
深度学习入门Day6:循环神经网络与文本处理实战
本文介绍了从RNN到注意力机制的序列数据处理方法。首先分析了基础RNN的梯度消失问题,对比了LSTM和GRU的门控机制差异;随后展示了文本处理全流程,包括情感分析和文本生成任务;最后探讨了注意力机制的实现与可视化。文章总结了RNN训练技巧和注意力应用场景,并预告了Transformer架构的学习内容。关键点包括:1)长短序列分别适用不同模型;2)梯度裁剪和学习率预热等训练技巧;3)注意力机制在序列
一、开篇:从空间到时间的维度拓展
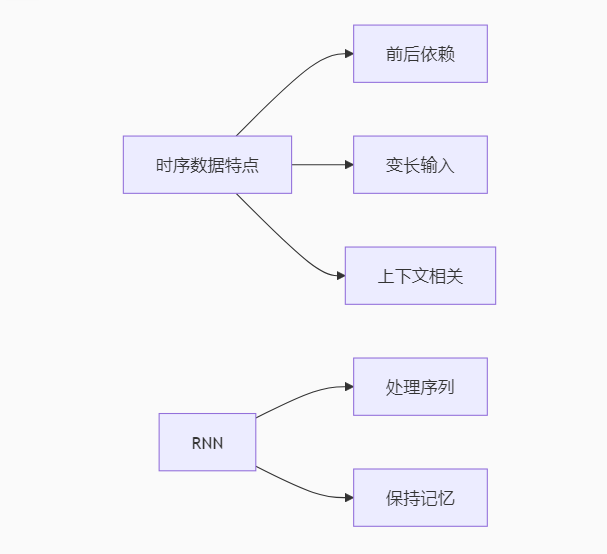
前五天我们聚焦于处理网格状数据(如图像)的CNN,今天将转向更具挑战性的序列数据领域。循环神经网络(RNN)通过引入"记忆"机制,让神经网络首次具备了处理时序数据的能力。从简单的RNN到精妙的LSTM,再到改变游戏规则的注意力机制,这些创新让我们能够处理文本、语音、股票行情等具有时间依赖性的数据。
---
二、上午学习:RNN原理与变体精析
2.1 基础RNN结构与缺陷
RNN计算图展开:
class VanillaRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.hidden_size = hidden_size
self.Wxh = nn.Parameter(torch.randn(input_size, hidden_size)*0.01
self.Whh = nn.Parameter(torch.randn(hidden_size, hidden_size)*0.01
self.bh = nn.Parameter(torch.zeros(hidden_size))
def forward(self, inputs, hidden):
# inputs形状: (seq_len, batch_size, input_size)
outputs = []
for x in inputs: # 按时间步迭代
hidden = torch.tanh(x @ self.Wxh + hidden @ self.Whh + self.bh)
outputs.append(hidden)
return torch.stack(outputs), hidden```
梯度问题分析:
- 梯度消失:长序列中早期信号难以影响后期(类似连乘效应)
- 梯度爆炸:权重矩阵乘积导致梯度指数增长
- 解决方案:梯度裁剪(`torch.nn.utils.clip_grad_norm_`)
2.2 LSTM与GRU门控机制对比
LSTM核心组件:
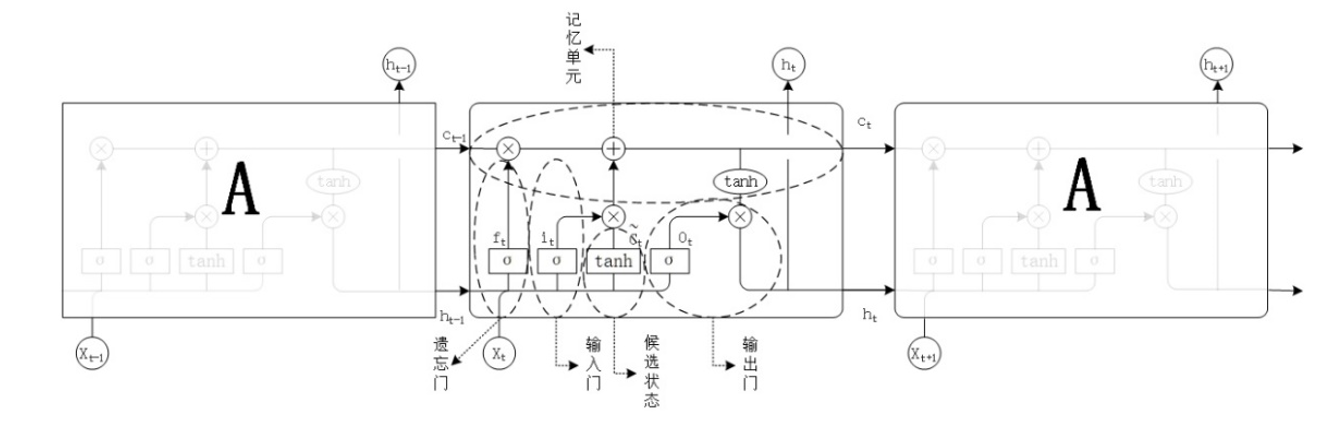
class LSTMCell(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
# 输入门/遗忘门/输出门/记忆单元(候选记忆)
self.gates = nn.Linear(input_size + hidden_size, 4*hidden_size)
def forward(self, x, hc):
h, c = hc
gates = self.gates(torch.cat([x, h], dim=1))
# 分割四个门
i, f, o, g = gates.chunk(4, 1)
i = torch.sigmoid(i) # 输入门
f = torch.sigmoid(f) # 遗忘门
o = torch.sigmoid(o) # 输出门
g = torch.tanh(g) # 记忆单元(候选记忆)
c_new = f * c + i * g # 记忆更新
h_new = o * torch.tanh(c_new)
return h_new, c_new```
GRU简化结构:
class GRUCell(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.reset_gate = nn.Linear(input_size + hidden_size, hidden_size)
self.update_gate = nn.Linear(input_size + hidden_size, hidden_size)
self.candidate = nn.Linear(input_size + hidden_size, hidden_size)
def forward(self, x, h):
combined = torch.cat([x, h], dim=1)
r = torch.sigmoid(self.reset_gate(combined))
z = torch.sigmoid(self.update_gate(combined))
combined_reset = torch.cat([x, r * h], dim=1)
h_candidate = torch.tanh(self.candidate(combined_reset))
h_new = z * h + (1 - z) * h_candidate
return h_new```
门控机制对比表
| 模型 | 参数量 | 训练速度 | 适用场景 |
|---|---|---|---|
| LSTM | 多(3个门) | 较慢 | 长序列 |
| GRU | 少(2个门) | 较快 | 短序列 |
| 双向RNN | 翻倍 | 最慢 | 需要上下文 |
---
三、下午实战:文本处理全流程
3.1 文本数据预处理流水线
from torchtext.data import get_tokenizer
from torchtext.vocab import GloVe
# 英文分词
tokenizer = get_tokenizer('spacy', language='en_core_web_sm')
# 加载预训练词向量
glove = GloVe(name='6B', dim=100)
# 文本向量化示例
text = "This movie is absolutely wonderful!"
tokens = tokenizer(text)
word_vectors = [glove[token] for token in tokens if token in glove]
sentence_vector = torch.stack(word_vectors).mean(dim=0) # 平均词向量```
3.2 IMDb情感分析实战
模型架构:
class SentimentRNN(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_size):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
# x形状: (batch_size, seq_length)
embedded = self.embedding(x) # (batch_size, seq_length, embed_dim)
lstm_out, _ = self.lstm(embedded)
# 取最后一个时间步的输出
out = self.fc(lstm_out[:, -1, :])
return torch.sigmoid(out)```
训练关键设置:
# 使用pad_sequence处理变长序列
from torch.nn.utils.rnn import pad_sequence
# 动态批处理函数
def collate_batch(batch):
texts, labels = zip(*batch)
lengths = [len(text) for text in texts]
texts_padded = pad_sequence(texts, batch_first=True)
return texts_padded, torch.tensor(labels), lengths
# 创建DataLoader
train_loader = DataLoader(train_data, batch_size=32,
shuffle=True, collate_fn=collate_batch)```
3.3 文本生成实验
字符级RNN生成器:
class CharRNN(nn.Module):
def __init__(self, vocab_size, hidden_size):
super().__init__()
self.embed = nn.Embedding(vocab_size, hidden_size)
self.rnn = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x, hidden):
x = self.embed(x)
output, hidden = self.rnn(x, hidden)
output = self.fc(output)
return output, hidden
def generate(self, start_str, length=100, temperature=1.0):
hidden = torch.zeros(1, 1, self.rnn.hidden_size)
input_seq = torch.tensor([char_to_idx[start_str[0]]).unsqueeze(0)
generated = start_str
for _ in range(length):
output, hidden = self(input_seq, hidden)
# 应用温度参数控制多样性
probs = F.softmax(output.squeeze() / temperature, dim=0)
next_char = torch.multinomial(probs, 1).item()
generated += idx_to_char[next_char]
input_seq = torch.tensor([next_char]).unsqueeze(0)
return generated```
温度参数效果对比
| 温度值 | 生成特点 | 适用场景 |
|---|---|---|
| <0.5 | 保守可预测 | 正式文本 |
| 0.5-1.0 | 平衡创意 | 诗歌创作 |
| >1.0 | 随机性强 | 实验探索 |
---
四、晚上探索:注意力机制初探
4.1 Bahdanau注意力实现
class Attention(nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.Wa = nn.Linear(hidden_size, hidden_size)
self.Ua = nn.Linear(hidden_size, hidden_size)
self.Va = nn.Linear(hidden_size, 1)
def forward(self, query, keys):
# query: (batch_size, hidden_size)
# keys: (batch_size, seq_len, hidden_size)
# 计算注意力分数
scores = self.Va(torch.tanh(self.Wa(query.unsqueeze(1)) + self.Ua(keys)))
scores = F.softmax(scores, dim=1)
# 加权求和
context = torch.sum(scores * keys, dim=1)
return context, scores```
4.2 带注意力的RNN模型
class AttnRNN(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_size):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.encoder = nn.GRU(embed_dim, hidden_size, bidirectional=True)
self.attention = Attention(hidden_size)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
embedded = self.embedding(x)
enc_out, _ = self.encoder(embedded)
# 取最后一个时间步作为查询向量
query = enc_out[:, -1, :hidden_size] # 正向最后状态
context, attn_weights = self.attention(query, enc_out[:, :, :hidden_size])
out = self.fc(context)
return torch.sigmoid(out), attn_weights```
注意力可视化示例:
# 展示注意力权重热力图
plt.imshow(attn_weights.squeeze().detach().numpy(), cmap='hot')
plt.xlabel('Input Sequence')
plt.ylabel('Attention Weight')
plt.colorbar()
plt.show()---
五、学习总结与明日计划
5.1 今日核心成果
✅ 掌握RNN/LSTM/GRU的结构差异与适用场景
✅ 实现文本情感分析完整流程(预处理→训练→评估)
✅ 构建字符级文本生成器并调节创造性
✅ 初步实现注意力机制并可视化权重分布
5.2 待解决问题
❓ Transformer的自注意力与今日实现的注意力区别
❓ 如何处理超长序列(如文档分类)
❓ 子词切分(BPE)与字符/词级处理的优劣
5.3 明日学习重点
- Transformer架构全面解析
- 实现自注意力机制
- 构建简易的Transformer模型
- 在机器翻译任务上测试性能
---
六、优质资源推荐
1. [LSTM可视化](http://lstm.seas.harvard.edu/):交互式理解门控机制
2. [Attention Is All You Need论文](https://arxiv.org/abs/1706.03762):Transformer开创性工作
3. [PyTorch Seq2Seq教程](https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html):实战机器翻译
4. [HuggingFace课程](https://huggingface.co/course/chapter1):现代NLP最佳实践
---
七、关键经验总结
1. 文本处理黄金法则:
- 短文本:词级处理+预训练词向量
- 长文本:字符级或子词级处理
- 重要技巧:截断/填充保持统一长度
2. RNN训练技巧:
# 梯度裁剪防止爆炸
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# 学习率预热
scheduler = torch.optim.lr_scheduler.LambdaLR(
optimizer, lr_lambda=lambda epoch: min(epoch/10, 1.0))
3. 注意力机制应用场景:
- 需要对齐的任务(机器翻译)
- 长文档关键信息提取
- 可解释性要求高的场景
"RNN教会我们:时间是重要的维度,而注意力机制告诉我们:时间维度上的每个瞬间并非同等重要。" —— Yoshua Bengio
---
下篇预告:《Day7:Transformer革命—从自注意力到大语言模型基础》
将深入解析改变NLP格局的Transformer架构,并实现自己的迷你版GPT!

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)