
李宏毅机器学习笔记:梯度下降
前言本文是基于台湾李宏毅机器学习的笔记,本文主要记录关于梯度下降的知识点一、梯度下降梯度下降法简介梯度下降的优化目标是使得损失函数L最小,其中θ为参数,假设 θ 有里面有两个参数 θ1, θ2 随机选取初始值,η为学习率梯度下降遇到的问题梯度下降过程中可能会遇到马鞍点,局部最小点,下降速率过慢等等情况,如下图所示,这些情况导致的后果就是梯度约等于或等于0,即梯度消失,在深度学习中,对于梯度消失问题
·
前言
本文是基于台湾李宏毅机器学习的笔记,本文主要记录关于梯度下降的知识点
一、梯度下降
- 梯度下降法简介
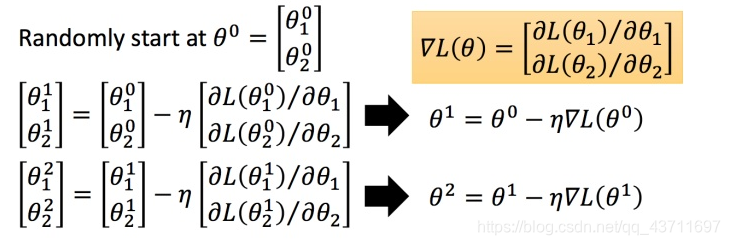
梯度下降的优化目标是使得损失函数L最小,其中θ为参数,假设 θ 有里面有两个参数 θ1, θ2 随机选取初始值 ,η为学习率
- 梯度下降遇到的问题
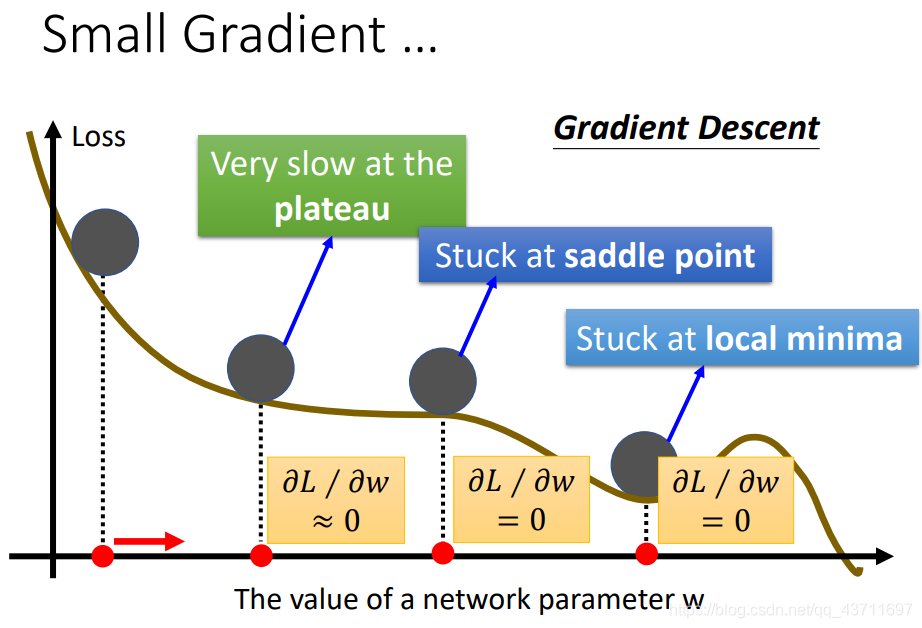
梯度下降过程中可能会遇到马鞍点,局部最小点,下降速率过慢等等情况,如下图所示,这些情况导致的后果就是梯度约等于或等于0,即梯度消失,在深度学习中,对于梯度消失问题尤其看重,梯度消失意味着网络失去了活性相当于网络死亡。
二、梯度下降优化
- 调整优化的Batch大小
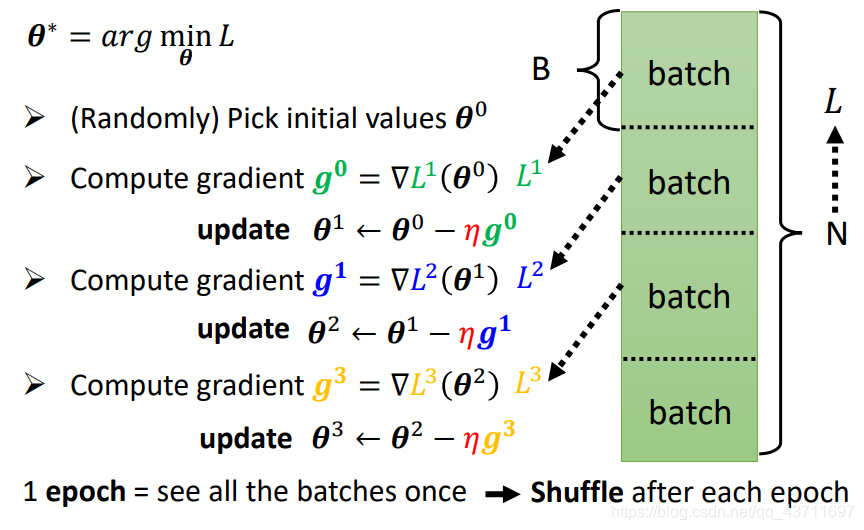
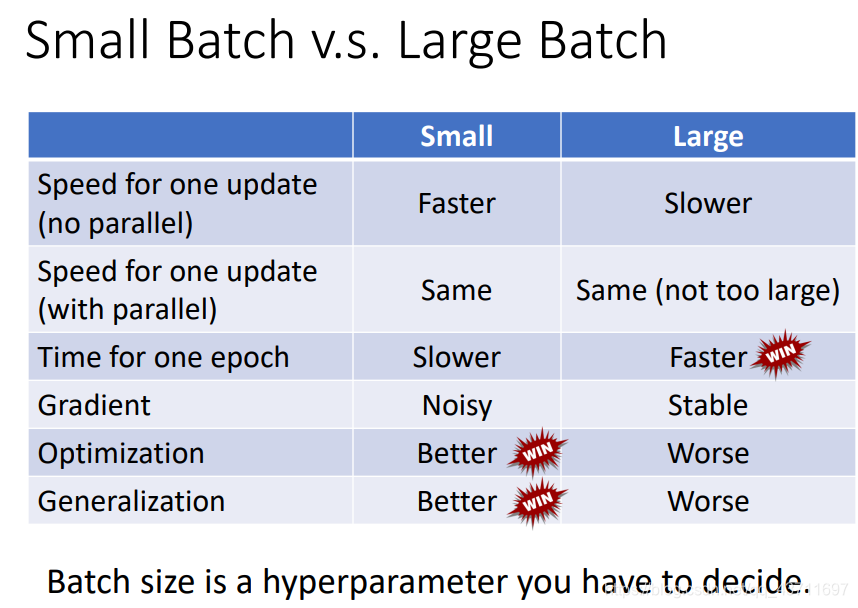
调整训练的优化的batch大小其实主要的区别在于速度和精度上,在优化上如果一次性大批次进行梯度下降优化造成的结果就是速率上很快但是不能保证精确性,因此使用更小的批次进行优化虽然牺牲了速度但是提高了精度
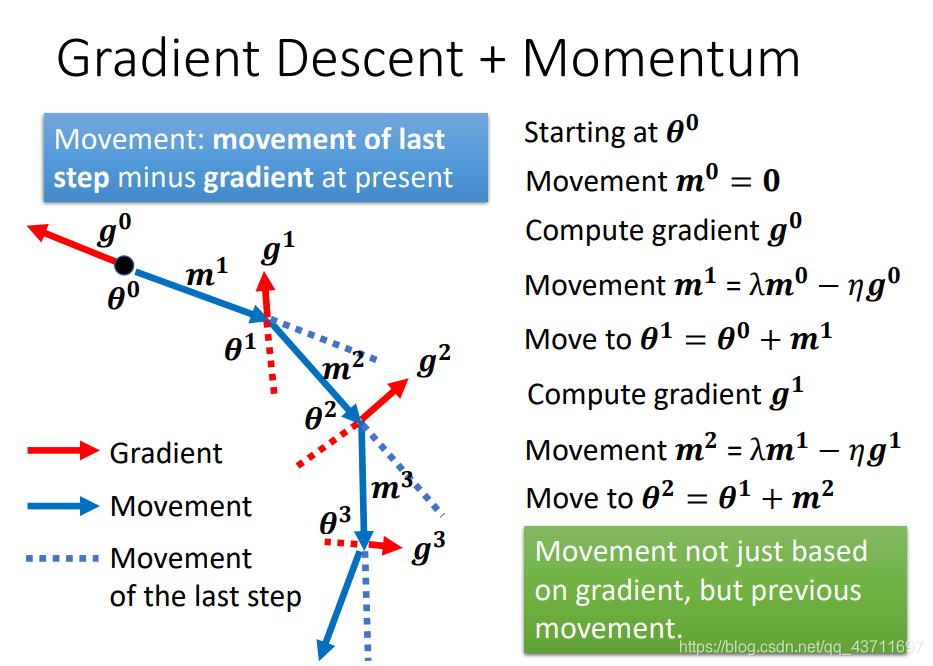
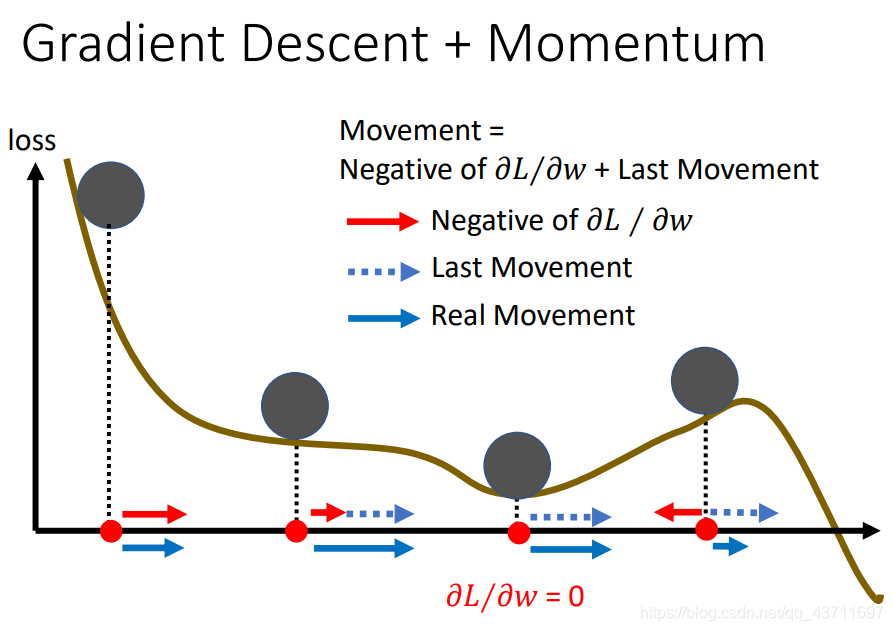
- 动量法
动量法事实上可以看作给原来的梯度下降法加入了惯性,可以看作一个具有惯性的小球,在梯度越陡的地方随着惯性下降速度也增加,即当前的速度会考虑上一步。
- 自适应优化
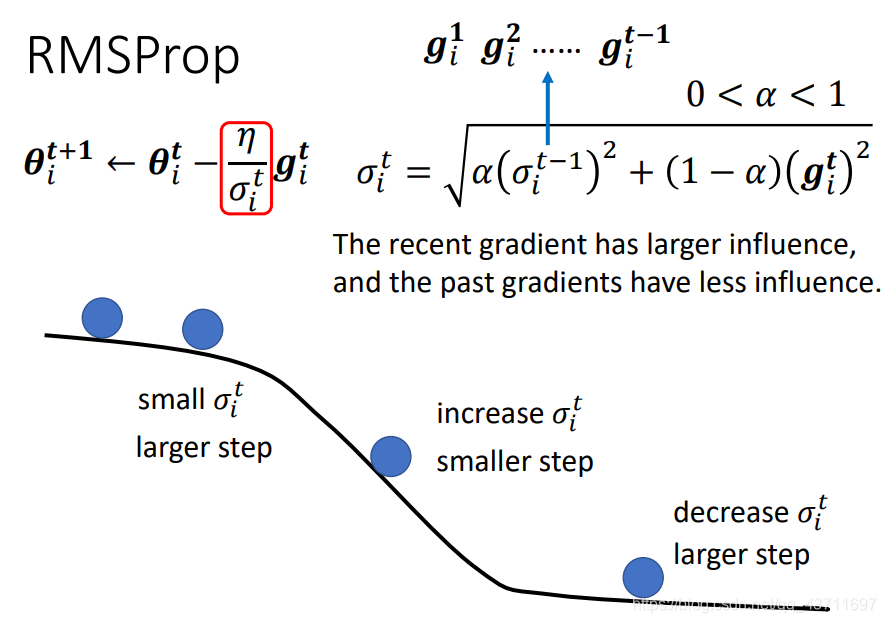
RMSprop是基于随机梯度下降法改进的自适应梯度下降,对于不同的参数需要不同的学习速率,并且对于最近的梯度给予更大的影响对于更早的梯度给予更小的影响

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)