
(2025|字节,VAE,DiT,多阶段训练,并行,蒸馏,内核融合)Seaweed-7B:经济高效的视频生成基础模型训练
Seaweed-7B 是一个具备约 7B 参数的中型视频生成基础模型,展示了中等规模模型在视频生成中的巨大潜力,其高效的数据处理、模型设计和优化策略使其在有限资源下依然具备极强的通用性与生成能力。
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
目录
1. 简介
Seaweed-7B 是一个具备约 7B 参数的中型视频生成基础模型,通过仅 665,000 小时的 H100 GPU 训练资源完成训练,在多个下游任务上与远大于它的模型相比展现了极具竞争力的性能。
本文强调设计选择在资源受限条件下的重要性,特别是在数据处理、模型架构和训练策略上。
2. 数据
在计算资源有限的条件下,数据的质量与多样性比数量更为关键。
Seaweed-7B 为支持高效训练构建了大规模高质量视频数据集。
2.1 数据处理
Seaweed 的原始视频数据来自多个来源,通过一套高效的流程进行筛选和处理,关键处理流程如下:
时间分段(Temporal Splitting):使用 HSV 3D 颜色直方图识别镜头边界,将长视频切分为单镜头片段(Clip),并结合 ImageBind 特征合并成用于长视频生成的多镜头序列。
空间裁剪(Spatial Cropping):利用 FFmpeg 的裁剪检测过滤器(crop-detect filter)清除黑边,并使用帧级模型检测水印、文字、logo 等,采用置信度与 IoU 聚合方法,将帧级检测聚合成视频级边界框,生成最优裁剪区域,无法裁剪的片段被丢弃。
质量过滤(Quality Filtering):包括:
-
属性过滤(时长、分辨率、宽高比);
-
视觉质量打分;
-
动作幅度检测(通过改进的运动矢量算法);
-
摄像机抖动与播放速度异常检测;
-
安全审查(移除暴力和色情内容);
-
非自然特效检测(滑动切换、加速、颜色过饱和等)。
-
最终无效片段比例由 42% 降至 2.9%。
多长宽比数据均衡与去重(Multi-aspect data balancing and video deduplication):
- 为处理原始数据的长拖尾分布,通过视觉(CLIP 模型)与语义(LLM 生成的标签)特征聚类,检测并移除重复内容,获得 10K+ 类。
- 对内容最多的类别降采样,在保留多样性的同时平滑分布。
合成视频引入:使用 3D 引擎生成几百万条模拟视频,增强对 3D 一致性和复杂人体动作的建模能力。
视频字幕生成(Video captioning):
-
提供 “短描述” 与 “详细描述”;
-
视频字幕生成模型由 CLIP 编码器 + LLM 构成;
-
使用 72B LLM 教师模型蒸馏出 7B 轻量模型,以减少计算开销;
-
利用 chain-of-thought 流程先生成长字幕再提炼短句,准确率从 84.81% 提升至 90.84%。
系统提示词(System Prompt):用于补充视频的结构化信息,如拍摄类型、角度、视觉风格等,并与字幕一同输入模型训练阶段,提升推理时的可控性。

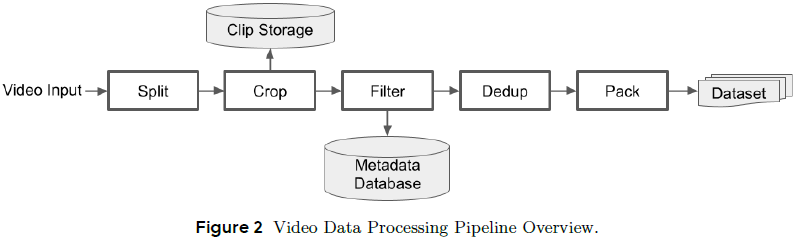
2.2 高吞吐量处理流程
为应对视频数据庞大的存储与处理压力,Seaweed 构建了高吞吐量的视频数据处理系统:
-
每日处理能力超 50 万小时视频;
-
使用 BMF(Babit Multimedia Framework) 实现模块化、跨语言的视频处理;
-
使用 Ray 实现 CPU 和 GPU 混合资源的大规模分布式调度;
-
系统支持并行处理如视频编解码、镜头分割、空间裁剪及所有质量过滤操作。
3. 设计与讨论
Seaweed-7B 模型主要由两部分组成:变分自编码器(VAE) 和潜空间扩散 Transformer(DiT)。
3.1 变分自编码器(VAE)
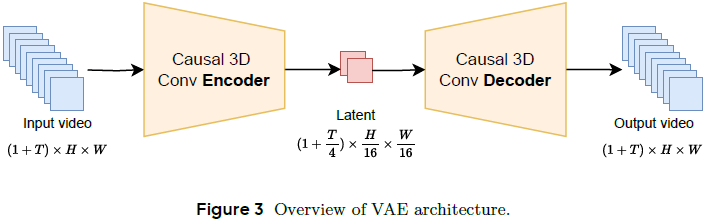
架构设计:
-
编译码器使用基于因果 3D 卷积的结构,统一图像与视频压缩的潜在表示。
-
原始 RGB 视频(T×H×W×3)被编码为潜空间张量(T×H×W×C),并可解码还原原视频。
压缩率设计:
-
48× Seaweed VAE:压缩率较低,重建更精细。
-
64× Seaweed VAE:压缩率高,收敛更快。
-
压缩率(由下采样率和潜在的通道数决定)主要决定重建质量;
- 下采样比例影响收敛速度,越小的下采样率收敛越快。值得注意的是,尽管 64× VAE 具有更高的空间压缩比,在高分辨率视频生成(如 720p)中并未观察到明显的视觉伪影。
【注:原文此处有误,结合上面的内容和图 6,此处为 “越大的下采样率收敛越快”】

设计优势:
-
支持图像转视频(首帧即视频起始帧)的自然生成方式。
-
可编码任意长度视频,避免因切片拼接造成的闪烁;
VAE 决定了生成真实感和保真度的上限。
- 由于 VAE 负责连接潜空间与像素空间,其本身的重建质量直接反映了压缩过程中的信息损失情况,也决定了生成任务所能达到的保真度上限。
- 如图 4 和图 5 所示,VAE 模型能够有效还原细腻纹理和高动态视频,这可能是能够生成视频具备高度真实感和生动运动表现的主要原因之一。


Patchification 对比:
- DiT 通过 patchification 合并相邻 token,从而减少序列长度和注意力开销
- 相较 DiT 的 patch 压缩策略,使用 VAE 进行压缩更优
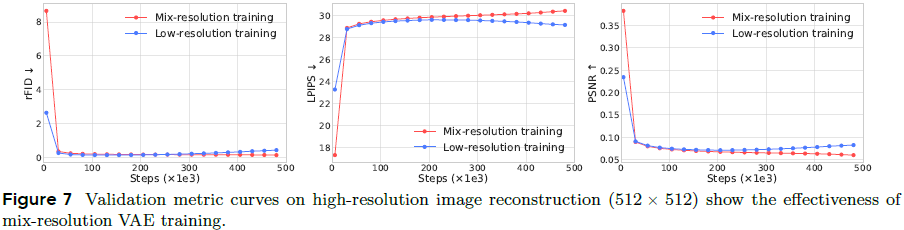
混合分辨率训练:
- 为应对高分辨率重建时的失真问题,训练阶段加入多种分辨率的图像/视频样本,显著提升泛化能力。
- 如图 7 所示,使用混合分辨率的数据进行训练比仅使用高分辨率训练具有更好的性能
【注:虽然原文没有给出仅使用高分辨率数据训练的结果,但是直觉上,这样会有更好的结果,但会有更高的计算开销。而使用混合分辨率数据训练是在更好的结果与训练开销之间的折衷】
提升 VAE 训练稳定性的技巧:VAE 同时采用重建损失(如 L1 和 LPIPS)与对抗损失进行训练,其中对抗训练的稳定性对大规模 VAE 训练至关重要,使用如下方法以增强训练稳定性:
- 首先,同时使用图像判别器和视频判别器比单独使用任意一种判别器效果更好。对于判别器结构而言,PatchGAN 比 StyleGAN 和 UNet 判别器效果更佳。
- 然而,PatchGAN 搭配 BatchNorm 在高压缩比 VAE 中可能过于强势,导致训练不稳定。实验表明,SpectralNorm 比常用的 R1 正则化或 LeCAM 正则化能更有效地提升训练稳定性。
- 因此,移除所有 BatchNorm 层,并在所有卷积层上应用 SpectralNorm。尽管在训练初期,SpectralNorm 相比 BatchNorm 或 GroupNorm 会略微降低重建指标,但它能带来更稳定的训练过程,并最终实现更好的重建性能。
3.2 DiT
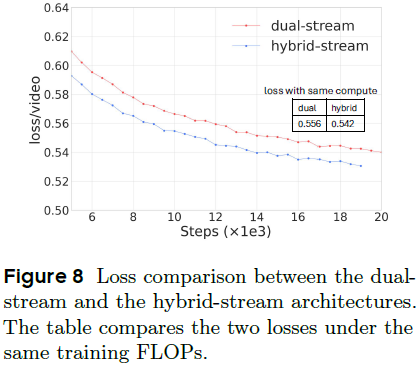
Hybrid-stream 结构表现出更快的收敛速度。采用双流(Dual-stream)DiT作为扩散模型的主干结构,其中视频与文本 token 分别通过多个自注意力层和前馈网络(FFN)处理,使每种模态能独立学习表示(representation)。在实现细节上:
-
将激活函数由 GeLU 替换为 SwiGLU;
-
使用 AdaSingle 方法进行时间步调制;
-
在模型的深层部分共享三分之二的 FFN 参数,以提升参数利用率并减少显存开销。
-
这种结构称为 Hybrid-stream
实验表明,在相同的参数规模与计算预算下,该结构相比传统双流(Dual-stream)结构能够实现更快的训练收敛。
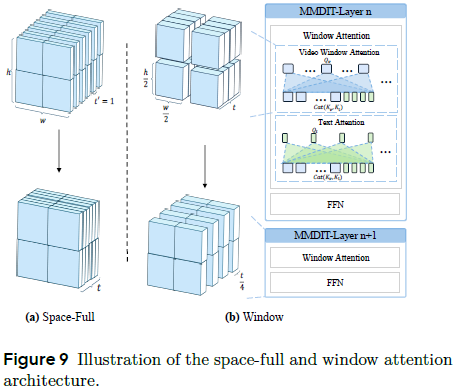
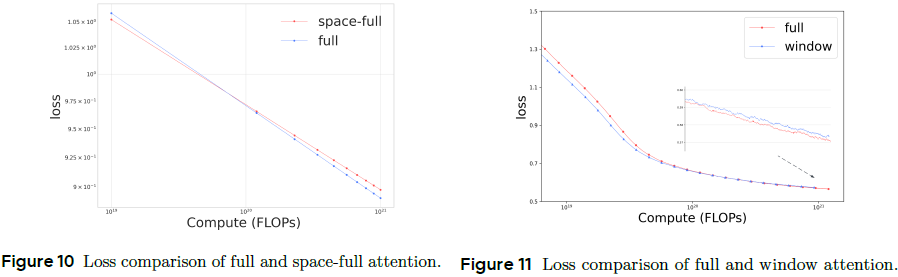
注意力机制选择:比较三种机制:全注意力(Full)、空间注意力(Space-Full)、稀疏窗口注意力(Window)。
- 在充分计算预算下,全注意力最终效果最优;
- 稀疏注意力初期收敛快,后期全注意力表现更强;
- 建议策略:先用全注意力预训练,再切换为稀疏结构提升推理效率。
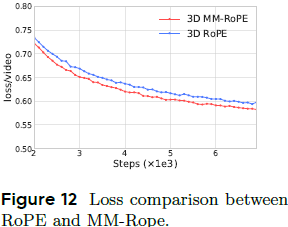
多模态旋转位置编码(MM-RoPE):
- 为增强不同长宽比和时长下的位置编码效果,在视频 token 上应用了 3D 旋转位置编码(3D RoPE,包括时间、宽度和高度),在注意力计算中同时考虑绝对与相对位置依赖关系。
-
为了进一步促进文本与视频之间位置信息的有效融合,在拼接后的序列中构建了 3D 多模态旋转位置编码(3D MM-RoPE):为文本 token 添加兼容的 1D 位置编码,并与视频 token 共享相同的位置 ID。
- 如图 12 所示,在双流 MMDiT 结构中采用这一设计可以显著降低训练损失。
3.3 多阶段训练策略
Seaweed-7B 采用逐步扩展分辨率与任务难度的 多阶段、多任务训练流程,包括预训练(Pre-training)与后训练(Post-training)两个阶段,目标是在有限 GPU 资源下最大化训练效率与生成质量。
3.3.1 预训练(Pre-training)

四阶段训练流程:
-
Stage 0:仅使用图像进行训练,有助于构建文本与视觉之间的对齐关系;
-
后续阶段逐步引入视频,提升视频生成的解析度与动态建模能力;
-
所有阶段中图像与视频数据按一定比例混合训练。
多任务混合训练:
- 训练任务包括:文本 → 视频,图像 → 视频,视频 → 视频
- 文本 → 视频是最有效的收敛任务;
- 图像 → 视频任务比例设置为 20%,能提升两个任务的泛化能力;
- 预训练后会派生出一个专门的图像→视频模型,将任务比例调整至 50–75%,进一步优化生成一致性。
3.3.2 后训练(Post-training)
为提升生成质量,Seaweed-7B 在预训练之后引入两步微调:
监督微调(Supervised Fine-Tuning,SFT)
-
使用约 700K 高质量视频进行人工筛选并标注;
-
选取其中 50K 美学表现最优的视频加权训练;
-
目标是提升视频的色彩表现与美学风格;
-
注意:训练时间过长会造成 “过拟合” 现象,导致生成内容无法准确响应输入提示,运动质量下降。

人类反馈强化学习(Reinforcement Learning from Human Feedback,RLHF):为弥补 SFT 后出现的结构和运动退化,使用直接偏好优化(Direct Preference Optimization,DPO)强化学习;
- 每条文本-视频对生成 4 个候选视频;
- 人类标注者从中选出最好与最差;
- 训练时对 “好视频” 加权 SFT 损失,实现微调;
- 参数设置:学习率 1e-7(50 ~ 100 倍小于 SFT),权重因子 β = 100;
与 LLaMA 的 “切换参考模型” 的多轮 DPO 不同,Seaweed 始终使用 SFT 模型作为参考模型,避免出现问题:在目标维度(例如,结构崩塌)上仅带来微弱的提升,但在其他维度(例如,指令跟随性、颜色准确性)上出现明显的下降。
图像→视频特例处理:
-
由于该任务中首帧是确定的,与负样本之间差异应最小;
-
常规 DPO 会对首帧产生过饱和现象;
-
解决方法:将首帧与后续帧分离处理,只对后续帧计算 DPO 损失,保持前后内容一致性。
3.4 基础设施
为支持在高分辨率与长时长视频上的大模型训练,Seaweed-7B 构建了高效的分布式训练基础设施,从并行策略、负载均衡到显存优化全面提升训练吞吐与稳定性。
3.4.1 并行策略
使用 3D 并行:
-
数据并行(Data Parallel)
-
上下文并行(Context Parallel)
-
模型切分(Model Sharding)
使用完全切分数据并行(Fully Sharded Data Parallel,FSDP):
-
切分模型参数、优化器状态与梯度;
-
支持计算与通信重叠,提高训练效率。
上下文并行采用 Ulysess 框架:通过全互联通信(all-to-all communication),在 token 依赖层与非依赖层中,迭代地沿着序列维度和注意力头维度对样本进行切分。
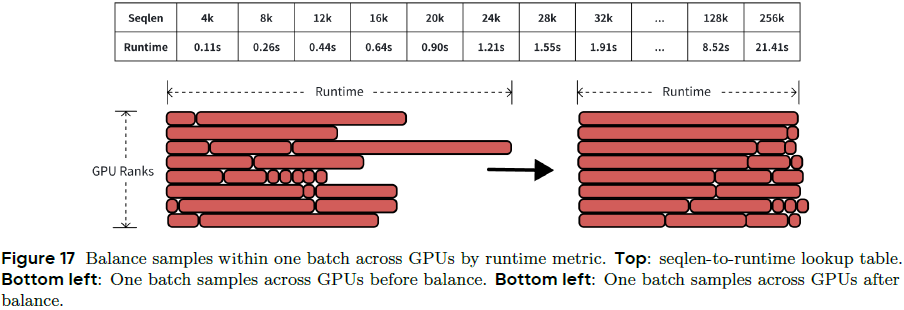
3.4.2 运行时长均衡(Runtime Balance)
问题:图像与视频混合训练导致样本长度差异大,GPU 负载严重不均,造成同步等待、吞吐下降。
现有方法:按序列长度或 FLOPs 分配任务,但由于运算符效率差异,无法实现最优均衡。
Seaweed 方法:
-
构建一个离线查找表,将序列长度(seqlen)映射为实际运行时长。
-
在训练过程中,系统通过查表方式获取运行时长估计值,从而实现最优的工作负载分配。
3.4.3 多级激活检查点(MLAC)
问题:普通激活检查点(Activation Checkpointing)虽可减少显存使用,但仍需缓存模块输入,在长语境场景可能导致显存溢出(OOM)。
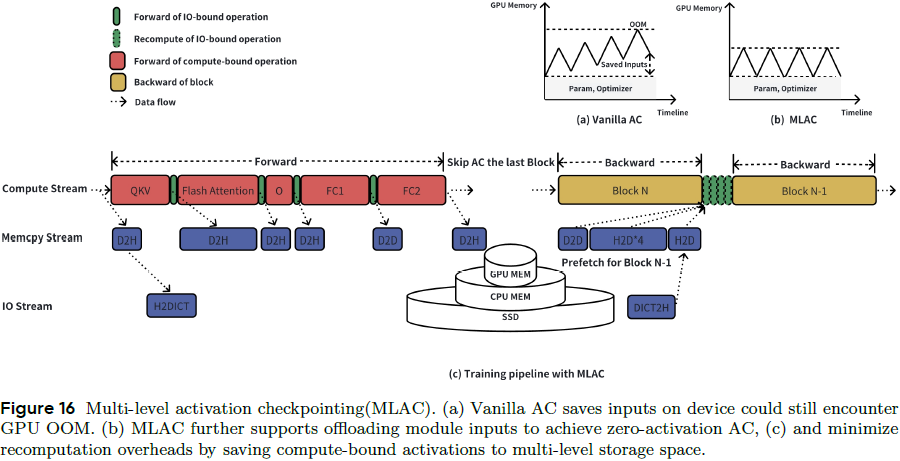
MLAC 解决方案:
-
将激活缓存分为 GPU / CPU / 硬盘 多级存储;
-
对计算密集型层仅保存输出激活,极大减少反向传播时的重算;
-
梯度检查点模块的输入则可转移至 CPU / 硬盘,达到 GPU 激活 “零占用”,实现更大模型更长上下文训练;
-
通过异步缓存 + 预取机制,最大限度重叠显存传输与前向/后向计算过程。
3.4.4 融合 CUDA 内核
许多内存密集型操作(如归一化、RoPE 编码)存在大量全局内存访问,限制了 GPU 计算单元利用率。
Seaweed 提出 融合内核策略(Fused Kernel):
-
利用寄存器和共享内存缓存内存访问密集型操作(如 QK-Norm、RoPE 和注意力预处理)的中间结果,并将它们融合为单个 CUDA 内核(前向和反向融合内核)。
-
这些融合内核将全局内存访问量减少至原来的十分之一,显著提升了内核的计算强度(arithmetic intensity)。
-
同样适用于模型中其他内存密集型模块,显著提升训练与推理效率。
3.5 推理与加速优化
为实现高质量且高效的视频生成,Seaweed-7B 在推理速度、VAE 效率、Prompt 理解质量三方面进行了系统级优化。
3.5.1 推理加速
采用三阶段蒸馏方案,显著减少推理步数(NFE),提升速度:
轨迹分段一致性蒸馏(trajectory segmented consistency distillation,TSCD)
-
采用 HyperSD 提出的方法;
-
将模型推理步数从 >50 降至约 24 NFE,保持输出质量。
CFG(Classifier-Free Guidance)蒸馏
-
引入 CFG 嵌入模块,避免原始 CFG 每步双推理(two-NFE-per-step)的问题,提升效率
-
该模块同时支持引导强度与负面提示词输入
对抗训练增强少步推理质量:为缓解少步推理所带来的模糊问题,在模型固定为 8 NFE 的条件下,进行了对抗训练。
基于三阶段蒸馏方案,8-NFE 蒸馏模型在文本对齐与运动质量方面与原始模型相当,且在视觉保真度上表现更优。例如,在一项典型评估中,该 8 NFE 模型的胜率为 56%,与原始模型的 58% 非常接近。
3.5.2 VAE 优化
因果分块(Causal Chunking)
-
显著降低显存消耗;
-
单 GPU(40GB+)即可支持 1280×720 分辨率任意长度视频的编码/解码。
高分辨率支持
-
使用特征图分块策略,分区域处理卷积与归一化,减少显存峰值;
-
同时实现更大分辨率推理。
多 GPU 时序并行
-
视频在时间维度划分成片段,分配至多个 GPU;
-
每层因果卷积将 padding 缓存传递至下一 GPU,实现时序并行加速。
3.5.3 Prompt 重写(Rephraser)
为提升生成图像的视觉表现与运动稳定性,Seaweed 训练了一个提示词重写模型,将用户 prompt 改写为更接近专业视频字幕(caption)风格:
-
构建并行语料对(原始 prompt ↔ 高质量字幕);
-
使用一个 7B LLM 进行微调,生成 8 个改写版本;
-
使用监督微调 + DPO 训练,筛选语义准确且风格优的版本;
-
效果:显著提升美学与风格一致性;
-
注意事项:对于超过 12 个词的长 prompt,可能出现语义偏移,导致指令跟随能力下降。
4. 评估
4.1 视频生成的定量分析
任务类别:
-
图像到视频(Image-to-Video)
-
文本到视频(Text-to-Video)
方法:
-
使用 MagicArena 平台进行 人类评价 Elo 排名;
-
每轮比较两个模型在相同 prompt 下生成的视频,由人工评价其总体保真度;
-
每个模型至少参与了 7000 次配对对比,评价由 500 多位人类评估者完成。
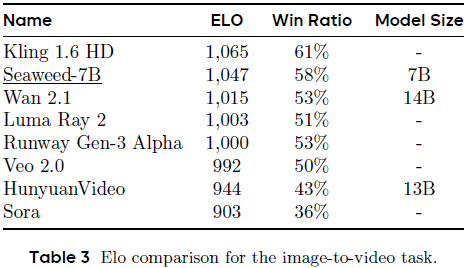
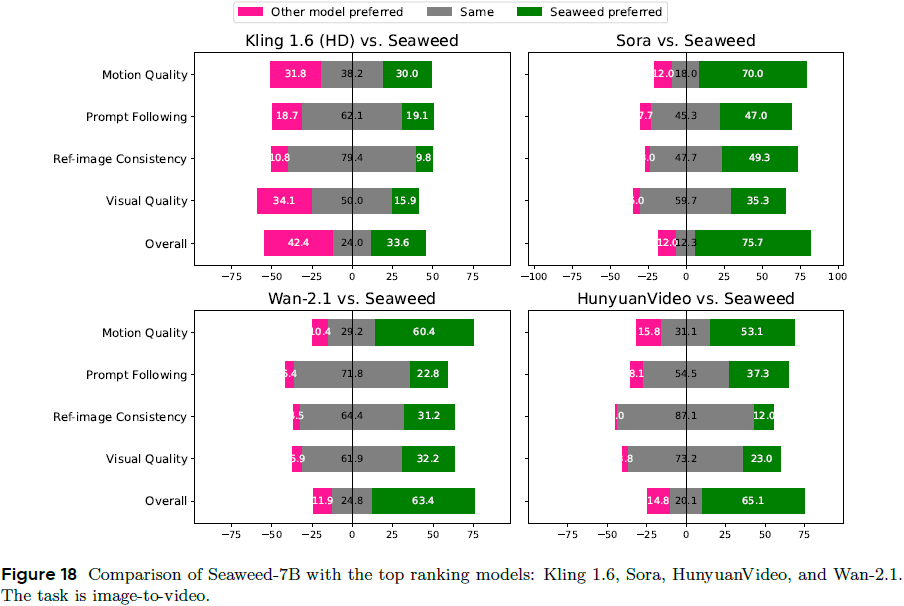
图像到视频任务 Elo 排名结果:
-
Seaweed-7B 超越多个更大规模模型(如 Wan 2.1 和 HunyuanVideo);
-
Kling 由于输出为 1080p 在视觉质量上更优,而 Seaweed 使用 480p–720p,性能仍极具竞争力;
-
精细指标评估(如下图所示)显示:Seaweed 在 运动质量与指令对齐上表现突出,在图像一致性与美学表现上略低于 Kling。
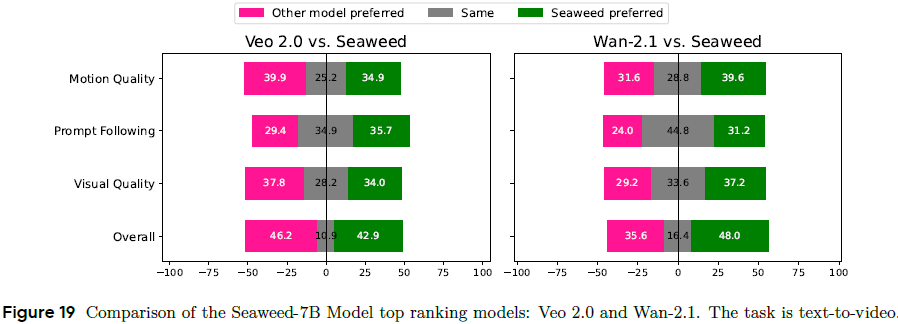
文本到视频任务表现:
-
Seaweed 在 Elo 排名中名列前 2–3;
-
与 Veo 2.0 和 Wan 2.1 持平或略优,优于 Kling;
-
在 prompt 跟随能力和运动质量上表现尤其出色。
4.2 推理效率分析

Seaweed-7B 推理速度提升约 62 倍;
主要得益于:三阶段蒸馏、少步对抗训练、蒸馏优化后的 CFG 模块。
4.3 VAE 重建质量评估
使用两套评估数据集:
-
UCF-101(动作视频短片,256×256)
-
MCL-JCV(高分辨率长视频,720×1080)
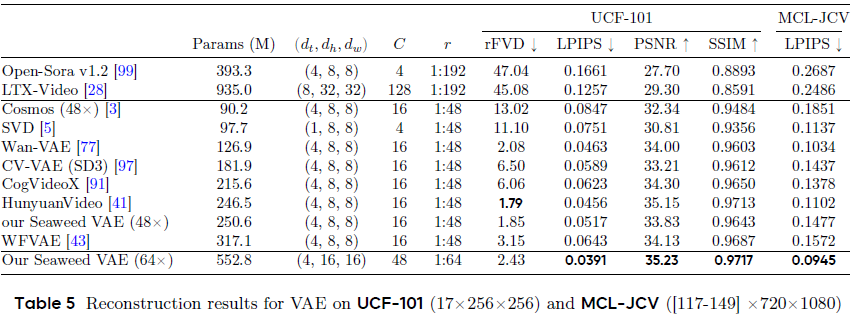
Seaweed-7B 的 VAE 模型在重建精度和压缩效率之间达到了极佳的平衡;
特别是 64× VAE 在更高压缩率下仍实现最低 LPIPS 与最高 SSIM,表明其在真实细节保留方面性能优异。

5. 应用
Seaweed-7B 作为视频生成基础模型,具备良好的泛化能力,能够在多种下游任务中实现 零样本生成 或通过 轻量微调(如 LoRA) 高效适配。
1)图像到视频生成
模型原生支持从图像和文本提示生成视频;
还支持首帧和尾帧条件生成,实现从起始图像到目标图像的自然过渡(视频过渡生成)。
2)人体视频生成
通过优化架构、定制训练策略与人体数据,OmniHuman-1 模型在 Seaweed 基础上扩展,实现 SOTA 级人体动画生成。
3)主体一致性视频生成(Subject-Consistent Video Generation)
微调模型以支持单人/多人、物体、服装、动物、虚拟角色等一致性生成;
支持多主体交互,如虚拟试穿、产品演示、群体动作等。
4)视频-音频联合生成
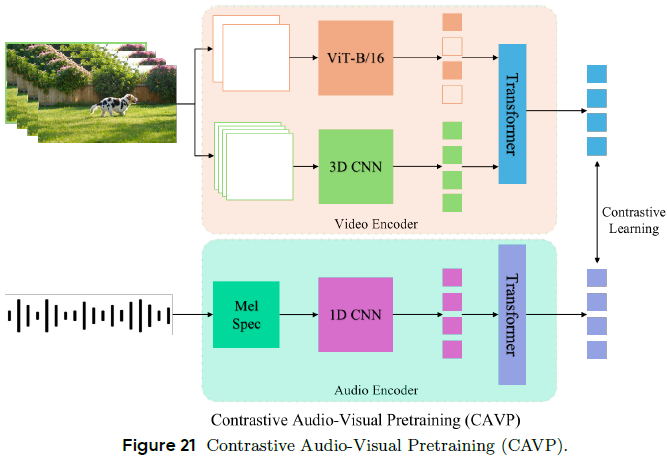
引入对比式音视频预训练(Contrastive Audio-Visual Pretraining, CAVP)模型:
-
视频编码器包括两个分支:
-
高帧率分支使用 3D CNN 提取细粒度动作特征;
-
低帧率分支使用 SigLIP 模型捕捉静态关键帧语义;
-
-
音频使用 mel-spectrogram + transformer 提取特征;
用作条件输入的音频通过条件扩散模型生成,实现时序对齐与语义一致的音视频内容生成。
5)长视频生成与故事生成
使用长上下文微调(long-context tuning,LCT) 技术,实现单镜头模型的长场景生成;
支持生成由多个片段组成的故事内容,并探索 视频-文本交替生成 的故事创作流程(视频 + 解说文本自动生成)。
6)实时生成
通过 Seaweed-APT 实现 1 步推理(1-NFE);
支持 720p@24fps 的实时视频生成;
拓展如虚拟主播、视频聊天、互动动画等实时场景应用。
7)超分辨率与视频修复
Seaweed 可生成高分辨率视频;
亦可作为低质量视频恢复的起始模型,在公开 benchmark 上达成 SOTA 水平。
8)摄像机控制生成
模型支持多种虚拟摄像机运动(如 Dolly-out、Pan-left、Spin-shot 等);
结合合成数据与 CameraCtrl II 实现精准控制;
适配图像转视频、长视频与实时视频生成任务。
6. 相关工作
视频生成作为多模态人工智能研究的前沿领域,在过去两年中发展迅猛,吸引了学术界和工业界的广泛关注。其研究意义在于:视频作为融合图像、文本、语音等多模态的媒介,具备极高的生成潜力。
视频生成的挑战。与图像生成不同,视频生成面临额外挑战:
-
需要建模时序动态信息;
-
要保持跨帧的时空一致性;
-
在计算上远比语言/图像生成开销更大;
-
导致视频生成模型通常是资源最密集的基础模型之一。
早期方法。在扩散模型成为主流之前,许多方法依赖于对已有图像生成模型的微调,例如:
-
扩展 U-Net 模型结构,引入时间维度;
-
修改架构以适配视频输入;
-
从头训练的模型开始受到关注,强调同时使用图像与视频训练,提升泛化能力
标志性架构进展。随着模型和数据规模的增长,出现了多个重要架构革新:
-
Diffusion Transformers(DiT)用 Transformer 替代 U-Net 以更好扩展;
-
因果 3D VAE 可高效建模视频的时空潜变量;
-
此类结构逐步成为主流系统(如 WALT)的标准组成部分。
代表性系统。Sora 是视频生成领域的重要里程碑:
-
集成多项前沿技术:DiT、3D VAE、图像+视频联合训练、序列打包等;
-
实现原始分辨率训练和多分辨率视频生成;
-
展示出极高的视觉质量,显著优于同期模型;
-
促使学界和产业加大对视频生成的投入。
商业产品与产业生态。基于扩散模型的视频生成技术快速商业化,涌现出多个产品与模型:MovieGen、Cosmos、HunyuanVideo、Nova、Veo、Runway、Pika、Kling、WanVideo、Pixelverse、Mochi、DreamMachine 等;
Seaweed-7B 在该背景下的突出贡献是:在显著降低训练资源消耗的前提下,达成与大模型相媲美甚至超越的性能表现。
7. 结论
Seaweed-7B 展示了中等规模模型在视频生成中的巨大潜力,其高效的数据处理、模型设计和优化策略使其在有限资源下依然具备极强的通用性与生成能力。未来需在细节保真、安全性及伦理性方面继续完善。
论文地址:https://arxiv.org/abs/2504.08685
项目页面:https://seaweed.video/
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 26
26 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)