
vllm0.8.5发布Qwen2.5-Omni-7B,报python3.10/site-packages/transformers/models/autKeyError: ‘qwen2_5_omni‘
当前安装的 HuggingFace Transformers4.51.1 库不支持这种模型结构。这通常是因为该模型是新推出的,而你当前使用的 Transformers 版本尚未包含对该模型的支持。因此需要卸载旧Transformers版本,安装Transformers4.52.3版本。注:不能安装Transformers4.52.4,会导致vllm出现问题。多模态:Qwen2.5-Omni-7B。
环境:
GPU:2张A6000
vllm:0.8.5
transformers:4.51.1
多模态:Qwen2.5-Omni-7B
执行命令:
vllm serve "/mnt/data/models/Qwen2.5-Omni-7B" \
--host "*.*.*.*" \
--port 9400 \
--gpu-memory-utilization 0.9 \
--max-model-len 8192 \
--served-model-name "qwen7b" \
--tensor-parallel-size 2
错误内容:
Traceback (most recent call last):
File "/mnt/data/app/miniconda3/envs/factory092/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py", line 1129, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/mnt/data/app/miniconda3/envs/factory092/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py", line 831, in __getitem__
raise KeyError(key)
KeyError: 'qwen2_5_omni'错误原因:
当前安装的 HuggingFace Transformers4.51.1 库不支持这种模型结构。这通常是因为该模型是新推出的,而你当前使用的 Transformers 版本尚未包含对该模型的支持。
因此需要卸载旧Transformers版本,安装Transformers4.52.3版本。
注:不能安装Transformers4.52.4,会导致vllm出现问题。
解步骤:
1.pip uninstall transformers;
2.pip install transformers==4.52.3
3.再执行如下命令:
vllm serve "/mnt/data/models/Qwen2.5-Omni-7B" \
--host "*.*.*.*" \
--port 9400 \
--gpu-memory-utilization 0.9 \
--max-model-len 8192 \
--served-model-name "qwen7b" \
--tensor-parallel-size 2代码验证
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key="sk-xxx",
api_key="EMPTY",
base_url="http://IP:9400/v1",
)
completion = client.chat.completions.create(
model="qwen7b",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"
},
},
{"type": "text", "text": "图中描绘的是什么景象?"},
],
},
],
# 设置输出数据的模态,当前支持两种:["text","audio"]、["text"]
modalities=["text", "audio"],
audio={"voice": "Chelsie", "format": "wav"},
# stream 必须设置为 True,否则会报错
stream=True,
stream_options={
"include_usage": True
}
)
for chunk in completion:
if chunk.choices:
print(chunk.choices[0].delta)
else:
print(chunk.usage)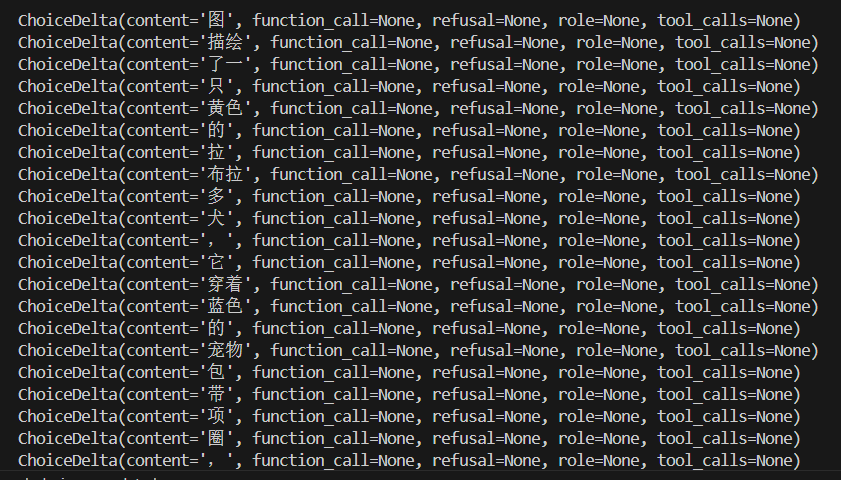

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)