
文本分类任务和命名实体识别任务进行多任务学习中的问题
与标准的单任务相比,在学习共享表示的同时训练多个任务有两个主要挑战:Loss Function(how to balance tasks):多任务学习的损失函数,对每个任务的损失进行权重分配,在这个过程中,必须保证所有任务同等重要,而不能让简单任务主导整个训练过程。手动的设置权重是低效而且不是最优的,可能会出现第一个任务已经训练的很好了,然而第二个任务还完全没有收敛。
在训练的时候发现分类任务训练的已经很好了,但是NER的F1值还没有上去。。。
与标准的单任务相比,在学习共享表示的同时训练多个任务有两个主要挑战:
- Loss Function(how to balance tasks):多任务学习的损失函数,对每个任务的损失进行权重分配,在这个过程中,必须保证所有任务同等重要,而不能让简单任务主导整个训练过程。手动的设置权重是低效而且不是最优的,可能会出现第一个任务已经训练的很好了,然而第二个任务还完全没有收敛。
在此任务中,将两个任务的loss相加,可手动设置每个任务的权重
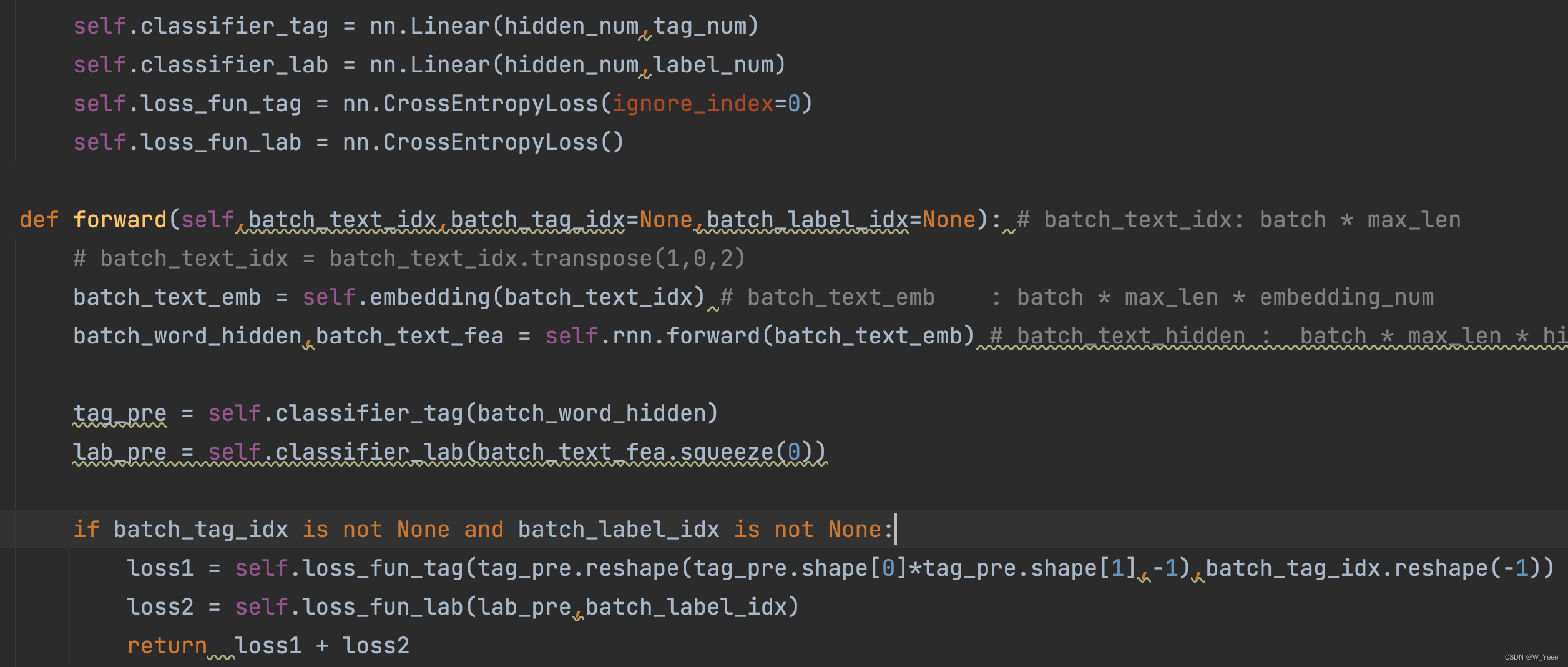
但是整体的loss,这种loss的计算方式的不合理之处是显而易见的,不同任务loss的量级很有可能是不一样的,loss直接相加的方式有可能会导致多任务 的学习被其中某一个任务所主导或者学偏。当模型倾向于去拟合某个任务的时候,另外一个任务的效果往往可能受到负面影响,效果会相对变差(看数据的拟合程度了估计),
相对于loss直接相加的方式,这个loss函数对于每个任务的loss进行加权。这种方式允许我们手动调整每个任务的重要性程度;但是固定的w会一直伴随整个训练周期。这种loss权重的设置方式可能也是存在问题的,不同任务学习的难易程度也是不同的;且,不同任务可能处于不同的学习阶段,比如任务A接近收敛,任务B仍然没训练好等。这种固定的权重在某个阶段可能会限制了任务的学习。就比如说第一个任务比较简单,收敛的比较快,可以将权重设置的小一点比如锁0.3,后面的任务相对复杂,收敛的比较慢,就可以将权重设置的大一点,比如0.7.
其实这是目前深度学习领域被某种程度上忽视了的一个重要问题,在近几年大火的multi-task learning,很多paper的做法都是暴力调参结果玄学。
极端情况下,当某个任务的loss非常的大而其它任务的loss非常的小,此时多任务近似退化为单任务目标学习,网络的权重几乎完全按照大loss任务来进行更新,逐渐丧失了多任务学习的优势。

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)