
机器学习过拟合演示实例
机器学习过拟合演示
机器学习过拟合演示实例
小白的机器学习之路
飞鹰翱翔,烈火燃烧,无惧风浪,征服苍穹。
目录
1. 什么是过拟合?
过拟合是机器学习中一个很常见的问题。
在机器学习中,过拟合指的是模型过度地适应了训练数据,以至于捕捉到了数据中的噪声和随机变化,而失去了对新数据的泛化能力。简单来说,就是模型在训练数据上表现得很好,但是在未见过的数据上表现很差。
2.为什么会发生过拟合?
过拟合通常发生在模型过于复杂或者训练数据过少的情况下。当模型的复杂度很高时,它有能力记住训练数据中的每一个细节,包括噪声和异常值,而不仅仅是真正的模式或规律。如果训练数据量太少,模型可能没有足够的信息来学习数据的真实分布,导致过度拟合。
3.如何避免过拟合?
1. 增加数据量: 增加更多的训练数据可以帮助模型更好地学习数据的真实分布,减少过拟合的风险。
2. 简化模型: 减少模型的复杂度,可以通过减少参数的数量、特征选择、正则化等方法来实现。简单的模型通常更不容易过拟合。
3. 交叉验证: 使用交叉验证来评估模型的泛化能力。通过将数据分成训练集和验证集,在训练过程中检查模型在验证集上的性能,可以及时发现过拟合的情况。
4. 正则化: 在损失函数中加入正则化项,如L1正则化(Lasso)或L2正则化(Ridge),可以限制模型的复杂度,防止过拟合。
4.示例
举个例子,假设你正在训练一个分类器来识别手写数字。如果你的模型在训练集上表现很好,但在测试集上表现很差,可能就是发生了过拟合。这时候,你可以尝试收集更多的数据,简化模型的结构,或者尝试正则化方法来改善模型的性能。
1)代码展示
#coding=UTF-8
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import sklearn.metrics as metrics#用来统计指标
import warnings
from sklearn.linear_model import LinearRegression, LassoCV, RidgeCV, ElasticNetCV
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
import sys
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
defaultencoding = 'utf-8'
np.random.seed(100)
#1.加载数据 2.数据处理 3.创建模型 4.训练模型 5.模型评估 6.上线
#
np.set_printoptions(linewidth=1000, suppress=True)
#生成样本数据
N = 10
x = np.linspace(0, 6, N) + np.random.randn(N)
y = 1.8*x**3 + x**2 - 14*x - 7 + np.random.randn(N)
x.shape = -1, 1 #10行一列
y.shape = -1, 1 #10行一列
#创建模型
models = [
Pipeline([
('Poly', PolynomialFeatures(include_bias=False)),
('Linear', LinearRegression(fit_intercept=False))
]),
Pipeline([
('Poly', PolynomialFeatures(include_bias=False)),
#岭回归 +l2
('Linear', RidgeCV(alphas=np.logspace(-3,2,50), fit_intercept=False))
]),
Pipeline([
('Poly', PolynomialFeatures(include_bias=False)),
# Lasso回归 +l2
('Linear', LassoCV(alphas=np.logspace(0,1,10), fit_intercept=False))
]),
Pipeline([
('Poly', PolynomialFeatures(include_bias=False)),
#alphas指正则项中的λ l1_ratio指p 弹性网络
('Linear', ElasticNetCV(alphas=np.logspace(0,1,10), l1_ratio=[.1, .5, .7, .9, .95, 1], fit_intercept=False))
])
]
plt.figure(facecolor='w')
#阶次(1,5,9)
degree = np.arange(1,N,4)
dm = degree.size#3
colors = []
for c in np.linspace(16711680, 255, dm):#有多少条线生成多少种颜色
colors.append('#%06x' % int(c))#把数字变成16进制
titles = ['lineregreession', 'Ridge', 'Lasso', 'ElasticNet']#4个模型的类型名
for t in range(4):#循环4次 4个模型
model = models[t]#取每个算法
plt.subplot(2,2,t+1)#2x2子图,
plt.plot(x, y, 'black', ms=10,label="原始数据")#显示原始数据的线
for i,d in enumerate(degree):#取每个阶 循环每阶次
print("=="*30+ str(d)+""+titles[t])
model.set_params(Poly__degree=d)#当第一次循环时,1阶次
model.fit(x, y.ravel()) #训练模型 求theta
xx_hat=model.predict(x) #预测
lin = model.get_params()['Linear']
print ("theta:",lin.coef_.ravel())#打印下theta向量
#按照训练样本的最小值和最大值再次生100个成样本
x_hat = np.linspace(x.min(), x.max(), num=100)
x_hat.shape = -1,1 #把样本变成100行,1列
y_hat = model.predict(x_hat) #对生成的样本进行预测
# mse=metrics.mean_squared_error(y,xx_hat)#求mse指标,这值越小越好
# print("mse", mse)
#
# print(np.sum((y-xx_hat)**2))#手动算
s = model.score(x, y)#R^2越接近1越好
# print(s)
label = u'%dje, zhengque=%.3f' % (d,s)
#用样本x和预测值y显示图像
plt.plot(x_hat, y_hat, color=colors[i], label=label)
plt.legend(loc = 'upper left')
plt.grid(True)
plt.title(titles[t])
plt.xlabel('X', fontsize=16)
plt.ylabel('Y', fontsize=16)
# plt.tight_layout(1, rect=(0,0,1,0.95))
plt.suptitle(u'过拟合', fontsize=22)
plt.show()
2)运行结果
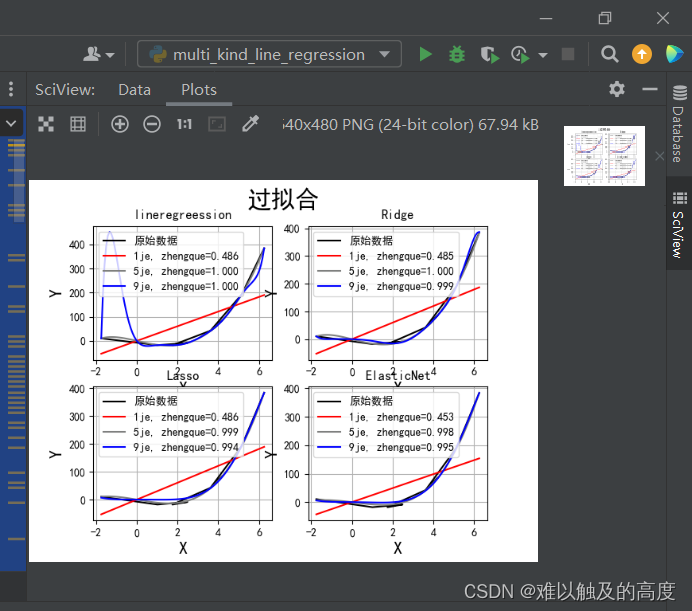
5.结论
过拟合是机器学习中需要注意的一个重要问题,可以通过增加数据量、简化模型、交叉验证和正则化等方法来避免。在训练模型时,始终要注意平衡模型的复杂度和泛化能力,以获得更好的性能。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)