
《从青铜学到王者》Python 深度学习 之 递归神经网络RNN
递归神经网络简介递归神经网络是在传统的神经网络基础上的改进,普通的神经网络,先进入输入,隐藏层,在输出结果。而RNN网络会考虑数据之间的时间序列关系。加入数据集中有一个时间序列,普通的神经网络并不能考虑这么一个序列,不认为t1和t2和t3之间的关系,每一个操作都是独立来进行的。但是如果是一个时序的数据,数据之间就有相关性,那么网络能不能学习到由于时间的关系,而对最后的结果造成影响呢?这就是RNN的
文章目录

递归神经网络简介
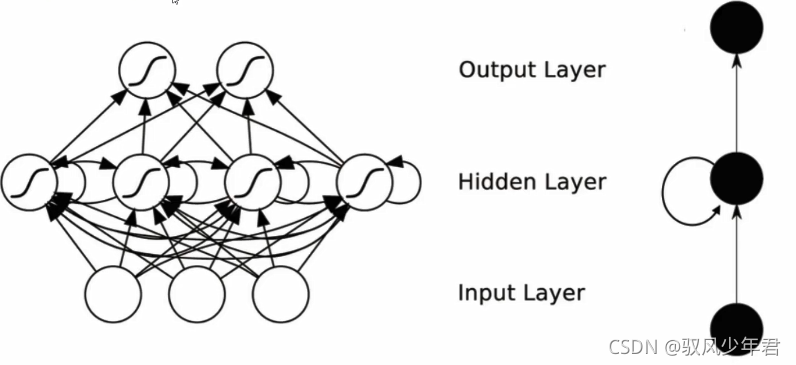
递归神经网络是在传统的神经网络基础上的改进,普通的神经网络,先进入输入,隐藏层,在输出结果。而RNN网络会考虑数据之间的时间序列关系。
加入数据集中有一个时间序列,普通的神经网络并不能考虑这么一个序列,不认为t1和t2和t3之间的关系,每一个操作都是独立来进行的 。但是如果是一个时序的数据,数据之间就有相关性,那么网络能不能学习到由于时间的关系,而对最后的结果造成影响呢?这就是RNN的特点。
RNN的隐藏层,数据经过隐藏层后,得到的特征,再输出。RNN会把前一层的输出结果参与到下一层的输入计算,即X2数据进入计算的时候,此时的输入,不止X2还有X1的中间特征结果一起进入输入,同时传入到隐藏层之中。
-
会把前一层得到的中间结果保留下来,参与下一层一起的运算。在计算Hn+1的时候会考虑到之前的H0-Hn。
-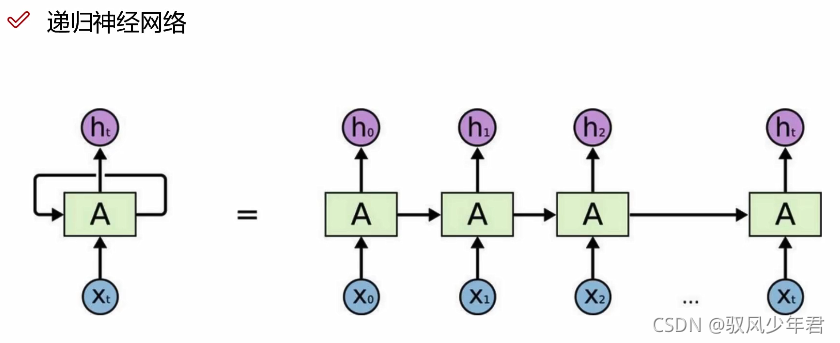
ht表示之前的所有数据的特征结果,在RNN一般只考虑最后的输出结果,前面H0-Ht-1都只是一个中间结果。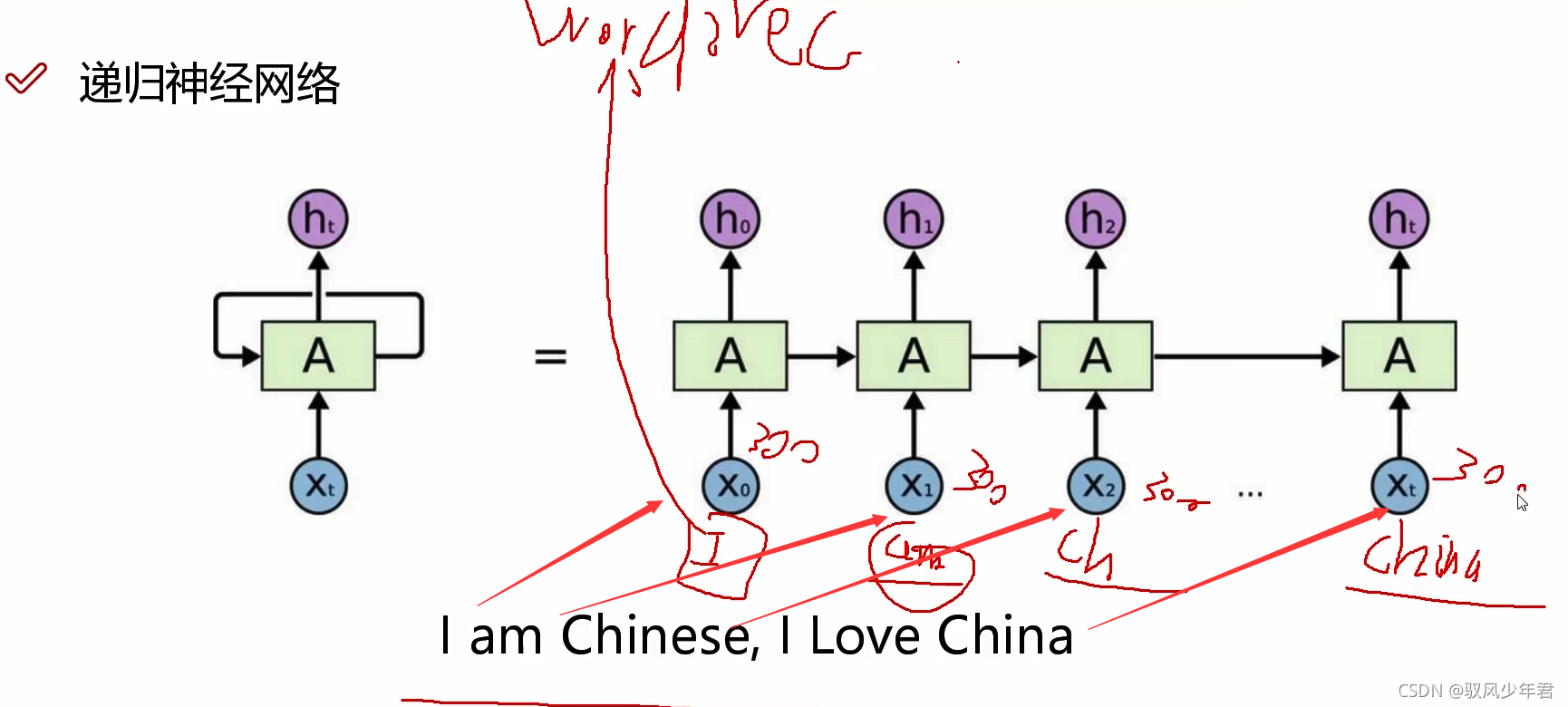
需要将每个单词通过word2vec转为向量,参与计算。 -
RNN记忆能力太强了,最后一个结果会考虑之前的所有的结果。但是有的时候其实前面的结果不都重要,可能也只有近期的数据才重要。记得太多也会造成误差和错误。
-
LSTM可以选择性的去忘记一些特征,过滤一些不必要的特征。
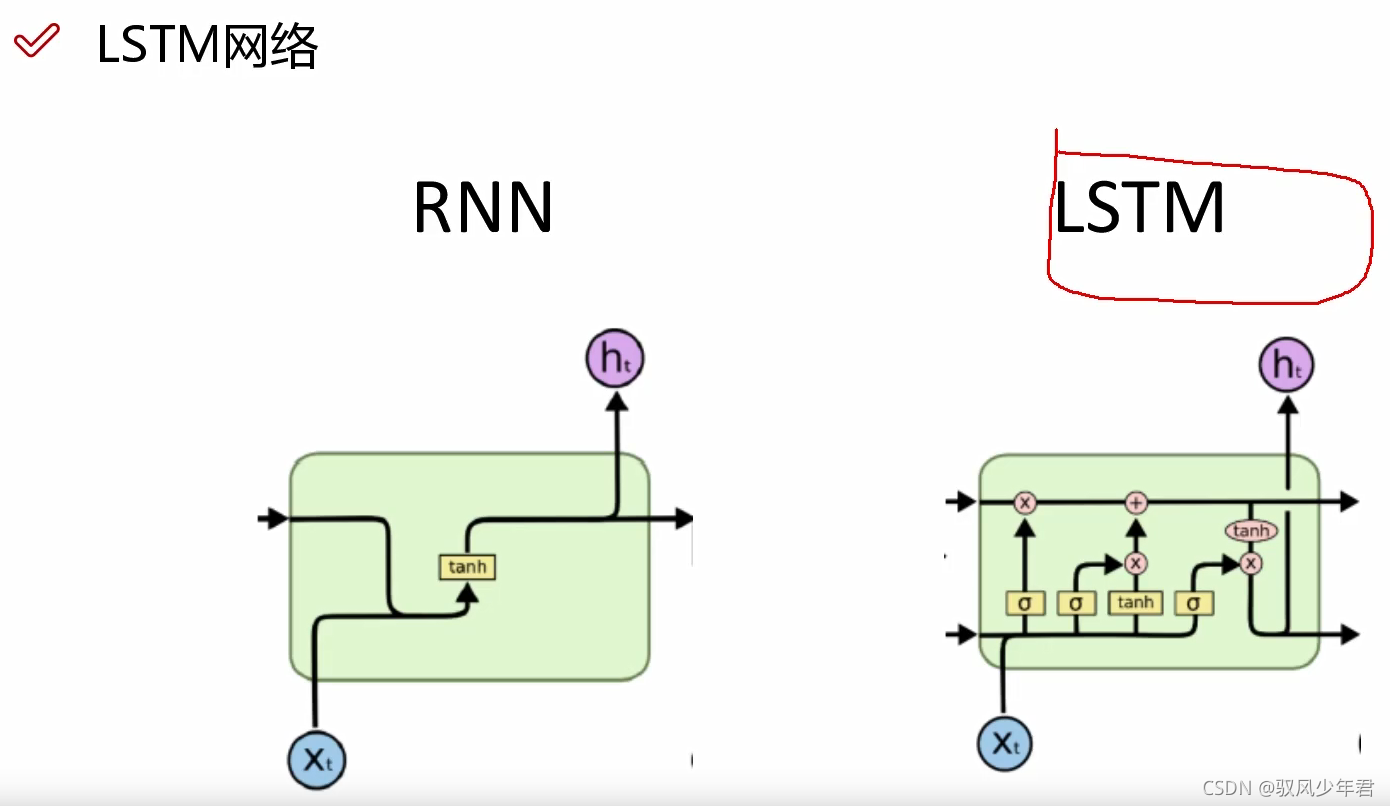
RNN的核心: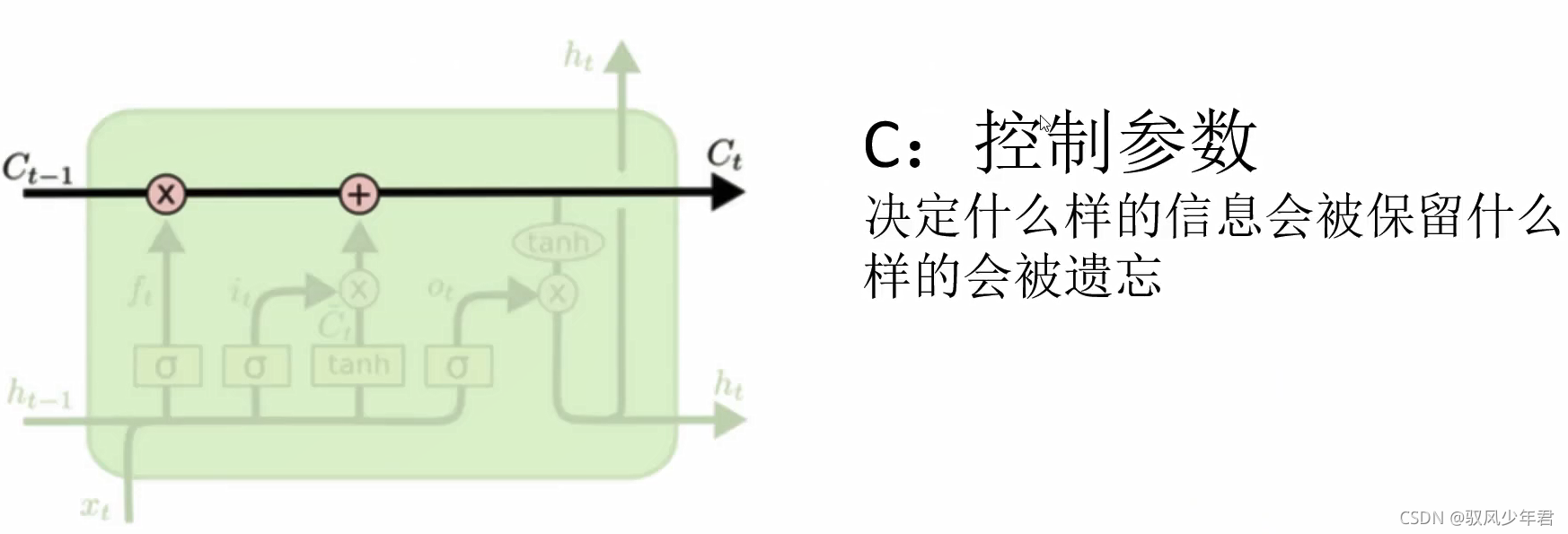
门单元: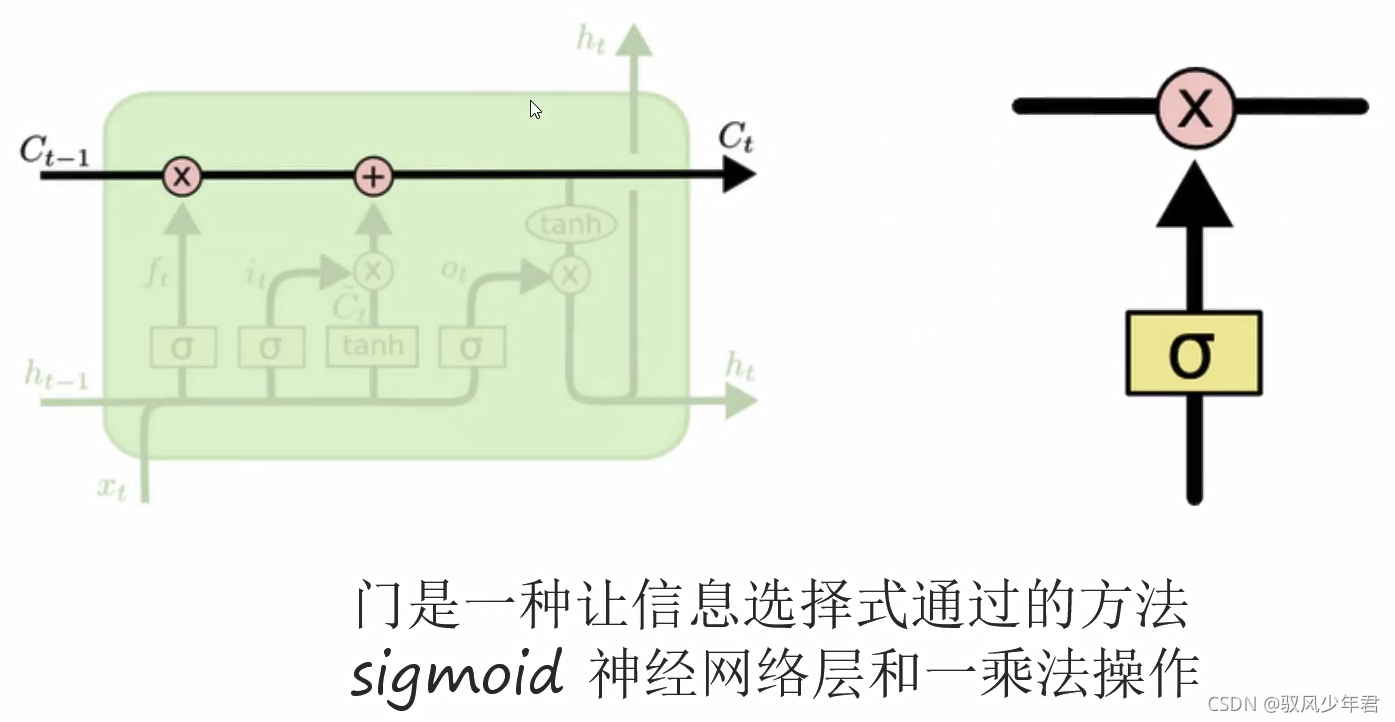
LSTM的基本的架构: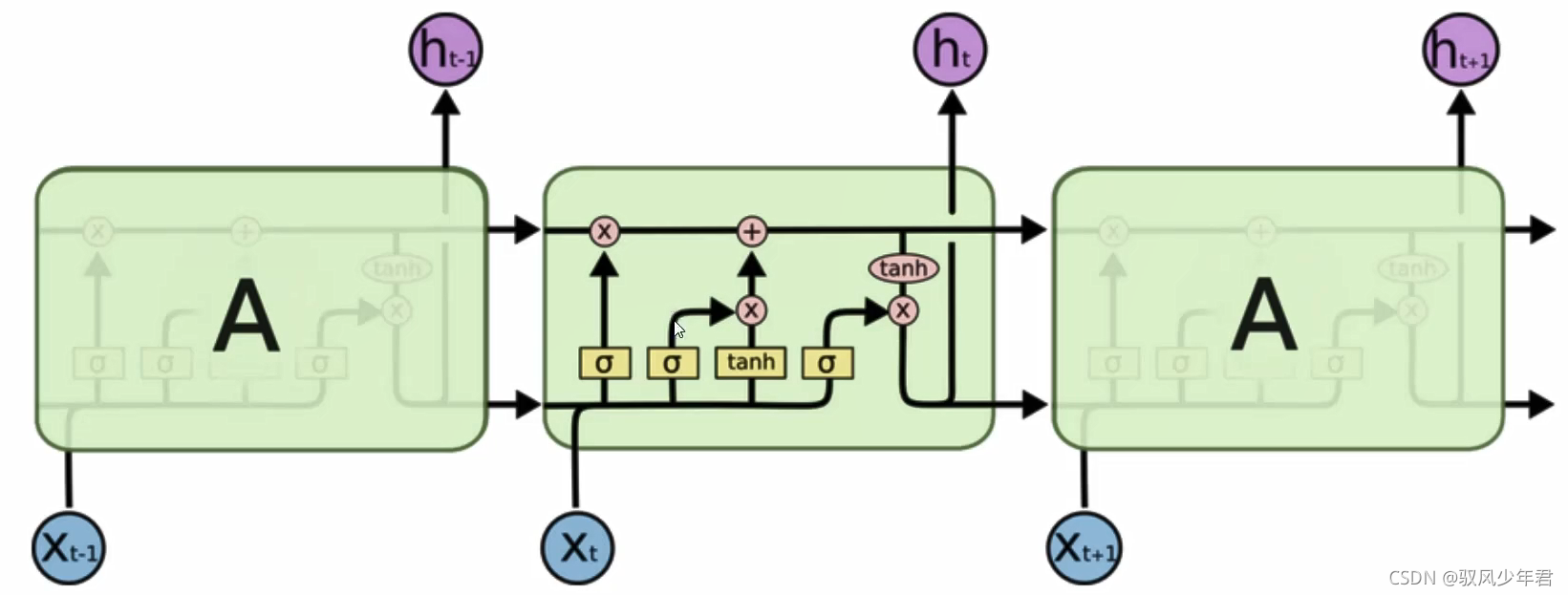
sigmoid函数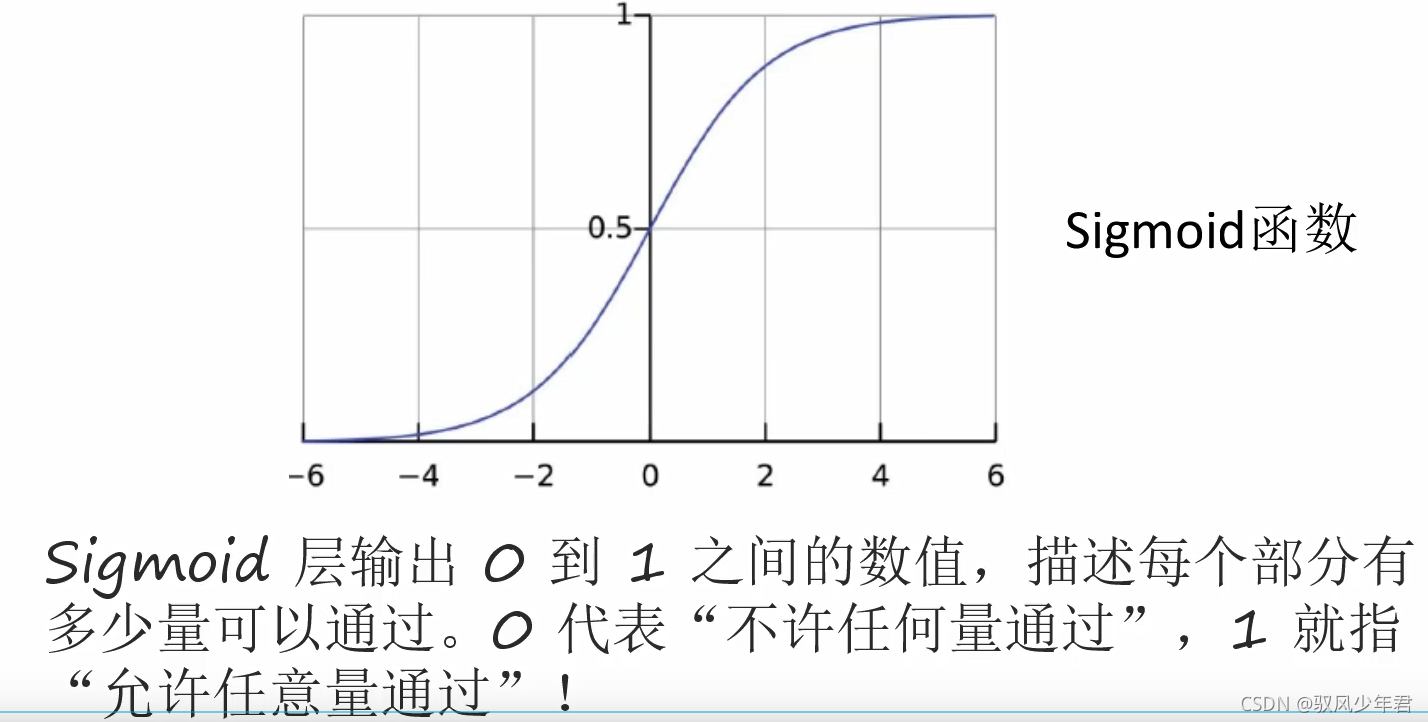
遗忘门: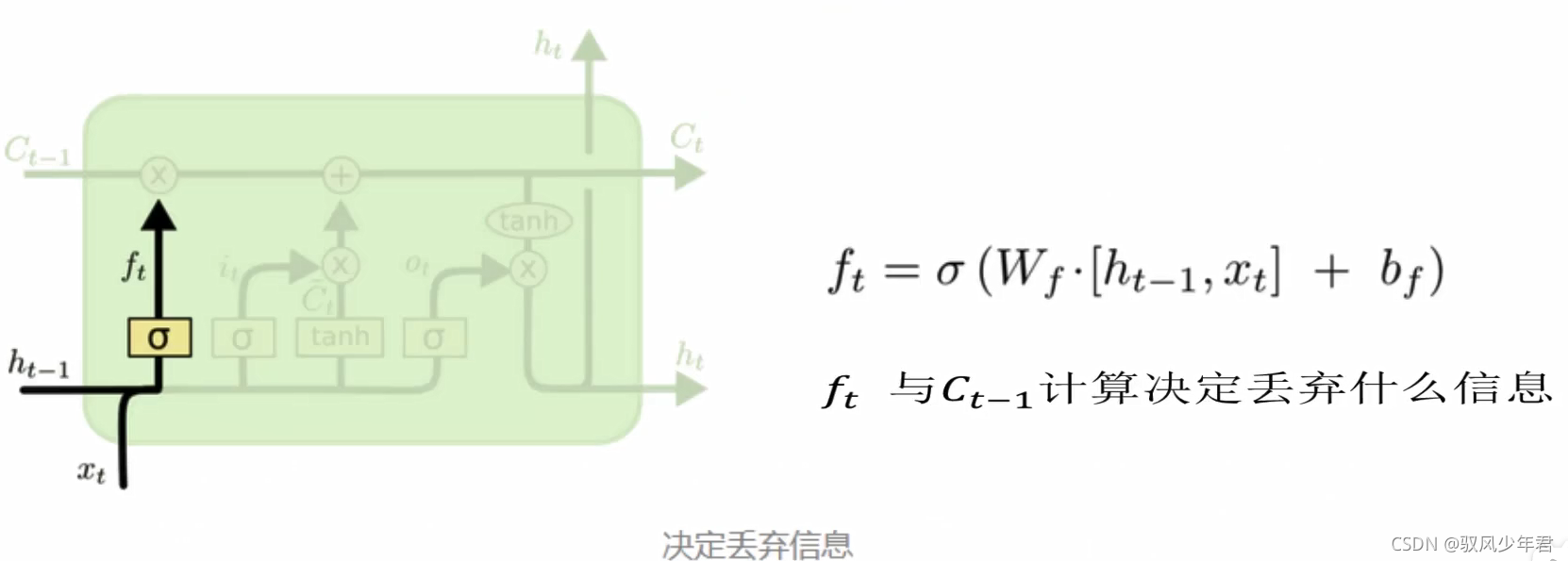
更新门: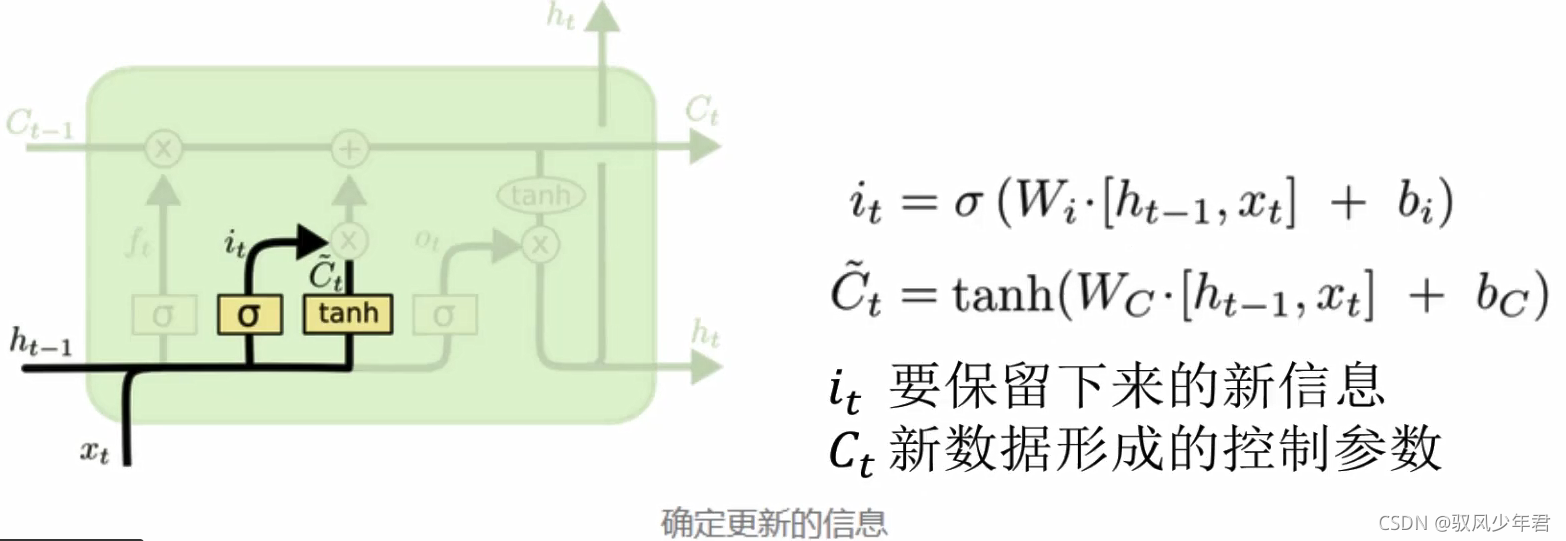
使用LSTM进行情感分析
深度学习在自然语言处理中的应用
自然语言处理是教会机器如何去处理或者读懂人类语言的系统,主要应用领域:
- 对话系统–聊天机器人(小冰)
- 情感分析-对一段文本进行情感识别(我们一会要做的)
- 图文映射- CNN和RNN的融合
- 机器翻译-将一种语言翻译成另一种语言,现在谷歌做的太牛了
- 语音识别–能不能应用到游戏上,王者荣耀摁的手疼
词向量模型
计算机可只认识数字
将词进行编码转化为计算机可以认识的数值特征。word2vec,可以通过训练一个模型,将每一个词都转化为一个数值向量。每一个词的向量的长度都是一致的。
你可以将输入数据看成是一个16*D的一个矩阵。
词向量是具有空间意义的并不是简单的映射!例如,我们希望单词“love"和"adore’这两个词在向量空间中是有一定的相关性的,因为他们有类似的定义,他们都在类似的上下文中使用。单词的向量表示也被称之为词嵌入。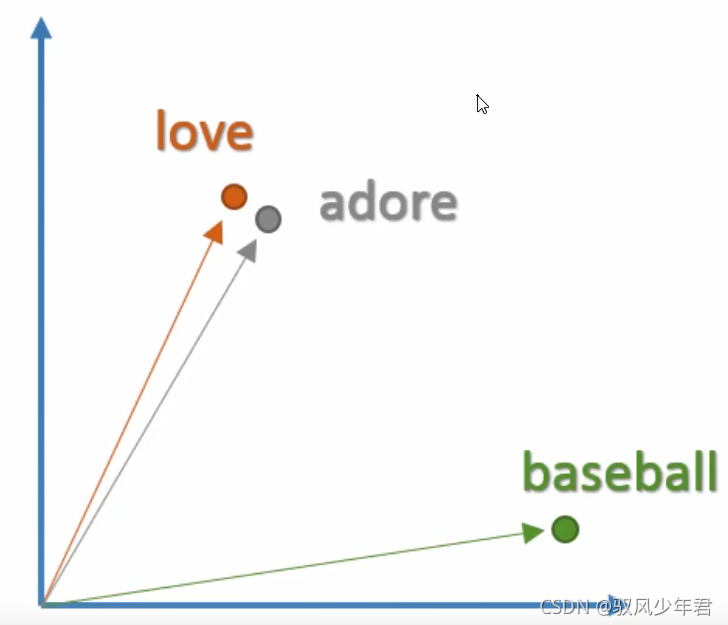
对于不同的词,建立一个词袋模型或者说是TF-IDF模型,对于不同的词会区别对待,比如,喜欢和喜爱。这两者之间是完全不同的。
但是在词向量模型中,在一个高纬度中间中,意思相同的词,他们之间的距离是非常相近的。词向量并不是简单的数值编码,而是其中的每一个值都有一个实际的意义。
Word2Vec
为了去得到这些词嵌入,我们使用一个非常厉害的模型Word2Vec。简单的说,这个模型根据上下文的语境来推断出每个词的词向量。如果两个个词在上下文的语境中,可以被互相替换,那么这两个词的距离就非常近。在自然语言中,上下文的语境对分析词语的意义是非常重要的。比如,之前我们提到的*adore"和"love”这两个词,我们观察如下上下文的语境。
l
从句子中我们可以看到,这两个词通常在句子中是表现积极的,而且一般比名词或者名词组合要好。这也说明了,这两个词可以被互相替换,他们的意思是非常裾近的。对于句子的语法结构分析,上下文语境也是非常重要的。所有,这个模型的作用就是从一大堆句子(以Wikipedia为例)中为每个独一无二的单词进行建模,并且输出一个唯一的向量。Word2Vec模型的输出被称为一个嵌入矩阵。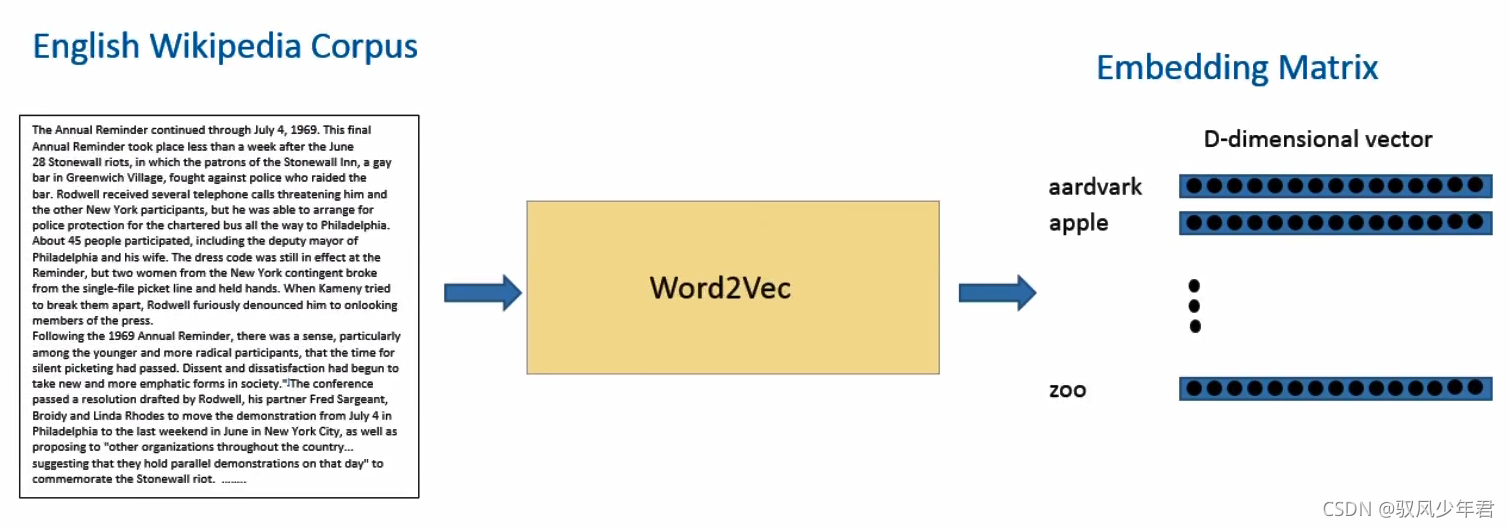
通过word2Vec先将所有出现的词都训练成一个个向量,读取语料库,对比word2vec,将文章中的每一个词按照顺序,去取得每个词的向量。就完成了将每个词转为向量,
这个嵌入矩阵(embeding Matrix)包含训练集中每个词的一个向量。传统来讲,这个嵌入矩阵中的词向量数据会很大。
Word2NVec模型根据数据集中的每个句子进行训练,并且以一个固定窗口在句子上进行滑动,根据句子的上下文来预测固定窗口中间那个词的向量。然后根据一个损失函数和优化方法,来对这个模型进行训练。
Recurrent Neural Networks (RNNs)
现在,我们已经得到了神经网络的输入数据——词向量,接下来让我们看看需要构建的神经网络。NLP数据的一个独特之处是它是时间序列数据。每个单词的出现都依赖于它的前一个单词和后一个单词。由于这种依赖的存在,我们使用循环神经网络来处理这种时间序列数据。
循环神经网络的结构和你之前看到的那些前馈神经网络的结构可能有一些不一样。前馈神经网络由三部分组成,输入层,隐藏层和输出层。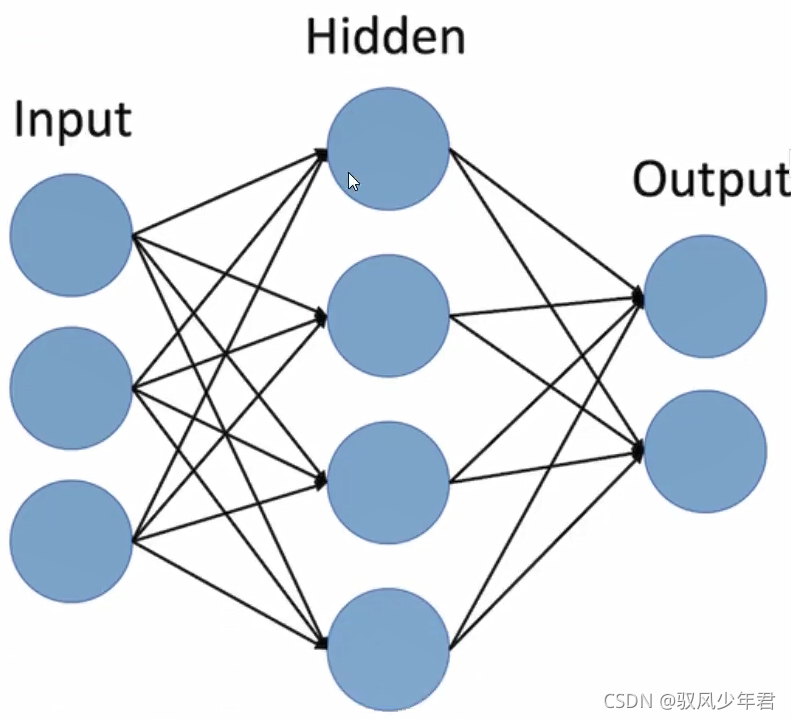
前馈神经网络和RNN之前的主要区别就是RN考虑了时间的信息。在RNN中,句子中的每个单词都被考虑上了时间步骤。实际上,时间步长的数量将等于最大序列长度。
与每个时间步骤相关联的中间状态也被作为一个新的组件,称为隐藏状态向量th()。从抽象的角度来看,这个向量是用来封装和汇总前面时间步骤中所看到的所有信息。就像x(t)表示一个向量,它封装了一个特定单词的所有信息。
隐藏状态是当前单词向量和前一步的隐藏状态向量的函数。并且这两项之和需要通过激活函数来进行激活。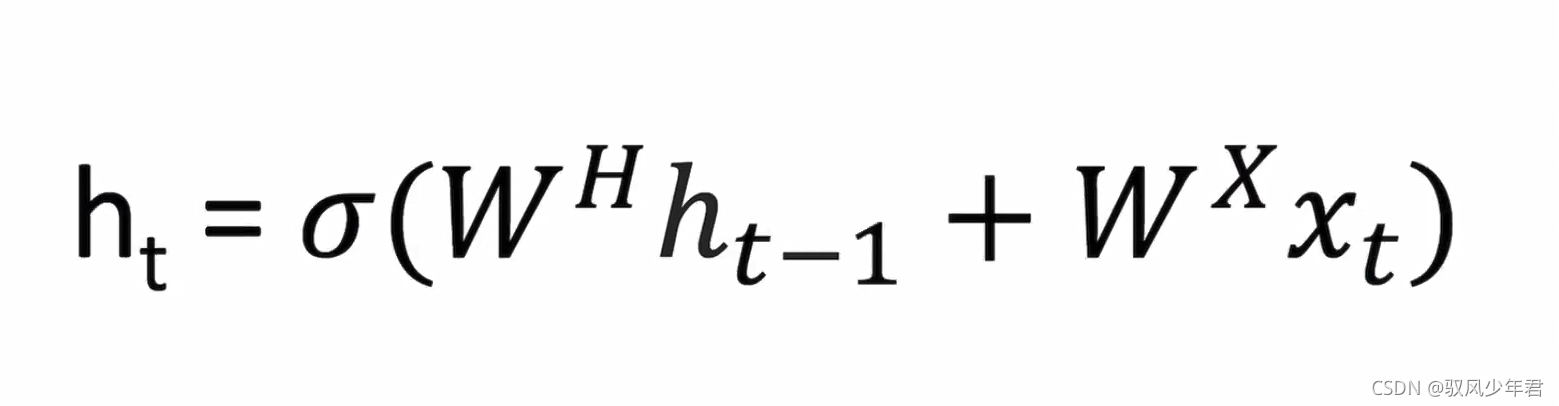
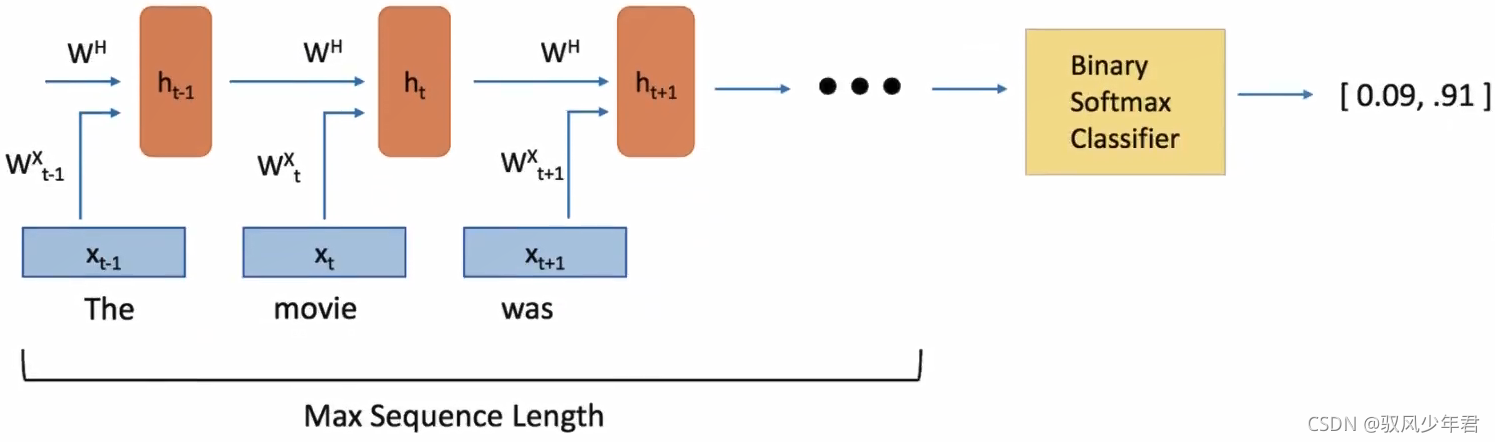
Long Short Term Memory Units (LSTMs)
长短期记忆网络单元,是另一个RN中的模块。从抽象的角度看,LSTM保存了文本中长期的依赖信息。正如我们前面所看到的,H在传统的RNN网络中是非常简单的,这种简单结构不能有效的将历史信息链接在一起”举个例子,在问答领域中,假设我们得到如下一段文本,那么LSTM就可以很好的将历史信息进行记录学习。
在这里,我们看到中间的句子对被问的问题没有影响。然而,第一句和第三句之间有很强的联系。对于一个典型的RNN网络,隐藏状态向量对于第二句的存储信息量可能比第一句的信息量会大很多。但是LSTM,基本上就会判断哪些信息是有用的,哪些是没用的,并且把有用的信息在LSTM中进行保存。
我们从更加技术的角度来谈谈LSTM单元,该单元根据输入数据x(),隐藏层输出h()。在这些单元中, h(t)的表达形式比经典的RN网络会复杂很多。这些复杂组件分为四个部分:输入门,输出门,遗忘门和一个记忆控制器。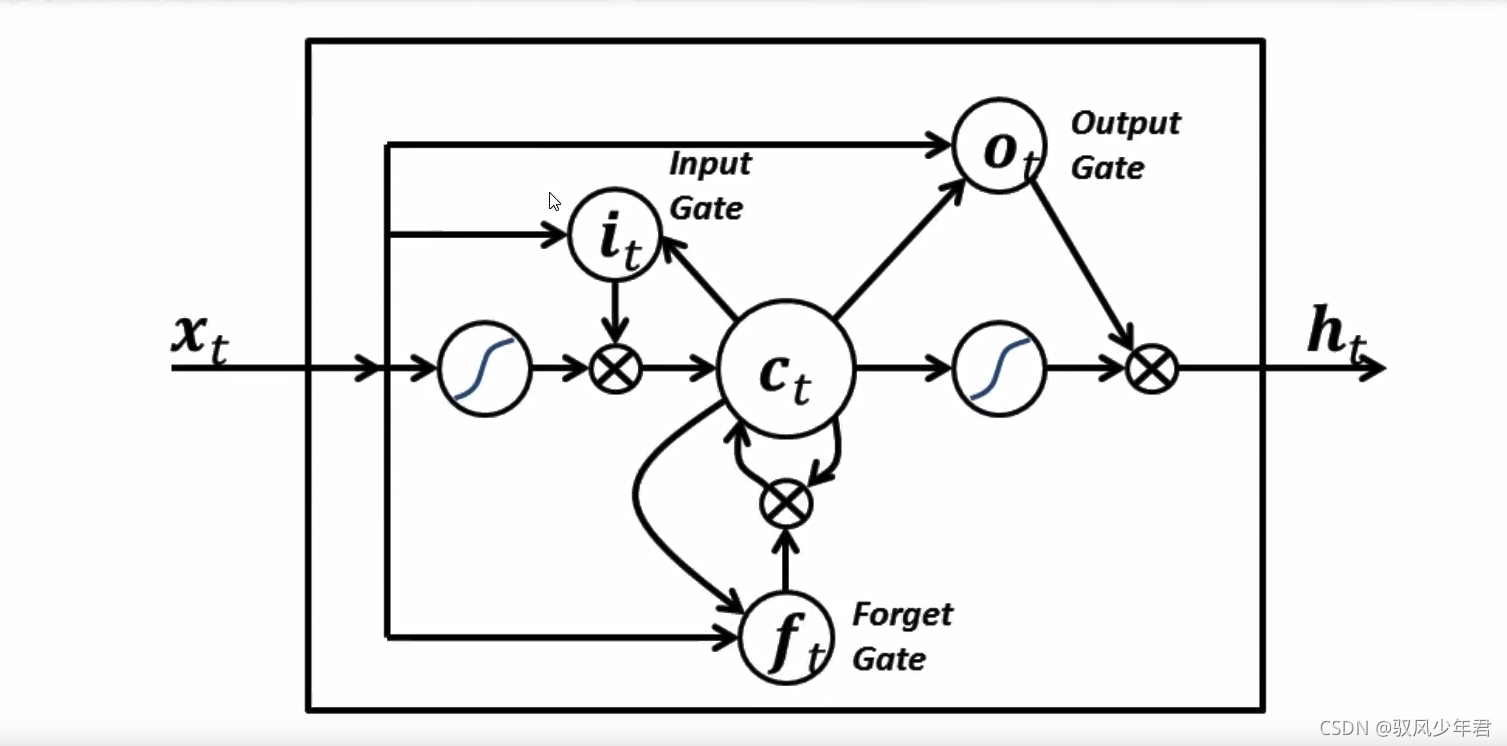
每个门都将x(t)和h(-1)作为输入(没有在图中显示出来),并且利用这些输入来计算一些中间状态。每个中间状态都会被送入不同的管道,并且这些信息最终会汇集到h()。为简单起见,我们不会去关心每一个门的具体推导。这些门可以被认为是不同的模块,各有不同的功能。输入门决定在每个输入上施加多少强调,遗忘门决定我们将丢弃什么信息,输出门根据中间状态来决定最终的h(t)。
案例流程
1)制作词向量,可以使用gensim这个库,也可以直接用现成的(可以自己训练,也可以用别人训练的,因为同一个语种互通),但是在专门的领域,有专业词汇的时候,还是要领域的词汇训练的效果好点,比如医学。
2)词和ID的映射,常规套路了 (tensorflow要求,方便取得向量)
3)构建RNN网络架构
4))训练我们的模型
5)试试咋样
导入数据
首先,我们需要去创建词向量。为了简单起见,我们使用训练好的模型来创建。
作为该领域的一个最大玩家,Google已经帮助我们在大规模数据集上训练出来了Word2Nec模型,包括1000亿个不同的词!在这个模型中,谷歌能创建300万个词向量,每个向量维度为300。
在理想情况下,我们将使用这些向量来构建模型,但是因为这个单词向量矩阵相当大(3.6G),我们用另外一个现成的小一些的该矩阵由GloVe进行训练得到。矩阵将包含400000个词向量,每个向量的维数为50。
我们将导入两个不同的数据结构,一个是包含400000个单词的Python列表,一个是包含所有单词向量值得400000*50维的嵌入矩阵。

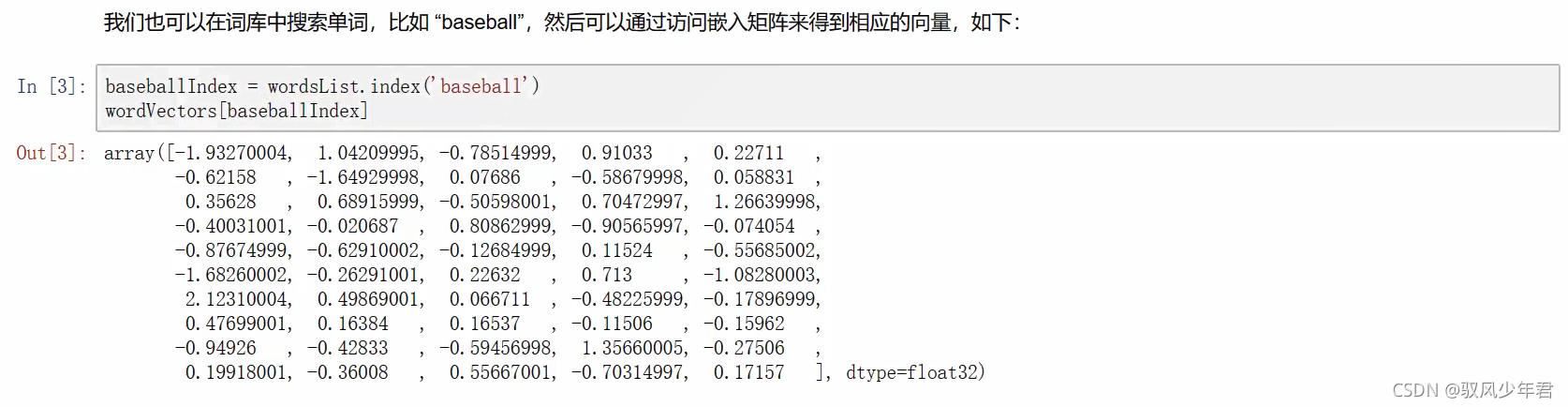
现在我们有了向量,我们的第一步就是输入一个句子,然后构造它的向量表示。假设我们现在的输入句子是a1lthoughthe move was incredible and insping"。为了得到词向量,我们可以使用TensorFlow的嵌入函数。这个函数有两个参数,一个是嵌入矩阵(在我们的情况下是词向量矩阵),另一个是每个词对应的索引。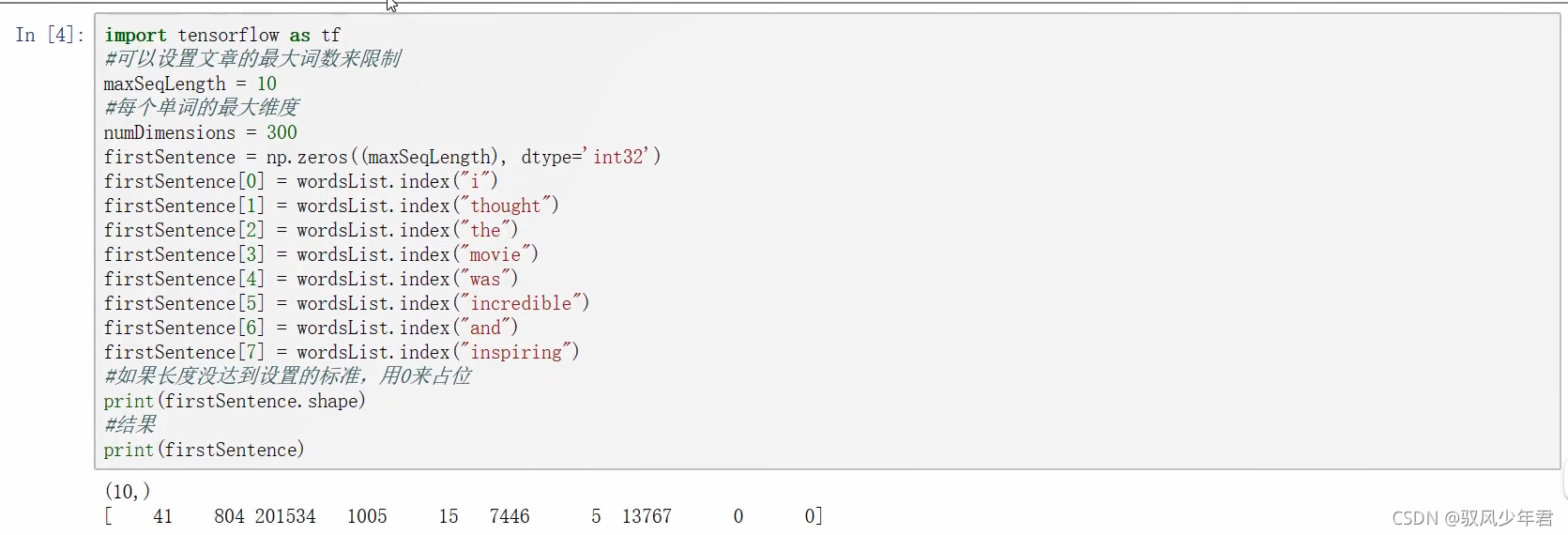
数据管道如下所示: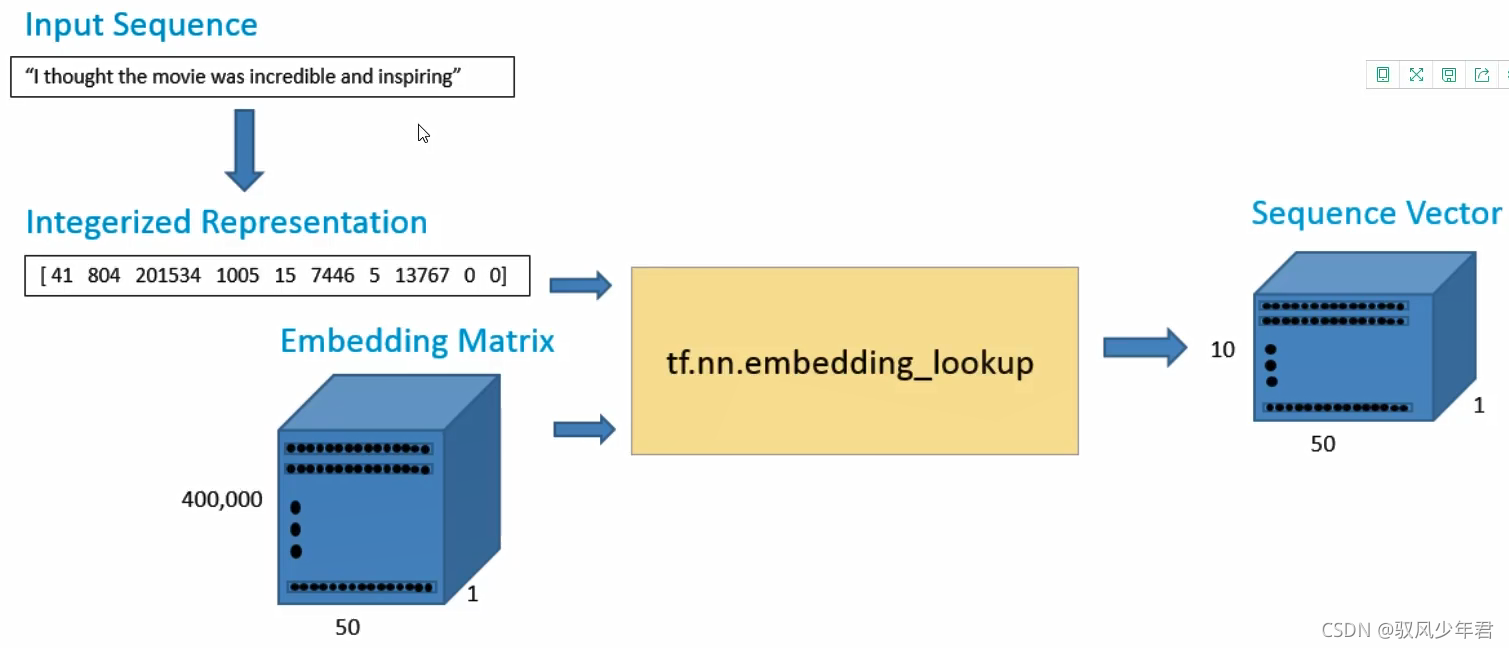
将每一句话的词转为ID,通过tf.nn.embedding_lookup函数转为向量。这个函数需要输入ID映射列表和词向量表,这个函数会完成查找词向量表,再输出。
输出数据是一个10*50 的词矩阵,其中包括10个词,每个词的向量维度是50。就是去找到这些词对应的向量
在整个训练集上面构造索引之前,我们先花一些时间来可视化我们所拥有的数据类型。这将帮助我们去决定如何设置最大序列长度的最佳值。在前面的例子中,我们设置了最大长度为10,但这个值在很大程度上取决于你输入的数据。
训练集我们使用的是IMDB数据集。这个数据集包含2500 条电影数据,其中1250O 条正向数据,12500条负向数据。这些数据都是存储在一个文本文件中.首先我们需要做的就是去解析这个文件。正向数据包含在一个文件中,负向数据包含在另一个文件中。
情感积极数据集加载完毕
情感消极数据集加载完毕
总共文件数量25000
全部词语数量5844680
平均每篇评论词语数量233.7872
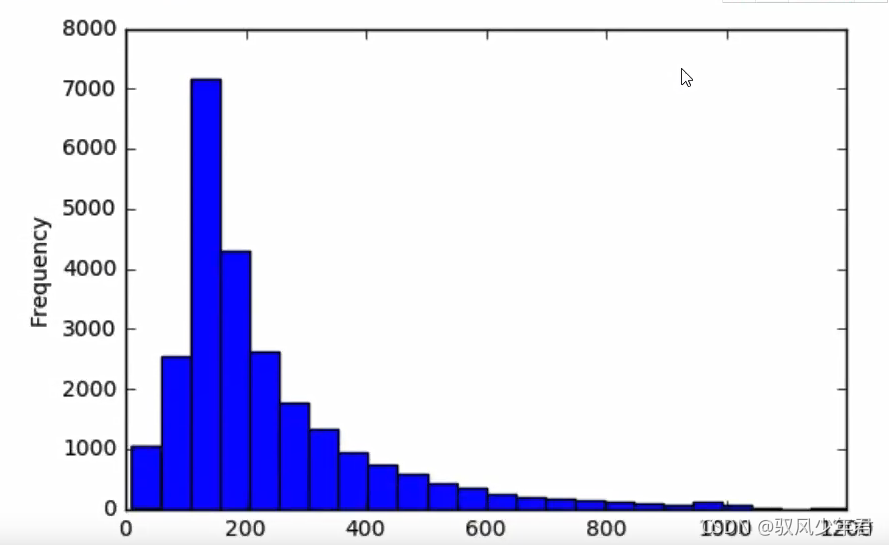
从直方图和句子的平均单词数,我们认为将句子最大长度设置为250是可行的。设置阈值
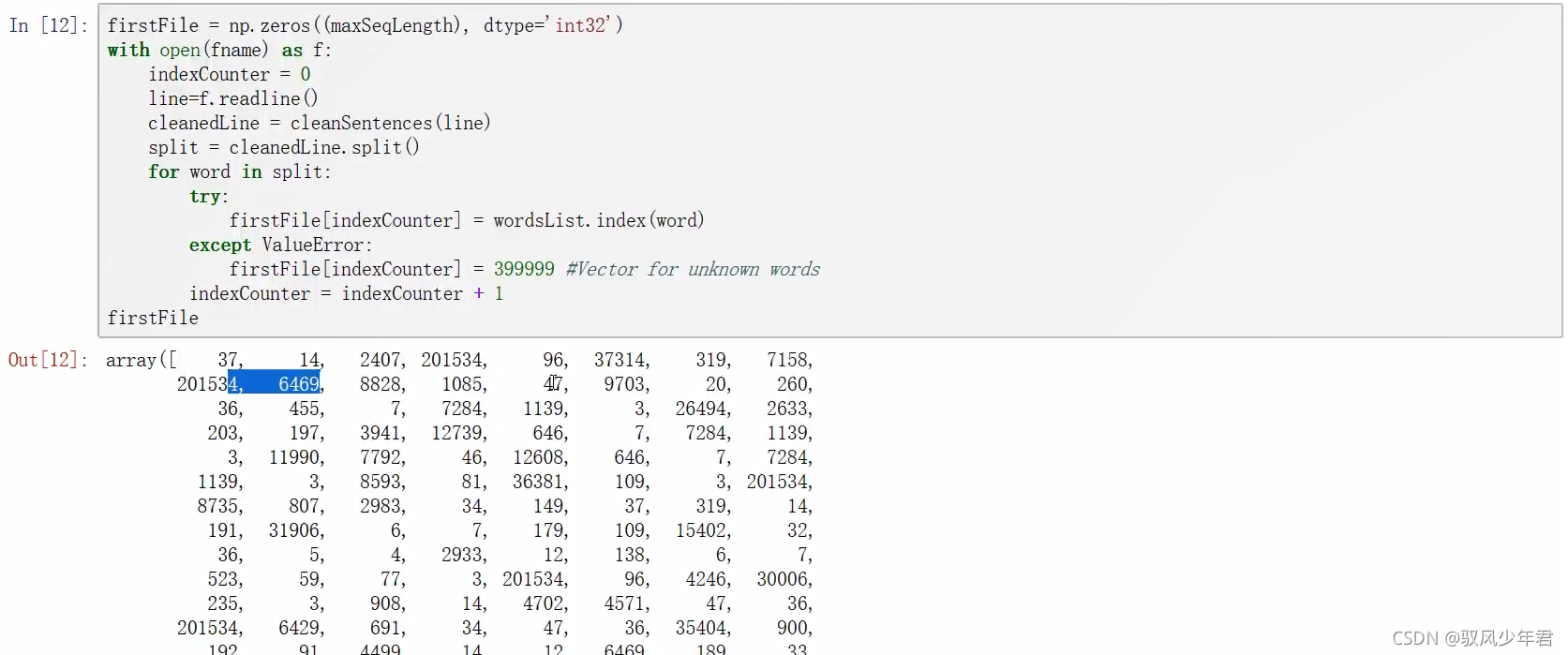
接下来,让我们看看如何将单个文件中的文本转换成索引矩阵,比如下面的代码就是文本中的其中一个评论。
接下来,我们将它转换成一个索引矩阵。
现在,我们用相同的方法来处理全部的25000 条评论。我们将导入电影训练集,并且得到一个2500*250的矩阵。这是一个计算成本非常高的过程,可以直接使用理好的索引矩阵文件。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)