
【20210911】【机器/深度学习】Cart决策树、lightGBM模型训练阶段小结
一、背景问题源于工作中的一项分类任务,正负样本比例严重失衡,想使用 lgb 实现二分类算法。二、读取样本集(.mat格式的数据)import scipy.io as scioimport pandas as pddata_dict = scio.loadmat('样本集.mat')# scio.loadmat()读出来的数据是dict格式data_narray = data_dict['data'
一、背景
问题源于工作中的一项分类任务,正负样本比例严重失衡,想使用 lgb 实现二分类算法。
二、读取样本集(.mat格式的数据)
import scipy.io as scio
import pandas as pd
data_dict = scio.loadmat('样本集.mat') # scio.loadmat()读出来的数据是dict格式
data_narray = data_dict['data'] # dict转为narray格式
data_df = pd.DataFrame(data_narray, columns=column_name) # narray格式转为dataframe格式对样本集进一步处理:正样本分为了多种类型,对应了多种标签,需要进一步处理,将这几种标签映射成一种标签,处理之后的标签只有 1 和 0 两种,分别对应正样本、负样本。
映射标签涉及到了修改 dataframe 的数据,这个过程我踩了坑,具体见:【20210907】【Python】修改Dataframe符合条件的行、列值
三、划分训练集和测试集
划分训练集和测试集通常使用 上sklearn.model_selection 中的 train_test_split,使用方法如下:
from sklearn.model_selection import train_test_split
[data_train, data_test, labels_train, labels_test] = train_test_split(myData, labels, test_size=0.3)
''' myData是特征数据;
labels是标签数据;
test_size是测试集占总数据数量的比例,也就是说划分出来的训练集和测试集的比例是7:3 '''这种划分方式的特点在于测试集中有70%的数据是经过训练的,但并不适用于这个场景,所以修改了划分训练集和测试集的方式:
num_total = data_df.iloc[:, 0].size # 样本总个数
num_train = round(2 / 3 * num_total) # 选训练集和测试集的比例为 2:1
num_test = num_total - num_train
data_train = data_df.iloc[0 : num_train] # 训练集数据
data_test = data_df.iloc[num_train : num_total] # 测试集数据四、解决训练集正负样本不均衡的问题
1. 方式一:对负样本进行随机下采样
import random
data_train_normal = data_train[data_train['标签']==0] # 负样本数据
indexTrain_neg = data_train_normal.index.values.tolist() # 负样本的index
tmp = data_train.groupby('标签')['标签'].count() # 查看正负样本的个数
tmp_dict = dict(tmp) # Series转成dict
num_pos = tmp_dict[1.0] # 正样本个数
num_neg = tmp_dict[0.0] # 负样本个数
ratio = 3 # 设置正负样本比例为1:3
num_neg_underSample = ratio * num_pos
index_neg_underSample = random.sample(indexTrain_neg, num_neg_underSample) # 从负样本中随机抽样
(参考:Python random() 函数)
(参考:Python中产生随机数)
2. 方式二:提高正样本的权重
不同的库函数,有不同的设置方式,例如:
(1)tree.DecisionTreeClassifier 的 class_weight
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion='gini', splitter='best', class_weight='balanced') # 计算机自动计算一个合适的正负样本的权重比例
clf = tree.DecisionTreeClassifier(criterion='gini', splitter='best', class_weight={0:1, 1:3}) # 设置正负样本权重为 3:1(通常是设置为样本个数的倒数)
''' 注意:对 class_weight 指定具体的值时,数据格式为 dict! '''(参考:sklearn的class_weight设置为'balanced'的计算方法)
(2)lgb.train 的 scale_pos_weight
import lightGBM as lgb
params = {
'learning rate': 0.1,
'lambda_l1': 0,
'lambda_l2': 0,
'max_depth': 4,
'objective': 'multiclass',
'num_class': 2,
'scale_pos_weight': 3 # 设置正样本权重
}
gbm = lgb.train(params, dataset_train, valid_sets=dataset_test)下图从左到右依次给出了:设置class_weight='balanced'、class_weight 和正负样本个数成反比、对负样本降采样到正样本数量的三倍的结果。
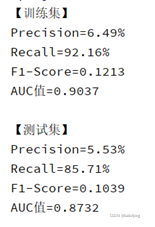
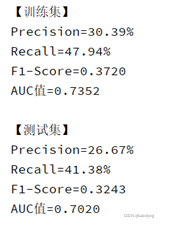

正负样本比例严重失衡,所以将 class_weight设置为'balanced' 之后计算机将正样本的权重设置的过高,导致模型会很注重这些小样本,而误伤了许多负样本,所以精确率很低,而召回率较高。
五、模型训练
1. 方法一:使用 tree 库函数
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion='gini', splitter='best')
clf = clf.fit(data_train, labels_train)
labels_train_pre = clf.predict(data_train) # 训练集预测标签
labels_test_pre = clf.predict(data_test) # 测试集预测标签2. 方法二:使用 lgb
import lightGBM as lgb
dataset_train = lgb.Dataset(data_train, labels_train) # 将样本集转换成 lgb 模型训练需要的 Dataset 格式
dataset_test = lgb.Dataset(data_test, labels_test)
gbm = lgb.train(params, dataset_train, valid_sets=dataset_test)
prob_train_pre = gbm.predict(data_train) # lgb模型训练结果:是该样本属于某个种类的概率
prob_test_pre = gbm.predict(data_test)
labels_train_pre = [list(x).index(max(x)) for x in prob_train_pre] # 将概率转换成标签
labels_test_pre = [list(y).index(max(y)) for y in prob_test_pre]六、模型评价
1. 评价指标
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
from sklearn.metrics import roc_auc_score
precision = precision_score(labels_test, labels_test_pre) # 精确率
recall = recall_score(labels_test, labels_test_pre) # 召回率
f1 = f1_score(labels_test, labels_test_pre) # f1_score
AUC = roc_auc_score(labels_test, labels_test_pre) # AUC
''' 或者:
fpr, tpr, thresholds = roc_curve(labels_test, labels_test_pre) # 计算真正率和假正率
AUC = auc(fpr, tpr) # 根据计算出的真正率和假正率计算 AUC
'''(1)roc_curve:用来计算 假正率 fpr 和真正率 tpr;
(2)auc:计算 ROC 曲线下的面积 area;
(3)roc_auc_score:计算 AUC,即预测得分下的 auc,也就是输出的AUC。在计算的时候调用了 auc,它不能用于多分类。
(参考:curve函数 roc_分类器指标ROC曲线和AUC值)
(参考:sklearn:auc、roc_curve、roc_auc_score)
(参考:sklearn学习:为什么roc_auc_score()和auc()有不同的结果?)
2. 绘制混淆矩阵、ROC曲线
七、特征选择
(参考:机器学习中特征选择概述)
(参考:机器学习中的特征选择_hellozhxy的博客-CSDN博客)
1. 方法一:使用 tree 库函数输出特征重要性
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion='gini')
fea_importances = clf.feature_importances_ # 特征重要性(参考:在Python中获取clf.feature_importances)
2. 方法二:使用 lgb 输出特征重要性

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)