
万物皆可Graph | 当信息检索遇上图神经网络
作者|上杉翔二悠闲会·信息检索整理|NewBeeNLP本篇文章继续整理 Graph in Rec&Search 这个系列的文章,以前博主整理过的系...

作者 | 上杉翔二
悠闲会 · 信息检索
整理 | NewBeeNLP
本篇文章继续整理 Graph in Rec&Search 这个系列的文章,以前博主整理过的系列可以见:
这次更新最近SIGIR2021,博主自己刷过觉得还不错的几篇文章,分搜索和推荐两篇博文整理吧,这篇是关于检索的三篇文章。
GraphCM
-
A Graph-Enhanced Click Model for Web Search
-
https://dl.acm.org/doi/10.1145/3404835.3462895
图方法结合点击模型,不做过多科普。作者认为现有的点击模型无法应对
-
稀疏性。现有的模型通常会出现数据稀疏性问题,即对查询文档对缺乏有用的用户交互反馈。
-
冷启动。现有的模型在冷启动环境中易受到攻击。
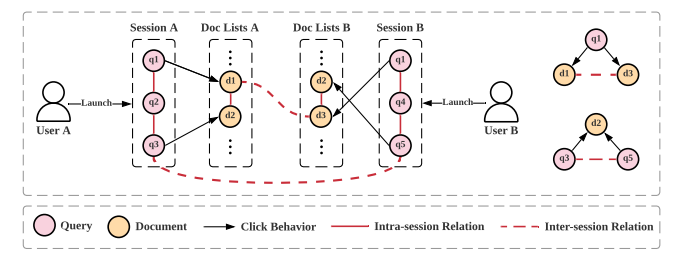
因此从不同用户发布的不同会话(即会话间信息)的查询或文档或会话之间的交互中提取用户的行为模式具有丰富的潜力,可以同时解决以上问题。因此提出图增强点击模型(GraphCM),模型图如下: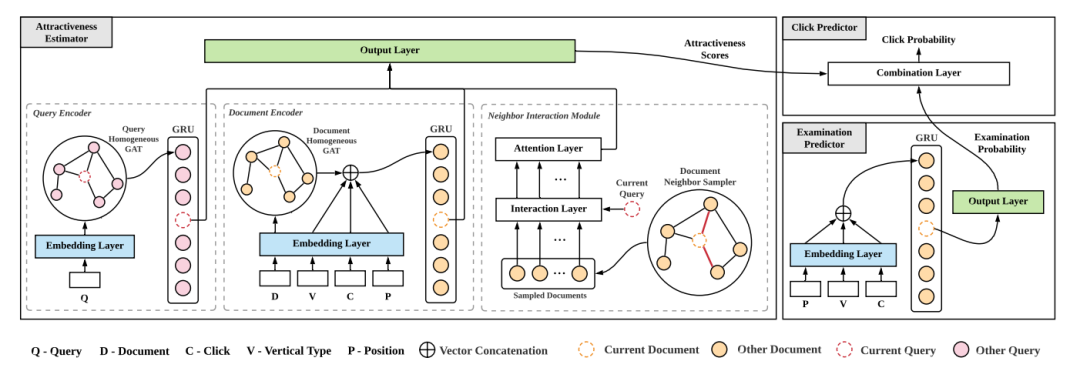 博主个人觉得具体的做法比较完善,GraphCM由attractiveness estimator和examination predictor组成。attractiveness estimator涉及到三个模块,query encoder, document encoder, 和neighbor interaction,即左边的三个小虚线框框。
博主个人觉得具体的做法比较完善,GraphCM由attractiveness estimator和examination predictor组成。attractiveness estimator涉及到三个模块,query encoder, document encoder, 和neighbor interaction,即左边的三个小虚线框框。
-
query encoder。编码查询上下文,将每个查询视为一个顶点构图,利用Query Homogeneous GAT学习表示,然后GRU建模序列得到表示。
-
document encoder。编码文档上下文,document构图同query类似,用GAT学习完毕之后,还会拼接一些,文档ID d、垂直类型v、先前点击c,排序位置p,一起生成文档上下文表示。
-
neighbor interaction。进一步考虑查询和文档之间的交互,提出了一种显式合并文档高阶邻居信息的邻居交互方法,即采样同域内的节点,进一步丰富局部图的结构信息,可以缓解数据的稀疏性问题。
attractiveness estimator测量的是每个文档对用户的吸引力分数,而examination predictor旨在预测用户是否会根据她的会话上下文继续点击概率。即上图右侧的两个任务小框。最后可以看到模型通过一个组合层,结合吸引力分数和概率来进行用户点击预测。
FNPS
-
Group based Personalized Search by Integrating Search Behaviour and Friend Network
-
https://dl.acm.org/doi/abs/10.1145/3404835.3462918
这一篇的任务是个性化搜索。一般常见的个性化搜索在数据少时会合并一些相似用户,即有相似的搜索词。但当行为少时,这种相似用户的行为不一定可靠,因此引入朋友网络来共同建模,即相似的信息需求+多样的朋友关系。
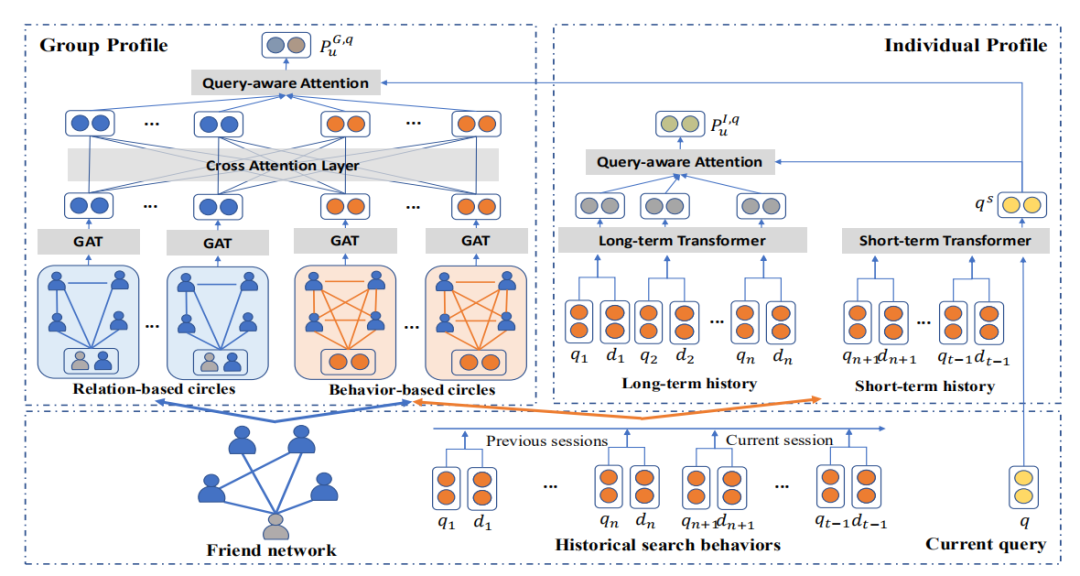
作者提出模型FNPS的架构如上图,比较直观
-
首先,利用朋友网络和用户的历史搜索行为,从两个角度形成朋友圈。即图中的relation-based circles(友谊伴随这共享的经验,因此拿到朋友关系来分组)和behavior-based circles(历史搜索行为可以在一定程度上反映用户的兴趣,所以利用行为来分组)。
-
其次,利用图注意网络GAT对不同权重的朋友信息进行聚合。
-
第三,将两种朋友圈的表征输入交叉注意层Cross-Attention,相互增强。
-
最后,为了响应当前的查询意图,使用查询感知的注意力来突出相关的朋友圈。其中长短期Transformer建模历史记录得到动态的个人profile信息。
GRAPH4DIV
-
Modeling Intent Graph for Search Result Diversification
-
https://dl.acm.org/doi/10.1145/3404835.3462872
这一篇研究搜索多样性问题。搜索结果多样化旨在提供包含尽可能多意图的不同文档。一些常见的多样性检索方法博主在过往文章有过整理了,传送门:多样性检索[5]。
一般都是使用逐个选最多样的某个item,但作者认为现有多样化的方法仍然存在的问题有:
-
多样性排序loss是唯一的。因此就不知道排错的结果是因为特征的组合问题导致,还是多样性的特征不够。同时只用初始化特征来计算新颖性也是不准确的,文档的内容是推导文档多样性信息的重要来源,应该被重点关注。
-
候选文档的多样性是通过其与所选文档的不同性来衡量的,而忽略了所选文档对查询的意图覆盖范围和候选文档之间的相似性。
总体来说作者认为文档的内容和查询的意图是重要的两个衡量点。但会各自遇到两大困难:
-
如何同时考虑内容和意图覆盖来计算文档相似度。文档的意图很重要,相似的内容一定也共享很多的意图。同时对于结果来说,返回文档中的意图越多则多样性越好,但用户意图通常隐藏在文档内容中。
-
如何在文档选择过程中考虑查询和文档的复杂和动态关系。这里的动态博主个人理解是在一个一个挑选过程中,选择队列中对意图多样性的需求是不断变动的,因此候选文件的多样性不是独立的。
因此作者提出可以直接通过文档意图覆盖范围的相似性,而不是仅仅文档表示特征的相似性来建模,同时讨论复杂的意图关系。最终提出的方案GRAPH4DIV如下图所示: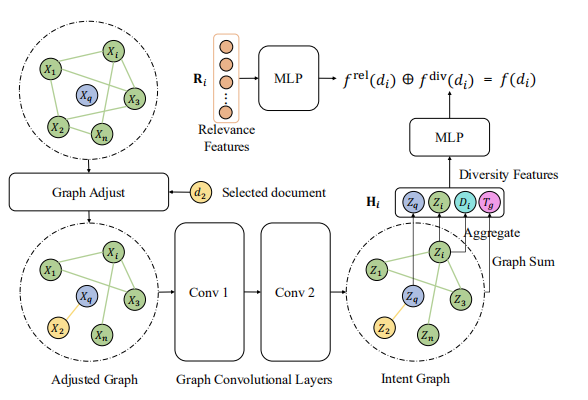 首先看一下ranking分数 的计算,如上图的右上角的地方:
首先看一下ranking分数 的计算,如上图的右上角的地方:
402 Payment Required
其中当前查询 、文档集 和候选文档 。 和 分别是相关性和多样性分数。然后这俩的计算分别为: 相关性分数比较好计算,而多样性分数由于选择文档的动态性,因此计算会复杂一些为:如图的其他部分都是在获得这里的多样性特征 。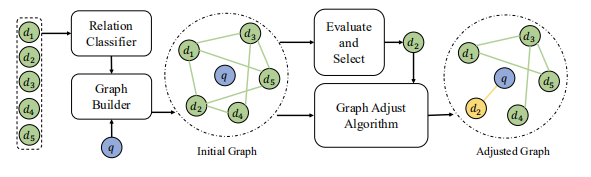
具体的做法分为以下几步。
-
文档关系图。为了充分利用文档内容的丰富信息,作者设计了一个文档关系分类器,其根据文档内容的内容来判断两个文档是否包含相同的意图。然后构建意图图,其中如果两个文档共享相同的意图,则它们是连接的。
-
图卷积层。用GCN适应这个动态意图图来学习意图感知文档表示和上下文感知查询表示。动态的意思是当选择完分数最高的文档后,图的结果将会变化即Adjusted Graph,然后在用GCN学习表示。
-
多样性特征。由query表示 ,文档表示 ,度表示 和全局图表示 组成。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

本文参考资料
[1]
图神经网络用于推荐系统问题(PinSage,EGES,SR-GNN): https://nakaizura.blog.csdn.net/article/details/106413118
[2]图神经网络用于推荐系统问题(NGCF,LightGCN): https://nakaizura.blog.csdn.net/article/details/106970194
[3]图神经网络用于推荐系统问题(IMP-GCN,LR-GCN): https://nakaizura.blog.csdn.net/article/details/114320157
[4]图神经网络用于推荐系统问题(SURGE,GMCF,TASRec): https://nakaizura.blog.csdn.net/article/details/121549056
[5]多样性检索: https://blog.csdn.net/qq_39388410/article/details/109706683
- END -






技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)