
大数据(1c)集群环境变量,持续更
`source /etc/profile.d/custom.sh`个人专用的集群环境变量环境变量文件hosts集群环境变量source命令集群环境变量source脚本python自动化运维脚本hadoop环境变量profile
·
阅读本文前,请先配置好集群免密登录
1、环境变量文件
vim /etc/profile.d/custom.sh
# Big Data:大数据根目录
export B_HOME=/opt
# Java
export JAVA_HOME=$B_HOME/jdk
export PATH=$PATH:$JAVA_HOME/bin
# Zookeeper
export ZOOKEEPER_HOME=$B_HOME/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
# Hadoop
export HADOOP_HOME=$B_HOME/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# HIVE
export HIVE_HOME=$B_HOME/hive
export PATH=$PATH:$HIVE_HOME/bin
# Spark
export SPARK_HOME=$B_HOME/spark
export PATH=$PATH:$SPARK_HOME/bin
# Kafka
export KAFKA_HOME=$B_HOME/kafka
export PATH=$PATH:$KAFKA_HOME/bin
# Flume
export FLUME_HOME=$B_HOME/flume
export PATH=$PATH:$FLUME_HOME/bin
# Sqoop
export SQOOP_HOME=$B_HOME/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
# HBase
export HBASE_HOME=$B_HOME/hbase
export PATH=$PATH:$HBASE_HOME/bin
# Scala
export SCALA_HOME=$B_HOME/scala
export PATH=$PATH:$SCALA_HOME/bin
# Flink
export FLINK_HOME=$B_HOME/flink
# Phoenix
export PHOENIX_HOME=$B_HOME/phoenix
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
# ElasticSearch
export ES_HOME=$B_HOME/elasticsearch
# Maven
export MAVEN_HOME=$B_HOME/maven
export PATH=$PATH:$MAVEN_HOME/bin
# Atlas
export ATLAS_HOME=$B_HOME/atlas
# DolphinScheduler
#export DOLPHINSCHEDULER_HOME=$B_HOME/dolphinscheduler
用户为root时需要添加下面变量
# Hadoop user
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# SecondaryNameNode
export HDFS_SECONDARYNAMENODE_USER=root
# Hadoop high availability
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
2、集群hosts配置
https://yellow520.blog.csdn.net/article/details/113073636
3、集群环境变量source脚本
脚本的功能:一键 分发环境配置文件 并 使其生效(有点小bug)
3.1、Python版(root用户可用)
touch /usr/bin/source.py
chmod 777 /usr/bin/source.py
vim /usr/bin/source.py
#!/usr/bin/python2
import os, re, socket
# file name
f = 'custom.sh'
# command
source = 'source /etc/profile.d/' + f
hostname = socket.gethostname()
with open('/etc/hosts') as fr:
for h in re.findall('hadoop[0-9]+', fr.read()):
if h == hostname:
os.system(source)
else:
os.system('rsync -a /etc/profile.d/{} {}:/etc/profile.d/'.format(f, h))
os.system('ssh {} "{}"'.format(h, source))
3.2、bash版(非root用户可用)
cd ~
touch source.sh
vim source.sh
#!/usr/bin/bash
for h in $(cat /etc/hosts | grep -oE 'hadoop[0-9]+')
do
sudo rsync -a /etc/profile.d/custom.sh $h:/etc/profile.d/
done
source /etc/profile.d/custom.sh
使用方法
source ~/source.sh
4、补充
CentOS7系统目录结构基础知识
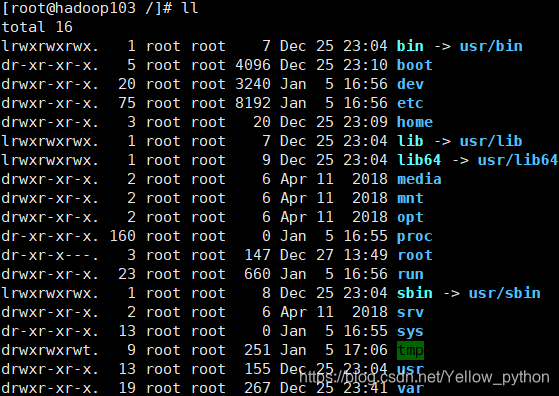
| 常用目录 | 全称 | 说明 | 备注 |
|---|---|---|---|
| usr | Unix Shared Resources | Unix共享资源 | bin和sbin都在这里面自写脚本放到此处,可在任意目录调用 |
| bin | binaries | 二进制文件 | 存放常用指令,如:ls、pwd、python2 |
| sbin | Super User Binaries | 超级用户的二进制文件 | 存放系统管理员使用的程序和指令 如: init、reboot |
| etc | etcetera | 存放系统管理所需的配置文件 | 如:profile、sudoers |
| root | 系统管理员的用户主目录 | ||
| home | 普通用户的主目录 | ||
| opt | optional | 额外软件所摆放的目录 默认是空的 |
比如可以把Hadoop装到这个目录下 |
| tmp | temporary | 存放临时文件 |

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)