
最新大数据入门-大数据技术概述(二)
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在
一、简介
====
本次介绍的是Zookeeper、Yarn、Spark、Impala、Kafka、Flume。
二、技术详解
======
1.分布式协调服务:Zookeeper
1.架构
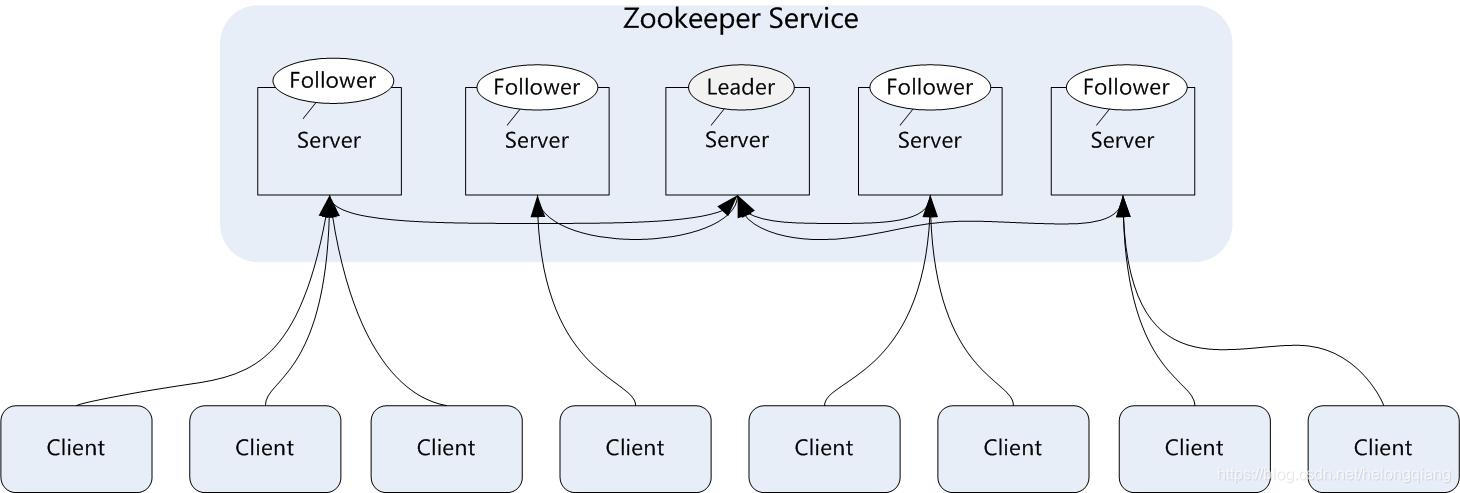
2.简介
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
3.特点
一致性、可靠性、实时性、等待无关、原子性、顺序性。
2.分布式资源管理器:Yarn
1.架构

2.简介
Apache Hadoop YARN是一种新的Hadoop资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
3.计算引擎:Spark
1.架构

2.简介
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是加州大学伯克利分校的AMP实验室所开源的类Hadoop MapReduce的通用并行框架,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
3.特点
运行速度快、易用性好、通用性强、随处处理。
4.查询引擎:Impala
1.架构

2.简介
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
3.特点
查询速度快,无需转化为MR、但是基于内存,计算的数据量不能大于内存。
5.分布式消息系统:Kafka
1.架构

2.简介
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
3.特点
解耦、冗余、扩展性、灵活性和峰值处理、可恢复性、顺序保存、缓冲、异步通信。
6.日志收集系统:Flume
1.架构

2.简介
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3.特点
高可靠、可恢复性。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
入研究,那么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)