是否为PDF格式 if (!Objects.equals(file.getContentType(), "application/pdf")) { return Result.fail("只能上传PDF文件!"); } // 2.保存文件 boolean success = fileRepository.save(chatId, file.getResource()); if(! success) { return Result.fail("保存文件失败!"); } // 3.写入向量库 this.writeToVectorStore(file.getResource()); return Result.ok(); } catch (Exception e) { log.error("Failed to upload PDF.", e); return Result.fail("上传文件失败!"); } } /** * 文件下载 */ @GetMapping("/file/{chatId}") public ResponseEntity<Resource> download(@PathVariable("chatId") String chatId) throws IOException { // 1.读取文件 Resource resource = fileRepository.getFile(chatId); if (!resource.exists()) { return ResponseEntity.notFound().build(); } // 2.文件名编码,写入响应头 String filename = URLEncoder.encode(Objects.requireNonNull(resource.getFilename()), StandardCharsets.UTF_8); // 3.返回文件 return ResponseEntity.ok() .contentType(MediaType.APPLICATION_OCTET_STREAM) .header("Content-Disposition", "attachment; filename=\"" + filename + "\"") .body(resource); } private void writeToVectorStore(Resource resource) { // 1.创建PDF的读取器 PagePdfDocumentReader reader = new PagePdfDocumentReader( resource, // 文件源 PdfDocumentReaderConfig.builder() .withPageExtractedTextFormatter(ExtractedTextFormatter.defaults()) .withPagesPerDocument(1) // 每1页PDF作为一个Document .build() ); // 2.读取PDF文档,拆分为Document List<Document> documents = reader.read(); // 3.写入向量库 vectorStore.add(documents); } }
7.2.4 上传大小限制
-
SpringMVC有默认的文件大小限制,只有10M,很多知识库文件都会超过这个值,所以我们需要修改配置,增加文件上传允许的上限;
-
修改
application.yaml文件,添加配置:spring: servlet: multipart: # 单个文件的最大大小为100MB max-file-size: 104857600 # 整个请求的最大大小为100MB max-request-size: 104857600
7.3 配置ChatClient
-
理论上来说,每次与AI对话的完整流程是这样的:
- 将用户的问题利用向量大模型做向量化 OpenAiEmbeddingModel;
- 去向量数据库检索相关的文档 VectorStore;
- 拼接提示词,发送给大模型;
- 解析响应结果;
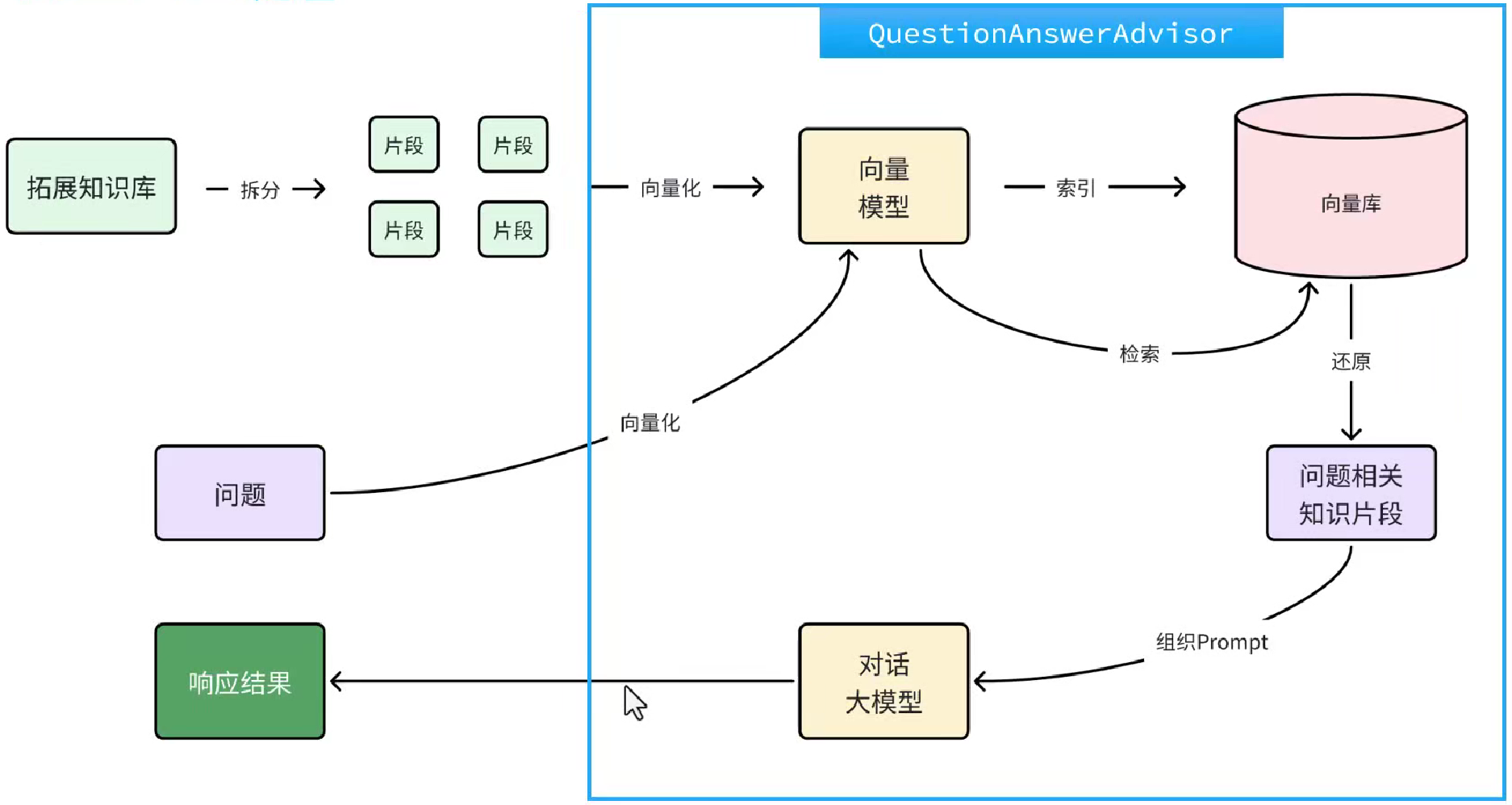
-
不过,SpringAI同样基于AOP技术帮我们完成了全部流程,用的是一个名为
QuestionAnswerAdvisor的Advisor。我们只需要把VectorStore配置到Advisor即可。在CommonConfiguration类中给ChatPDF也单独定义一个ChatClient://ChatPDF @Bean public ChatClient pdfChatClient( OpenAiChatModel model, ChatMemory chatMemory, VectorStore vectorStore) { return ChatClient.builder(model) .defaultSystem("请根据提供的上下文回答问题,不要自己猜测。") .defaultAdvisors( new MessageChatMemoryAdvisor(chatMemory), // CHAT MEMORY new SimpleLoggerAdvisor(), new QuestionAnswerAdvisor( vectorStore, // 向量库 SearchRequest.builder() // 向量检索的请求参数 .similarityThreshold(0.5d) // 相似度阈值 .topK(2) // 返回的文档片段数量 .build() ) ) .build(); } -
也可以自己自定义RAG查询的流程,不使用Advisor,具体可参考官网:Retrieval Augmented Generation :: Spring AI Reference。
7.4 对话接口
-
最后,对接前端与大模型对话。修改
PdfController,添加一个接口:private final ChatClient pdfChatClient; private final ChatHistoryRepository chatHistoryRepository; @RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8") public Flux<String> chat(String prompt, String chatId) { chatHistoryRepository.save("pdf", chatId); Resource file = fileRepository.getFile(chatId); return pdfChatClient .prompt(prompt) .advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)) .advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "file_name == '"+file.getFilename()+"'")) .stream() .content(); }
7.5 测试
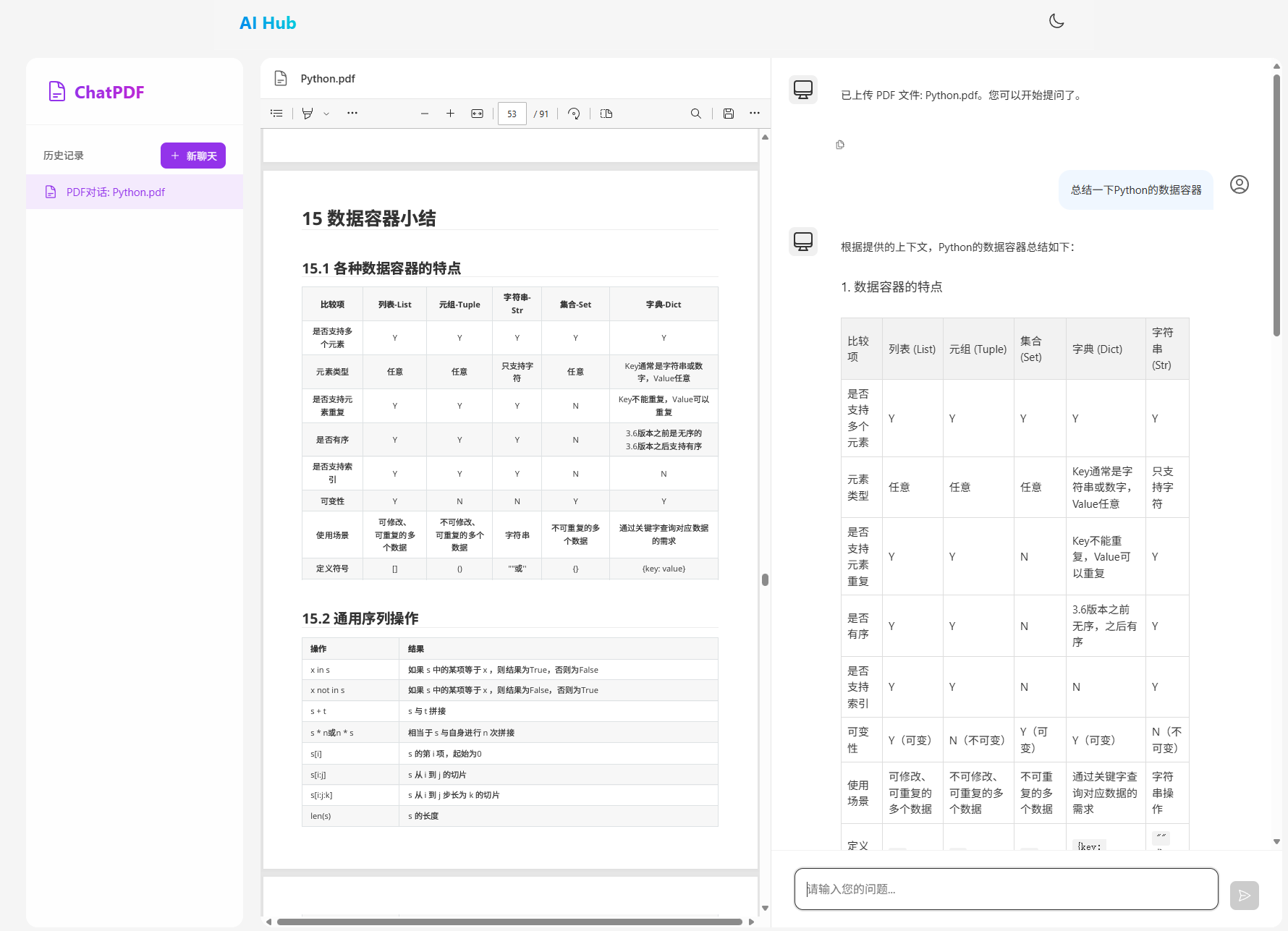
7.6 持久化VectorStore
-
SpringAI提供了很多持久化的VectorStore,下面以其中两个为例来介绍:
- RedisVectorStore : 目前测试metafiled过滤有异常;
- CassandraVectorStore。
7.6.1 RedisVectorStore
-
需要安装一个Redis Stack,这是Redis官方提供的拓展版本,其中有向量库的功能;
-
可以使用Docker安装:
docker run -d --name redis-stack -p 6379:6379 -p 8001:8001 redis/redis-stack:latest -
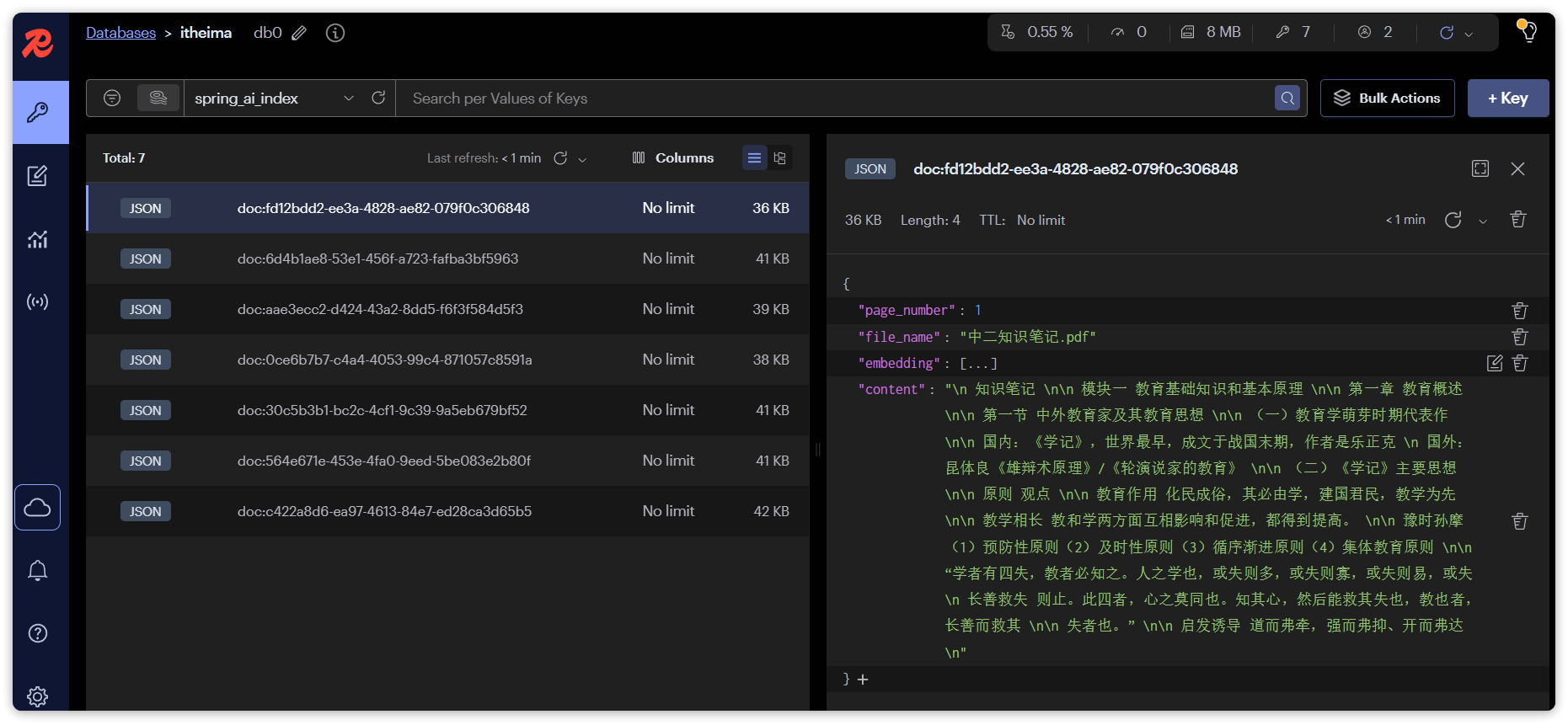
安装完成后,可以通过命令行访问:
docker exec -it redis-stack redis-cli -
也可以通过浏览器访问控制台:http://localhost:8001;
- 注意,这里的IP要换成自己的;
-
在项目中引入RedisVectorStore的依赖:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-redis-store-spring-boot-starter</artifactId> </dependency> -
在
application.yml配置Redis:spring: ai: vectorstore: redis: index: spring_ai_index # 向量库索引名 initialize-schema: true # 是否初始化向量库索引结构 prefix: "doc:" # 向量库key前缀 data: redis: host: 192.168.150.101 # redis地址 -
接下来,无需声明bean,直接就可以直接使用
VectorStore了。
7.6.2 CassandraVectorStore
-
首先,需要安装一个Cassandra访问,使用Docker安装:
docker run -d --name cas -p 9042:9042 cassandra -
在项目中添加cassandra依赖:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-cassandra-store-spring-boot-starter</artifactId> </dependency> -
配置Cassandra地址:
spring: cassandra: contact-points: 192.168.150.101:9042 local-datacenter: datacenter1 -
配置VectorStore:
public CassandraVectorStore vectorStore(OpenAiEmbeddingModel embeddingModel, CqlSession cqlSession) { return CassandraVectorStore.builder(embeddingModel) .session(cqlSession) .addMetadataColumn( new CassandraVectorStore.SchemaColumn("file_name", DataTypes.TEXT, CassandraVectorStore.SchemaColumnTags.INDEXED) ) .build(); }

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 53
53 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)