
大数据培训hive数仓存储格式详解
Hive简介Hive 是基于 Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载。这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。hive 数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供 SQL 查询功能,能将 SQL 语句转变成 MapReduce 任务来执行。一、文件存储格式在HIVE中,常见的文件存储格式有1 TextFile2 Parquet
Hive简介
Hive 是基于 Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载。
这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
hive 数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供 SQL 查询功能,能将 SQL 语句转变成 MapReduce 任务来执行。
一、文件存储格式
在HIVE中,常见的文件存储格式有
1 TextFile
2 Parquet
3 ORC
4 Sequencefile
5 RC
6 AVRO
注意:TextFile、Sequencefile 基于行存储,ORC、Patquet基于列存储。
行存储和列存储
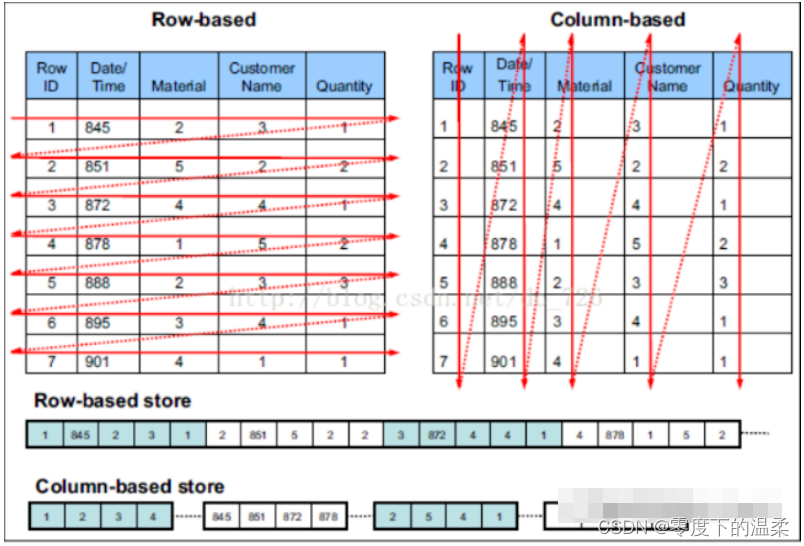
行存储的特点:查询满足条件的一整行数据时,列式存储则需要去每个聚集的字段找到对应的每列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询数据更快。
列式存储的特点:查询满足条件的一整列数据的时候,行存储则需要去每个聚集的字段找到对应的每个行的值,列存储只需要找到其中一个值,其余的值都在相邻的地方,所以此时列式查询的速度更快。另一方面,每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的压缩算法
当查询结果为一整行的时候,行存储效率会高一些;当查询表中某几列时,大数据培训列存储的效率会更高。
在对数据的压缩方面,列存储比行存储更有优势,所以列存储占用空间相对小一些。
1.TextFile
Hive中默认的存储文件格式,行存储。每一行都是一条记录,每行都以换行符(\n)结尾。数据不做压缩,磁盘开销大,数据解析开销大。文件拷贝至hdfs不进行处理。
优点:最简单的数据格式,便于和其他工具(Pig,grep,sed,awk)共享数据,便于查看和编辑;加载较快
缺点:耗费存储空间,I/O性能较低;Hive不进行数据切分合并,不能进行并行操作,查询效率低。
应用场景:适合于小型查询,查看具体数据内容的和测试操作。
建表是进行限定:
stored as textfile
2.sequencefile
含有键值对的二进制文件,行存储,Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点
优点:可压缩、可分割,优化磁盘利用率和I/O;可并行操作数据,查询效率高
缺点:存储空间消耗最大;对于Hadoop生态系统之外的工具不适用,需要通过text文件转换加载
解释:text转换加载,是指linux的shell端的 -text 命令来查看二进制数据
应用场景:适用于数据量较小,大部分列的查询。
建表是进行限定:
sorted as sequencefile
3.RC
是一种行列存储相结合的存储方式。首先,将数据按行分块,保证同一个record在一个快上,避免读一个记录需要读取多个block。其次,快数据列式存储,有利于数据压缩和快速的列存储。
4.orc(工作中常用)
orc文件代表了优化排柱状的文件格式。orc文件格式提供了一种将数据存储在Hive表中的高效方法。这个文件系统实际上是为了克服其他Hive文件格式的限制而设计的。HIve从大型表读取、写入和处理数据时,使用orc文件可以提高性能
数据按行分块 每块按列存储。
特点:压缩快,快速列存取、是rcfile的改良版本。
缺点:加载时性能消耗较大;需要通过text文件转化加载;
应用场景:适用于Hive中大型的存储、查询
建表是进行限定:
sorted as orc
5.parquet
parquet类似于orc、相对于orc文件格式,hadoop生态系统中大部分工程都支持parquet文件。
存储模式:按列存储,Parquet文件是以二进制方式存储的,不可以直接读取和修改,文件是自解析的,文件中包括该文件的数据和元数据。
优点:Parquet能够很好的压缩和编码,有良好的查询性能,支持优先的模式演进。
缺点:写速度通常比较慢,不支持update、insert,delete、ACID等特性。
应用场景:适用于字段数非常多,无更新、只取部分列的查询。
文章来源于robin

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)