
利用ollama和open-webui本地部署通义千问Qwen1.5-7B-Chat模型
利用ollama和open-webui本地部署通义千问Qwen1.5-7B-Chat模型
目录
4.2 将qwen的huggingface safetensors转为llama.cpp的二进制文件
1 安装ollama
curl -fsSL https://ollama.com/install.sh | sh启动、关闭ollama
systemctl start ollama
systemctl stop ollama
systemctl restart ollama
systemctl status ollama
2 安装open-webui
git clone https://github.com/open-webui/open-webui.git
cd open-webui这里open-webui的源码其实用不到,直接用下面的镜像就行。
2.1 镜像下载
官方没有在 docker hub 上发布镜像,而是发布在 ghcr.io,地址在 https://Github.com/open-webui/open-webui/pkgs/container/open-webui
docker pull ghcr.io/open-webui/open-webui:main如果没有科学上网,很可能会拉不动,可以试试 docker 代理网站:https://dockerproxy.com/,但是会多几个步骤
# 如果拉不动的话加个代理
docker pull ghcr.dockerproxy.com/open-webui/open-webui:main
# 重命名镜像(如果是通过代理下载的)
docker tag ghcr.dockerproxy.com/open-webui/open-webui:main ghcr.io/open-webui/open-webui:main
# 删除代理镜像(如果是通过代理下载的)
docker rmi ghcr.dockerproxy.com/open-webui/open-webui:main然后docker images可以看到镜像

docker run -d -p 3006:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui-chw --restart always ghcr.io/open-webui/open-webui:main
2c93ac3c6c911302d4d2926692a7bab64f607317938da71e53ff32798be801da
3 配置ollama的模型转换工具环境
3.1 下载ollama源码
git clone https://github.com/ollama/ollama.git
cd ollama3.2 下载ollama子模块
git submodule init
git submodule update llm/llama.cpp3.3 创建ollama虚拟环境
conda create -n ollama_chw python=3.11
conda activate ollama_chw3.4 安装依赖
pip install -r llm/llama.cpp/requirements.txt3.5 编译量化工具
make -C llm/llama.cpp quantize
如果编译llama.cpp的测试工具main,在llama.cpp目录执行make -j,会在当前目录生成main文件。
测试实验./main -m ./model_name4 转换qwen模型
4.1 下载qwen模型
从hugging face国内镜像网址下载模型更快。
4.2 将qwen的huggingface safetensors转为llama.cpp的二进制文件
cd ollama
python llm/llama.cpp/convert-hf-to-gguf.py /data/chw/ollama_20240419/qwen1.5-7B/ --outtype f16 --outfile /data/chw/ollama_20240419/qwen1.5-7B/converted.bin若重新生成,需先删除之前的converted.bin,否则报错。
4.3 测试转换的模型是否能正常运行
llm/llama.cpp/main -m /data/chw/ollama_20240419/qwen1.5-7B/converted.bin5 量化模型
cd ollama
llm/llama.cpp/quantize /data/chw/ollama_20240419/qwen1.5-7B/converted.bin /data/chw/ollama_20240419/qwen1.5-7B/quantized.bin q4_06 创建Modelfile文件
/data/chw/ollama_20240419/qwen1.5-7B
vim Modelfile然后里面写入如下内容
FROM quantized.bin
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>{{ end }}<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant"""7 创建ollama模型
ollama create chw1.5 -f /data/chw/ollama_20240419/qwen1.5-7B/Modelfile到了这一步之后,其实在open-webui上就可以看到这个模型了,浏览器登录
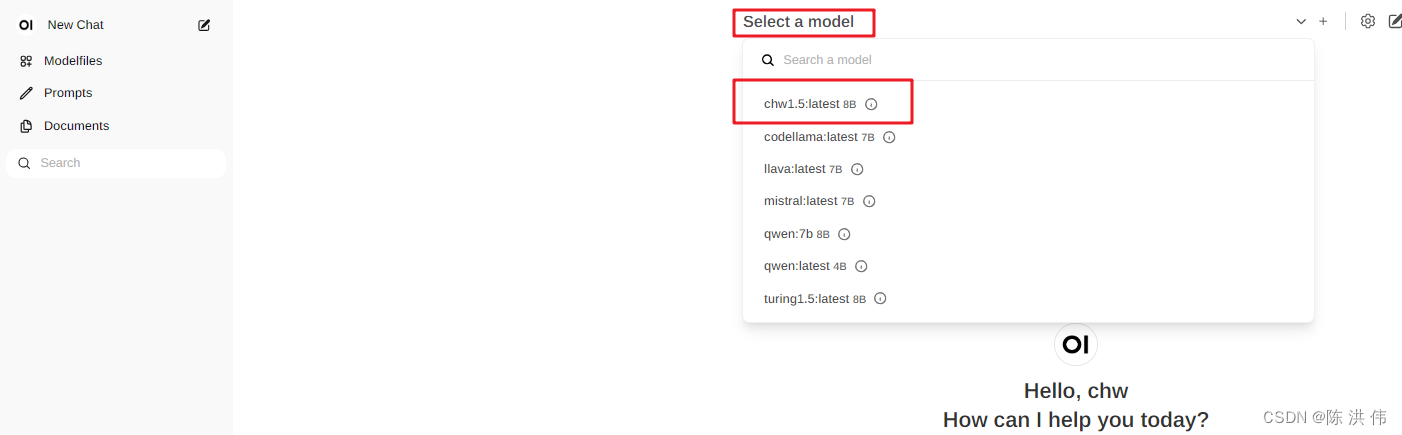
8 运行模型
ollama run chw1.5其实这个ollama run就相当于在命令行运行模型,但是我们这里是用open-webui,所以直接ollama create之后就可以用open-webui。
参考文献:
GitHub - open-webui/open-webui: User-friendly WebUI for LLMs (Formerly Ollama WebUI)
llama.cpp部署通义千问Qwen-14B_通义千问gguf model-CSDN博客
适配Ollama的前端界面Open WebUI | 半码博客
🚀 Getting Started | Open WebUI

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 11
11 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)