
python评估不平衡数据集_第56集 python机器学习:评估指标与评分
就目前为止,我们使用预测的精准度来评估分类性能,使用R²来评估回归性能,但是,总结监督模型给定数据集上的表现有多种方法,这两个指标只是其中两种。在实践中,这些评估指标可能不适用于某些应用,但是在进行模型选择和调参时,选择正确的指标是很重要的。接下来我们先讨论二分类指标。首先我们来看一下常见的几个定义:二分类指标:二分类可能是实践中最常见的机器学习应用,对于二分类问题,我们通常会说正类(positi
就目前为止,我们使用预测的精准度来评估分类性能,使用R²来评估回归性能,但是,总结监督模型给定数据集上的表现有多种方法,这两个指标只是其中两种。在实践中,这些评估指标可能不适用于某些应用,但是在进行模型选择和调参时,选择正确的指标是很重要的。接下来我们先讨论二分类指标。
首先我们来看一下常见的几个定义:
二分类指标:二分类可能是实践中最常见的机器学习应用,对于二分类问题,我们通常会说正类(positive class)和反类(negative class),而正类是我们要寻找的类。
错误类型:我们把本来应该是正类的结果预测为反类结果的样例叫做假正例;本来应该是反例的结果预测为正例成为假反例;假正例也叫第一类错误,假反例也成为了第二类错误(type II error)
不平衡数据集:在机器学习中,我们将一个类别比另一个类别出现的次数多出很多的现象,叫做不平衡数据集(imbalanced dataset)或者具有不平衡类别的数据集(dataset with imbalanced)。在实际应用中,不平衡数据集才是常态,就比如我们浏览某个网页,但是我们关注的知识其中的某个点,而网页中的大部分内容我们是不关心的。
下面我们以digits数据集中的数字9与其他9个类别加以区分,从而创建一个9:1的不平衡数据集:
from sklearn.datasets import load_digits
digits = load_digits()
y = digits.target == 9
x_train, x_test, y_train, y_test = train_test_split(digits.data, y, random_state=0)
#我们可以使用DumyClassifier来始终预测多数类(这里是非9),以证明精度提供的信息量是很少的
from sklearn.dummy import DummyClassifier
dumy_majority = DummyClassifier(strategy='most_frequent').fit(x_train, y_train)
pred_most_frequent = dumy_majority.predict(x_test)
print("unique predicted labels: {}".format(np.unique(pred_most_frequent)))
print("Test score:{:.2f}".format(dumy_majority.score(x_test, y_test)))
运行后结果为:
unique predicted labels: [False]
Test score:0.90
从运行结果来看,我们的预测精度为0.90,但是却没有学习到任何内容。下面我们将这一结果与另一个真实的分类器作对比:
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(max_depth=2).fit(x_train, y_train)
pred_tree = tree.predict(x_test)
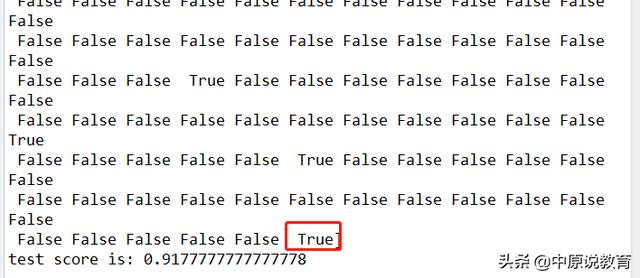
print("Unique predicted of tree label are: {}".format(pred_tree))
print("test score is: {}".format(tree.score(x_test, y_test)))
上述代码运行结果如下:
不平衡数据集的精度预测和学习效果
从精度上来看,这里的精度提高了一些,差不多达到了0.92,但是其学习效果仍然很差,绝大部分仍然为False。
为了便于对比,我们再评估两个分类器,LogisticRegression和默认DummyClassifier,其中后者进行随机预测,但预测类别的比例与训练集中的比例相同:
from sklearn.linear_model import LogisticRegression
dummy = DummyClassifier().fit(x_train, y_train)
pred_dummy = dummy.fit(x_train, y_train)
print("Dummy score is: {:.2f}".format(dummy.score(x_test, y_test)))
logreg = LogisticRegression(C=0.1).fit(x_train, y_train)
pred_logreg = logreg.predict(x_test)
print("Logreg test score is: {:2f}".format(logreg.score(x_test, y_test)))
运行结果为:
Dummy score is: 0.79
Logreg test score is: 0.98
由此可见,产生输出的虚拟分数其实所有分类器中最差的(精度最低),而LogisticRegression则给出了较好的预测精度,不过,即使是最差的分类器的精度都达到了近80%,这就使得很难判断那些结果是真正有帮助的,因为精度并不能对不平衡数据预测性能进行量化。
那么,我们用什么方法来评估这类不平衡数据进行评估呢,下节我们将介绍这一方法——混淆矩阵

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)